-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Guida di facile consultazione alla regressione lineare
Che cos’è la regressione?
La
regressione stima una formula matematica che mette in relazione una o più variabili di input con una variabile di output.
Per esempio, diciamo che gestite un chiosco di limonate e siete interessati a capire quali sono gli elementi che determinano le entrate. I dati includono le “Entrate” di ogni giorno, la “Temperatura” elevata, il “Numero di bambini che sono passati”, il “Numero di adulti che sono passati”, la “Segnaletica” utilizzata quel giorno e le “Entrate di un concorrente” vicino
| Reddito | Temperatura (Celsius) | Minuti di pausa | Numero di bambini che hanno camminato | Numero di adulti che hanno camminato | Segnaletica | Ricavi della concorrenza |
|---|---|---|---|---|---|---|
| 44 $ | 28,2 | 30 | 43 | 380 | Dipinto a mano | $20 |
| 23 $ | 21,4 | 42 | 28 | 207 | LED | 30 $ |
| 43 $ | 32,9 | 14 | 43 | 364 | Dipinto a mano | $34 |
| 30 $ | 24,0 | 24 | 18 | 103 | LED | $15 |
| ecc. | ecc. | ecc. | ecc. | ecc. | ecc. | ecc. |
Pensate che “Temperatura” (una variabile di inputo esplicativa) possa avere un impatto su “Ricavi” (una variabile di outputo di risposta). Quando si usa la regressione per analizzare questa relazione, si può ottenere la seguente formula
: Entrate = 2,71 * Temperatura – 35Questa
formula è utile per due motivi.
In primo luogo, permette di comprendere una relazione: giornate più calde portano a un maggior numero di “Entrate” In particolare, il 2,71 prima di “Temperatura” (chiamato coefficiente) significa che per ogni grado in più di “Temperatura”, in media ci saranno 2,71 dollari in più di “Entrate” Questa intuizione potrebbe portarvi a decidere di non vendere limonate nelle giornate fredde.
In secondo luogo, e in modo correlato, può anche aiutare a fare previsioni specifiche. Se la “Temperatura” è di 24, si può stimare che, poiché…
Entrate = 2,71 * Temperatura – 35
Entrate = 2,71 * 24 – 35
Entrate = 30
… si avranno circa 30 dollari di “Entrate” Questa potrebbe essere un’informazione utile per sapere se sarete in grado di effettuare un pagamento quel giorno, ammesso che siate sicuri che il vostro modello sia accurato.
Ora esamineremo il processo di creazione di questa equazione di regressione.
Preparazione alla creazione di un modello di regressione
1. Pensate alla teoria della regressione
Una volta scelta una variabile di risposta, “Entrate“, ipotizzate come i vari input possano essere correlati ad essa. Ad esempio, potreste pensare che una “Temperatura” più alta porterà a un “Ricavo” più alto, potreste non essere sicuri di come le varie insegne influiscano sul “Ricavo” e potreste credere che le “Vendite dei concorrenti” siano influenzate dalla “Temperatura” ma non abbiano alcun impatto sul vostro chiosco di limonate.
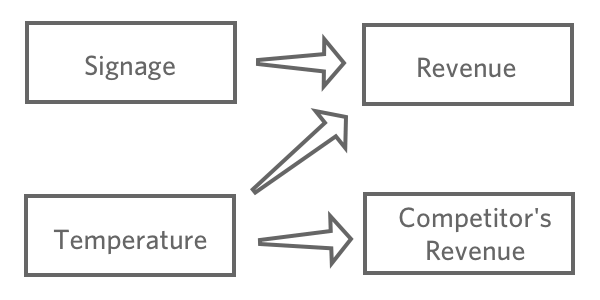
L’obiettivo della regressione è tipicamente quello di capire la relazione tra diversi input e un output, quindi in questo caso probabilmente si deciderà di creare un modello che spieghi le “Relazioni” con la “Temperatura”e la “Segnaletica”(detto anche “previsione delle Entrate dalla Temperatura e dalla Segnaletica“, anche se si è più interessati alla spiegazione che alla previsione vera e propria).
Probabilmente non includereste le “vendite dei concorrenti” nella vostra regressione. È probabile che sia correlato al “reddito”, ma non lo precede nella catena causale, quindi includerlo confonderebbe il modello.
2. “Descrivere tutte le variabili che potrebbero essere utili per il modello
Cominciate a descrivere la variabile di risposta, in questo caso “entrate”, e a farvi un’idea della stessa. Fate lo stesso per le variabili esplicative.
Nota che hanno una forma come questa..
