-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Analisi cluster
Informazioni sull’analisi dei cluster
Quando analizziamo i nostri dati, spesso ci occupiamo di gruppi demografici diversi e segmentiamo gli intervistati per reddito, regione, età e altro ancora. Ma a volte queste etichette possono essere riduttive: dopo tutto, sapere di avere molti intervistati di sesso maschile non ci dice che tipo di campagna pubblicitaria vorrebbero vedere. Il vostro pubblico è composto principalmente da millennials? Papà calciatori? Entrambi? Come si fa a tradurre le caratteristiche personali in termini che possano essere suddivisi per scopi di marketing?
L’analisi dei cluster è un mezzo per individuare i gruppi naturalmente presenti nel set di dati del sondaggio. A tal fine si analizzano le qualità demografiche, comportamentali e/o basate sulle convinzioni che presentano la maggiore correlazione.
Preparazione di un sondaggio per l’analisi dei cluster
Per eseguire un’analisi cluster, è necessario raccogliere i dati corretti nel sondaggio.
- Fate le domande giuste:
- Dati demografici: Chiedere informazioni descrittive di base, come l’età, la fascia di reddito, la razza o il sesso.
- Comportamento: Chiedete come i clienti interagiscono con il vostro brand e i vostri prodotti, o quali comportamenti possono essere correlati al loro comportamento d’acquisto. Ad esempio, si può chiedere quanto spesso il cliente va a fare la spesa.
- Datioperativi : Si tratta di informazioni come il tempo trascorso sul vostro sito web o la permanenza di un dipendente nella vostra azienda.
Consiglio Q: Siete interessati a tracciare il tempo trascorso su una pagina? Allora potrebbe essere interessato a utilizzare la funzione Feedback del nostro sito web. Contattate il vostro Account Executive se siete interessati a saperne di più.
- Atteggiamenti e convinzioni: Sondaggio sui valori fondamentali, gli atteggiamenti e le convinzioni degli intervistati. Questo può includere le convinzioni religiose o politiche, ma si può anche chiedere di conoscere le convinzioni direttamente rilevanti per il funzionamento della vostra azienda. Ad esempio, si può chiedere loro di valutare quanto sia importante che le interazioni di assistenza avvengano faccia a faccia.
- Formati delle domande: Formare le domande sui comportamenti e le convinzioni come scale. L’intervallo di una scala può aiutarci a capire quali punti di valutazione sono correlati e quindi approssimativamente nello stesso cluster; le domande Sì/No e a selezione singola non sono altrettanto utili per l’analisi dei cluster.
Esempio: Se si chiede “Che tipo di acquirente sei?” e si danno le opzioni “Preferisco fare acquisti nei centri commerciali”, “Preferisco fare acquisti online” e “Preferisco fare acquisti nelle boutique”, l’algoritmo di clustering vorrà dividere gli intervistati in tre gruppi, uno per ogni risposta. Se invece si pone una serie di domande (ad esempio, “Le piace fare shopping nei centri commerciali?”) con risposte da 1 a 7, l’algoritmo di clustering farà un lavoro migliore per discernere realmente ciò che separa i diversi acquirenti gli uni dagli altri.CONSIGLIO Q: Le domande a Scelta multipla sono le migliori per raccogliere dati scalari.
- Tipi di variabili: Quando si è pronti per l’analisi in Stats iq, assicurarsi di formattare le variabili come categorie o numeri. Le date sono incompatibili con l’analisi dei cluster.
Performance dell’analisi dei cluster
- Assicurarsi che i tipi di variabile delle domande siano impostati su numero o categorico.
- Selezionare le variabili da analizzare sulla sinistra.
- Fare clic su Cluster.
