Guida di facile consultazione alla regressione logistica
Cosa puoi trovare in questa pagina
Che cos’è la regressione logistica?
La regressione logistica stima una formula matematica che mette in relazione una o più variabili di input con una variabile di output.
Per esempio, diciamo che gestite un chiosco di limonate e siete interessati a sapere quali tipi di clienti tendono a tornare. I dati includono una voce per ogni cliente, il suo primo acquisto e se è tornato il mese avanti per acquistare altra limonata. I dati potrebbero assomigliare a questi:
| Restituisci | Età del cliente | Il sesso | Temperatura al primo acquisto | Colore della limonata | Lunghezza dei pantaloni |
|---|---|---|---|---|---|
| Non | 21 | Maschio | 24 | Rosa | Pantaloncini |
| Restituito | 34 | Femmina | 20 | Giallo | Pantaloncini |
| Restituito | 13 | Femmina | 25 | Rosa | Pantaloni |
| Non | 25 | Femmina | 27 | Giallo | Abito |
| ecc. | ecc. | ecc. | ecc. | ecc. | ecc. |
Pensate che “Età del cliente” (una variabile di inputo esplicativa) possa avere un impatto su “Rendimento” (una variabile di outputo di risposta). La regressione logistica potrebbe dare questo risultato
: a 12 anni (l’età più bassa), la probabilità che il ritorno sia “restituito” è del 10%.
Per ogni anno in più di età, il “ritorno” è 1,1 volte maggiore
Questa conoscenza è utile per due motivi.
In primo luogo, consente di comprendere una relazione: i clienti più anziani hanno maggiori probabilità di tornare. Questa intuizione potrebbe indurvi a orientare la vostra pubblicità verso i clienti più anziani, poiché è più probabile che diventino clienti abituali.
In secondo luogo, e in modo correlato, può anche aiutare a fare previsioni specifiche. Se passa un cliente di 24 anni, si può stimare che se acquista una limonata, c’è il 26% di possibilità che diventi un cliente di ritorno.
Comprendere la moltiplicazione delle probabilità
Si noti che se diciamo che il “ritorno” è “1,5 volte più probabile” in una certa situazione che in un’altra, stiamo facendo quanto segue
: le probabilità erano 1:9, scritto anche 1/(1+9) = 10%.
La “probabilità per” (l’1) è moltiplicata per 1,5.
Ora 1,5:9, scritto anche 1,5/(1,5+9) = 14%.
Un altro esempio, questa volta di passaggio da una probabilità del 50% a qualcosa di 3 volte più probabile
: le probabilità erano 1:1, scritto anche 1/(1+1) = 50%.
La “probabilità per” (il lato sinistro 1) viene moltiplicata per 3.
Ora 3:1, scritto anche 3/(3+1) = 75%.
Ora esamineremo il processo di creazione di questo modello di regressione.
Preparazione alla creazione di un modello di regressione
1. Pensate alla teoria della vostra regressione.
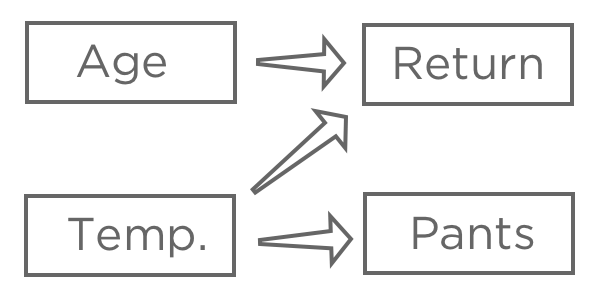
Una volta scelta una variabile di risposta, “Entrate“, ipotizzate come i vari input possano essere correlati ad essa. Ad esempio, potreste pensare che una “Temperatura al primo acquisto” più alta comporti una maggiore probabilità di “Restituzione”, potreste non essere sicuri di come l'”Età” influisca sulla “Restituzione” e potreste credere che i “Pantaloni”(rispetto ai pantaloncini) siano influenzati dalla “Temperatura” ma non abbiano alcun impatto sul vostro chiosco di limonate.
