-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Comprendere il set di dati
Informazioni sul set di dati delle risposte
Per ulteriori analisi al di fuori di Qualtrics, è possibile scaricare un file di dati per qualsiasi sondaggio. Questo set di dati include tutti i dati grezzi delle risposte al sondaggio, che coprono ogni cosa, dalle risposte alle domande del sondaggio, fino a metadati aggiuntivi come durata e date, dati incorporati e altro ancora.
In questa pagina:
- Spiegheremo diverse colonne di informazioni che è possibile visualizzare nel file di dati.
- Spiegheremo il modo in cui le risposte possono essere formattate in questo file di dati, a seconda della colonna.
- Ci collegheremo ad altre risorse che ti consentono di comprendere o personalizzare il download dei dati.
Tuttavia, questa pagina tratta l’analisi statistica e non ti dà informazioni sul modo in cui interpretare i risultati dei tuoi dati, al di là della loro letteralità (ad es. questo intervistato ha contrassegnato il suo alto grado di soddisfazione). Ci sono tante variabili e progetti diversi all’interno della ricerca, e anche se ci piacerebbe dire che sappiamo tutto, dipende davvero dalle specifiche del tuo studio e dal modo in cui lo imposti!
Tipi di set di dati di risposte trattati in questa pagina
Questa pagina può aiutare a comprendere i dati grezzi esportati dai seguenti tipi di progetti:
Esistono altri tipi di progetti in cui è possibile esportare i dati delle risposte. Tuttavia, ci sono importanti differenze da tenere a mente:
- Per i progetti 360, vedere Comprendere il set di dati delle risposte (360).
- Per tutti gli altri progetti di Esperienza dei dipendenti, vedere Comprendere il set di dati delle risposte (EX).
Tecnicamente, anche i set di dati E ANALISI CONGIUNTA e MaxDiff sono formattati come descritto in questa pagina quando vengono esportati da Dati e analisi. Tuttavia, questa esportazione di dati esclude i dati specificidi Conjoint e MaxDiff.
Informazioni di base sul formato dei file
Ogni riga del file è una risposta diversa al sondaggio (anche se non ci sono necessariamente intervistati diversi, se lasci che le persone rispondano più volte). Ogni colonna è un tipo di dati del sondaggio.
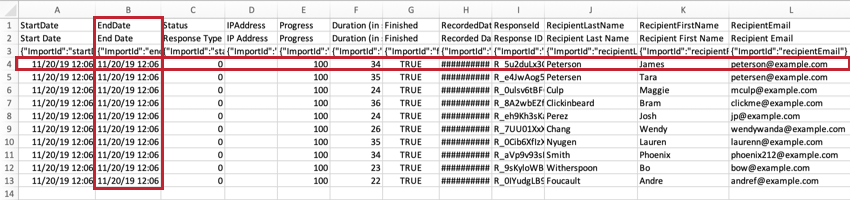
I file CSV e TSV contengono 3 righe di intestazioni. La prima intestazione è l’ID Qualtrics interno del campo (ad es. EndDate, Q1, Q2 e così via). La seconda intestazione è il nome o il testo del campo (ad es. Data di fine, Quanto sei soddisfatto/a di Qualtrics?). La terza intestazione contiene ID di importazione. Tutte e 3 queste intestazioni sono incluse perché sono necessarie per caricare i dati in un sondaggio. I dati dell’intervistato iniziano nella quarta riga del file.
Informazioni sull’intervistato
Le prime colonne di un set di dati includono informazioni su ogni intervistato e la relativa risposta, ad esempio il nome, l’indirizzo IP, le date di invio delle risposte, e così via. Qui riporteremo ognuna di queste colonne e il modo in cui comprenderne il contenuto.
Data di inizioQuesti
valori di data e ora indicano quando i rispondenti hanno cliccato per la prima volta sul collegamento al sondaggio.