Risultati dell’analisi dei cluster
Tabella di resistenza e statica
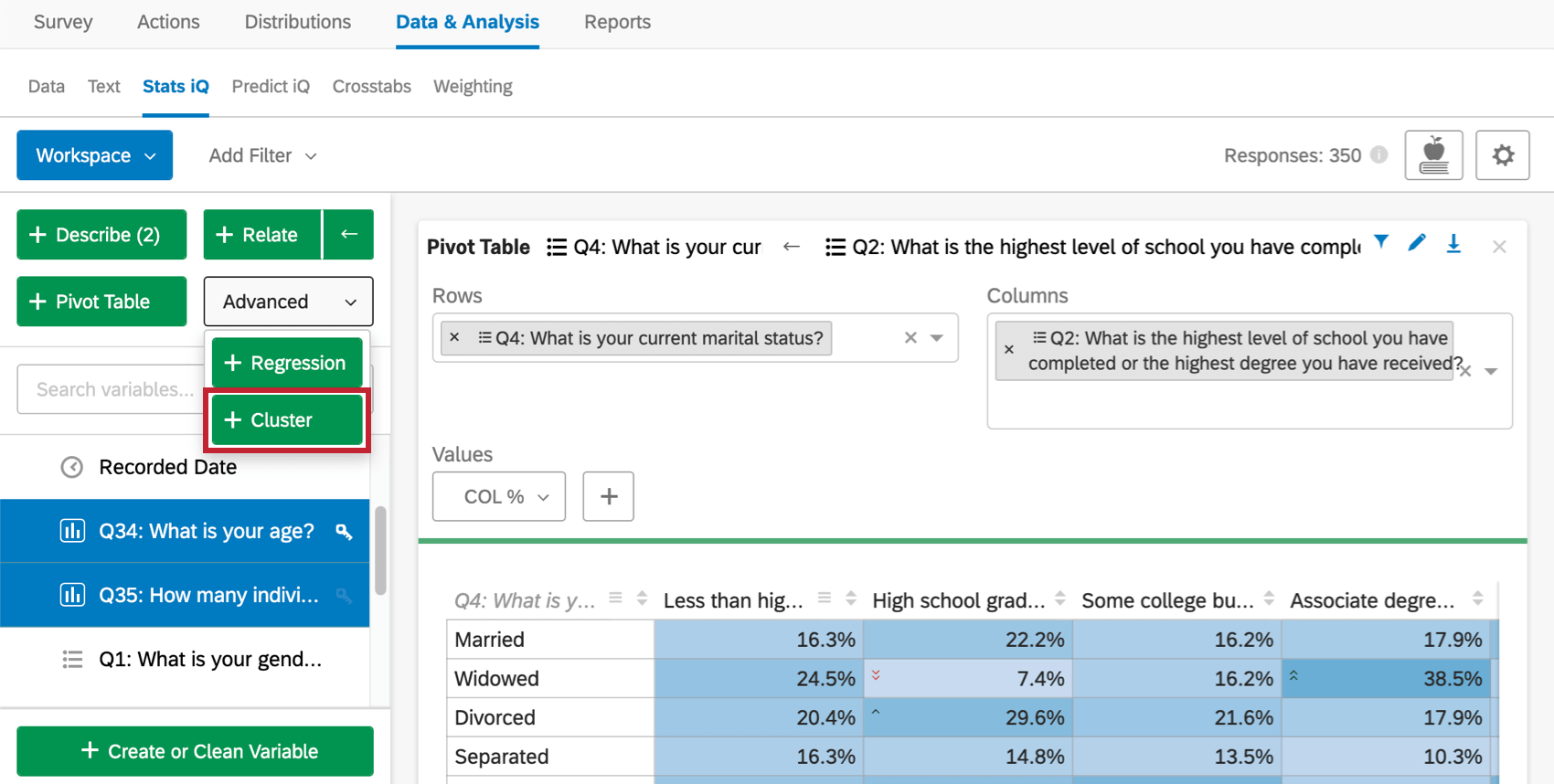
La tabella elenca la dimensione del campione (quanti intervistati hanno contribuito all’analisi), il numero di cluster e il punteggio della silhouette. Il punteggio della silhouette viene interpretato in frasi come “molto forte” nella frase in alto.
