Utilizzo e modifica dell'Origine dati del Brand Tracker
Cosa puoi trovare in questa pagina
Informazioni sull’utilizzo e la modifica dell’Origine dati del Brand Tracker
I
programmi BRAND raccolgono dati sul vostro marchio oltre che sui brand della concorrenza e sul mercato in generale, il che rende il set di dati più complesso rispetto ai progetti standard. I programmi BX utilizzano un set di dati impilati (Brand Tracker Data Source, o BTDS) per identificare più facilmente gli insight nei dati.
Conoscere l’Origine dati di BX
Attenzione: L’Origine dati Brand Tracker viene creata come Progetto da dati importati nel Programma BX.
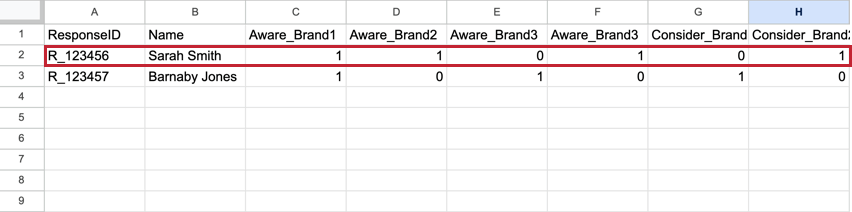
Il BTDS è diverso da quello che si vede in un set di dati standard. In un set di dati standard, ogni intervistato ha una riga che contiene tutte le risposte, con la metrica di ogni brand come colonna a sé stante. Questi set di dati tendono a essere molto ampi, con centinaia di colonne.
Esempio: In questo dataset piatto, c’è una riga di dati per Sarah Smith e una riga di dati per Barnaby Jones. Sono presenti colonne separate per le metriche di ciascun brand.