Data fineQuesti
valori di data e ora indicano quando il rispondente ha inviato il sondaggio. Se la voce è una risposta incompleta, questa data indicherà l’ultima volta in cui l’intervistato ha interagito con il sondaggio.
StatoIl
valore della colonna Stato indica il tipo di risposta raccolta. Questi sono gli stati possibili, presentati sia in formato di valore che di etichetta:
- 0/Indirizzo IP: una risposta normale
- 1 / Anteprima SONDAGGIO: A anteprima delle risposte
- 2/Test del sondaggio: una risposta di prova
- 4 / Importato: An risposte importate
- 16 / Offline: A Applicazione Qualtrics offline risposta
- 17 / Anteprima offline: Le anteprime inviate tramite il programma Applicazione Qualtrics offline. Questa funzionalità è obsoleta nelle ultime versioni dell’app
Indirizzo IPQuesta
colonna include l’indirizzo IP del rispondente. Questi dati non saranno disponibili se le risposte sono state completamente anonimizzato.
DurataIl
numero di secondi impiegati dal rispondente per completare il sondaggio. Si tratta dell’intera durata della risposta; se un intervistato si ferma a metà del sondaggio, chiude il browser e ritorna un altro giorno, quel tempo viene conteggiato.
Finita e in corsoLa
colonna Finita indica se la risposta è stata inviata o chiusa. Un “1” o “VERO” indica che l’intervistato ha raggiunto un punto finale del proprio sondaggio (selezionando l’ultimo pulsante Avanti/Invia, venendo escluso con Salta o la logica di diramazione, ecc.). Uno “0” o “FALSO” indica che l’intervistato ha abbandonato il sondaggio prima di raggiungere un punto finale, e la risposta è stata invece chiusa manualmente o a causa della scadenza della sessione.
La colonna Progressi mostra i progressi compiuti dal rispondente nel sondaggio prima di terminarlo. Per quelli contrassegnati con “1” o “VERO” nella colonna Concluso, l’avanzamento viene contrassegnato con 100, indipendentemente dal fatto che siano stati esclusi. Per coloro le cui risposte sono contrassegnate con “0” o “FALSO”, ci sarà una percentuale esatta di completamento del sondaggio in base alla domanda in cui hanno abbandonato.
Data di registrazioneQuesta
colonna indica quando un sondaggio è stato registrato in Qualtrics. Per gli utenti che effettuano sondaggi online, questa data e ora saranno molto simili alla Data di fine. Tuttavia, per le risposte importate o caricate dall’app offline, la Data registrata sarà spesso diversa dalla Data di fine e riporterà il momento in cui i risultati sono stati caricati manualmente, non quando il partecipante al sondaggio ha terminato.
Consiglio Q: presenza di una differenza di diversi minuti tra la data di fine e la data registrata? Una connessione a Internet lenta può ritardare il tempo che intercorre tra l’invio dei dati del sondaggio da parte dell’intervistato e il salvataggio ufficiale di Qualtrics sul sito web.
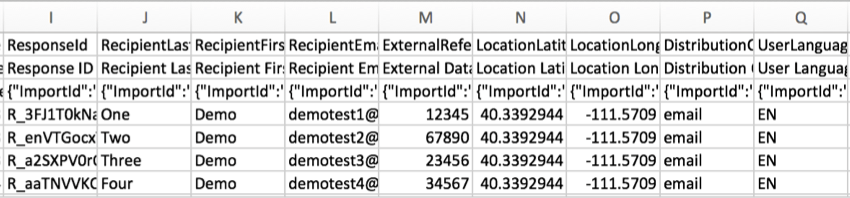
ResponseIDIl
ResponseID è l’ID che Qualtrics utilizza per identificare ogni risposta nel database. Questo identificatore univoco viene fornito come riferimento, e generalmente non è utilizzato nell’analisi dei dati.
