-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Giunti (CX)
Informazioni su Joins
I join consentono di combinare le righe di 2 o più origini dati in base a una colonna di dati correlata che condividono. Utilizzando un join, è possibile raccogliere e analizzare i dati combinati in modo più efficiente ed efficace, creando maggiori approfondimenti.
Il modellatore di dati CX supporta solo join esterni a sinistra, join interni e join esterni. Solo le giunzioni esterne a sinistra si aggiornano continuamente.
Chiavi di accesso
Una chiave di join è un campo che aiuta ad abbinare più set di dati, identificando quali record devono essere combinati. Ad esempio, gli identificatori unici mappati ai dati della dashboard, come ID e nomi utente. Le chiavi di giunzione sono importanti per assicurarsi che una giunzione sia impostata correttamente.
Il modellatore di dati non supporta le chiavi di join che:
- Sono stati ricodificati.
- Sono stati modificati.
- Sono popolati da qualsiasi campo di Text iQ (ad esempio, argomenti, analisi del sentiment, azionabilità, ecc.)
- Avere più di 50.000 valori unici.
Né la chiave di unione aggiunta al lato destro o sinistro supporta queste configurazioni.
Capire le giunzioni esterne a sinistra
Per capire come funziona una join esterna sinistra, vediamo un esempio.
Guardate l’immagine del set di dati qui sotto. La prima origine dati in alto è la nostra origine dati “sinistra”, mentre la seconda origine dati in basso è la nostra origine dati “destra”.
Diciamo che queste tabelle rappresentano i dati che si possono trovare in ogni sondaggio
:Origine del SONDAGGIO (Origine sinistra)
| ID posizione | Nome località |
| 555 | Provo |
| 777 | Dublino |
| 999 | Seattle |
| 1000 | Tokyo |
Feedback dei clienti (fonte giusta)
| ID cliente | Soddisfazione (1-5) | ID posizione |
| 101 | 2 | 555 |
| 102 | 4 | 777 |
| 103 | 5 | 999 |
| 104 | 5 | 222 |
Si sceglie di unire i dati in base all’ID della località. Questo campo è chiamato “chiave di collegamento”
Questi sono i dati unici del secondo set di dati. Questo sarebbe stato rimosso:
| ID cliente | Soddisfazione (1-5) | ID posizione |
| 104 | 5 | 222 |
Questo è l’output finale, ovvero tutti i dati che saranno inclusi nei risultati:
| ID posizione | Nome località | ID cliente | Soddisfazione (1-5) |
| 555 | Provo | 101 | 2 |
| 777 | Dublino | 102 | 4 |
| 999 | Seattle | 103 | 5 |
| 1000 | Tokyo | Nullo | Nullo |
Si noti come i risultati di Provo, Dublino e Seattle contengano colonne di dati provenienti sia dall’origine destra che da quella sinistra, perché queste righe condividono ID di località comuni.
Nell’origine dati non c’erano dati per Tokyo, quindi la riga di Tokyo ha valori nulli nelle nuove colonne ID cliente e Soddisfazione.
Importanza delle chiavi di accesso univoche
Poiché le chiavi di join aiutano a identificare le righe che devono essere combinate dalle fonti di sinistra e di destra, si consiglia di assicurarsi che la chiave di join utilizzata sia un identificatore unico. Altrimenti, se nell’origine destra ci sono più record che corrispondono alla chiave di join dell’origine sinistra, solo uno di essi verrà estratto in modo casuale.
Esempio: Riprendiamo l’esempio di cui abbiamo parlato sopra. Abbiamo la stessa fonte di sinistra. Ma nella fonte giusta abbiamo queste righe:
| ID cliente | Soddisfazione (1-5) | ID posizione |
| 101 | 2 | 555 |
| 107 | 4 | 555 |
Nella join risultante, verrà salvata solo una delle 555 righe, ma non entrambe.
Se la chiave di join non è unica per ogni record di una sorgente destra e si desidera includere tutti i record della sorgente destra e di quella sinistra, è necessario utilizzare un’unione. I sindacati inseriscono ogni record separatamente invece di combinare le righe di informazioni.
Capire le giunzioni interne
Con un join interno, il set di dati risultante, unito, include solo le righe corrispondenti trovate in entrambi i set di dati. Poiché le join interne escludono i record mancanti da entrambe le origini dati, i set di dati risultanti tendono ad avere meno colonne vuote e l’ordine delle origini (sinistra o destra) è meno importante rispetto ad altri tipi di join.