L’analisi dei cluster cerca di scegliere automaticamente il numero appropriato di cluster, valutando la tenuta del raggruppamento a vari numeri, ma penalizzando un numero maggiore di cluster perché più difficile da lavorare. La scelta del numero giusto è più un’arte che una scienza e si dovrebbe sperimentare con diversi numeri per vedere quello che funziona meglio.
In alcuni casi, l’algoritmo non sarà in grado di produrre un certo numero di cluster e ripiegherà su un numero inferiore.
Riepilogo cluster
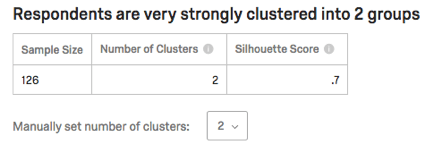
I cluster saranno elencati nella sezione Cluster Summary. Saranno descritti in base alle domande a cui i membri del cluster hanno risposto in modo più simile.

Esempio: Il Cluster 1 in questa schermata contiene persone che sono:
- Coniugato/a
- Hanno conseguito un master
- Hanno poche persone (parenti stretti, bambini) che vivono nella loro casa
- Giovane
Fare clic sul nome di un cluster per rinominarlo.
Consiglio Q: Rinominare i cluster è importante per dare un senso ai risultati in un contesto reale o di marketing.

Tabella risultati del cluster
Nella tabella Risultati del cluster, vengono evidenziate le variabili principali del cluster. Per le variabili categoriche, verrà indicata l’opzione più comune e la percentuale di intervistati nel cluster che hanno fornito questa risposta. Per le variabili numeriche, si vedrà una risposta media.
Esempio: In questa schermata, il livello di istruzione è categorico, quindi vediamo una suddivisione delle percentuali di intervistati con dottorato rispetto a quelli con laurea. Meno di un diploma di scuola superiore contro un’istruzione di livello superiore. Master.
L’età è numerica, quindi vediamo l’età media per ogni cluster (32,4 per il Cluster 1, 50,3 per il Cluster 2).
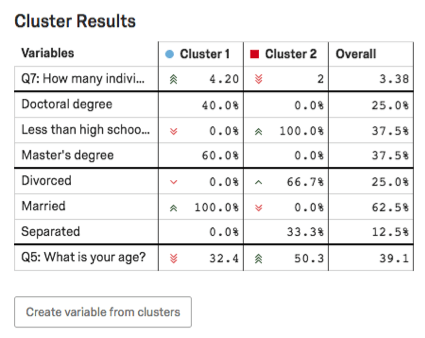
Per ulteriori informazioni sulla creazione di variabili dai cluster, consultare la sezione Creare una variabile dai cluster.
Importanza di variabile
La tabella dell’importanza delle variabili mostra la forza della relazione tra ciascuna variabile e i cluster. Una relazione più forte indica che la variabile è stata più importante nella creazione dei cluster.
Per calcolarlo, eseguiamo regressioni per ogni variabile. Ad esempio, l’età viene confrontata con il risultato del cluster, le ore lavorate con il risultato del cluster e così via.
I valori di r-quadro risultanti da queste regressioni vengono poi scalati in modo che il valore di r-quadro più alto sia impostato su 1.
Esempio: Supponiamo che il Q7 abbia un r-squared di 0,5, il più alto del gruppo. Dobbiamo raddoppiare questo valore per portarlo a 1. Ciò significa che se Q13 avesse un valore di r-squared di 0,4, nel grafico seguente verrebbe visualizzato come 0,8.

Creazione di nuove variabili dai risultati
Una volta determinati i cluster tra gli intervistati, è possibile trasformare queste categorie in nuove variabili da analizzare in Stats iQ!
