-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Preparazione del file PARTECIPANTE per l’importazione (EX)
Informazioni sulla preparazione del file PARTECIPANTE
Quando si importano i partecipanti al progetto Employee Experience, occorre tenere presenti alcune cose importanti. Ad esempio, ogni importazione di partecipanti richiede le seguenti colonne, indipendentemente dal tipo di gerarchia:
- Nome: Nome del dipendente.
- Cognome: Il cognome del dipendente.
- Email: L’indirizzo e-mail del dipendente. Questo dettaglio è il più importante. L’e-mail può fungere da nome utente per ogni partecipante o da modo per ricordare quali utenti sono già presenti nella directory.
Attenzione: Se il campo e-mail nel file del partecipante viene lasciato vuoto, verrà generata un’e-mail artificiale utilizzando il formato UniqueID@BrandID.fake come segnaposto per completare le informazioni personali. Poiché l’e-mail generata è artificiale, le distribuzioni EX non verranno inviate al partecipante finché l’e-mail non verrà aggiornata con un indirizzo valido. Tuttavia, se l’organizzazione dispone di SSO, è necessario includere indirizzi e-mail convalidati quando si caricano i partecipanti per garantire la corretta generazione automatica del nome utente.
- Identificatore univoco: Specificare i partecipanti con l’identificativo preferito dall’azienda. È possibile utilizzare qualsiasi cosa, dagli ID numerici interni ai nomi utente, fino alla ripetizione della colonna EmployeeID (ma solo se questa è unica all’interno dell’organizzazione e non sarà condivisa con nessun altro progetto). Per maggiori dettagli, consultare la pagina di supporto sugli identificatori univoci.
Se state creando un progetto Engage, dovete assicurarvi di aver scelto la gerarchia giusta per il vostro progetto, poiché questa influisce sui metadati, o sulle colonne personalizzate dei dati dei partecipanti, che includerete nel file CSV/TSV. Ad esempio, il file di gerarchia Genitore-Figlio dovrebbe includere colonne per l’ID del dipendente e l’ID del manager, mentre il file di gerarchia basato sul livello dovrebbe avere colonne diverse per il livello. In questa pagina vengono illustrati i metadati da includere per ogni gerarchia.
Se si dimentica di includere i metadati corretti all’inizio, non c’è problema! È sempre possibile aggiornare i metadati dei partecipanti in un secondo momento, seguendo i passaggi indicati nella sezione collegata.
Importazione dei partecipanti per una gerarchia genitore-figlio
Le gerarchie genitore-figlio sono il tipo di gerarchia più comunemente usato. Sono l’opzione migliore se i dati delle risorse umane sono formattati in modo da avere una lista di ID dei dipendenti e dei manager a cui ciascun dipendente fa rapporto.
Fare clic qui per accedere al modello di file gerarchico Genitore-Figlio.
Metadati richiesti
Per creare una gerarchia genitore-figlio, è necessario includere due colonne di metadata:
- EmployeeID: è l’identificativo del dipendente del partecipante. È preferibile utilizzare gli ID assegnati internamente dall’ufficio risorse umane dell’azienda, piuttosto che cercare di creare nuovi ID generati a caso.
- ManagerID: è l’identificativo del manager del partecipante.
Esempio: Nell’immagine seguente, l’ID dipendente di John Doe è 1, quindi la sua colonna EmployeeID dice 1. Jill Davis, Sammy External e Joseph Miller fanno capo direttamente allo sconosciuto, quindi le loro colonne ManagerID dicono 1.
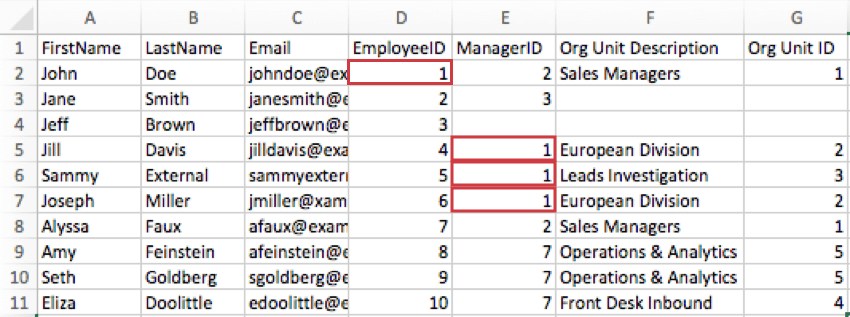
Consiglio Q: tecnicamente, si può dare ai nomi EmployeeID e ManagerID il nome che si desidera. Ad esempio, se la vostra organizzazione preferisce il termine “numero di dipendente” o ha un termine speciale come “QID”, potete dare alle colonne questi nomi. L’importante è includere questi concetti e inserirli nei campi corretti quando si genera la gerarchia Genitori-Figli.