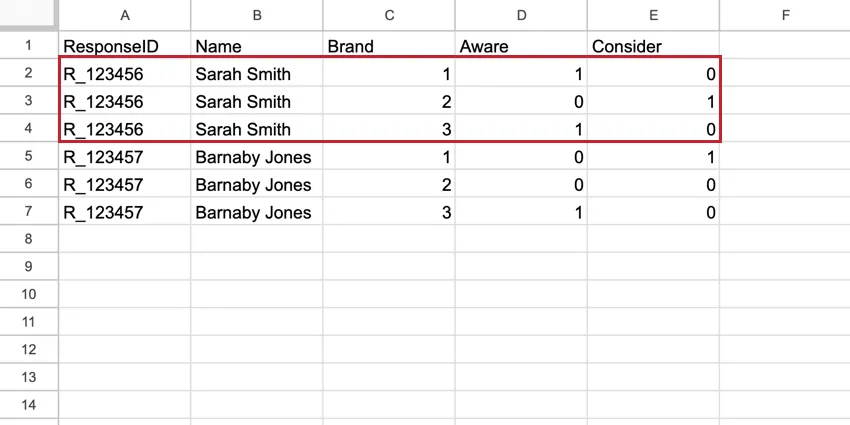
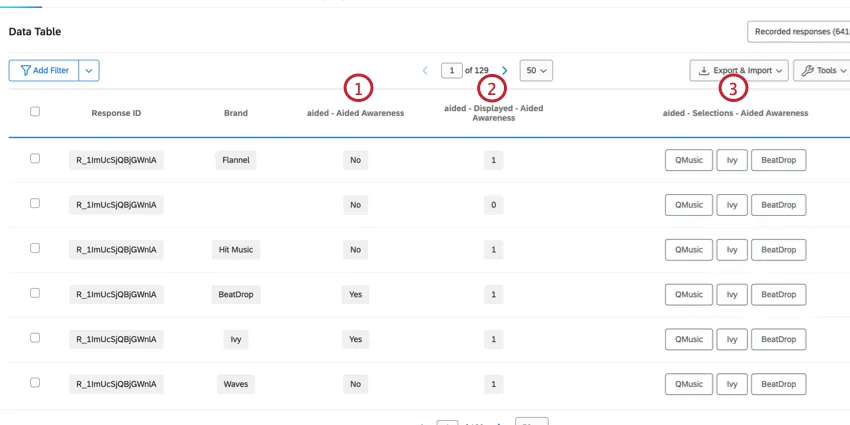
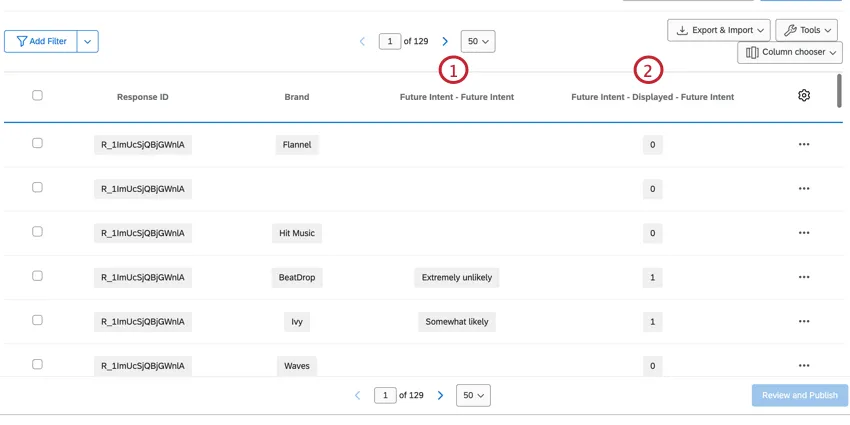
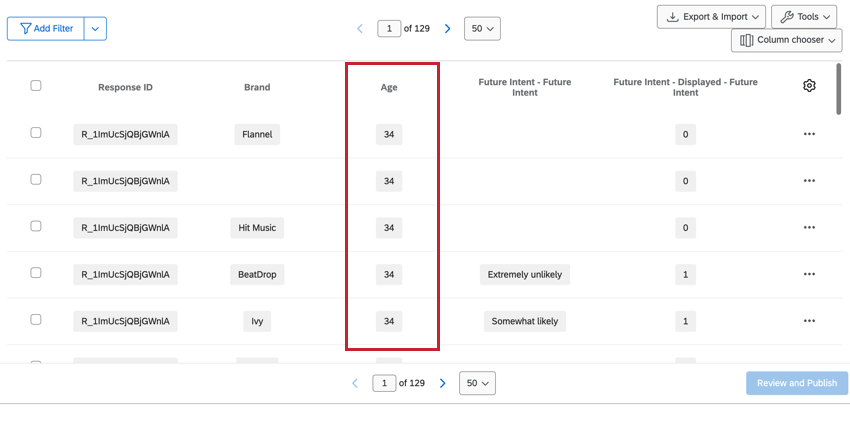
Nel BRAND, il Brand diventa una colonna di prima classe nel dataset e ogni intervistato ha una riga per ogni brand. La riga del brand contiene tutti i dati relativi a quel singolo marchio. Questi set di dati hanno più righe del set di dati standard, ma hanno molte meno colonne, il che li rende più facili da leggere.
Esempio: In questo set di dati impilati, ci sono 5 righe di dati per Sarah Smith, anche se rappresentano solo una risposta. Ogni riga contiene i dati di Sarah per ogni brand misurato.
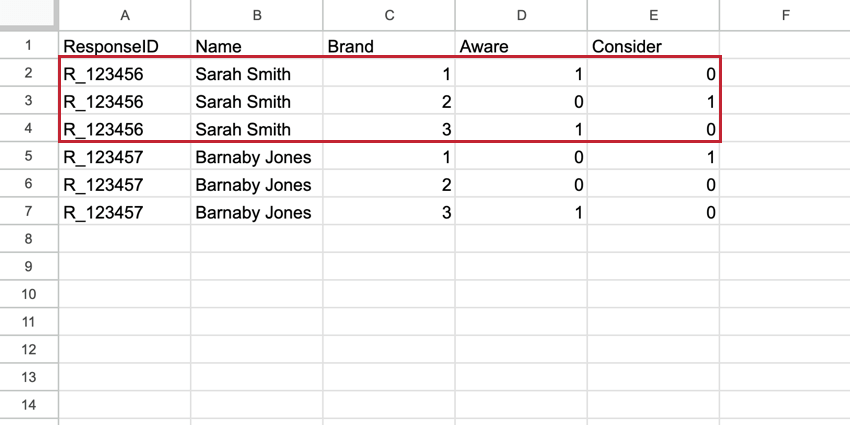
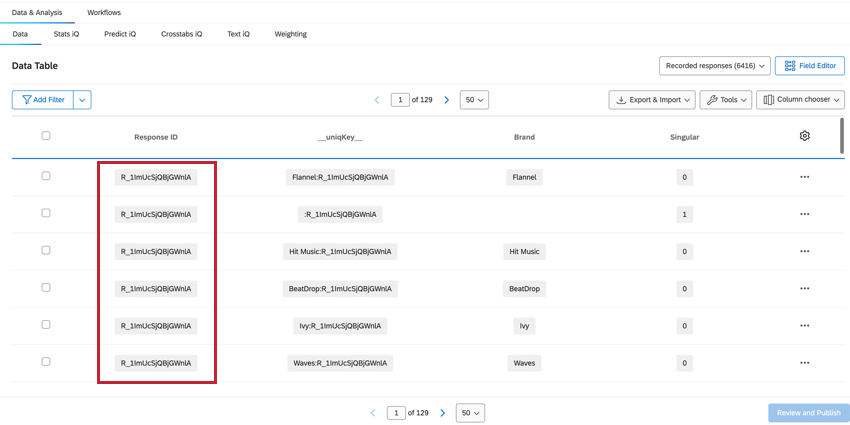
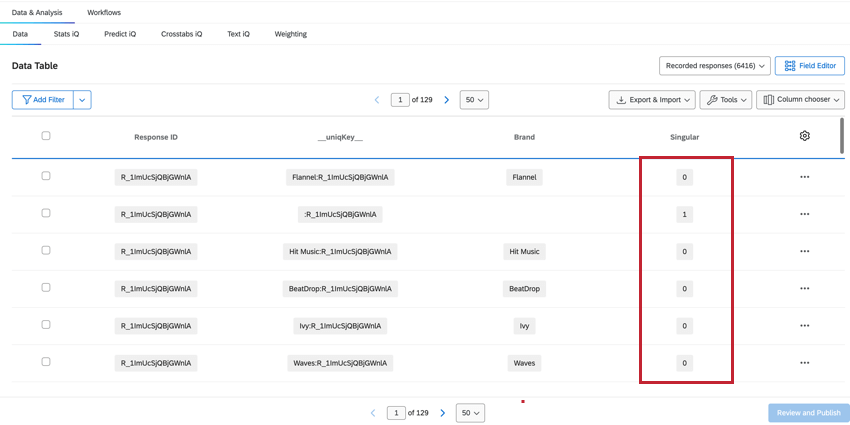
Consiglio q: Poiché i set di dati impilati hanno righe diverse per ogni brand, il conteggio delle risposte registrate nella scheda DATI E ANALISI sarà superiore al numero totale di risposte totali. Per trovare il numero totale di rispondenti unici, creare un filtro per Singolare = 1.
