-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Clustering MaxDiff
Informazioni su MaxDiff Clustering
All’interno delle popolazioni che hanno risposto al sondaggio ci sono gruppi di persone che la pensano allo stesso modo. Questi gruppi, o “cluster”, possono essere determinati in base alla somiglianza delle funzioni preferite da ciascun intervistato. Clusterizzando ogni intervistato in base alla sua utilità individuale per ogni attributo, possiamo determinare le sottopopolazioni e i dati demografici che le compongono.
Preparazione di un sondaggio per il Cluster
Prima di poter utilizzare il clustering di MaxDiff, è necessario assicurarsi che il sondaggio del progetto MaxDiff ponga le domande giuste. Ciò significa che è necessario impostare alcune funzioni prima di raccogliere i dati.
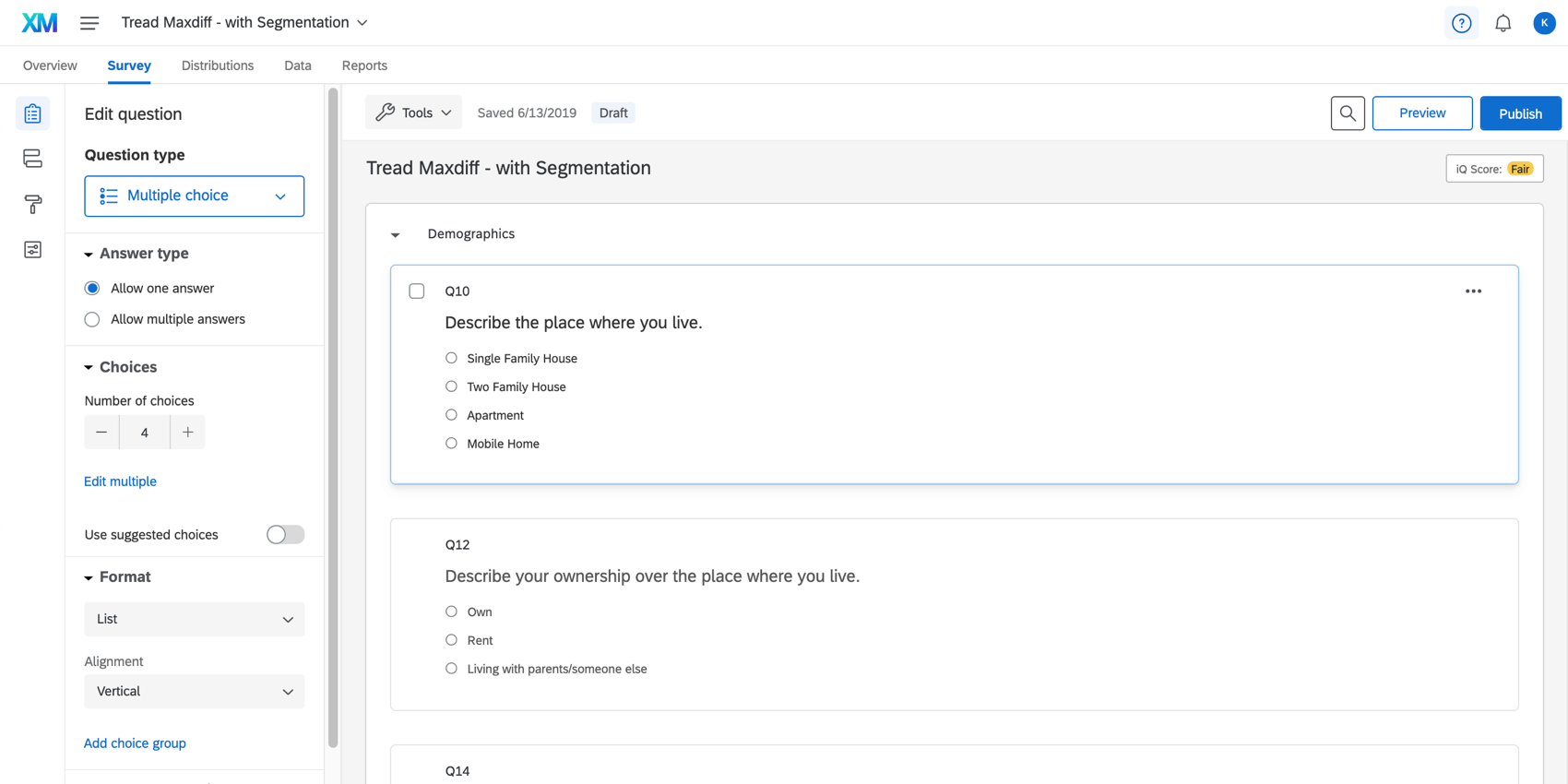
Nella scheda Sondaggio, assicurarsi di aver aggiunto le domande a un blocco non MaxDiff. Nell’esempio seguente, il blocco Demografia contiene una domanda sull’età, sul numero di persone nel nucleo familiare dell’intervistato e altro ancora.