CognomeDestinatario, NomeDestinatario e E-mailDestinatario
I nomi e gli indirizzi e-mail dei
rispondenti
vengono visualizzati in queste colonne se il sondaggio è stato distribuito tramite un elenco di contatti. Alcune delle distribuzioni comuni che utilizzano gli elenchi di contatti includono:
Per tutte le altre risposte, come quelle raccolte con un collegamento anonimo o con alcune Opzioni SONDAGGIO attivate, queste colonne saranno vuote. Tieni presente che qualsiasi distribuzione può essere resa anonima, indipendentemente dal metodo di distribuzione.
ExternalDataReferenceFrequentemente
usato quando si carica un file di tipo elenco dei contatti a Qualtrics per l’utilizzo in un autenticatore e, occasionalmente, in un e-mail distribuzione, è possibile includere un riferimento a dati esterni per ogni partecipante. Si tratta di un campo generico che consente di archiviare qualsiasi informazione desiderata (e viene spesso utilizzato per identificatori univoci come ID dipendente o studente). Se è stato aggiunto un riferimento a dati esterni all’elenco di contatti, verrà visualizzato in questa colonna. Se non hai scelto di utilizzare questo campo, la colonna sarà vuota.
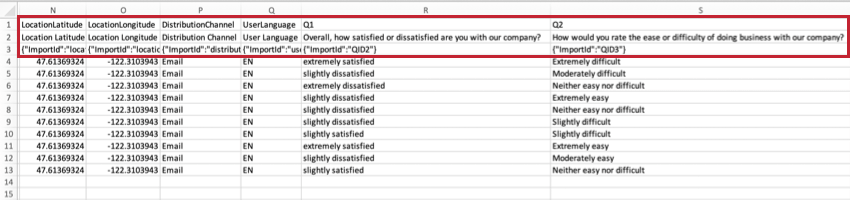
PosizioneLatitudine e PosizioneLongitudineSe
il rispondente ha compilato il sondaggio utilizzando il metodo Applicazione Qualtrics offline su un dispositivo abilitato al GPS, questi dati saranno una rappresentazione accurata della posizione dell’intervistato.
Per tutti gli altri intervistati, la posizione è un’approssimazione determinata mettendo a confronto l’indirizzo IP del partecipante con un database di localizzazione. Negli Stati Uniti, questi dati presentano generalmente un’accuratezza a livello di città. Al di fuori degli Stati Uniti, questi dati presentano generalmente un’accuratezza solo a livello di paese.
Questi dati non saranno disponibili se le risposte sono state completamente anonimizzate.
Canale di distribuzioneQuesta
colonna descrive il metodo di distribuzione del sondaggio.
Nell’esempio precedente, il sondaggio è stato inviato via e-mail ai partecipanti.
Lingua utenteSe
il sondaggio ha più lingue, il codice lingua del rispondente sarà visualizzato in questa colonna.
Anche se un sondaggio ha solo una lingua, ogni risposta deve avere i dati nella colonna UserLanguage, comprese le anteprime. L’unica eccezione è costituita dalle risposte di prova, che avranno una colonna UserLanguage vuota.
Risposte alla domanda
Le colonne avanti del dataset mostrano le risposte fornite per ogni domanda del sondaggio. Le colonne sono intestate con i numeri della domanda (ad es. Q1) e poi le righe iniziali del testo della domanda (ad es. quanto è stato facile capire le letture assegnate?).
Le domande semplici (Immissione di testo, SCELTA MULTIPLA – 1 risposta, ecc.) saranno contenute in 1 colonna, ma le domande più complesse con affermazioni multiple (tabella matrice, Affiancato, ecc.) saranno distribuite su più colonne.

Per impostazione predefinita, i dati vengono scaricati in etichette (cioè il testo esatto delle domande e delle risposte). Tuttavia, si può anche scegliere di esportarli come valori (chiamati “ricodifica valori“) per ogni scelta di risposta. Ad esempio, su una scala di 5 punti, “Completamente d’accordo” viene visualizzato come “5”, rendendo più semplice la possibilità di calcolare una media o eseguire altre analisi statistiche.