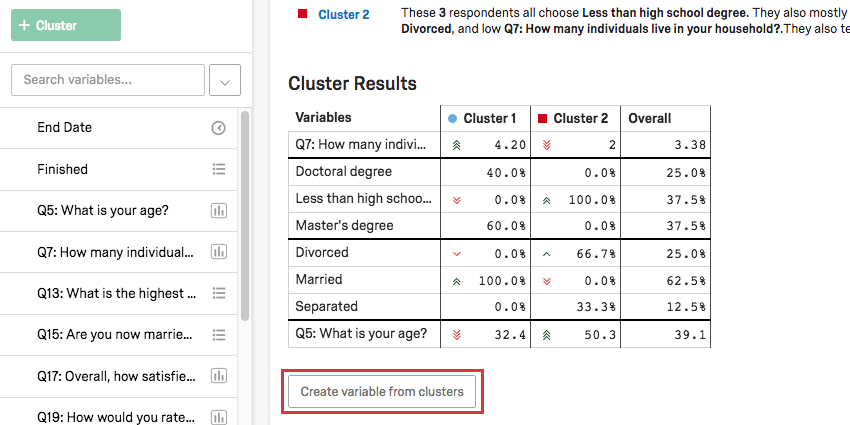
Per prima cosa, assicurarsi di rinominare i cluster facendo clic sui loro nomi.
Una volta che i cluster hanno un nome sensato, fare clic su Crea variabile dai cluster sotto la tabella Risultati dei cluster. In questo modo si aggiunge automaticamente una variabile categorica alla lista delle variabili a sinistra.
Note tecniche
L’analisi dei cluster in Stats iQ utilizza la Latent Class Analysis (LCA) per suddividere i dati forniti dall’utente nei cluster sottostanti. A differenza di altri algoritmi di clustering, l’algoritmo Stats iQ LCA consente di clusterizzare tipi di dati misti (numerici, categorici e binari).
Analisi di classe latente di tipo misto
La Latent Class Analysis (LCA) è un modello di clustering basato sulla probabilità. Ogni cluster è definito da un insieme di funzioni di densità di probabilità che, in base al valore delle variabili di un punto dati, restituiscono la probabilità che un particolare punto dati appartenga a quel cluster.
Esempio: La vostra famiglia può essere suddivisa in alcune generazioni, come i figli attuali, i genitori e i nonni. Un modello LCA rappresenterebbe questi 3 cluster, dove ogni cluster è definito da una singola funzione di probabilità basata sull’età:
| Cluster | Funzione di probabilità Media | Funzione di probabilità Deviazione standard |
| Attuale | 25 | 7 |
| Genitori | 48 | 5 |
| Nonni | 75 | 3 |
Per assegnare una persona di 30 anni a un cluster, utilizzare queste funzioni di densità di probabilità per calcolare che c’è il 44% di probabilità che sia in Corrente, l’1% di probabilità che sia in Genitori e l’1% di probabilità che sia in Nonni. Questo individuo verrebbe assegnato al suo cluster più probabile, Current.
Un modello LCA può essere applicato a più variabili moltiplicando la probabilità che un datapoint appartenga a un cluster in base a ciascuna variabile. Il modello può essere applicato a diversi tipi di variabili utilizzando diverse funzioni di densità di probabilità:
| Tipo | Trasformazione | Funzione di densità di probabilità |
| Categorico | Manichino codificato (N-1) | Bernoulli |
| Binario | Bernoulli | |
| Numerico | Normale |
Determinazione del numero di classi
Per determinare il numero ottimale di classi, Stats iQ utilizza il punteggio BIC.
Valutare l’adattamento del modello
Per valutare la “bontà” oggettiva di un modello, Stats iQ utilizza un punteggio di silhouette basato sulla probabilità. Il punteggio della silhouette è una misura del benessere di ciascun punto dati all’interno del proprio cluster. Il punteggio di silhouette misura la somiglianza di un particolare punto con tutti gli altri punti del suo cluster e la confronta con la somiglianza con tutti i punti del cluster più vicino. Per misurare la somiglianza tra due punti di dati, Stats iq calcola la distanza di Gower (una metrica di distanza che funziona per dati binari, categorici e numerici) tra i punti.