Script R precomposti
Cosa puoi trovare in questa pagina
Attenzione: State leggendo una funzione a cui non tutti gli utenti di Stats iq hanno accesso. Se siete interessati a questa funzione, contattate il vostro Account Executive per verificare se avete i requisiti necessari.
Informazioni sugli script R precomposti
R è un linguaggio di programmazione statistica ampiamente utilizzato per analisi flessibili e potenti. Quando si utilizza R Coding in Stats iQ, è possibile scegliere tra più script di analisi per rendere l’uso di R più semplice ed efficiente.
Selezione di uno script per il codice R
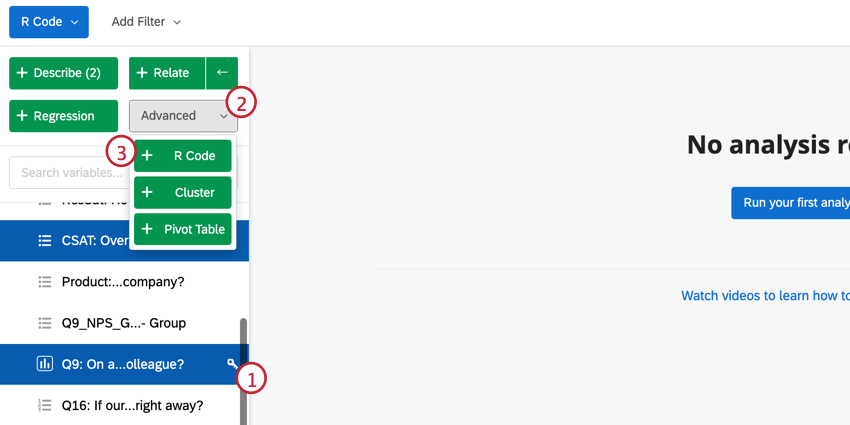
Consiglio Q: è possibile modificare le variabili selezionate direttamente da questa finestra. Per modificare i valori di ricodifica, fare clic su Modifica. Se si desidera cancellare la variabile, fare clic sull’icona ( – ). Per aggiungere una nuova variabile, fare clic su Aggiungi variabile in basso a sinistra.
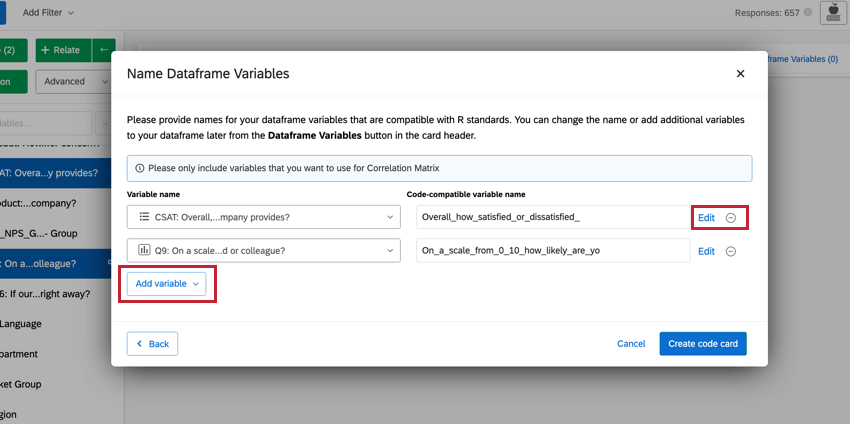
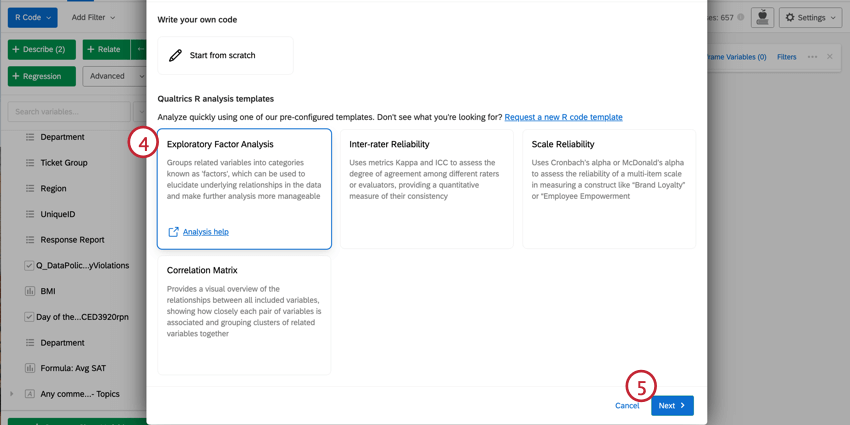
Navigazione negli script di codice R precomposti
Lo script verrà incollato nella sezione del codice della scheda R Code. Questo codice conterrà i consigli e i comandi per generare l’analisi selezionata. Per eseguire l’analisi, fare clic su Esegui tutto. I risultati vengono visualizzati nella casella di output a destra.