Diciamo che queste tabelle rappresentano i dati che si possono trovare in ogni sondaggio
:Customer Reward Tier (Origine del SONDAGGIO)
| ID cliente | Nome | Livello di ricompensa |
| 101 | Phil Stein | Smeraldo |
| 102 | Amir Dar | Oro |
| 103 | Beth Green | Argento |
| 104 | Lucia Vasquez | Smeraldo |
Feedback sull’esperienza del negozio (Right Source)
| ID cliente | Soddisfazione (1-5) | Negozio |
| 101 | 1 | Provo |
| 104 | 3 | Provo |
| 113 | 5 | Scranton |
Si sceglie di unire i dati in base all’ID cliente. Questo campo è chiamato “chiave di collegamento”
Si tratta di tutti i dati di ciascuna fonte che verrebbero esclusi dal set di dati finale.
| ID cliente | Nome | Livello di ricompensa | Soddisfazione (1-5) | Negozio |
| 102 | Amir Dar | Oro | Nullo | Nullo |
| 103 | Beth Green | Argento | Nullo | Nullo |
| 113 | Nullo | Nullo | 5 | Scranton |
Questo è il risultato finale, ovvero tutti i dati che saranno inclusi nei risultati:
| ID cliente | Soddisfazione (1-5) | Nome | Negozio | Livello di ricompensa |
| 101 | 1 | Phil Stein | Provo | Smeraldo |
| 104 | 3 | Lucia Vasquez | Provo | Smeraldo |
Anche se queste fonti vengono unite per ID cliente, i clienti con ID 102, 103 e 113 vengono esclusi dal dataset finale perché mancano troppe informazioni. Solo Phil (101) e Lucia (104) hanno a disposizione i dati completi di entrambe le fonti.
Capire le giunzioni esterne complete
Con un join esterno completo, il set di dati risultante, unito, include tutte le righe di entrambi i set di dati. Mentre i record vengono abbinati e uniti in base alla chiave di unione, anche i record che mancano dei dati per la chiave di unione saranno inclusi nel set di dati finale.
Diciamo che queste tabelle rappresentano i dati che si possono trovare in ogni sondaggio
:Customer Reward Tier (Origine del SONDAGGIO)
| ID cliente | Nome | Livello di ricompensa |
| 101 | Phil Stein | Smeraldo |
| 102 | Amir Dar | Oro |
| 104 | Lucia Vasquez | Smeraldo |
| Nullo | Beth Green | Argento |
Feedback sull’esperienza del negozio (Right Source)
| ID cliente | Soddisfazione (1-5) | Negozio |
| 101 | 1 | Provo |
| 104 | 3 | Provo |
| 113 | 5 | Scranton |
Si sceglie di unire i dati in base all’ID cliente. Questo campo è chiamato “chiave di collegamento”
Questo è l’output finale, ovvero tutti i dati che saranno inclusi nei risultati.
| ID cliente | Soddisfazione (1-5) | Nome | Negozio | Livello di ricompensa |
| 101 | 1 | Phil Stein | Provo | Smeraldo |
| 102 | Nullo | Amir Dar | Nullo | Oro |
| 104 | 3 | Lucia Vasquez | Provo | Smeraldo |
| 113 | 5 | Nullo | Scranton | Nullo |
| Nullo | Nullo | Beth Green | Nullo | Argento |
Si noti che nessun dato è escluso. Anche Beth Green, a cui mancano i dati per l’ID cliente, è inclusa nei risultati. Se ci sono più righe di ID cliente nullo, ognuna di queste righe viene inclusa e rimane un record unico e separato.
Creazione di join
- Creare un modello di dati.
- Aggiungere almeno 2 fonti al modello di dati.