RESPONSEID
Il campo RESPONSEID ci aiuta a identificare le righe che appartengono allo stesso rispondente. Questo valore proviene dall’invio del sondaggio originale e viene ripetuto per ogni riga appartenente a quel rispondente.
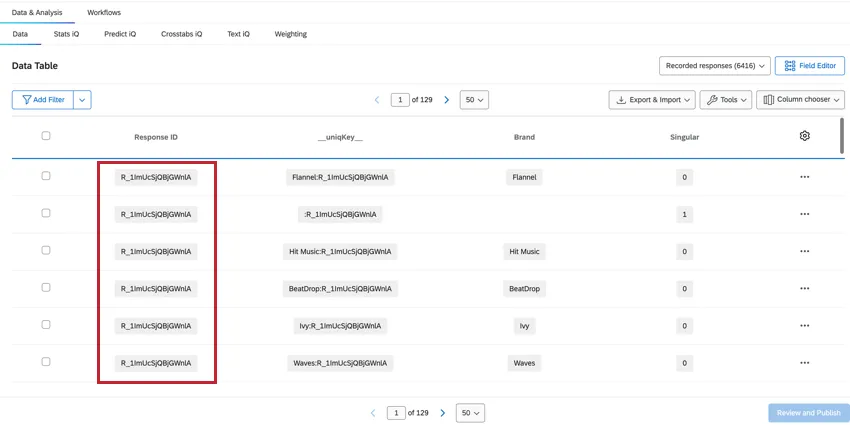
SINGOLO
Il conteggio delle RISPOSTE REGISTRATE nella scheda Dati e analisi fornirà il conteggio totale di tutte le righe, che sarà superiore al numero totale di risposte totali. Per determinare i rispondenti unici, possiamo filtrare per il campo Singolare.
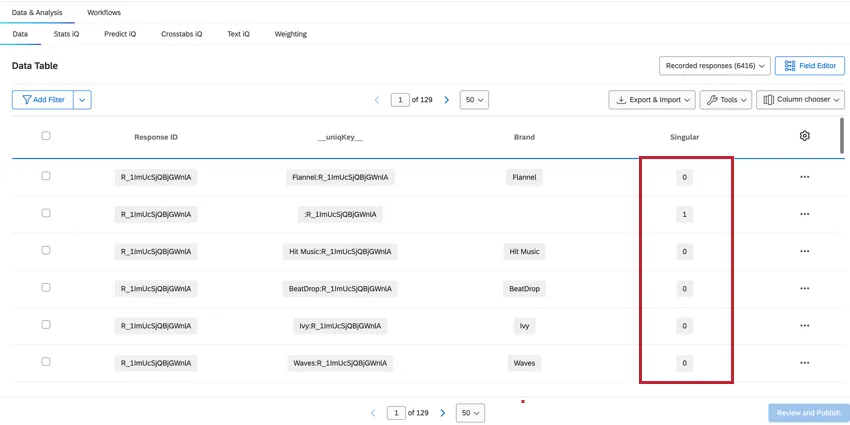
- Quando Singular = 1, vengono mostrate le righe dei rispondenti unici senza informazioni sul brand. Per ogni risposta c’è una riga unica di rispondente. Consiglio Q: Creando un filtro per Singolare = 1, verrà mostrato il numero di singoli rispondenti.

- Quando Singular = 0, la riga contiene i dati del brand. Ci sono più righe di dati relativi al brand per ogni intervistato.