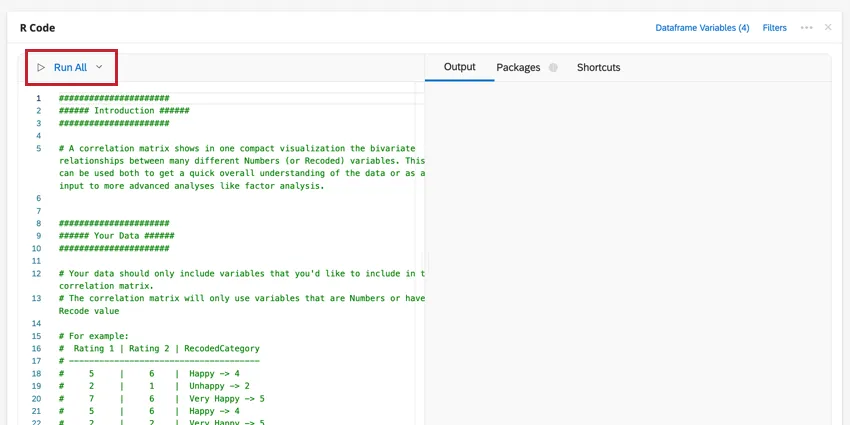
È possibile modificare le variabili del dataframe o aggiungere un filtro all’analisi facendo clic sulle opzioni in alto a destra. Fare clic sul menu a tre punti per aggiungere note alla scheda di codice, copiare l’analisi o aprire la scheda a schermo intero.
SCORTE
Le scorciatoie da tastiera possono essere utilizzate per navigare in modo più efficiente nella scheda R Code. Fare clic su Scorciatoie per visualizzare una lista di azioni possibili.
PACCHETTI
La codifica R in Stats iq è preinstallata con centinaia dei più popolari pacchetti R utilizzati per l’analisi. Fare clic sulla scheda Pacchetti nella metà destra della scheda per visualizzare la lista dei pacchetti disponibili. Per ulteriori informazioni sull’uso dei pacchetti, vedere Codifica R in Stats iQ.
Affidabilità scala
L’affidabilità della scala valuta la misura in cui gli item di una scala multi-item possono misurare in modo affidabile un costrutto. In altre parole, se la stessa cosa viene misurata utilizzando la stessa serie di domande, si otterranno risultati affidabili e simili? In caso affermativo, si ha la certezza che eventuali variazioni future siano dovute a cambiamenti nella popolazione del sondaggio o a interventi effettuati per migliorare il punteggio.
INTERPRETARE LE MISURE DI AFFIDABILITÀ
Le misure di affidabilità della scala sono comprese tra 0 e 1 e rappresentano essenzialmente una correlazione aggregata tra tutti gli item della scala.
L’alfa di Cronbach, una misura di affidabilità ampiamente utilizzata, spesso sottostima l’affidabilità a causa di alcuni presupposti. L’omega di McDonald’s, un’alternativa consigliata, evita questi difetti. Utilizziamo l’omega di McDonald per impostazione predefinita, ma l’alfa di Cronbach è ancora ampiamente accettato.