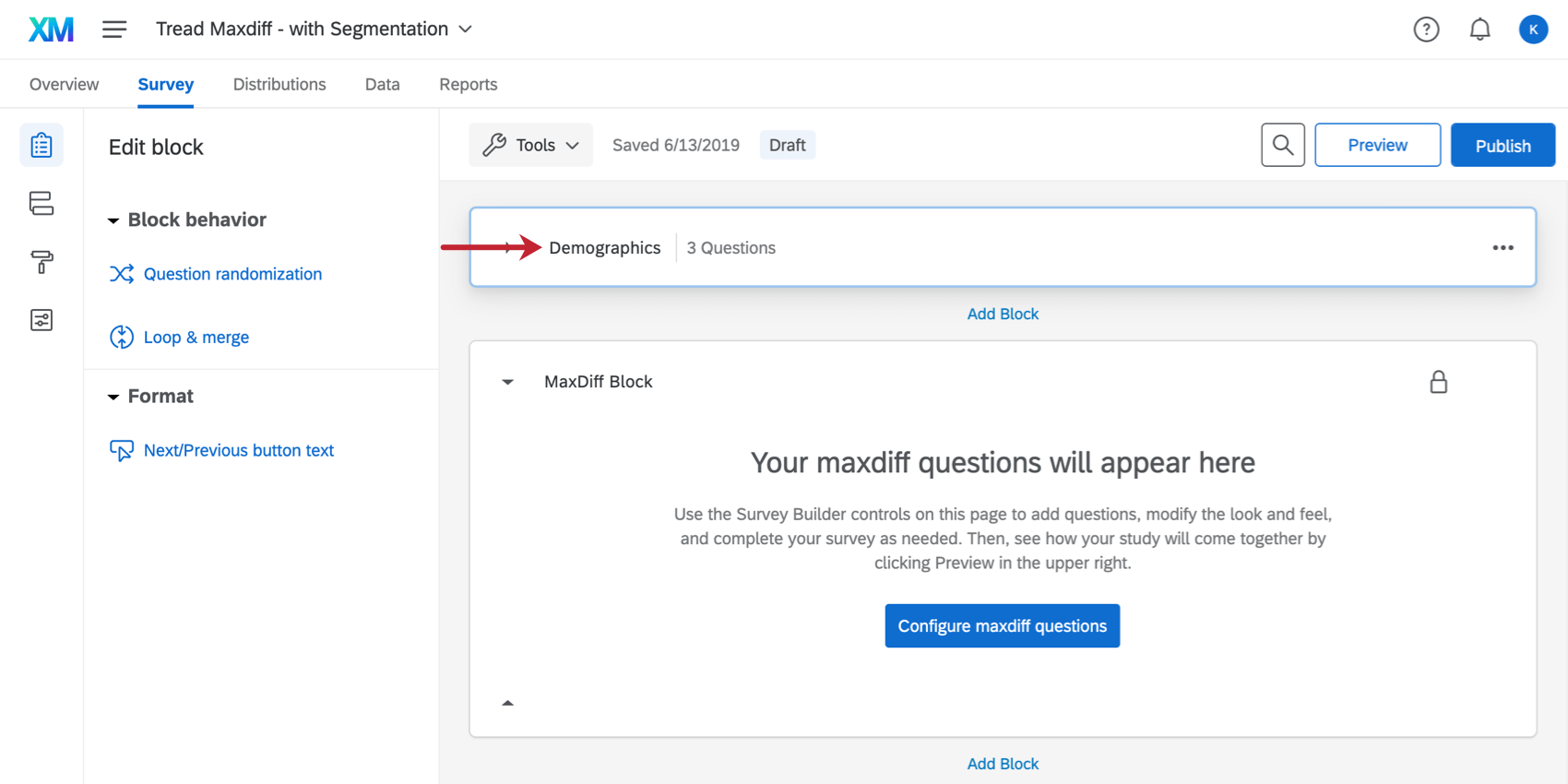
Il blocco Demographics si trova proprio sopra il blocco MaxDiff, anche se è possibile spostarlo a piacere.
Formattazione delle domande
È possibile eseguire il clustering MaxDiff solo con domande a scelta multipla a selezione singola. Questo perché offrono una scelta finita che può essere facilmente analizzata.