Attenzione: È necessario valutare attentamente se filtrare Singular = 1 o Singular = 0 in base agli obiettivi dei dati nei dashboard. Nella maggior parte dei casi, si desidera filtrare per Singular = 0 per escludere le righe extra non brand dalla dimensione di base e prevenire l’imprecisione dei dati. In alternativa, se si vogliono mostrare i conteggi reali dei dati a livello di rispondenti, si deve filtrare per Singular = 1.
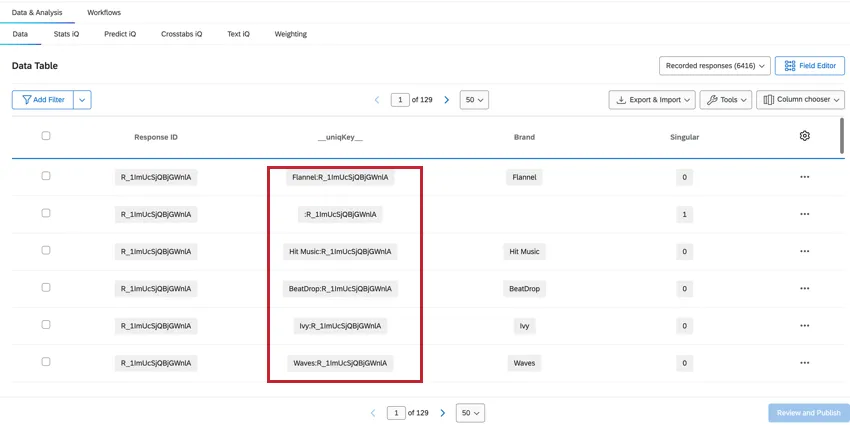
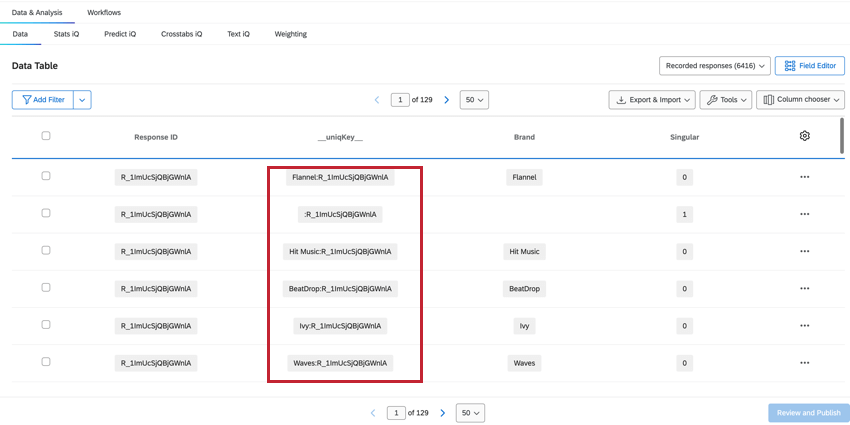
UNIQKEY
Il campo __uniqKey__ combina il ResponseID e il nome del marchio, indicato come BrandName:ResponseID. Per la riga unica del rispondente senza informazioni sul brand, la stessa riga in cui Singular = 1, la __uniqKey__ sarà :ResponseID. Questo è utile per restringere l’esatta risposta di questi dati, nonché il brand a cui danno un feedback specifico.
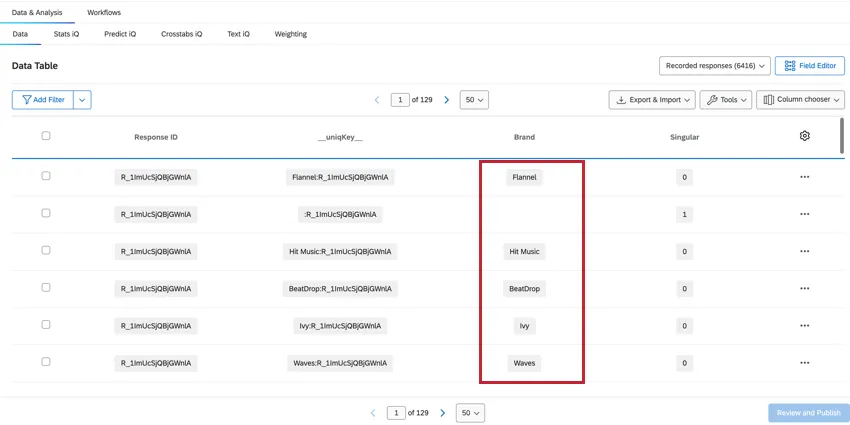
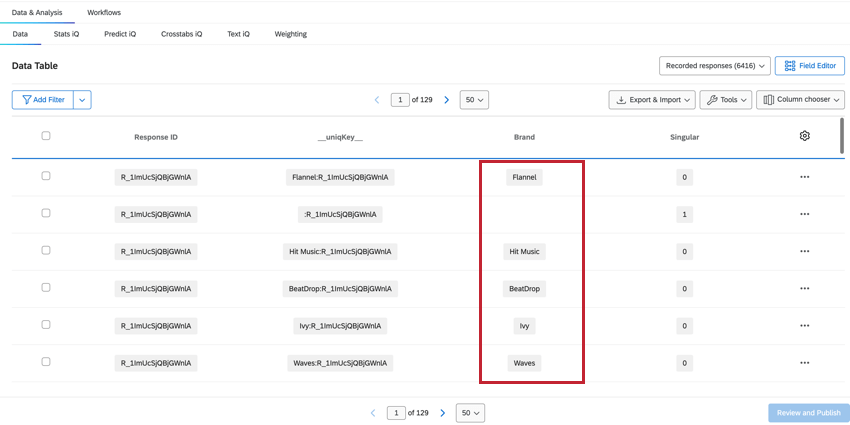
BRAND
Il campo Brand mostra a quale marchio si riferiscono i dati di quella colonna, consentendo di visualizzare e filtrare facilmente i dati relativi al brand.