Quando si aggiungono gli ID dei dipendenti e dei manager, occorre tenere presenti alcune cose importanti:
- La colonna Identificatore univoco dei dati può essere utilizzata per il campo ID dipendente quando si genera una gerarchia genitore-figlio. Ecco come si presenterebbe l’esempio precedente in questa circostanza:
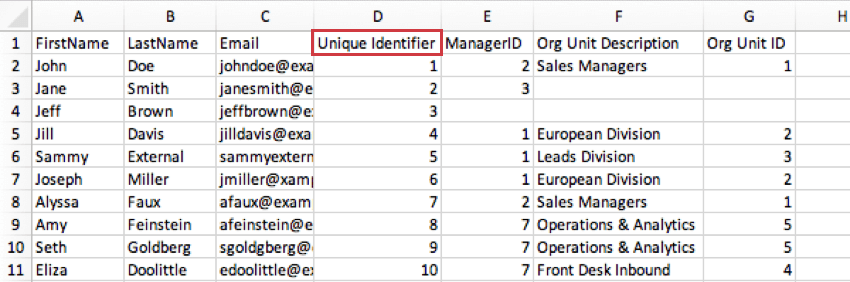
- Ogni partecipante deve inoltre disporre di un ID dipendente unico. Più partecipanti non possono condividere lo stesso ID. Può coincidere con l’Identificatore univoco.
- Ogni partecipante deve avere un manager. L’unica eccezione è rappresentata dai membri più alti dell’azienda inclusi nella gerarchia (ad esempio, gli amministratori delegati). Lasciare vuota la colonna Manager per indicare che questa persona non dipende da nessuno.
- Le colonne ID dipendente e ID manager di un singolo dipendente non devono mai essere uguali. I dipendenti non fanno rapporto a se stessi!
- Ogni ID Manager deve essere collegato a un dipendente. Qualsiasi partecipante con un ID Manager che non corrisponde a un ID dipendente esistente sarà assegnato a un Manager sconosciuto. Si noti che una volta che una persona è assegnata a un Manager sconosciuto, anche i membri della gerarchia sotto questa persona saranno interrotti. Per risolvere questo problema, è necessario correggere manualmente i dati e rigenerare la gerarchia.
- Attenzione alla logica circolare. Se lo sconosciuto riferisce a Jane Smith e Jane Smith riferisce a Joseph Miller, Joseph Miller non può riferire allo sconosciuto. Non potete gestire il manager del vostro manager.
Metadata facoltativi
Quando si carica la lista dei partecipanti, è possibile aggiungere qualsiasi metadata aggiuntiva si desideri. È possibile includere qualsiasi cosa, dalla data di nascita di ciascun dipendente alla sede dell’ufficio. Tuttavia, esistono due metadati opzionali che possono aiutare a formattare la gerarchia Genitori-Figli.
- ID unità organizzativa: Gli ID unità organizzativa aiutano a identificare lo stesso team nel tempo, anche se il nome del team cambia. Ha la stessa funzione di un ID univoco del dipendente, ma per un’unità invece che per un dipendente. Includere un ID stabile dell’Unità della gerarchia significa non dover mappare manualmente i dati della gerarchia; il sistema riconoscerà l’ID e mapperà in modo appropriato. Gli ID delle unità organizzative sono utili anche se un manager è responsabile di più team. Ciò significa che se il manager è John Doe, ma John Doe è il manager del team A e del team B, è possibile specificare a quale team appartiene un subordinato diretto con il campo ID unità.
- Descrizione dell’unità organizzativa: Quando si crea la gerarchia, le unità vengono automaticamente denominate per un manager. L’impostazione Descrizione unità org consente di denominare le unità in base ai nomi o alle descrizioni delle unità stesse.