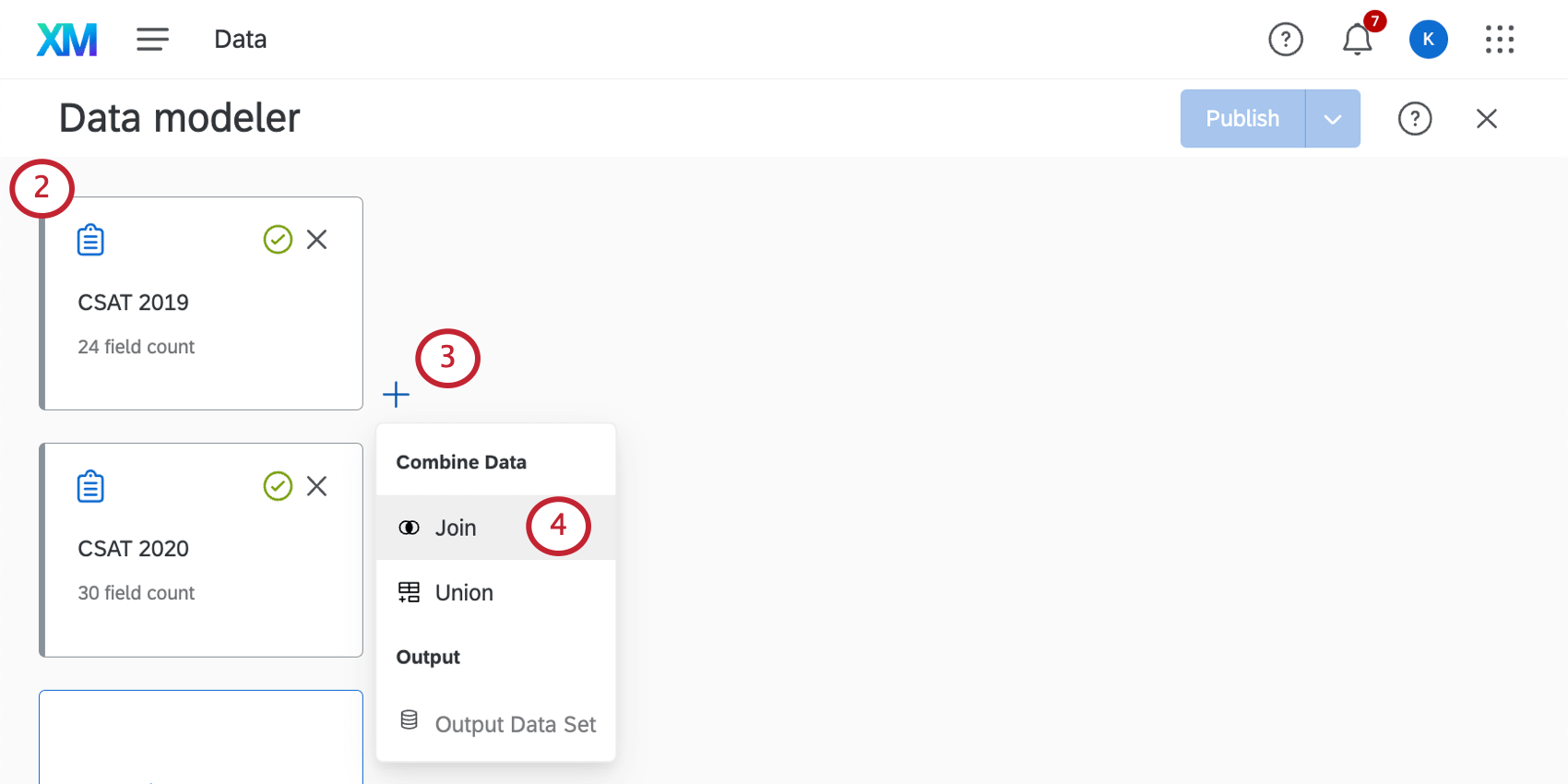 Consiglio Q: assicurarsi di includere tutti i campi necessari nelle Origini dati, compreso il campo comune che verrà utilizzato per unire i dati (ad esempio, un ID univoco).
Consiglio Q: assicurarsi di includere tutti i campi necessari nelle Origini dati, compreso il campo comune che verrà utilizzato per unire i dati (ad esempio, un ID univoco). - Fare clic sul segno più ( + ) accanto all’origine dati che si desidera utilizzare come origine dati sinistra.
- Selezionate Partecipa.
- Dare un nome all’uscita. È utile se si intende aggiungere più join al set di dati.