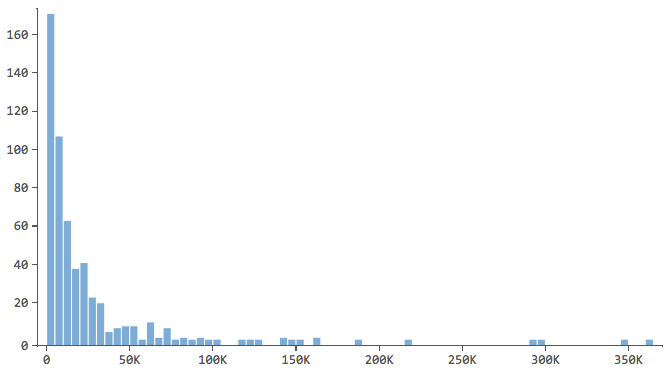
… dove la maggior parte dei dati si trova nei primi bins dell’istogramma. Queste variabili richiederanno un’attenzione particolare in seguito.
3. “Mettere in relazione tutte le possibili variabili esplicative con la variabile di risposta
Stats iQ ordina i risultati in base alla forza della relazione statistica. Date un’occhiata e fatevi un’idea dei risultati, notando quali variabili sono correlate alle “Entrate” e in che modo.
Se si ha già una buona idea di quali variabili dovrebbero teoricamente guidare l’output (ad esempio, da precedenti articoli accademici), si può saltare questo passaggio. Ma se la vostra analisi è di natura più esplorativa (come un sondaggio), questo è un passo utile e importante.
4. Iniziare a costruire la regressione
La costruzione di un modello di regressione è un processo iterativo. Passerete attraverso le tre fasi seguenti tutte le volte che sarà necessario.
Le tre fasi di costruzione di un modello di regressione
Fase 1: Aggiungere o sottrarre una variabile
Uno alla volta, iniziate ad aggiungere le variabili che le analisi precedenti indicavano essere correlate al “fatturato” (o aggiungete le variabili che avete una ragione teorica per aggiungere). Non è strettamente necessario procedere uno per uno, ma in questo modo è più facile identificare e risolvere i problemi man mano che si procede e ci si può fare un’idea del modello.
Supponiamo di iniziare prevedendo “Entrate” con “Temperatura” Trovate una relazione forte, valutate il modello e lo ritenete soddisfacente (maggiori dettagli tra un minuto).
Entrate = 2,71 * Temperatura – 35Se
poi si aggiunge il “Numero di bambini che sono passati”, il modello di regressione presenta due termini, entrambi predittori statisticamente significativi. In questo modo
: Entrate = 2,5 * Temperatura +
0
,3 * Numero di bambini che hanno camminato – 12Poi
si aggiunge “Numero di adulti che hanno camminato” e i risultati del modello mostrano che “Numero di adulti” è statisticamente significativo nel modello, ma “Numero di bambini” non lo è più. In genere si rimuove “Numero di figli” dal modello. Ora abbiamo:
Entrate = 2,6 * Temperatura + 0,4 * Numero di adulti che hanno camminato– 14
Ciò significa che il “Numero di adulti” è il miglior predittore delle “Entrate”; cioè, se si sa quanti adulti passano, sapere quanti bambini passano non aggiunge alcuna nuova informazione, non aiuta a prevedere le vendite.
Forse ripensandoci si ricorda che i bambini non comprano mai la limonata, quindi è logico che quella variabile non appartenga al modello.
Ma perché era statisticamente significativo nel primo modello? Probabilmente perché il “Numero di bambini” è correlato al “Numero di adulti” e, poiché il “Numero di adulti” non era ancora presente nel modello, il “Numero di bambini”fungeva da proxy approssimativo del “Numero di adulti”
L’interpretazione dei risultati della regressione richiede una buona dose di giudizio e il fatto che una variabile sia statisticamente significativa non significa che sia effettivamente causale. Ma aggiungendo e sottraendo con attenzione le variabili, notando come cambia il modello e pensando sempre alla teoria che sta alla base del modello, è possibile individuare relazioni interessanti nei dati.
Fase 2: Assessment del modello
Ogni volta che si aggiunge o si sottrae una variabile, è necessario valutare l’accuratezza del modello esaminando il suo r-quadro (R2), l’AICR e i grafici dei residui. Ogni volta che si modifica il modello, confrontare i nuovi grafici di r-squared, AICR e residui con quelli precedenti per determinare se il modello è migliorato o meno.
Quadro R (R2)
La metrica numerica per quantificare l’accuratezza della previsione del modello è nota come r-squared, che è compresa tra zero e uno. Uno zero significa che il modello non ha alcun valore predittivo, mentre un uno significa che il modello predice perfettamente tutto.