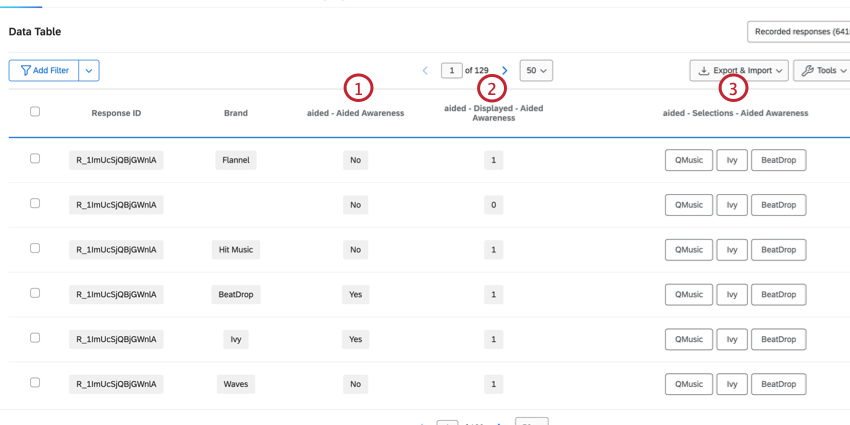
DATI MULTI-SELEZIONE GUIDATI DAGLI ATTRIBUTI
Le domande guidate dagli attributi contengono i brand come scelte della domanda. Si tratta in genere di domande a selezione multipla e di colonne multiple con i dati corrispondenti alla domanda.
Esempio: Un esempio comune di questi tipi di domande è la domanda “Consapevolezza assistita”.
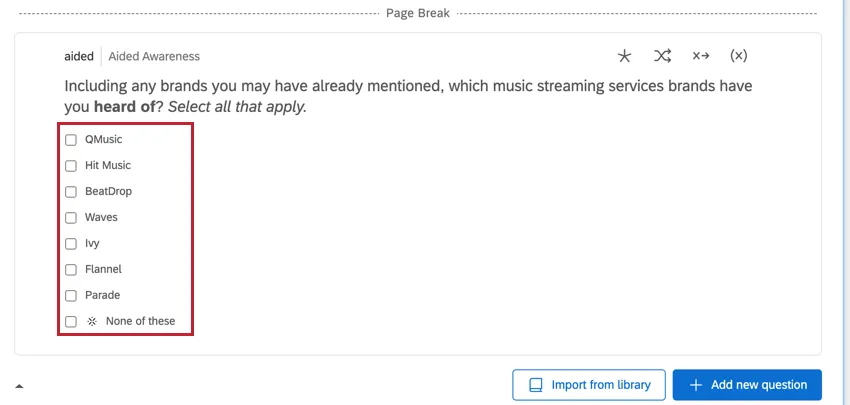
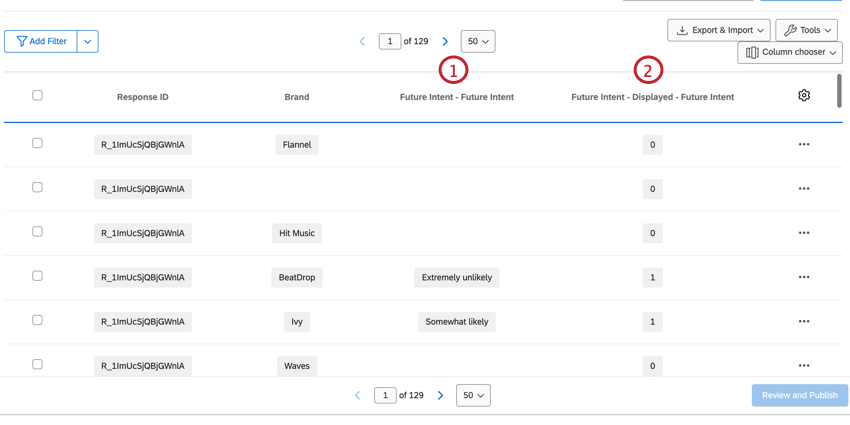
RIPETI E UNISCI I DATI DELLE DOMANDE
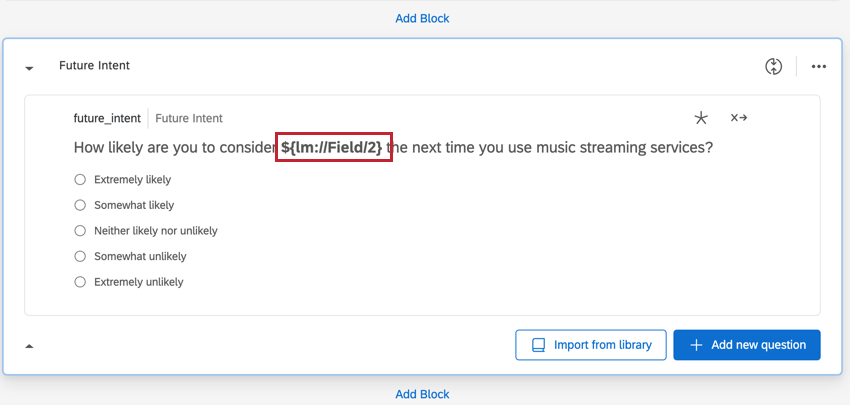
Ci sono anche colonne multiple per le domande che inseriscono il nome del brand usando Ripeti e unisci.