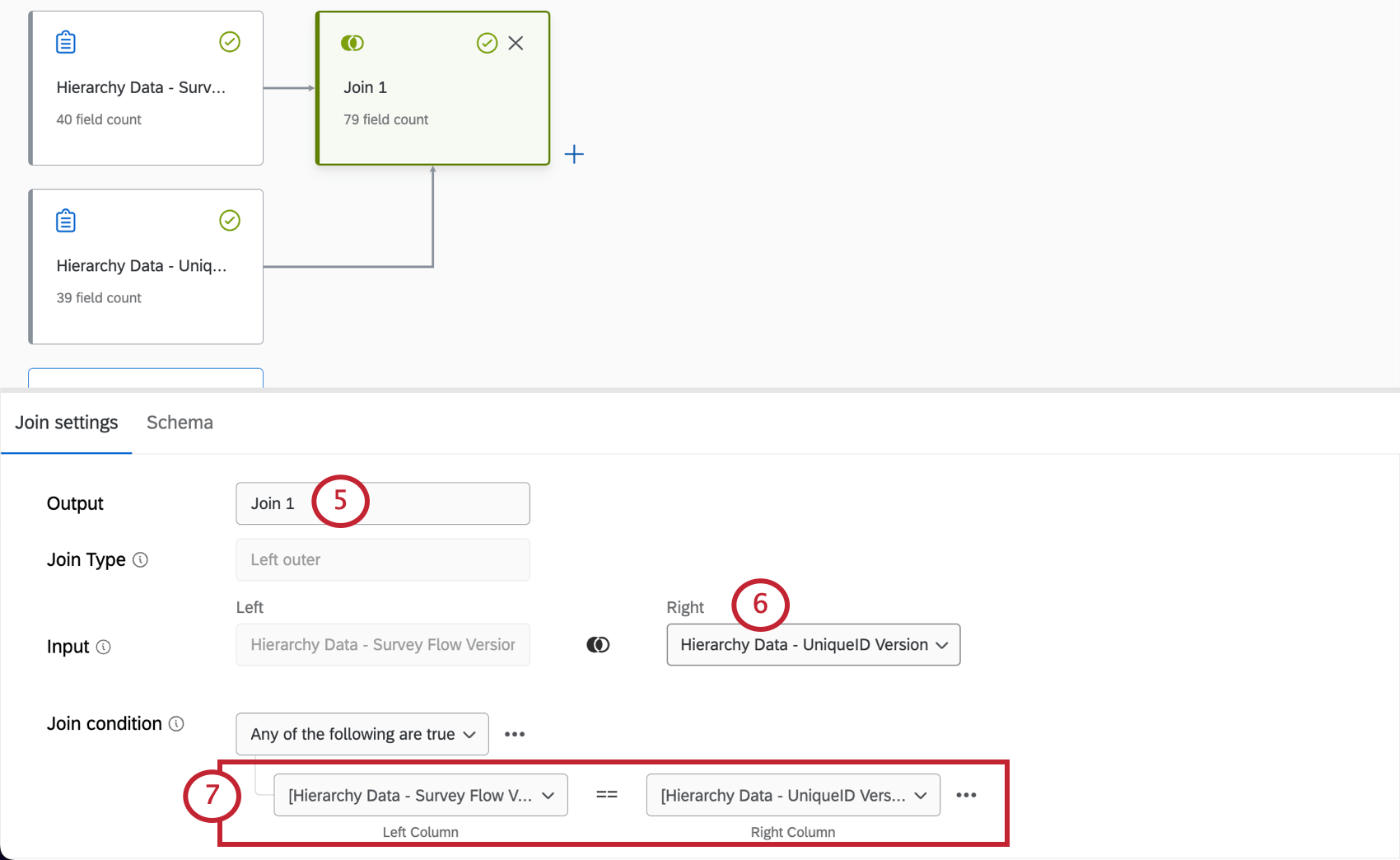
- In Input, selezionare l’origine dati Right.
- Creare una condizione di unione. Abbinare il campo che ogni set di dati ha in comune.
Esempio: Qui stiamo mappando il nostro campo Unique ID da ciascuna origine dati all’altra.Consiglio Q: Quasi tutti i tipi di campo possono essere utilizzati nelle serie di condizioni, ad eccezione dei campi Data e dei campi Serie di testo a risposta multipla. Si consiglia di utilizzare un identificatore unico che corrisponda a entrambe le origini dati.
- È possibile creare join separati nello stesso set di dati. In questa schermata, si uniscono i dati di 2022 SONDAGGIO e Actionability, ma non le prime due origini dati.