Ad esempio, il modello a sinistra è più preciso di quello a destra; cioè, se si conosce la “Temperatura”, si può indovinare abbastanza bene quale sarà il “Reddito”a sinistra, ma non quello a destra.
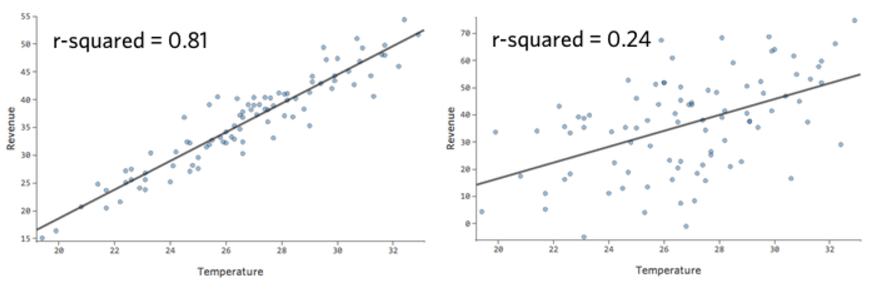
Non esiste una definizione fissa di un “buon” r-squared. In alcuni contesti potrebbe essere interessante vedere qualsiasi effetto, mentre in altri il modello potrebbe essere inutile, a meno che non sia molto accurato.
Ogni volta che si aggiunge una variabile, l’r-squared aumenterà, quindi l’obiettivo non è raggiungere l’r-squared più alto possibile; piuttosto, si vuole bilanciare l’accuratezza del modello (r-squared) con la sua complessità (in genere, il numero di variabili in esso contenute).
AICR
L’AICR è una metrica che bilancia l’accuratezza con la complessità: una maggiore accuratezza porta a punteggi migliori, mentre una maggiore complessità (più variabili) porta a punteggi peggiori. Il modello con l’AICR più basso è migliore.
Si noti che la metrica AICR è utile solo per confrontare gli AICR di modelli che hanno lo stesso numero di righe di datiela stessa variabile di output.
Intervalli di previsione
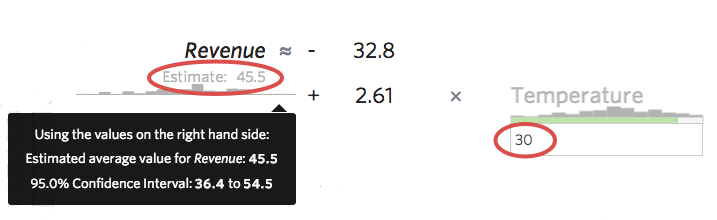
Un altro modo utile per farsi un’idea dell’accuratezza del modello è quello di inserire nella formula dei campioni e vedere l’intervallo di predict iq calcolato da Stats iQ. Ad esempio, se inserite il numero 30 nella formula, Stats iQ vi dirà che il valore predict iq è 45,5, ma che l’intervallo di confidenza al 95% è compreso tra 36,4 e 54,5, il che significa che potreste essere sicuri al 95% che se domani ci fossero 30 gradi, otterreste tra i 36,40 e i 54,50 dollari di “entrate” Si potrebbe immaginare un modello più accurato se l’intervallo di previsione fosse una fascia stretta come 44-48 dollari, o uno meno accurato se l’intervallo fosse ampio, come 20-72 dollari.
Questo approccio è utile solo se le trame residue sembrano sane (vedi sotto), altrimenti saranno imprecise.
Resti
I residui sono lo strumento diagnostico principale per valutare e migliorare la regressione, quindi c’è un’intera sezione separata sull’interpretazione dei residui per migliorare il modello. Imparerete o rinfrescherete la memoria su cosa sono i residui, su come usarli per valutare e migliorare il modello e su come pensare a quanto è necessario che il modello sia accurato.
Vi raccomandiamo di leggerlo per intero, in quanto contiene tutto ciò che è necessario per produrre un modello eccellente. Ma si può sempre tornare indietro, naturalmente.
Fase 3: modificare il modello di conseguenza
Se l’Assessment del modello è soddisfacente, il gioco è fatto, oppure si può tornare alla Fase 1 e inserire altre variabili.
Se l’assessment rileva delle carenze nel modello, si potranno utilizzare gli avvisi di Stats iQ e la sezione di diagnostica residua per risolvere i problemi.
Man mano che si modifica il modello, si devono osservare le variazioni di r-squared, AICR e diagnostica dei residui e decidere se le modifiche apportate stanno aiutando o danneggiando il modello.