- Dati demografici: Chiedere informazioni descrittive di base, come l’età, la fascia di reddito, la razza o il sesso.
- Comportamento: Chiedete come i clienti interagiscono con il vostro brand e i vostri prodotti, o quali comportamenti possono essere correlati al loro comportamento d’acquisto. Ad esempio, si può chiedere quanto spesso il cliente va a fare la spesa.
- Datioperativi : Si tratta di informazioni come il tempo trascorso sul vostro sito web o la permanenza di un dipendente nella vostra azienda.
- Formati delle domande: Formare le domande sui comportamenti e le convinzioni come scale. L’intervallo di una scala può aiutarci a capire quali punti di valutazione sono correlati e quindi approssimativamente nello stesso cluster; le domande Sì/No e a selezione singola non sono altrettanto utili per l’analisi dei cluster.
Esempio: Se si chiede “Che tipo di acquirente sei?” e si danno le opzioni “Preferisco fare acquisti nei centri commerciali”, “Preferisco fare acquisti online” e “Preferisco fare acquisti nelle boutique”, l’algoritmo di clustering vorrà dividere gli intervistati in tre gruppi, uno per ogni risposta. Se invece si pone una serie di domande (ad esempio, “Le piace fare shopping nei centri commerciali?”) con risposte da 1 a 7, l’algoritmo di clustering farà un lavoro migliore per discernere realmente ciò che separa i diversi acquirenti gli uni dagli altri.
Abilitazione dei cluster
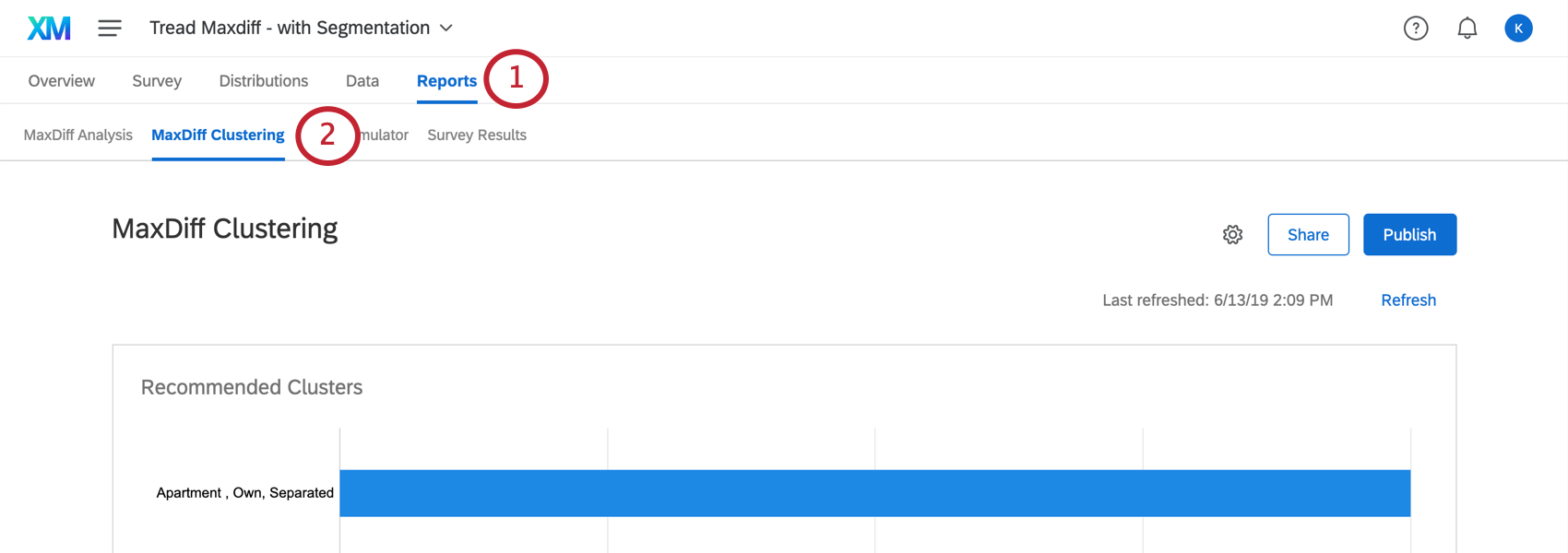
Il clustering si trova nella sezione MaxDiff Clustering della scheda Rapporti .