Se la codifica numerica delle scelte non corrisponde alle aspettative, è sempre possibile tornare alla scheda Sondaggio per modificarla ed esportare nuovamente i dati. È anche possibile esportare il sondaggio in Word per recuperare un libro dei codici che illustra come ogni scelta è codificata nel set di dati.
Guida ai tipi di domande specifici
I dati esportati appariranno spesso diversi, a seconda dei tipi di domanda che hai scelto di includere. Queste differenze vengono spiegate nella singola pagina della domanda. Qui di seguito i collegamenti alle relative sezioni.
- Scelta multipla (inclusa la modalità di visualizzazione delle esportazioni a risposta multipla)
- Tabella matrice
- Immissione di testo
- Campo modulo
- Cursore
- Ordine di classificazione
- Affiancato
- Somma costante
- Scelta, gruppo e classificazione; graduatoria
- Hot Spot
- Heat map
- Cursore grafico
- Menù a tendina
- Punteggio Net Promoter®
- Evidenzia testo
- Firma
- Tempistica
- Metainformazioni
- Carica file
Domande in Ripeti e unisci i blocchi
Quando vengono visualizzati i dati, ogni loop viene trattato come un set separato di domande. Se hai 5 possibili loop, vedrai le domande del loop ripetute 5 volte nei dati. Anche se a un intervistato non vengono mostrati tutti i loop, tutti i possibili loop verranno rappresentati nei dati.
Risultati punteggio
Per i sondaggi che utilizzano il Punteggio, il punteggio per ogni categoria è incluso nel set di dati. Ogni categoria di punteggio ha la propria colonna di dati. Nell’esempio seguente, il sondaggio aveva solo una categoria punteggio, chiamata “Leggibilità”
Questo punteggio è una somma dei punti guadagnati dall’intervistato nella categoria, non una media.
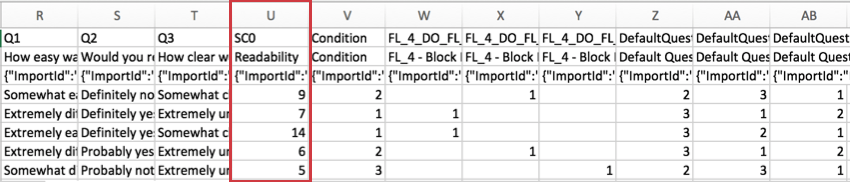
“SC” nell’intestazione sta per “Categoria di punteggio” e il numero rappresenta la categoria di numero, contando a partire da zero. Poiché l’esempio di sondaggio di cui sopra ha una sola categoria di punteggio, vediamo SC0, ma se ce ne fossero di più, vedremmo SC1, SC2 e così via.
Dati incorporati
Per i sondaggi che utilizzano dati integrati, le informazioni sui dati integrati sono incluse nelle colonne successive alle informazioni sul punteggio.
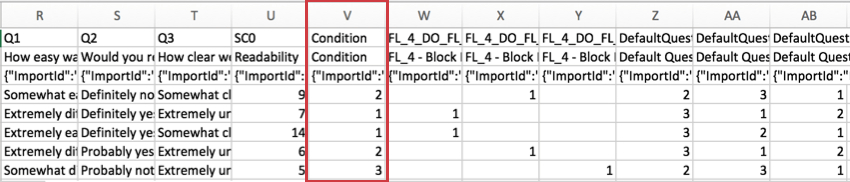
Solo i campi dati incorporati salvati nel flusso del sondaggio sono inclusi nel set di dati scaricato. I campi dati incorporati con valori provenienti da un elenco di contatti o da un URL possono essere salvati nel flusso del sondaggio in qualsiasi momento prima o dopo la raccolta dei dati.