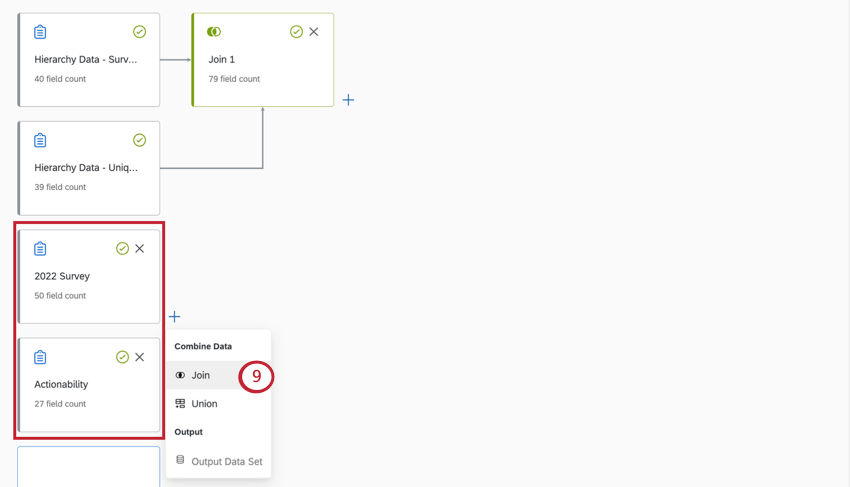
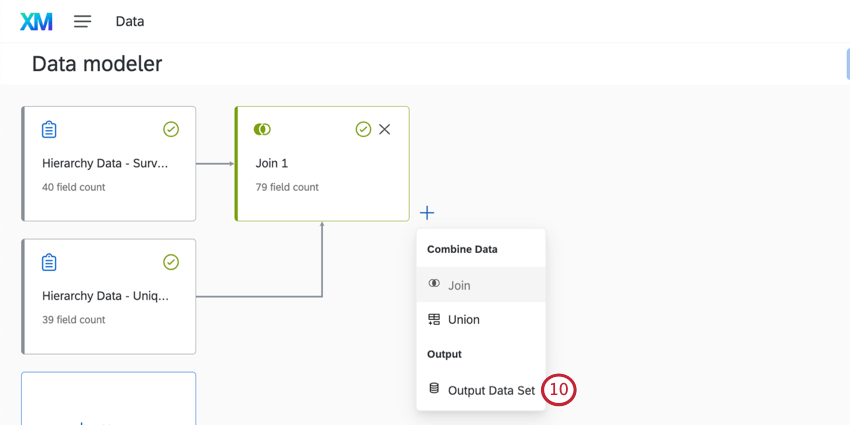
- Terminare la creazione del modello di dati con un set di dati di output.
Utilizzo delle giunzioni ausiliarie
I join ausiliari consentono di unire più fonti con la stessa condizione di join. Sono quindi utili quando si vogliono creare più join sovrapposti utilizzando le stesse origini dati.
Prima abbiamo spiegato come funzionano le giunzioni esterne a sinistra con due fonti: una fonte destra e una fonte sinistra. Le giunzioni ausiliarie consentono di impostare più sorgenti di sinistra per la stessa sorgente di destra in una giunzione.
Esempio di join ausiliario
Supponiamo di avere un database di sedi di negozi, con nomi collegati a ID. Avete 2 anni di sondaggi in cui raccogliete feedback sui vostri negozi. Nell’esempio seguente, troveremo l’indice di gradimento e l’ID cliente per il 2020 e il 2021 e li collegheremo a un nome di località.
Sedi dei negozi (fonte sinistra)
| ID posizione | Nome località |
| 555 | Provo |
| 777 | Dublino |
| 999 | Seattle |
| 1000 | Tokyo |
Feedback dei clienti 2020 (Right Source)
| ID cliente | Soddisfazione (1-5) | ID posizione |
| 101 | 2 | 555 |
| 102 | 4 | 777 |
| 103 | 5 | 999 |
| 104 | 5 | 222 |
Feedback dei clienti 2021 (fonte ausiliaria giusta)
| ID cliente | Soddisfazione (1-5) | ID posizione |
| 656 | 5 | 1000 |
| 838 | 4 | 222 |
| 979 | 3 | 999 |
| 343 | 5 | 777 |
Si uniscono i dati in base all’ID della località.
Questo è l’output finale, ovvero tutti i dati che saranno inclusi nei risultati:
| ID posizione | Nome località | 2020 ID cliente | 2020 Soddisfazione | 2021 ID cliente | 2021 Soddisfazione |
| 777 | Dublino | 102 | 4 | 343 | 5 |
| 1000 | Tokyo | N/D | N/D | 656 | 5 |
| 999 | Seattle | 103 | 5 | 979 | 3 |
| 555 | Provo | 101 | 2 | N/D | N/D |
Si noti come i dati del 2020 e del 2021 siano diventati colonneseparate nello stesso set di dati di output.