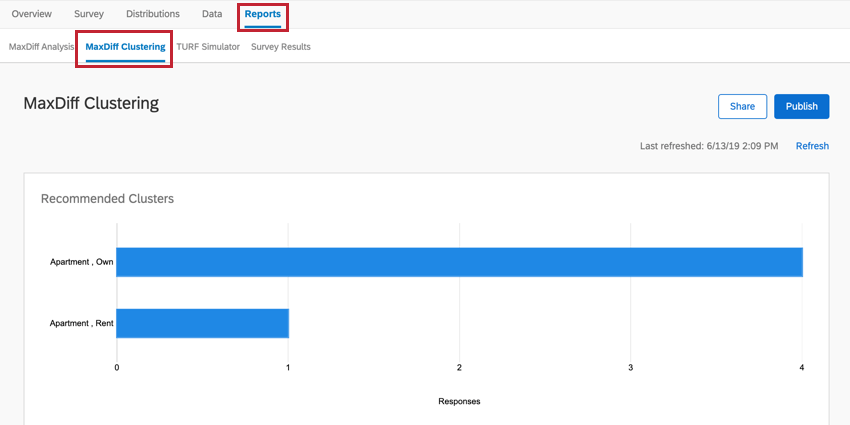
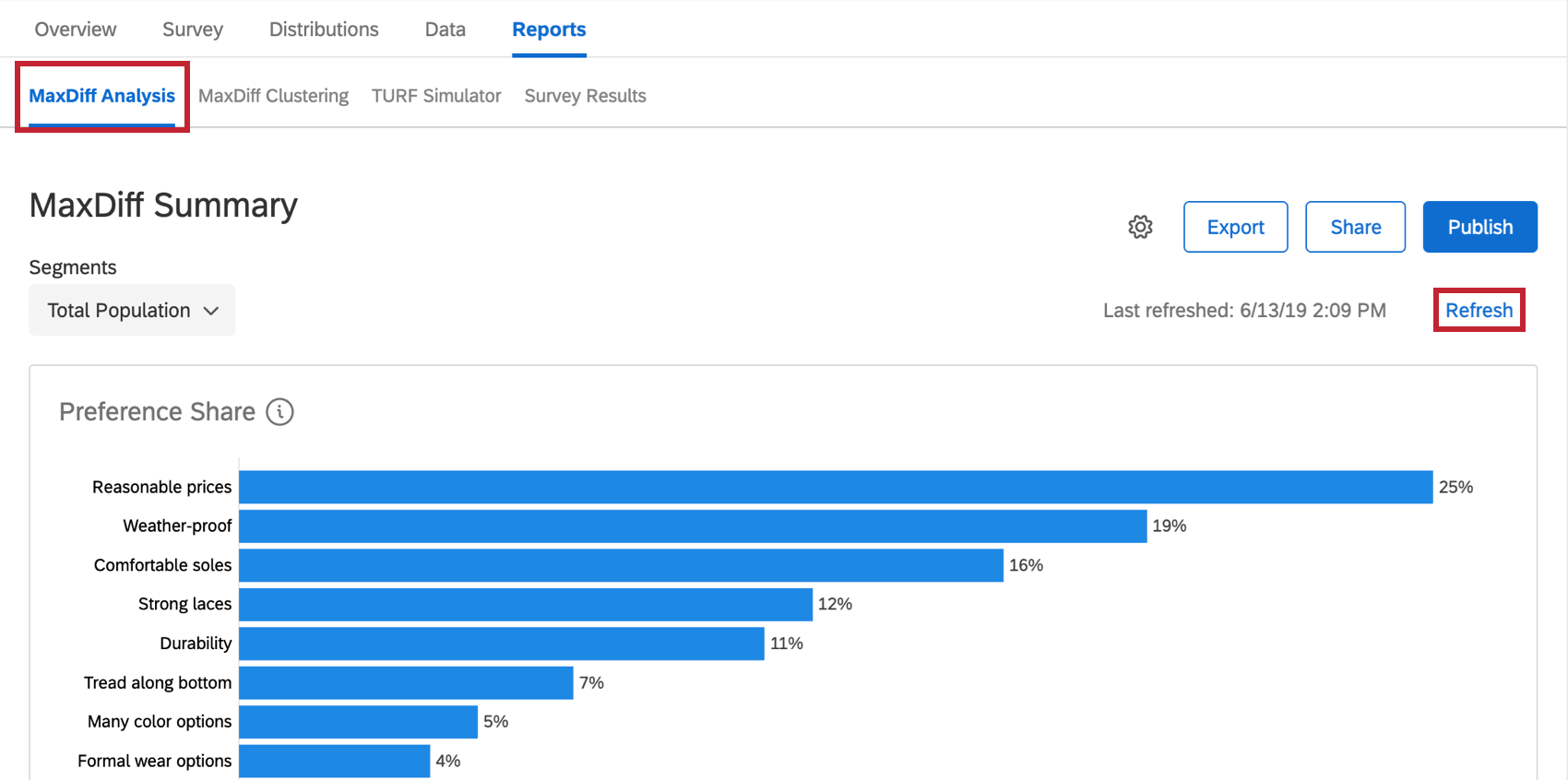
Per far apparire i dati la prima volta, potrebbe essere necessario cliccare su Aggiorna nella sezione Analisi di MaxDiff .