{kind=link}

L’obiettivo della regressione è tipicamente quello di capire la relazione tra diversi input e un output, quindi in questo caso probabilmente si deciderà di creare un modello che spieghi il “rendimento” con la “temperatura”e l'”età”(detto anche “prevedere il rendimento dalla temperatura e dall’età” ,anche se si è più interessati alla spiegazione che alla previsione vera e propria).
Probabilmente non includereste “Pantaloni” nella vostra regressione. Potrebbe essere correlato al “Ritorno” perché entrambi sono legati alla “Temperatura”, ma non viene prima del “Ritorno” nella catena causale, quindi includerlo confonderebbe il modello.
2. “Descrivere tutte le variabili che potrebbero essere utili per il modello.
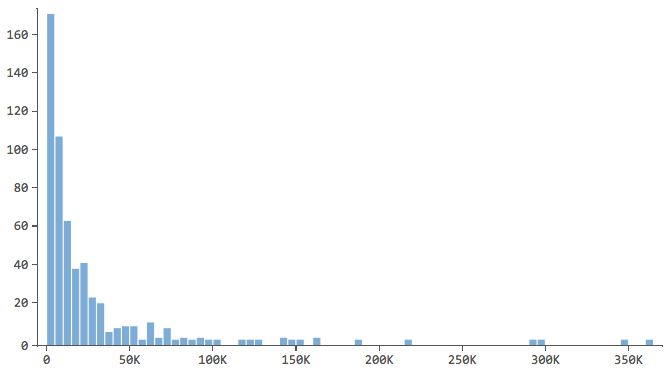
Cominciate a descrivere la variabile di risposta, in questo caso “entrate”, e a farvi un’idea della stessa. Fate lo stesso per le variabili esplicative.
Nota che hanno una forma come questa..
{kind=link}

… dove la maggior parte dei dati si trova nei primi bins dell’istogramma. Queste variabili richiederanno un’attenzione particolare in seguito.
3. “Mettere in relazione tutte le possibili variabili esplicative con la variabile di risposta.
Stats iQ ordina i risultati in base alla forza della relazione statistica. Date un’occhiata e fatevi un’idea dei risultati, notando quali variabili sono correlate alle “Entrate” e in che modo.
4. Iniziare a costruire la regressione.
La costruzione di un modello di regressione è un processo iterativo. Passerete attraverso le tre fasi seguenti tutte le volte che sarà necessario.
Le tre fasi di costruzione di un modello di regressione
Fase 1: Aggiungere o sottrarre una variabile.
Uno alla volta, iniziate ad aggiungere le variabili che le vostre analisi precedenti indicavano essere correlate al “Revenue”(o aggiungete le variabili che avete una ragione teorica per aggiungere). Non è strettamente necessario procedere uno per uno, ma in questo modo è più facile identificare e risolvere i problemi man mano che si procede e ci si può fare un’idea del modello.
Supponiamo di iniziare prevedendo “Entrate” con “Temperatura” Trovate una relazione forte, valutate il modello e lo ritenete soddisfacente (maggiori dettagli tra un minuto).
Return <- TemperatureSi
aggiunge poi “Colore della limonata” e ora il modello di regressione ha due termini, entrambi predittori statisticamente significativi. In questo modo
: Entrate <- Temperatura & Colore della limonataPoi
si aggiunge “Sesso” e i risultati del modello mostrano che “Sesso” è statisticamente significativo nel modello, ma “Colore della limonata” non lo è più. In genere si rimuove il “colore Lemonade” dal modello. Ora abbiamo
:Entrate <- Temperatura & SessoOvvero
, se si conosce il sesso del cliente, sapere quale colore di limonata ha ordinato non fornisce ulteriori informazioni sul fatto che sarà un cliente di ritorno.