Poiché il 2020 non ha fornito dati per Tokyo, ma il 2021 sì, le colonne del 2020 sono vuote (N/A) per Tokyo. Allo stesso modo, il 2021 non aveva dati su Provo.
I record con l’ID della località “222” di entrambi gli anni sono stati esclusi dall’Origine dati finale, poiché il file delle ubicazioni dei punti vendita non aveva una località corrispondente a quell’ID. Per una spiegazione del modo in cui i dati vengono esclusi, si veda la sezione Comprendere le giunzioni esterne a sinistra.
Creazione di una giunzione ausiliaria
- Fare clic su unisci.
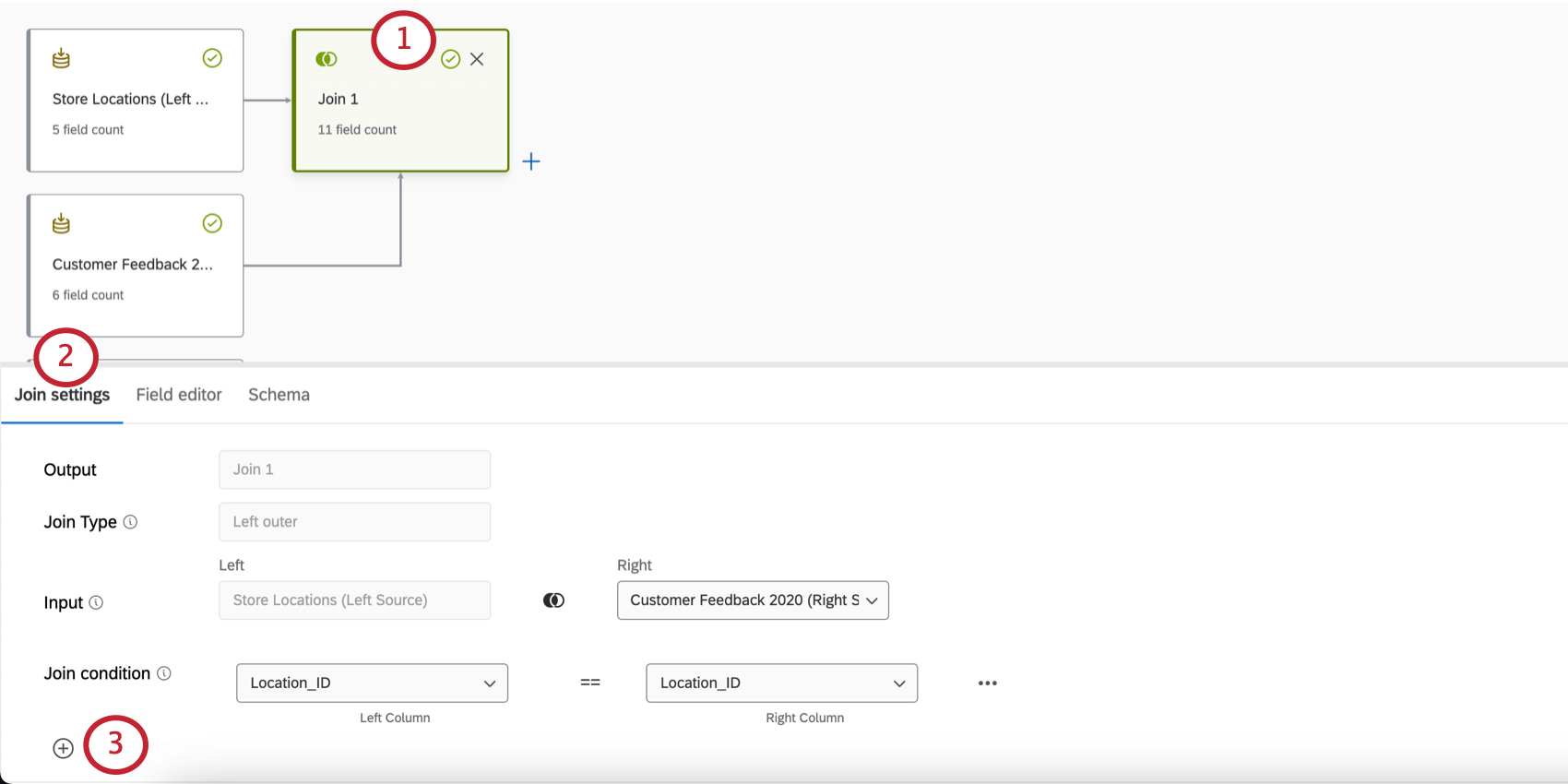
- Andare alle impostazioni di partecipazione.