Regolazione dei dati demografici utilizzati per il Cluster
Per impostazione predefinita, MaxDiff clustering utilizzerà tutte le domande a scelta multipla del sondaggio. Tuttavia, non è necessario utilizzare tutte le domande se non si vuole, e si possono aggiungere e rimuovere contenuti per vedere quali cluster diversi la funzione consiglia.
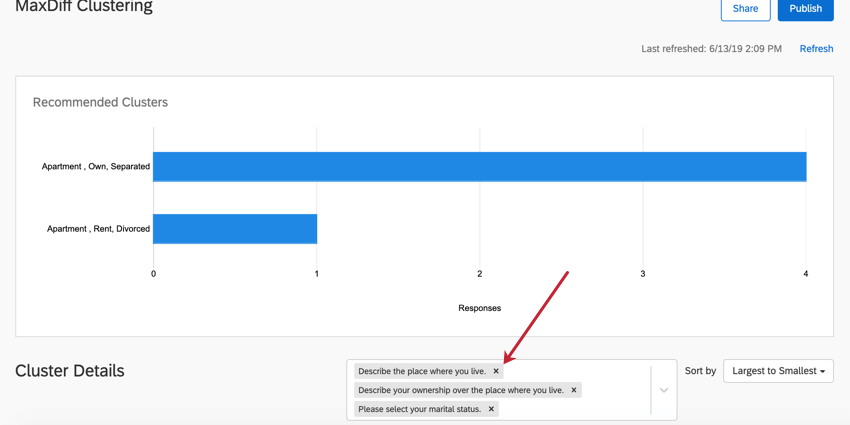
Rimozione dei dati demografici
Nel riquadro a destra dell’intestazione Dettagli cluster, fare clic sulla X di una domanda per rimuoverla dall’analisi dei cluster. La rimozione di una domanda non provoca il ricalcolo dei cluster.
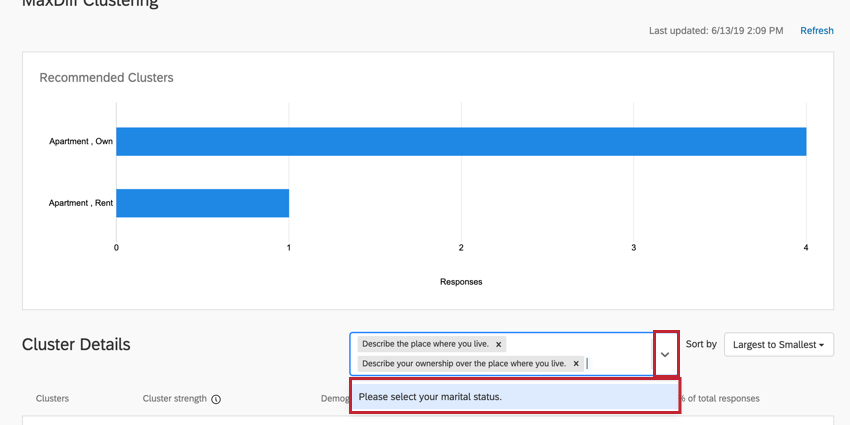
Aggiunta di dati demografici
Nella casella a destra dell’intestazione Dettagli cluster, fare clic sulla freccia a discesa. Quindi selezionate le domande che desiderate aggiungere ai cluster.
Cluster consigliati
Una volta raccolti dati sufficienti e aggiornata la pagina di MaxDiff dedicata al cluster, questa funzione vi consiglierà i cluster. Questi cluster sono determinati in base alla somiglianza delle funzioni preferite dagli intervistati. Viene calcolata la loro utilità individuale per ogni attributo e vengono evidenziati i dati demografici comuni a questi cluster, in modo da comprendere meglio come le diverse popolazioni preferiscono i vostri prodotti.
Evidenzia testo un cluster nel grafico superiore per saperne di più su questo cluster. Fare clic su di esso per aprire i dettagli del cluster in basso.