Esempio: Un esempio di questo tipo di domanda è la domanda “Intento futuro”.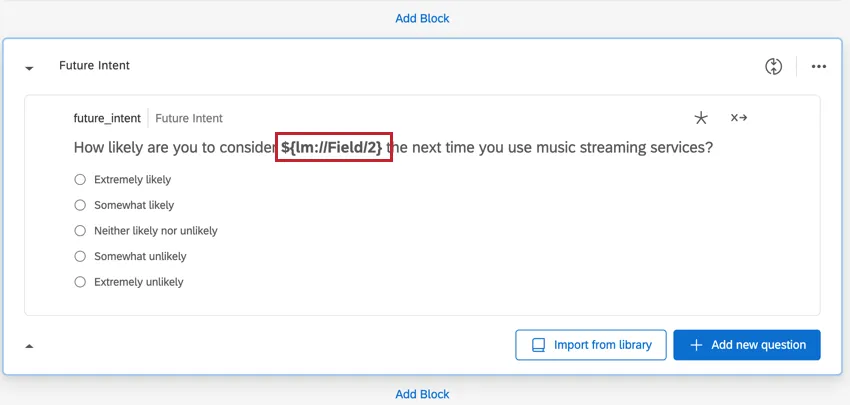
DATI NON IMPILATI
I dati non impilati non sono legati al brand, come le domande standard (ad esempio, i dati demografici) e i campi dati integrati non impilati. Questi campi sono ripetuti per ogni brand, in modo che i dati siano disponibili sia per un marchio specifico che per tutti i brand.
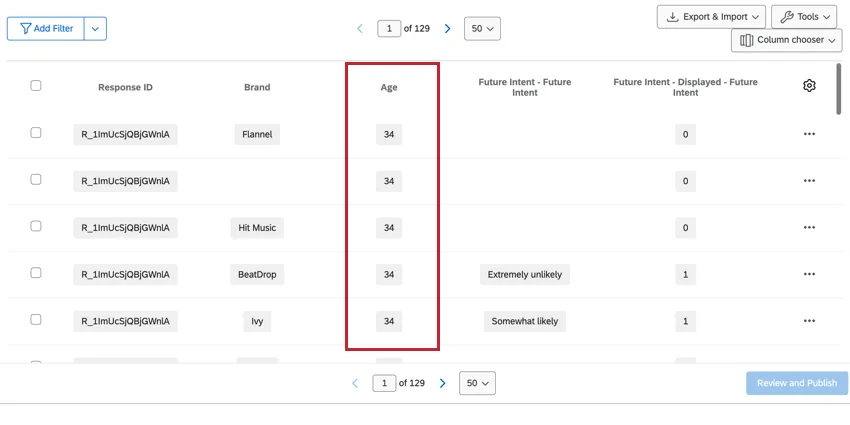
Consiglio Q: Le domande a selezione multipla che utilizzano dati non relativi al brand conterranno la lista delle domande selezionate nella stessa colonna. Non vengono memorizzate informazioni sul fatto che il rispondente abbia visto o meno le scelte di risposta.