Potreste indagare e scoprire che le donne tendono a scegliere la limonata gialla più degli uomini e che le donne sono più propense a tornare. Inizialmente sembrava che la scelta del giallo rendesse più probabile il ritorno del cliente, ma in realtà il “colore della limonata” è correlato al “ritorno” solo attraverso il “sesso” Pertanto, quando si include il “sesso” nella regressione, il “colore della limonata” esce dalla regressione.
L’interpretazione dei risultati della regressione richiede una buona dose di giudizio e il fatto che una variabile sia statisticamente significativa non significa che sia effettivamente causale. Ma aggiungendo e sottraendo con attenzione le variabili, notando come cambia il modello e pensando sempre alla teoria che sta alla base del modello, è possibile individuare relazioni interessanti nei dati.
Fase 2: Assessment del modello.
Ogni volta che si aggiunge o si sottrae una variabile, si deve valutare l’accuratezza del modello esaminando il suo r-quadro (R2), l’AICc e gli eventuali avvisi di Stats iq. Ogni volta che si modifica il modello, confrontare i nuovi valori di r-squared, AICc e diagrammi diagnostici con quelli precedenti per determinare se il modello è migliorato o meno.
Quadro R (R2)
La metrica numerica per quantificare l’accuratezza della previsione del modello è nota come r-squared, che è compresa tra zero e uno. Uno zero significa che il modello non ha alcun valore predittivo, mentre un uno significa che il modello predice perfettamente tutto.
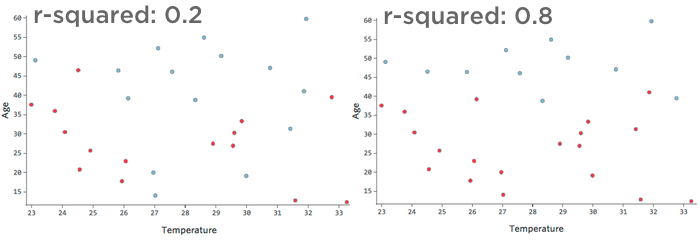
Ad esempio, i dati rappresentati a sinistra porteranno a un modello molto meno accurato di quello rappresentato a destra. Immaginate di provare a tracciare una linea attraverso il diagramma di dispersione; potreste separare quasi completamente il blu (“Ritornato”) dal rosso (“Non”) sul lato destro, ma sul lato sinistro sarebbe difficile farlo.
Cioè, il lato destro ha un elevato valore di r-quadrato; se si conoscono la “Temperatura” e l'”Età”, è possibile determinare il “Reso” rispetto al “Reso”. “Non” abbastanza facilmente. Il lato sinistro ha un valore medio-basso di r-squared; se si conoscono la “Temperatura” e l'”Età”,si può indovinare abbastanza bene se sarà “Restituito” o meno. “Non l’ho fatto”, ma ci saranno molti errori.
{kind=link}

Non esiste una definizione fissa di un “buon” r-squared. In alcuni contesti potrebbe essere interessante vedere qualsiasi effetto, mentre in altri il modello potrebbe essere inutile, a meno che non sia molto accurato.
Ogni volta che si aggiunge una variabile, l’r-squared aumenterà, quindi l’obiettivo non è raggiungere l’r-squared più alto possibile; piuttosto, si vuole bilanciare l’accuratezza del modello (r-squared) con la sua complessità (in genere, il numero di variabili in esso contenute).
AICc
L’AICc è una metrica che bilancia l’accuratezza con la complessità: una maggiore accuratezza porta a punteggi migliori e una maggiore complessità (più variabili) porta a punteggi peggiori. Il modello con l’AICc più basso è migliore.
Si noti che la metrica AICc è utile solo per confrontare gli AICc di modelli che hanno lo stesso numero di righe di datiela stessa variabile di output.
Avvisi
Di tanto in tanto Stats iQ vi suggerirà come migliorare il vostro modello. Ad esempio, Stats iQ può suggerire di prendere il logaritmo di una variabile(per maggiori dettagli su cosa significa).