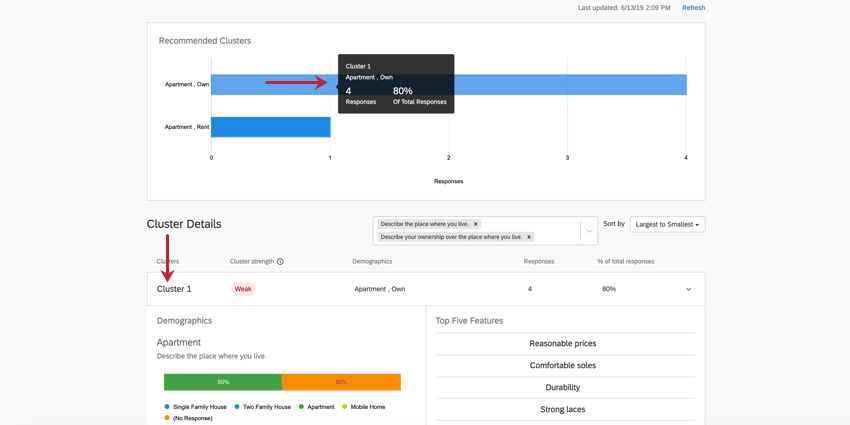
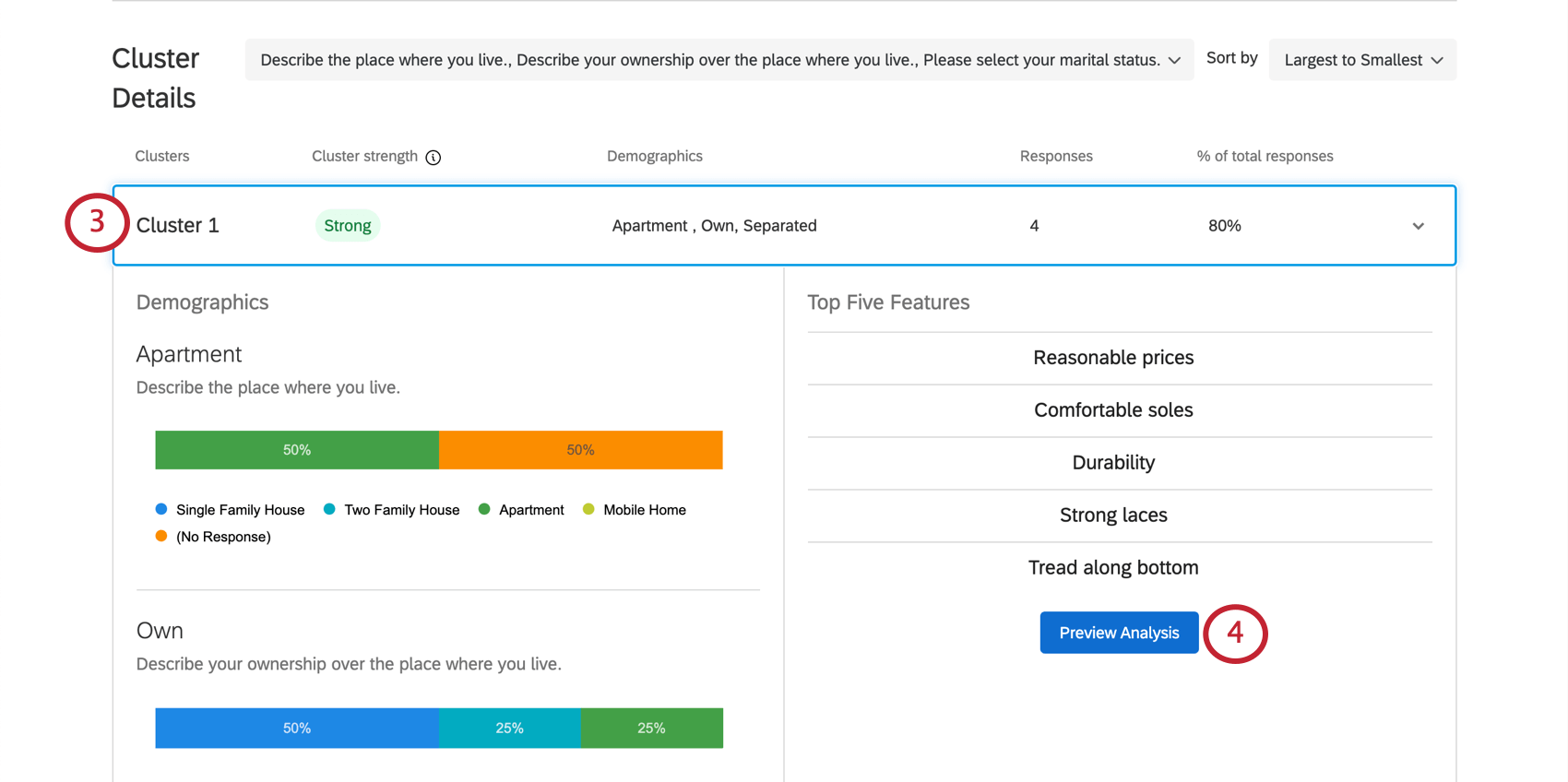
Dettagli cluster
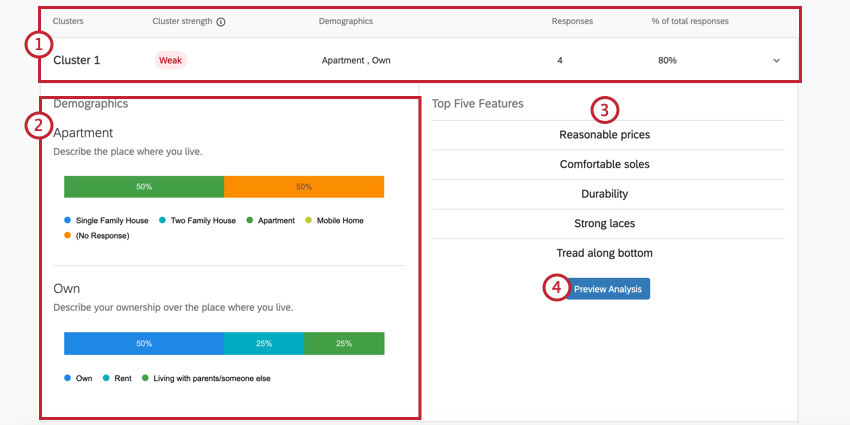
- RIEPILOGO DELLE RISPOSTE: La barra superiore dei dettagli del cluster fornisce un rapido riepilogo delle risposte più importanti, in primo luogo di quale cluster si tratta, della significatività statistica del cluster, di come i rispondenti hanno risposto in generale alle domande demografiche, del numero di risposte presenti in questo cluster e della percentuale di risposte a cui si applica questo cluster. È inoltre possibile fare clic su questa parte per espandere e ridurre il resto delle informazioni.
Esempio: Nel Cluster 1 qui raffigurato, le risposte tendono a provenire da persone che possiedono un appartamento di proprietà. 4 intervistati corrispondono generalmente a questo schema, ovvero l’80% dell’intero set di dati. Si tratta di un set di dati molto piccolo, quindi è probabile che non si debbano prendere decisioni sulla base di questi risultati. Ciò è indicato anche dalla debolezza del cluster.
- Dati demografici: Una serie di barre di suddivisione che mostrano come i membri di questo cluster hanno risposto alle domande demografiche. Ogni barra di suddivisione è etichettata con la risposta più correlata ai punteggi di utilità per le funzioni preferite, ma si può notare che le persone in un cluster variano nel modo in cui hanno risposto.