Consiglio Q: le descrizioni delle unità organizzative si basano sulle informazioni fornite dal subordinato diretto, non dal manager.
La Descrizione dell’unità organizzativa funge da nome per uno specifico ID dell’unità organizzativa e apparirà come etichetta dell’unità nei dashboard durante i filtri o la suddivisione per unità. Ad esempio, la descrizione dell’unità organizzativa dell’ID Org 2 può essere Divisione europea. Per ogni ID unità può esserci solo una descrizione dell’unità e viceversa. Allo stesso modo, se i dipendenti appartengono alla stessa unità organizzativa, le loro descrizioni devono corrispondere.
Esempio: Nell’immagine sottostante, John Doe gestisce due diversi team: la Divisione Europea e l’Indagine sui Leader. La colonna Descrizione dell’unità organizzativa specifica a quale di questi team appartengono i suoi 3 subordinati diretti. Vediamo che Jill Davis e Joseph Miller sono nella Divisione Europea, ma Sammy External è nei Leads Investigation.
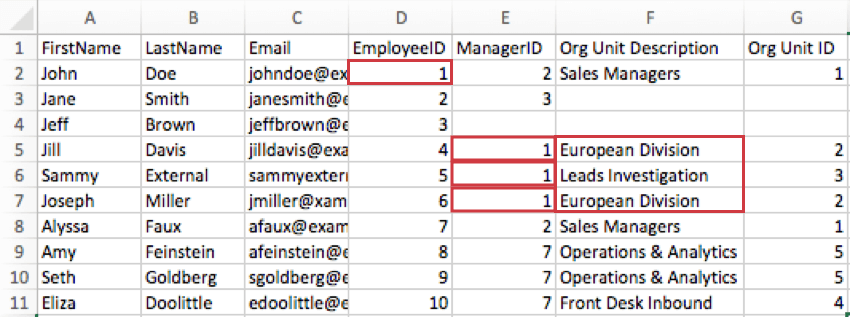
Esempio: Nell’immagine sottostante, Jill e Joseph appartengono entrambi alla “Divisione Europea”, che ha un ID Org Unit di 2. Si noti come la descrizione dell’Org Unit e l’ID Org Unit corrispondano di conseguenza.

Importazione dei partecipanti per una gerarchia basata sui livelli
Le gerarchie basate sui livelli sono una buona opzione se i dati HR includono ogni livello a cui il dipendente riferisce, dal vertice della gerarchia fino alla posizione del dipendente. Con le gerarchie basate sul livello, non è necessario sapere chi è il manager del dipendente; è sufficiente conoscere la catena di comando di ogni dipendente che si intende includere nel progetto. Questo formato di dati è spesso più comune nelle aziende che organizzano i dati dei dipendenti per livelli, sedi o suddivisioni funzionali distinte.
Fare clic qui per accedere al modello di file gerarchico basato sui livelli.
Metadati richiesti
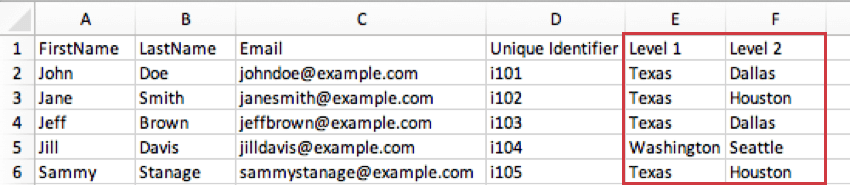
È necessario creare una colonna separata per ogni livello dell’organizzazione che si desidera definire. L’ultimo livello compilato per un partecipante indica la sua posizione nella gerarchia. Per chi è più in alto, di solito significa che la prima colonna del LIVELLO è piena, ma le altre non lo sono.
Metadata del Manager
Se siete interessati ad assegnare dei manager alle unità nelle vostre gerarchie basate sul livello, ci sono due modi diversi per farlo.
- Manager: Questa colonna indica se il partecipante è un manager. Il partecipante sarà assegnato come manager del livello inferiore nel quale è stato elencato. La maggior parte degli utenti usa “sì” per indicare un manager, ma si può anche usare “1”, “manager” o qualsiasi altro formato, purché nella colonna ci sia un valore che indichi che il partecipante è un manager.