Non esiste un unico modo corretto di interpretare il numero risultante, ma la nostra regola empirica preferita per entrambi gli omega è descritta di seguito:
| Meno di 0,65 | Inaccettabile |
| 0.65 | Accettabile |
| 0.8 | Ottimo |
Se la scala affidabile è inaccettabile, ci sono alcune opzioni per rimediare al set di dati:
- Rimuovere tutti gli elementi che abbassano l’omega o l’alfa.
- È possibile che vengano misurati due costrutti distinti. In questo caso, la separazione delle variabili in due gruppi e l’esecuzione dell’analisi su ciascuno di essi porterebbe a punteggi di affidabilità superiori a quelli dell’analisi iniziale. È possibile esplorare questo aspetto valutando la matrice di correlazione nell’output o utilizzando lo script Analisi fattoriale esplorativa per vedere quali raggruppamenti emergono naturalmente dai dati.
- In definitiva, potrebbe essere necessario modificare ed eseguire nuovamente il sondaggio. Le voci che hanno una bassa correlazione con le altre potrebbero dover essere chiarite o rielaborate, oppure potrebbero essere aggiunte altre voci.
Risultati molto alti (ad esempio, 0,95) possono anche indicare un problema con la scala, di solito è possibile avere una scala molto affidabile senza avere così tanti item. In questo caso, si consiglia di eliminare dalla scala gli item meno utili e di ripetere l’analisi.
INTERPRETARE LE STATISTICHE A LIVELLO DI ITEM
Lo script esegue prima una misura di affidabilità complessiva e poi un’iterazione per ogni variabile. L’obiettivo dell’analisi dell’affidabilità per item è capire quali sono gli item più utili per la costruzione della scala. Stats iQ produrrà una tabella simile a questa:
Omega complessivo di McDonald’s: 0,71
| N | Media | Correlazione item-totale | McDonald’s Omega se rimosso | |
| A1 | 2784 | 4.59 | 0.31 | 0.72 |
| A2 | 2773 | 4.80 | 0.56 | 0.69 |
| A3 | 2774 | 4.60 | 0.59 | 0.61 |
| … | … | … | … | … |
- L’obiettivo generale è avere un McDonald’s Omega più alto con un numero inferiore di articoli. Quindi, se un ricercatore stesse creando una nuova scala, probabilmente vorrebbe eliminare l’A1, poiché l’omega è effettivamente più alto senza di esso.
- Il resto degli item che, se rimossi, ridurrebbero l’affidabilità, spetta al ricercatore determinarlo. Ad esempio, se un ricercatore è preoccupato per l’affaticamento del sondaggio, potrebbe consentire una maggiore diminuzione dell’affidabilità quando decide di rimuovere una variabile.
- La Correlazione totale dell’item è la correlazione tra quell’item e la media di tutti gli altri. Una bassa correlazione item-totale suggerisce che la variabile non è sufficientemente rappresentativa del costrutto sottostante. La regola empirica più comune è quella di diffidare di tutto ciò che ha una correlazione totale di 0,3 o inferiore, soprattutto se gli item sono numerosi, il che gonfia artificialmente la metrica dell’affidabilità.
Se si sceglie di rimuovere un elemento, è necessario rieseguire tutte le altre statistiche prima di decidere se rimuovere un altro elemento. In Stats iQ, ciò significa semplicemente rimuovere la variabile dall’intera scheda: il resto avverrà automaticamente.
MATRICE DI CORRELAZIONE INTER-VOCE
La matrice di correlazione tra le voci mostra la correlazione tra ogni variabile dell’analisi e ogni altra variabile. Ad esempio, se una variabile è molto correlata con un’altra (ad esempio, 0,9), le domande potrebbero essere ridondanti e la loro eliminazione avrebbe solo un piccolo impatto sull’affidabilità.
La correlazione media tra le voci è la media dei numeri della matrice. I numeri più alti indicano che alcuni elementi potrebbero essere superflui e potrebbero essere rimossi. In generale, le variabili dovrebbero rientrare in un intervallo compreso tra 0,2 e 0,4.