- Fare clic sul segno più ( + ).
- Selezionare l’ingresso giusto.
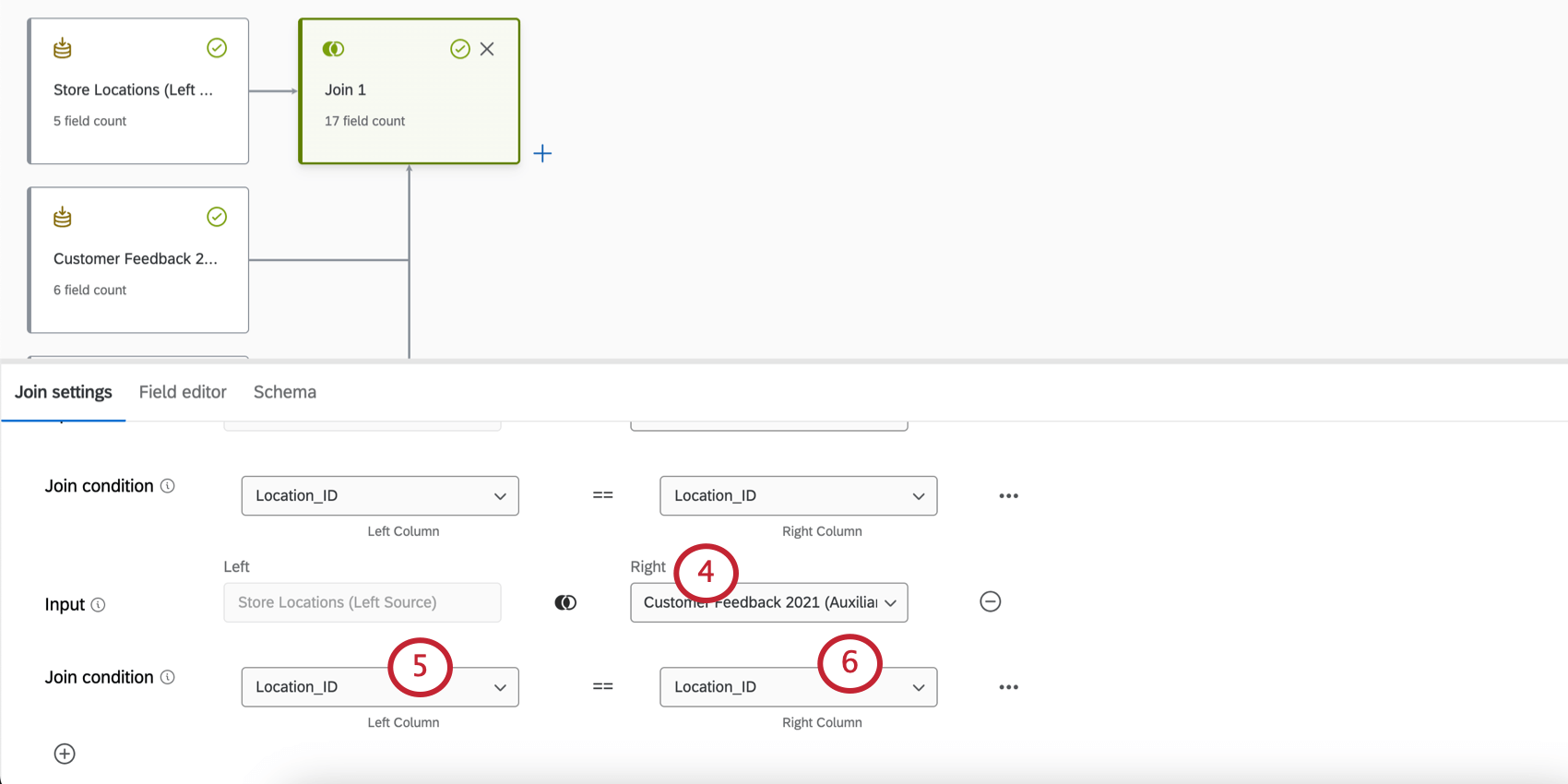 Esempio: Questa è la seconda sorgente che si vuole unire alla sorgente sinistra. Nell’esempio precedente, si tratta del sondaggio sul feedback dei clienti del 2021.