Matrice di confusione e curva di precisione-ricaduta
Anche la matrice di confusione e la curva precisione-richiamo sono strumenti utili per comprendere l’accuratezza del modello. E se volete fare previsioni basate sul vostro modello, questi strumenti vi aiuteranno a farlo. Non sono strettamente necessari per comprendere bene ciò che il vostro modello vi sta dicendo, quindi li abbiamo inseriti in un’altra sezione dedicata alla matrice di confusione e alla curva di precisione-richiamo
Fase 3: modificare il modello di conseguenza.
Se l’Assessment del modello è soddisfacente, il gioco è fatto oppure si può tornare alla Fase 1 e inserire altre variabili.
Se l’assessment rileva delle carenze nel modello, utilizzerete gli avvisi di Stats iQ per risolvere i problemi.
Man mano che si modifica il modello, si devono osservare le variazioni di r-squared, AICR e diagnostica dei residui e decidere se le modifiche apportate stanno aiutando o danneggiando il modello.
FAQs
Come posso creare una nuova variabile Stats iQ?
Come posso creare una nuova variabile Stats iQ?
Quali sono le opzioni per analizzare i miei dati in Stats iQ?
Quali sono le opzioni per analizzare i miei dati in Stats iQ?
- Descrivi: selezionando una variabile dall'elenco e facendo clic su Describe potrai visualizzare i dati contenuti in quella variabile. Da utilizzare quando si desidera vedere come vengono distribuiti i dati per una determinata variabile.
- Correla: selezionando due variabili e facendo clic su Correla verrà eseguita un'analisi statistica della relazione tra le due variabili. Da utilizzare quando si desidera conoscere l'intensità della correlazione tra due variabili.
- Tabella pivot: selezionando due o più variabili e facendo clic su Tabella pivot verrà creata una tabella che visualizza i valori delle variabili come righe e colonne. Le celle possono essere impostate in modo da visualizzare una serie di informazioni diverse, tra cui la percentuale di colonne e righe, la somma e lo scostamento. Da utilizzare quando si desidera confrontare la sovrapposizione tra valori specifici di un insieme di variabili.
- Regressione: selezionando due variabili e facendo clic su Regressione si otterrà la relazione matematica tra le variabili. Da utilizzare quando si desidera prevedere i valori di una variabile in base ai valori di un'altra.
- Cluster: selezionando da due a dieci variabili demografiche e facendo clic su Cluster verranno visualizzati raggruppamenti di tratti che più probabilmente si verificheranno insieme, rivelando così i segmenti di popolazione catturati nei tuoi dati.
Non so cosa significhi questo termine statistico. Me lo puoi dire?
Non so cosa significhi questo termine statistico. Me lo puoi dire?
- Test statistici: ANOVA, T-test e Chi-quaded sono tutti test statistici che Stats iQ esegue per verificare se la relazione tra due variabili è significativa o meno. Questi test sono utilizzati per generare un P-Value.
- Valore P: questo valore rappresenta la probabilità che i risultati osservati siano visti se non esiste alcuna correlazione tra le variabili. Un P-Value inferiore significa dati più correlati.
- Dimensione dell'effetto: la dimensione dell'effetto è una misura di quanto grande sia la correlazione tra due variabili. Ciò viene misurato in modi diversi a seconda del tipo di test statistico eseguito. Esempi sono Cohen’s d, Pearson’s r, e Cramer’s v. Maggiore è il valore della dimensione dell'effetto, più le variabili sono correlate.
Come posso filtrare i dati visualizzati in Stats iQ?
Come posso filtrare i dati visualizzati in Stats iQ?
Come faccio a far comparire le mie nuove risposte in Stats iQ?
Come faccio a far comparire le mie nuove risposte in Stats iQ?
Come vengono ordinate le schede di analisi nel mio workspace Stats iQ?
Come vengono ordinate le schede di analisi nel mio workspace Stats iQ?
Che cos'è Stats iQ? / Dov'è Statwing?
Che cos'è Stats iQ? / Dov'è Statwing?
Cosa fare se i dati non vengono caricati correttamente?
Cosa fare se i dati non vengono caricati correttamente?
È fantastico! Grazie per il tuo feedback!
Grazie per il tuo feedback!