Esempio: Il reddito annuale del Cluster 1 è elencato come “20.000 – 29.000 dollari” Tuttavia, questo non è il reddito annuale più comune per questo cluster, come si può vedere dalla barra “70.000 – 79.000 dollari” alla fine è molto più lunga. Questo perché chi ha un reddito più basso ha semplicemente maggiori probabilità di valutare prezzi ragionevoli, durata e così via, rispetto a chi nel cluster ha un reddito annuo più elevato.
- Le cinque funzioni principali: Queste sono le cinque funzioni che i membri del Cluster hanno indicato con maggiore probabilità come le preferite quando hanno selezionato le funzioni da una lista. I dati demografici evidenziati hanno punteggi di utilità elevati per gli attributi qui scelti.
- Anteprima dell’analisi: Fare clic su questo pulsante per visualizzare il report dell’analisi MaxDiff solo per i dati di questo cluster.
Determinazione della forza del cluster
Qualtrics utilizza una metrica chiamata punteggio silhouette per determinare la forza di ciascun cluster. Questo punteggio produce un valore compreso tra 0 e 1 che determina quanto siano strettamente raggruppati i rispondenti. Utilizziamo la seguente tabella per convertire il punteggio della silhouette in forza del cluster:
| Punteggio della correlazione | Forza delle relazioni | Etichetta di forza del cluster |
| 0.71 a 1,0 | Relazioni molto forti | Forte |
| 0.51 a 0,70 | Relazione piuttosto forte | Abbastanza forte |
| 0.26 a 0,50 | Relazione piuttosto debole | Un po’ debole |
| da 0 a 0,25 | Nessuna relazione significativa | Debole |
Applicare i Cluster ai Rapporti
I cluster possono essere applicati al rapporto MaxDiff Analysis, in modo da visualizzare dettagli più specifici su come i rispondenti di questo cluster hanno valutato gli attributi loro presentati.