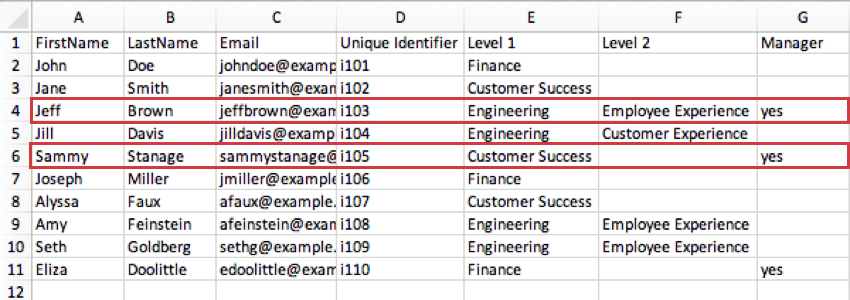
Esempio: Nell’immagine sottostante, il livello più basso definito per Sammy Stanage è il Livello 1, in cui ricopre un ruolo di successo clienti. Il “sì” nella colonna Manager indica che è manager di tutto il Customer Success. Nel frattempo, l’ultimo livello definito da Jeff Brown è l’Esperienza dei dipendenti nell’ambito dell’ingegneria. Ciò significa che all’interno di Engineering è a capo del livello Esperienza dei dipendenti.
- Livello del manager: Il Livello Manager è un mezzo per identificare i manager, indicando il livello specifico che gestiscono. Nell’esempio precedente, lo stesso valore (“sì”) indica se un partecipante è o meno un manager; per il Livello manager, invece, ci sono valori separati per ogni livello.
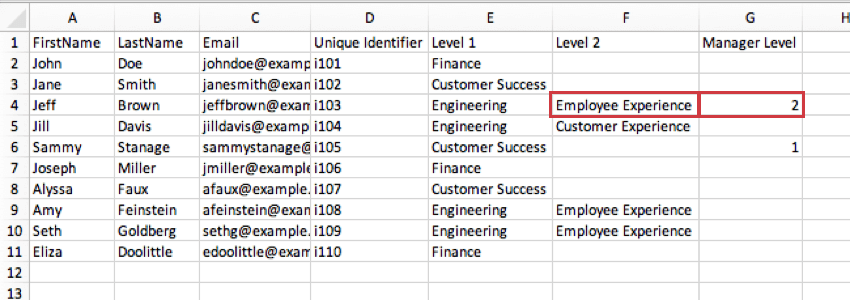
Esempio: Nell’immagine sottostante, il livello Manager di Jeff Brown è 2 per indicare che è manager della sua posizione di Livello 2 in Esperienza dei dipendenti, non manager della sua posizione di Livello 1 in Ingegneria.
Metadati facoltativi
ID unità organizzativa: Gli ID unità organizzativa aiutano a identificare lo stesso team nel tempo, anche se il nome del team cambia. Includere un ID stabile dell’Unità della gerarchia significa non dover mappare manualmente i dati della gerarchia; il sistema riconoscerà l’ID e mapperà in modo appropriato. Ha la stessa funzione di un ID univoco del dipendente, ma per un’unità invece che per un dipendente. È necessario includere tanti ID di unità organizzativa quanti sono i livelli, in modo da poter fornire un ID per ogni livello.
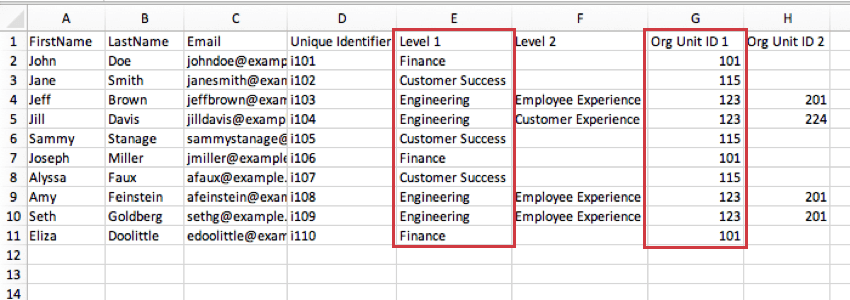
Deve esserci una colonna ID Unità dell’ORGARCHIA unica per ogni livello della gerarchia dell’organizzazione. Ad esempio, se l’organizzazione ha due livelli, “Livello 1” e “Livello 2”, sono necessarie due colonne per gli ID dell’unità organizzativa: “Org Unit ID 1”, che contiene l’ID dell’unità organizzativa per tutti coloro che fanno parte del Livello 1, e “Org Unit ID 2”, che contiene l’ID dell’unità organizzativa per tutti coloro che fanno parte del Livello 2. È necessario fare attenzione a non riutilizzare i nomi dei campi dell’unità organizzativa, per cui si consiglia di numerarli.