Consiglio Q: La correlazione media tra gli item può fornire informazioni utili sui punteggi complessivi di affidabilità. Ad esempio, se si lavora con un numero ridotto di item (ad esempio 3) e si ha un basso punteggio di affidabilità e un’alta correlazione media tra gli item, si potrebbe pensare che ciò sia dovuto a una mancanza di item piuttosto che a una mancanza di correlazione tra gli stessi.
ALTRE RISORSE
- L’analisi dell’affidabilità in Stats iQ viene eseguita dalla funzione compRelSem() del pacchetto R semTools. La documentazione descrive una serie di impostazioni avanzate. Non è necessario utilizzare o comprendere queste impostazioni per eseguire un’analisi di affidabilità.
- La matrice di correlazione viene eseguita dalla funzione corrplot() del pacchetto R corrplot. Una serie di impostazioni e personalizzazioni avanzate sono descritte nella documentazione e in questa guida.
Affidabilità inter-retributiva
L’affidabilità inter-rater (IRR) viene utilizzata per valutare la misura in cui due o più valutatori concordano nella loro valutazione. Ad esempio, tre diversi codificatori potrebbero valutare un commento testuale come avente un’analisi del sentiment positiva, neutra o negativa; l’IRR descrive la misura in cui concordano l’uno con l’altro.
MISURE DI AFFIDABILITÀ INTER-RATER
L’IRR viene valutato utilizzando metriche leggermente diverse in base alla struttura dei dati. Ad esempio, un’analisi dell’interaffidabilità di due valutatori utilizzerà una metrica leggermente diversa da quella dell’interaffidabilità di tre valutatori.
Stats iQ selezionerà automaticamente la metrica appropriata per i vostri dati.
INTERPRETAZIONE DEI RISULTATI
La metrica Kappa o ICC è il risultato principale, compreso tra 0 e 1, e indica il grado di correlazione tra i valutatori. Suggeriamo i seguenti intervalli per l’interpretazione del Kappa:
| 0.75 a 1 | Eccellente |
| 0.6 a 0,75 | Buono |
| 0.4 a 0,6 | Discreto |
| 0.4 o inferiore | Scarso |
ALTRE RISORSE
- L’analisi dell’affidabilità viene eseguita con le funzioni del pacchetto R IRR. La documentazione descrive una serie di impostazioni avanzate. Non è necessario utilizzare o comprendere queste impostazioni per eseguire l’analisi.
Analisi dei fattori esplorativi
L’analisi fattoriale esplorativa (EFA) è una tecnica statistica che aiuta a ridurre un gran numero di variabili in un insieme più piccolo e gestibile di “fattori” sintetici. Questo facilita notevolmente l’interpretazione, la comunicazione e l’esecuzione di ulteriori analisi (ad esempio, l’analisi di regressione). L’EFA segue tipicamente questa serie di fasi:
Il risultato è un insieme di fattori denominati e di voci di sondaggio che li compongono. Questi fattori possono servire come quadro concettuale per ulteriori analisi o essere applicati ai dati.
Esempio: Se le voci “La mia camera era pulita”, “Il resto dell’hotel era pulito” e “La mia camera aveva tutto ciò di cui avevo bisogno” fanno parte dello stesso fattore, si può fare una media di queste voci e riportare la misura riassuntiva “Qualità della camera”.
DIAGNOSTICA
Lo script esegue innanzitutto una serie di diagnosi per garantire che i dati siano adatti all’EFA:
- Dimensione del campione: In generale, si suggerisce un rapporto di 10:1 tra risposte e item. Ad esempio, se avete 10 domande, dovreste avere almeno 100 rispondenti.
- Test di sfericità di Bartlett: Questo test valuta se gli item sono sufficientemente correlati per essere utilmente raggruppati in fattori. Se questo non funziona, è probabile che ci siano diversi elementi che non sono sufficientemente correlati con gli altri. Si può pensare di eliminare dalla propria analisi le voci che non sono correlate con altre, oppure di aggiungere al sondaggio altre voci correlate.