Nella sezione Analisi MaxDiff della scheda Rapporti, selezionare un cluster dal menu a tendina Segmenti in alto a sinistra.
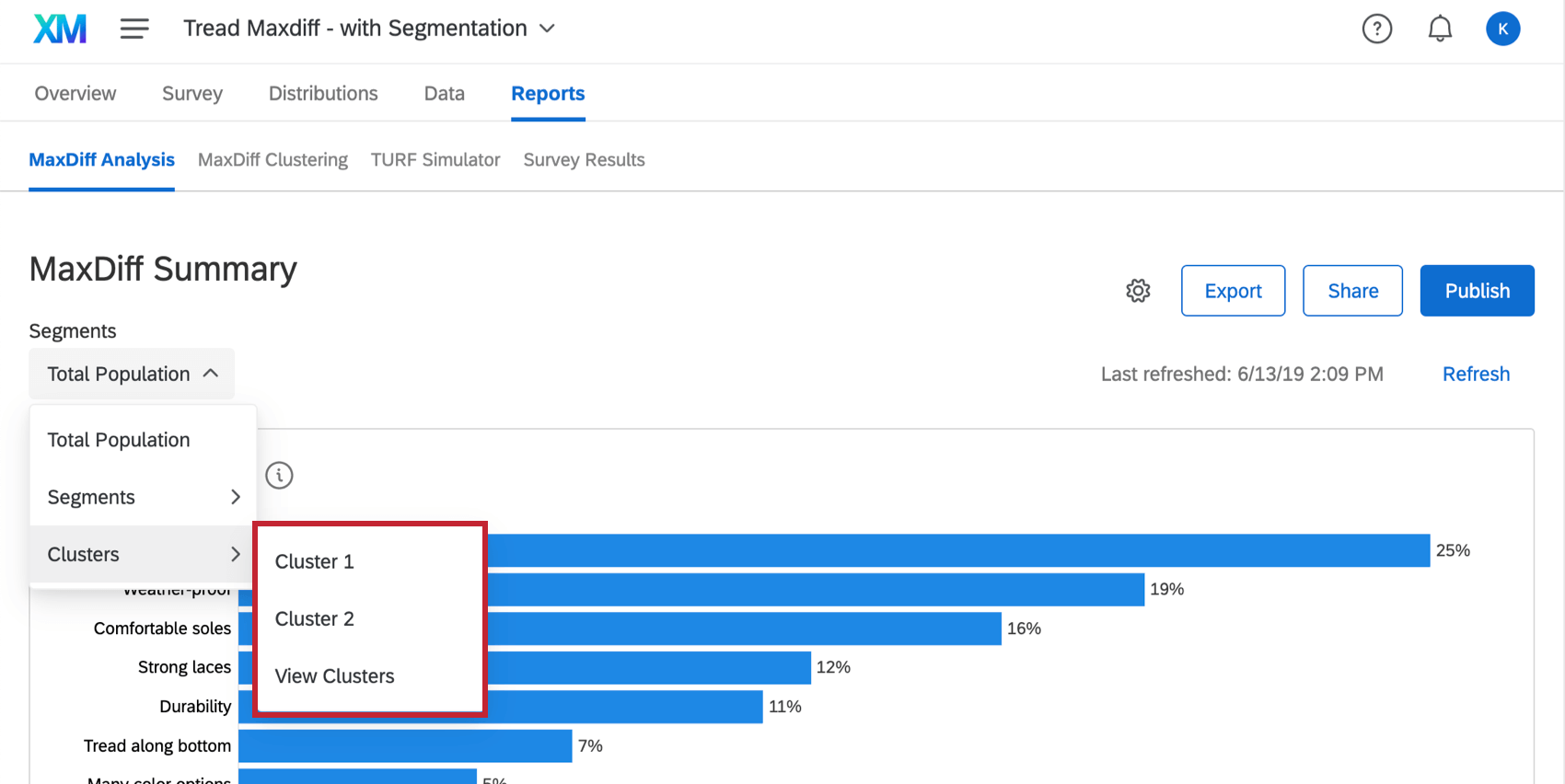
È inoltre possibile selezionare Anteprima analisi quando è stato selezionato un cluster nella sezione MaxDiff Clustering della scheda Rapporti.