Dati di randomizzazione
Vedrai le colonne di randomizzazione dopo i dati della risposta alle domande. Sarà presente una colonna per ogni elemento randomizzato nel sondaggio. Ad esempio, se si randomizza un blocco con 5 domande, si avranno 5 colonne, 1 per ogni domanda. Se nel flusso del sondaggio ci fosse un randomizzatore con 7 elementi sotto di esso, si avrebbero 7 colonne, 1 per ogni elemento randomizzato.
Se randomizzi l’ordine di tutti gli elementi presentati, la colonna mostrerà l’ordine in cui l’elemento è stato presentato, ad esempio 1, 2, 3 e così via.
Esempio: Nello screenshot sottostante, l’ordine delle domande è stato randomizzato e le colonne mostrano l’ordine in cui ogni domanda è apparsa nella sequenza. Tieni presente che i numeri delle domande sono nelle intestazioni.

Quando si presenta casualmente 1 elemento da una lista di più elementi, gli elementi che sono stati visualizzati saranno contrassegnati come 1. Gli elementi che non sono stati visualizzati dal randomizzatore saranno vuoti.
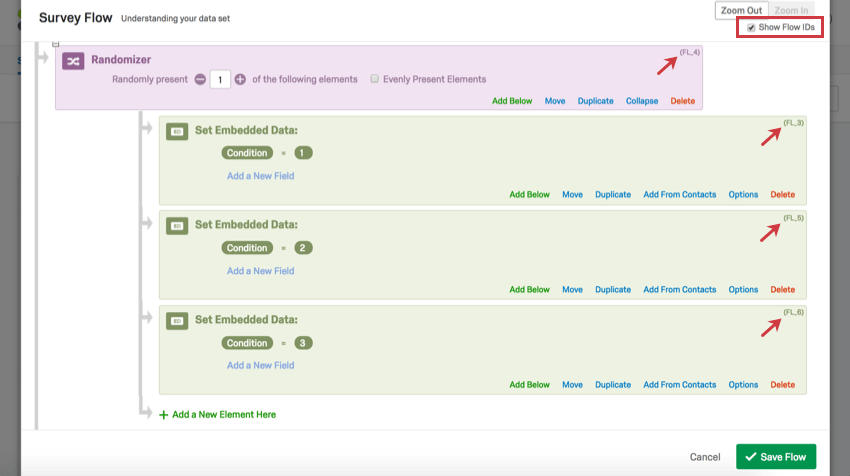
Esempio: Nell’esempio seguente, è stato presentato a caso 1 elemento da una lista di 3. Le colonne indicano quale elemento è stato mostrato all’intervistato mettendo un 1 sotto la colonna con l’etichetta dell’elemento presentato.
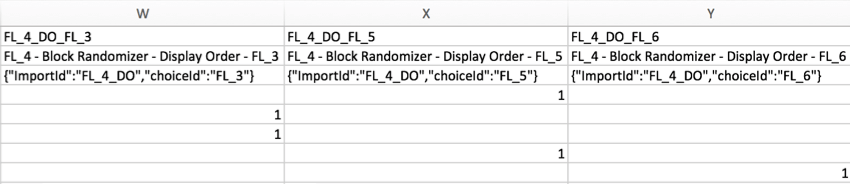
Consiglio Q: sei confuso sul modo in cui leggere le intestazioni nel secondo esempio? Poiché in questo esempio è stato utilizzato il randomizzatore del flusso del sondaggio, la colonna mostra gli ID del flusso invece degli ID della domanda. È possibile recuperare gli ID del flusso andando al flusso del sondaggio e selezionando Mostra ID del flusso nell’angolo in alto a destra. Gli ID del flusso non possono essere modificati.
Risoluzione dei problemi relativi a un file di dati
Questa sezione analizzerà alcune delle domande e dei dubbi comuni a molti utenti in merito al loro file di dati. Inoltre, evidenzieremo alcune funzionalità utili che è possibile utilizzare per personalizzare le esportazioni dei dati.