Generazione del BTDS
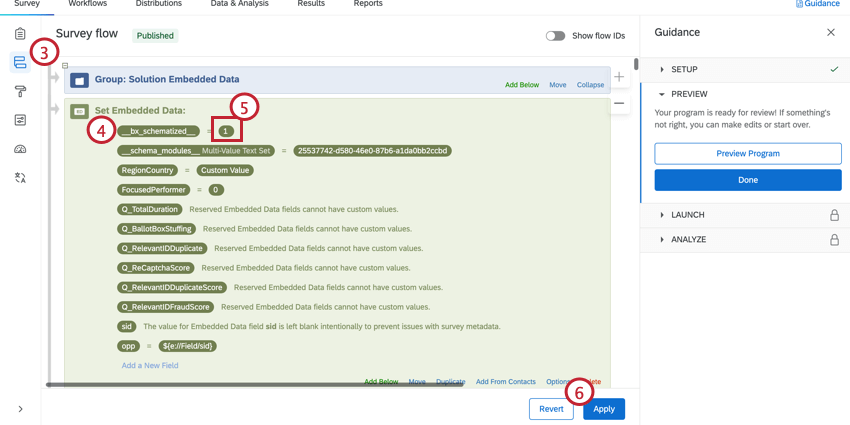
Se si crea un programma BX da zero, l’Origine dati Brand Tracker non viene generata automaticamente e deve essere generata prima della raccolta dei dati. Tutti i dati raccolti prima della generazione del BTDS non saranno impilati.
Consiglio q: si consiglia di generare il SONDAGGIO DI PROVA dopo che il sondaggio è stato completamente programmato e testato. Generarlo prima potrebbe finire per complicare il set di dati con materiale e colonne aggiuntive.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Compatibilità dei set di dati impilati
I set di dati impilati presentano limitazioni sui tipi di campo e sui tipi di domanda più adatti all’elaborazione dei dati. Durante la creazione del programma BX, è importante assicurarsi che la struttura del sondaggio sia compatibile con il BTDS che verrà generato.
Il BTDS è compatibile con i seguenti tipi di domande:
- Scelta multipla (singola e multi-selezione)
- Immissione di testo, Matrice
- Testo descrittivo
- Somma costante
- Cursore
- Ordine di classificazione
- Metainformazioni
Attenzione: L’uso di tipi di domande incompatibili può causare l’impilamento dei dati in modi imprevisti o l’assenza di impilamento.
Filtro ed esportazione del BTDS
Il filtro e l’esportazione del BTDS funzionano come il filtro e l’esportazione dalla scheda Dati e analisi. Queste operazioni possono essere utili per comprendere meglio gli insight del dashboard, per ridurre le dimensioni del dataset o per visualizzare sottosezioni specifiche del dataset impilato.
Consiglio Q: Il filtro per Singolare = 0 raffinerà il set di dati per includere solo le risposte uniche per il programma BX. Il conteggio delle risposte deve corrispondere ai dati del progetto di sondaggio del programma.
Ottimizzazione
I programmi BRAND con grandi liste di brand possono creare set di dati più grandi del necessario. Con l’ottimizzazione dei brand, è possibile limitare i dati ai soli brand significativi.
Esempio: Supponiamo che stiate facendo una ricerca sui brand sia negli Stati Uniti che in Canada. I brand di interesse negli Stati Uniti sono 10, mentre quelli di interesse in Canada sono solo 4. Il team di ricerca canadese avrebbe usato l’ottimizzazione per isolare i 4 brand e non avrebbe dovuto lavorare con dati inutili.
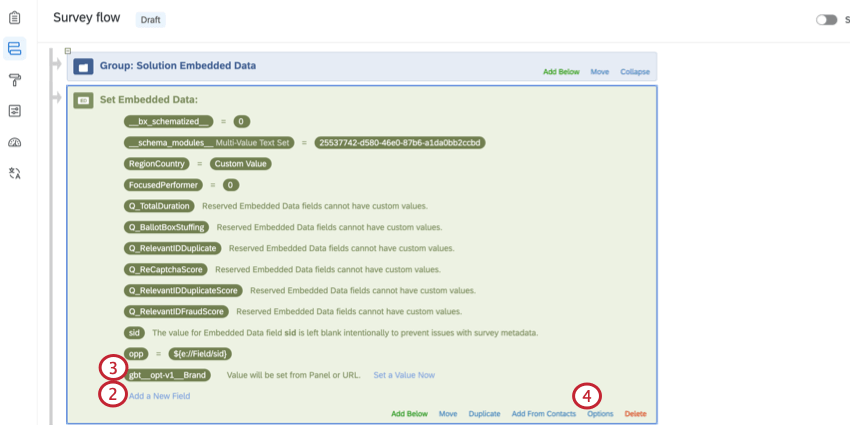
gbt__opt-v1__Marca. 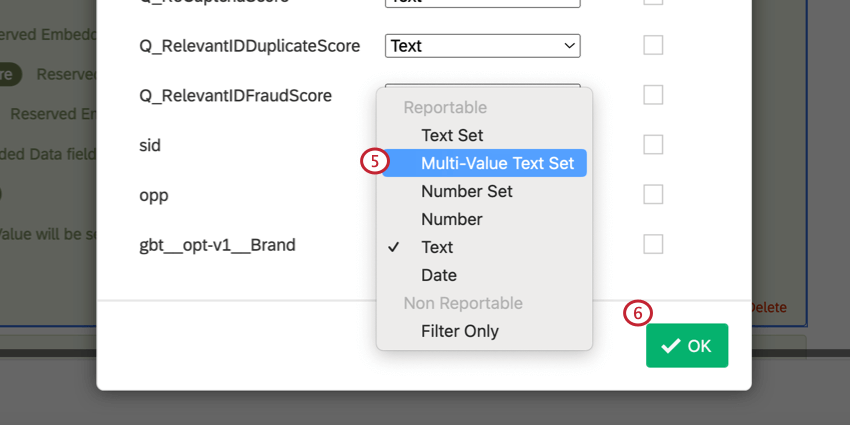
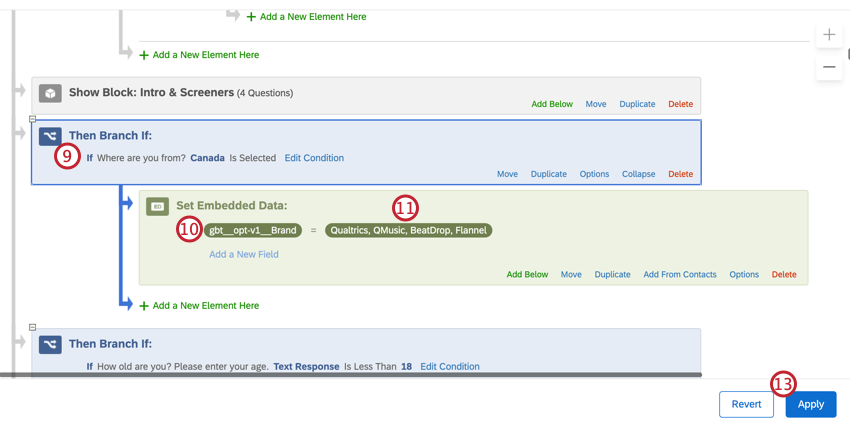
Con la variabile di ottimizzazione definita, il BTDS elaborato rimuoverà le righe non incluse nella lista per quella variabile.
Risoluzione dei problemi con BTDS
Attenzione: Se vengono apportate modifiche al sondaggio dopo la raccolta delle risposte, il BTDS dovrà essere rielaborato per applicare le modifiche alle risposte esistenti.