Esempio: Questa è la seconda sorgente che si vuole unire alla sorgente sinistra. Nell’esempio precedente, si tratta del sondaggio sul feedback dei clienti del 2021. - Impostare la condizione di unione della colonna sinistra.
- Impostare la condizione di unione della colonna destra.
Ripetere le operazioni necessarie per aggiungere altre giunzioni ausiliarie.
Risoluzione dei problemi di unione
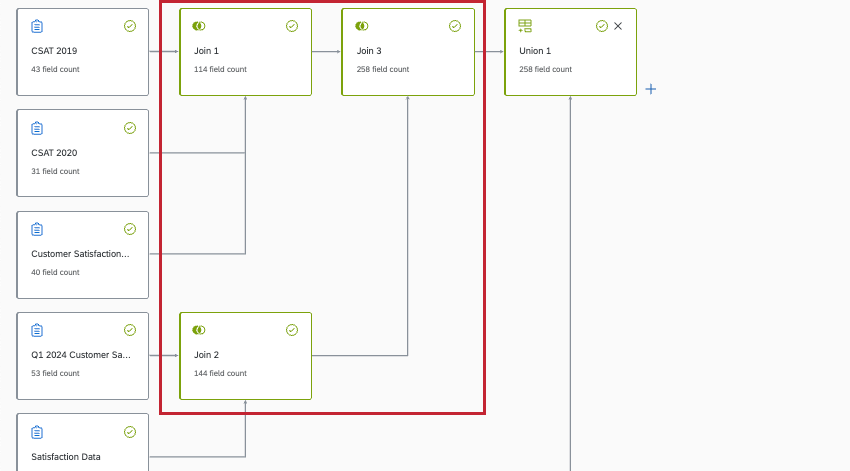
È possibile avere più join in un modello di dati. Tuttavia, è importante fare attenzione a come queste giunzioni interagiscono (o non interagiscono). I modelli di dati attualmente non supportano i join concatenati.
Un join concatenato è diverso da un join ausiliario. In una join concatenata, si crea una join con un’altra join al suo interno.
L’esempio seguente è un join ausiliario ed è supportato. Si noti come il join sia definito all’interno dello stesso singolo nodo, con fonti sovrapposte:
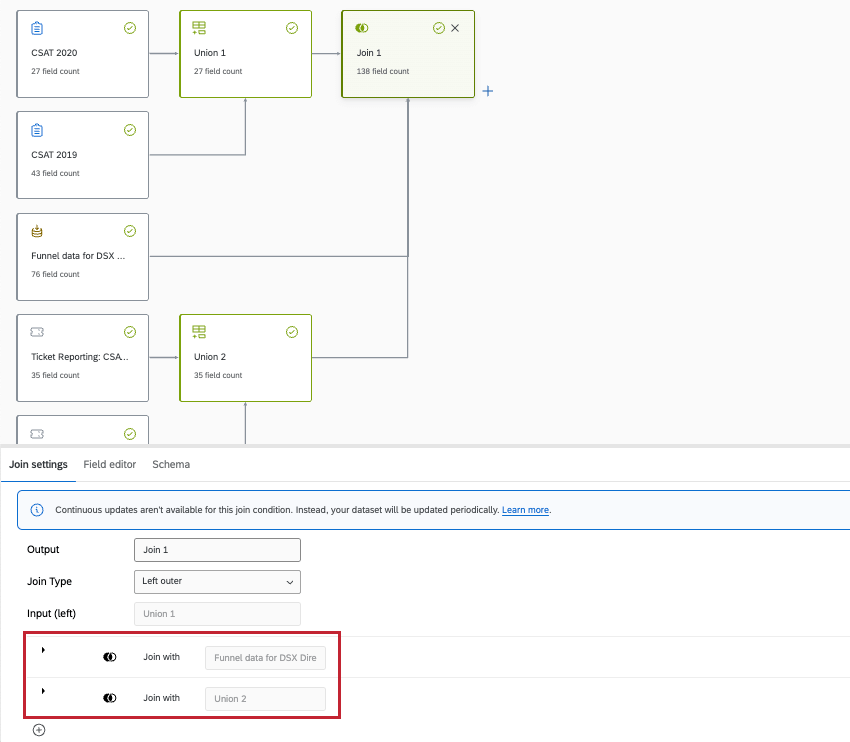
L’esempio seguente è un join concatenato e non è supportato. Si noti come ci siano join separati all’interno di altri join.