Guida all’esportazione dei dati e a tutte le opzioni disponibili
Per istruzioni su come esportare i dati, consulta le seguenti pagine di supporto:
- Esportazione dei dati di risposta: istruzioni e consigli dettagliati.
- Opzioni di esportazione dei dati: Guida alle opzioni aggiuntive, come l’esportazione di dati randomizzati, l’etichettatura delle domande viste ma senza risposta, l’esportazione in formato valore o etichetta e così via.
- Formati di esportazione dei dati: guida ai diversi tipi di file che è possibile esportare.
Personalizzazione delle colonne incluse nell’esportazione
Per personalizzare le colonne delle esportazioni,
- Scegliere le colonne che si desidera esportare e deselezionare quelle che non si desidera esportare.
- Esporta i dati con l’opzione Scarica tutti i campi deselezionata.
Esportazione dei dati filtrati
Per esportare i dati filtrati,
Funzionalità che non hanno dati da includere in un’esportazione
Se si è incluso un testo descrittivo (ad esempio un paragrafo introduttivo senza domanda allegata) o un grafico (ad esempio un’immagine senza domanda allegata), questi campi non avranno una propria colonna nell’esportazione dei dati, poiché non hanno risposte che il rispondente possa selezionare. Se hai notato che i numeri di domanda sono stati “ignorati” nell’esportazione del sondaggio, potrebbe essere perché sono presenti campi come questo inclusi.
Tuttavia, se hai randomizzato la visualizzazione dei campi grafici o di testo descrittivo da parte degli intervistati, puoi trovare questi dati esportando i dati randomizzati. Consulta Esportazione di dati randomizzati per istruzioni dettagliate, e consulta Dati di randomizzazione per una guida su come leggere il risultato.
Alcune scelte di risposta escluse dal file/Modalità di esclusione dei valori dall’analisi
Vedere Escludere dall’analisi. Alcuni valori, in base alla loro formulazione, vengono esclusi per impostazione predefinita. Queste risposte vengono registrate e possono essere aggiunte nuovamente ai dati in qualsiasi momento senza problemi.
Dati incorporati esclusi dal file
Assicurarsi che l’elemento di dati integrati sia aggiunto al flusso del sondaggio e che venga inserito in tutti i campi dei contatti.
Per una risoluzione dei problemi più approfondita con i dati incorporati, consulta le pagine di supporto collegate.
Altri campi esclusi dal file
Assicurarsi di aver selezionatoScarica tutti i campi quando si esportano i dati. I dati randomizzati non sono inclusi per impostazione predefinita, ma possono essere aggiunti in base a queste istruzioni.
Vedere ulteriori opzioni di esportazione.
Personalizza numeri delle domande
Vedere Numerazione automatica delle domande e Numeri di domanda.
Personalizza la formulazione della domanda o della risposta nell’esportazione dei dati, ma non il sondaggio
È possibile utilizzare le etichette delle domande per modificare la formulazione delle domande stesse nell’esportazione, senza influenzare il modo in cui le domande appaiono ai partecipanti al sondaggio. È possibile utilizzare nomi delle variabili per modificare la formulazione delle scelte delle risposte. È possibile modificare le etichette delle domande e i nomi delle variabili in qualsiasi momento durante la raccolta dei sondaggi.
Anche le etichette delle domande e i nomi delle variabili influiscono sulla visualizzazione dei dati nei risultati e nei rapporti.
La composizione delle domande/risposte differisce dall’editor del sondaggio
Se la formulazione delle domande è diversa da quella visualizzata nell’editor del sondaggio, verificare che non siano state aggiunte etichette alle domande. Se la formulazione delle tue risposte è diversa da quella visualizzata nell’editor del sondaggio, controlla i nomi delle variabili sotto le opzioni di ricodifica. Se si è creato il sondaggio da una copia di una versione precedente, queste impostazioni possono essere riportate. È possibile modificare le etichette delle domande e i nomi delle variabili in qualsiasi momento durante la raccolta dei sondaggi.