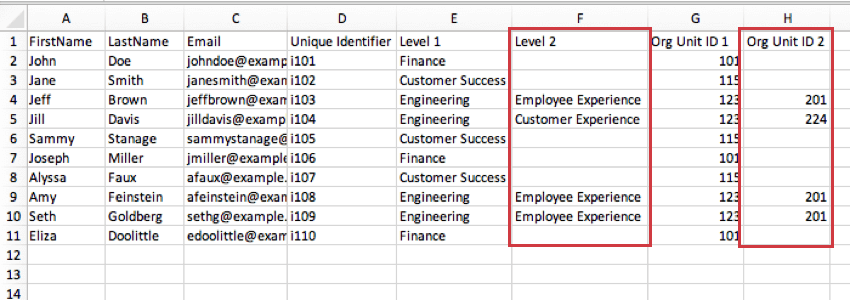
Nella schermata sottostante, le unità del Livello 2 corrispondono alla colonna Org Unit ID 2. Il team di ingegneria dell’Esperienza dei dipendenti è l’unità 201, mentre il team di ingegneria dell’Esperienza dei clienti è 224.
Importazione di Partecipanti per una Gerarchia scheletrica
Le gerarchie scheletriche si usano quando si conosce l’identità dei manager, ma non dei loro subordinati diretti. Invece di organizzare una gerarchia attorno a una lista di rapporti diretti e alla catena di comando che li sovrasta, si costruisce un elenco di manager e delle unità a cui fanno capo.
Ecco un esempio di Gerarchia scheletrica per iniziare. Creare un CSV/TSV e creare una riga con ciascun manager. Per costruire una Gerarchia scheletrica, è necessario disporre almeno delle informazioni sui manager.
Per ogni manager, aggiungere una colonna per il nome, il cognome, l’ e-mail,e qualsiasi altro metadata si desideri includere. Quindi, è necessario aggiungere i seguenti metadati:
- ID dipendente: l’ID dell’unità che il manager gestisce.
- ID del Manager: L’ID dell’unità direttamente superiore a questa unità. È l’unità a cui il dipendente si rapporta.
- Descrizione dell’organizzazione: Questa metadata è facoltativa. Consente di creare un nome per l’unità gestita dal dipendente. Può essere il nome della squadra o anche il nome del manager.
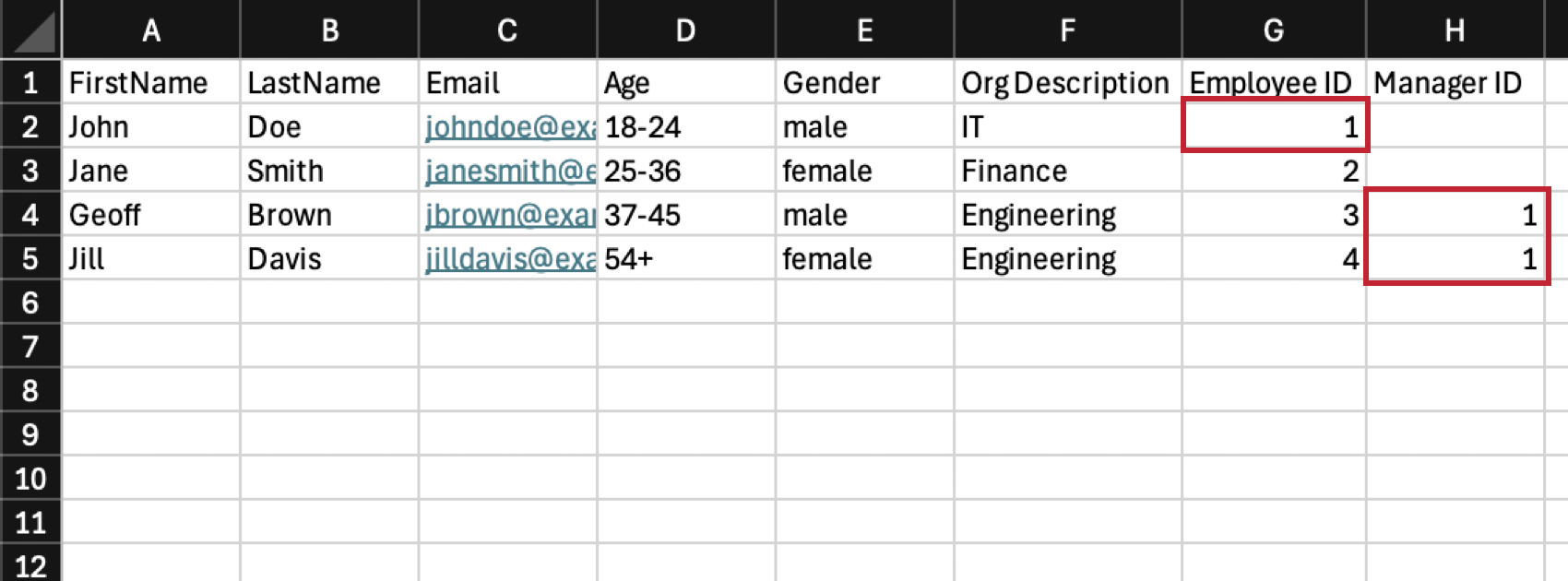
Esempio: Nell’esempio seguente, l’IT è un reparto più grande, sotto il quale è annidata l’Ingegneria. John Doe è il manager di IT, quindi la sua colonna Employee ID dice 1 per indicare che l’ID dell’unità di IT è 1. Geoff Brown e Jill Davis sono i manager di Engineering, quindi entrambi hanno un Manager ID di 1 per indicare che IT è l’unità madre di Engineering.
Rispondenti vs. Non rispondenti