- Determinante: Il determinatore valuta se gli item sono troppo correlati per essere utilmente raggruppati in fattori. Se questa diagnosi fallisce, è probabile che vi siano elementi troppo simili tra loro per essere separati in fattori. Considerate la possibilità di modificare le voci del sondaggio per renderle più distinte.
- Misura di Kaiser-Meyer-Olkin (KMO): questa misura verifica se gli elementi del sondaggio hanno abbastanza punti in comune da essere raggruppati in fattori significativi. Il superamento di questa diagnostica significa che le risposte del sondaggio hanno molti punti in comune e possono essere raggruppate in modo adeguato. Altrimenti, gli elementi non si clusteranno in categorie. Se questa diagnostica fallisce, è possibile rivedere le voci del sondaggio per catturare temi più simili e considerare la possibilità di rimuovere le voci che non mostrano una chiara relazione con le altre.
SCELTA DEI FATTORI
Lo scopo dell’EFA è ridurre molte variabili a un numero relativamente piccolo di variabili utili per l’analisi, quindi potrebbe essere necessario eseguire l’analisi fattoriale più volte con un numero diverso di fattori per trovare un raggruppamento che vada bene per voi. Lo script EFA suggerirà il numero di fattori in base ai loro autovalori.
Consiglio Q: gliautovalori misurano il grado di correlazione di un fattore con le variabili originali da cui è stato creato, sommando i valori di r-squared tra il fattore e le variabili. Ad esempio, se l’r-quadro tra il fattore e Q1 è pari a 0,8 e quello tra il fattore e Q2 è pari a 0,5, l’autovalore è pari a 1,3. In generale, si dovrebbero utilizzare fattori con un autovalore superiore a 1. Lo script EFA utilizza questo parametro per suggerire il numero di fattori.
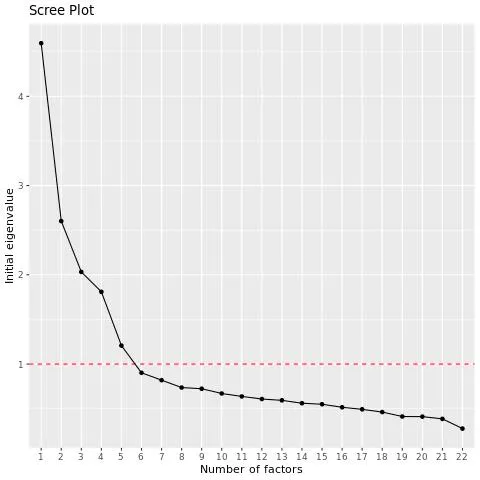
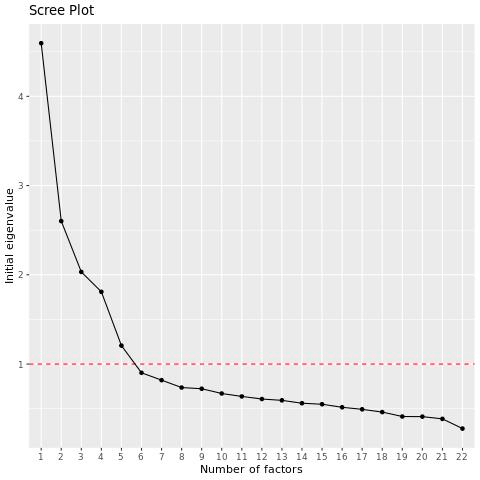
Lo script EFA produce uno scree plot, che mostra gli autovalori delle variabili in ordine decrescente. È possibile esaminare il grafico per vedere quanti fattori si verificano prima del “gomito” nel grafico, dopo il quale l’aggiunta di altri fattori è meno utile.
Esempio: In questo esempio c’è un forte calo dopo la quarta variabile e poi un altro calo significativo dopo la quinta variabile. Per impostazione predefinita, lo script utilizza 5 fattori, ma è possibile eseguirlo anche con 4 fattori e confrontare i risultati.
{kind=link}
{kind=link}
{kind=link}
DARE UN NOME AI PROPRI FATTORI
Dopo aver eseguito l’EFA, ogni variabile viene assegnata a un fattore. È utile assegnare a ciascun fattore un nome che consenta di parlare in modo abbreviato, in modo da rendere più accessibili i risultati. L’obiettivo è semplificare i dati complessi in pochi temi comprensibili.