Problemi di esportazione CSV
Se l’esportazione CSV non ha un aspetto corretto (ad esempio, presenta simboli al posto del testo previsto o colonne che si sovrappongono), esportare i dati in formato TSV. TSV è particolarmente utile per i dati che contengono caratteri speciali.
Per ulteriori informazioni sulla risoluzione dei problemi, vedere Problemi con i file CSV scaricati.
File di risposta da progetti 360, Engagement (Coinvolgimento dei dipendenti), Lifecycle (Ciclo di vita dei dipendenti) e Ad Hoc Employee Research (Ricerca ad hoc per i dipendenti)
Per 360, vedere Comprendere il set di dati delle risposte (360).
Per tutti gli altri progetti EX, vedere Understanding Your Response Dataset (EX).
Differenze di formato del file
Sebbene tutti i tipi di file eseguano il download degli stessi campi dati descritti sopra, ognuno presenta un layout che potrebbe essere leggermente diverso.
SPSSLa
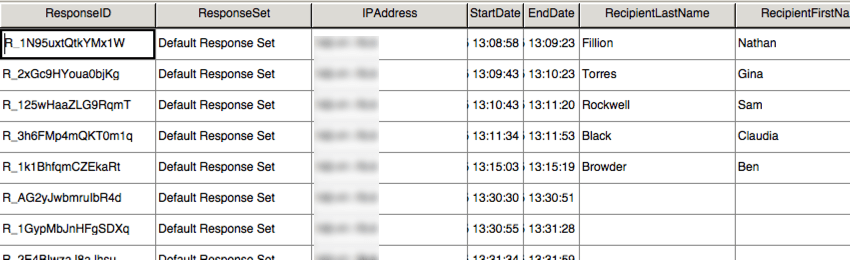
Vista dati in SPSS include lo stesso identico layout del file CSV, con meno intestazioni.
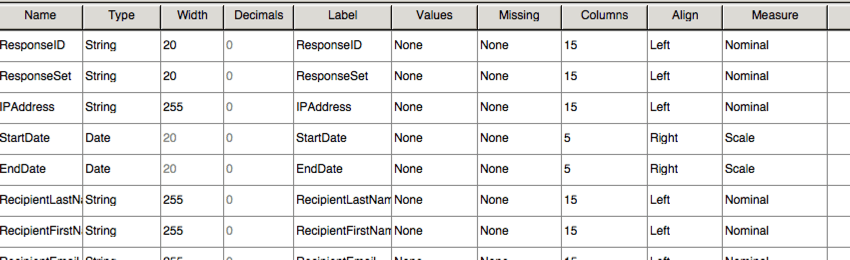
SPSS comprende un’altra vista, denominata Vista variabile. Questa vista elenca tutte le variabili del set di dati con le relative informazioni, ad esempio il tipo di variabile e i valori possibili.
XMLIl
tipo di file XML viene spesso utilizzato quando si integrano i dati di Qualtrics con un database di terze parti. Questo tipo di file può essere facilmente analizzato dal software del database comune.
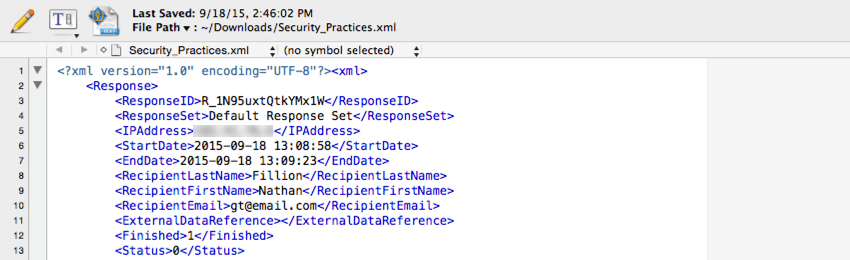
Per ogni risposta viene fornito un elemento XML, con un elemento figlio per ogni dato memorizzato nella risposta.