Un rispondente è un partecipante che può rispondere al sondaggio. Un non rispondente è un partecipante che non può accedere al sondaggio. Può essere utile rendere alcuni partecipanti non rispondenti se si desidera che possano visualizzare i risultati del dashboard o convalidare le gerarchie dell’organizzazione, ma non si vuole che compilino un sondaggio.
Si può determinare se il partecipante che si sta aggiungendo è un rispondente al progetto includendo un’intestazione chiamata Rispondente e utilizzando uno dei seguenti valori:
- 0 – Non rispondente
- 1 – Rispondente
Se non si include la colonna Rispondente nel file, tutti i nuovi partecipanti saranno impostati come rispondenti per impostazione predefinita. Se qualcuno è già presente nel progetto, il suo stato verrà aggiornato solo se specificato.
Caratteri massimi e supportati
Caratteri massimi per ogni campo
- Nome: 50 caratteri per ogni nome.
- Cognome: 50 caratteri per ogni cognome.
- Email: 100 caratteri per ogni e-mail.
- Identificatore univoco: 100 caratteri per ogni identificatore unico.
- Tutti gli altri metadati: I nomi dei metadati hanno un limite di 90 caratteri, mentre i valori hanno un limite di 1000 caratteri.
Caratteri parzialmente supportati
I seguenti caratteri non devono essere utilizzati nei nomi o nei valori dei metadati:
|
\
&
;
$
%
< >
( )
{ }
*
+
,È possibile utilizzare una barra in avanti ( / ) nei valori di campi come le date, ma non è possibile utilizzarla nel nome campo dei metadati.
Nomi di campi di metadata con restrizioni
Se il file del partecipante contiene campi con questi nomi o prefissi, questi campi non verranno importati e i dati verranno saltati.
Non è possibile utilizzare i seguenti nomi campo dei metadati:
finished
q_units
sid
responsesetid
rid
threesixtyid
enddate
auditable
personid
_cacheddate
userid
_recordid
firstname
_recordeddate
lastname
_enddate
e-mail
_startdate
userpassword
_sourceid
password
_sourcemapid
external
_sourcetype
q_primaryunits
uniqueid
uniqueidentifier
loginnameI seguenti prefissi non possono essere usati nei nomi dei campi dei metadati:
dichiarazione
dichiarazione grezza
_