I problemi comuni con il BTDS includono:
- Il conteggio delle risposte è diverso tra il BTDS e il Sondaggio Dati e analisi.
- Le domande o i campi del brand non sono impilati o lo sono in modo improprio dopo la generazione del BRAND.
NUMERO DI RISPOSTE
Per confrontare i conteggi delle risposte tra il set di dati del sondaggio e il BTDS, filtrare il BTDS per Singular = 1. Confrontare questo conteggio con quello totale del set di dati del sondaggio. Se i dati scorrono correttamente, questi due numeri dovrebbero corrispondere.
Se questi numeri non corrispondono, è possibile che ci siano componenti incompatibili nel sondaggio. Valutare le migliori pratiche dei programmi BX. Se tutti i componenti appaiono corretti, contattare il Supporto Qualtrics con una lista di ID risposta interessati.
NON ACCATASTATI O ACCATASTATI IN MODO IMPROPRIO
Consiglio Q: per ulteriori informazioni sulla programmazione dei set di dati impilati, consultare le Pratiche ottimali per i programmi BX.
- Controllate la lista delle Scelte riutilizzabili e tutte le domande relative ai brand. I brand devono corrispondere esattamente alla lista delle scelte riutilizzabili.
- Assicurarsi che non vi siano sottostringhe all’interno della lista dei marchi (ad esempio, un marchio “Qualtrics” e un altro “Esperienza dei dipendenti di Qualtrics”).
- Assicurarsi che il testo della domanda corrisponda esattamente a ogni domanda che si intende impilare insieme. Campi di testo trasferito diversi per ogni domanda (ad esempio, testo trasferito per loghi diversi per ogni brand) impediranno di sovrapporre le domande, cosa particolarmente comune nelle domande Matrice.
- Controllare i risultati di Expert Review > Data Stacking per vedere se ci sono problemi segnalati.
FAQs
Quando i BTDS assegnano uno zero o un “Null”?
Quando i BTDS assegnano uno zero o un “Null”?
- Se una domanda non viene visualizzata a un partecipante, il BTDS assegna un valore “Null”.
- Se una domanda sul marchio guidata da attributi viene mostrata a un intervistato, il BTDS assegna uno zero se il marchio non è selezionato, anche se il marchio non è visualizzato.
- Se una domanda guidata da brand non viene visualizzata a un partecipante, il BTDS assegna un valore “Null”.
- Se viene visualizzata una domanda con marchio e non viene fornita alcuna risposta, il BTDS assegna un valore "Null".
- Se una domanda basata su attributi non viene visualizzata a un partecipante, il BTDS assegna un valore “Null”.
- Se viene visualizzata una domanda basata su attributi ma l'opzione di risposta del marchio non lo è, il BTDS assegna uno 0.
È fantastico! Grazie per il tuo feedback!
Grazie per il tuo feedback!