Ecco alcune linee guida per la denominazione dei fattori:
- Siate descrittivi: Cercate di cogliere il tema comune che riassume le variabili del gruppo.
- Mantenere la semplicità: I nomi dei fattori devono essere facili da capire e da comunicare. Evitate il gergo tecnico o le frasi troppo complesse.
- Considerate il vostro pubblico: I nomi dei fattori devono avere un senso per le persone che utilizzeranno la vostra analisi. Ad esempio, “Pulizia” sarebbe significativa sia per i manager che per gli ospiti dell’hotel.
- Coerenza: Se il vostro sondaggio o set di dati si estende su diversi ambiti o soggetti, assicuratevi che i nomi dei fattori siano coerenti.
MISURE ASSOCIATE & METRICHE
La tabella dei caricamenti dei fattori è uno dei risultati principali dell’EFA. Il caricamento del fattore per una data coppia variabile-fattore è la correlazione tra quella variabile e il fattore. Se una variabile ha un carico fattoriale elevato per un determinato fattore, significa che la domanda è fortemente collegata a quel fattore.
L’unicità è la parte della varianza che è unica per la variabile specifica e non condivisa con altre variabili. I valori di unicità variano da 0 a 1. I valori più alti indicano che la variabile è unica e non si adatta bene a nessuno dei fattori. .
In generale, si raccomanda di rimuovere le variabili se i loro carichi fattoriali sono superiori a 0,3 o se la loro unicità è superiore a 0,7.
UTILIZZARE I RISULTATI OTTENUTI
L’analisi fattoriale è un processo iterativo, quindi potrebbe essere necessario eseguirla più volte con un numero diverso di fattori per trovare il raggruppamento che fa al caso vostro. Per la maggior parte dei ricercatori, l’aspetto fondamentale è la ricerca di raggruppamenti di fattori in grado di fornire nuove informazioni sui dati, ma è possibile utilizzare questi fattori come nuove variabili nelle analisi successive, come la regressione o l’analisi cluster. Ad esempio, si potrebbe creare una nuova variabile per ogni fattore che assuma il valore medio di tutte le variabili che vi sono raggruppate.
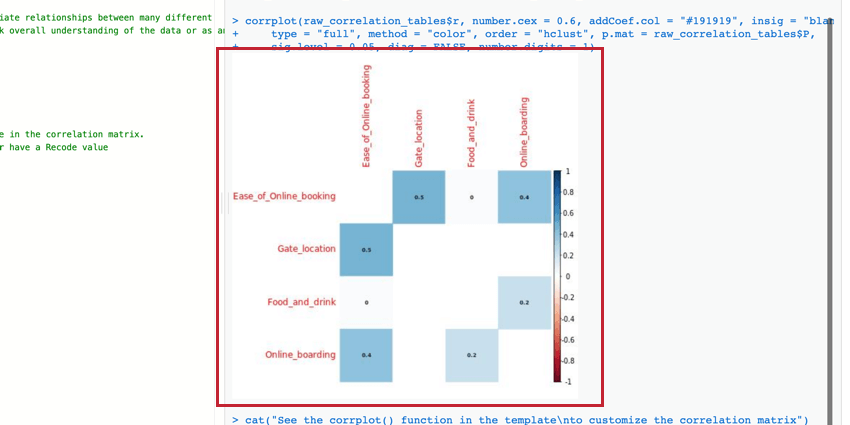
Matrice di correlazione
La matrice di correlazione è una tabella che mostra la correlazione tra ogni coppia di variabili fornite. Questa tabella utilizza la r di Pearson come misura predefinita della correlazione, ma è possibile modificarla in rho di Spearman se si desidera.
{kind=link}
È possibile modificare i parametri della funzione corrplot() per modificare la tabella e renderla più leggibile. Per ulteriori informazioni, è possibile consultare la documentazione ufficiale di R.
È fantastico! Grazie per il tuo feedback!
Grazie per il tuo feedback!