-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Filtrer les données structurées (Designer)
À propos du filtrage par données structurées
Utilisez les attributs de données structurées pour filtrer le retour d’information dans des modèles qui catégorisent et affichent les informations les plus pertinentes de votre ensemble de données. Pour plus d’informations sur la création et la modification des filtres, voir Filtrer les données (Designer).
Filtre par Sentiment
XM Discover utilise l’analyse des sentiments pour déterminer le sentiment général des commentaires. Le sentiment est disponible en tant qu’attribut du système avec des bandes prédéfinies :
- Sentiment négatif: Notation avec un sentiment de -5.0 à -1.0
- Sentiment neutre: Notation du sentiment de -0,99 à 0,99
- Sentiment positif: Notations avec un sentiment de 1 à 5.0
Filtrer par langue
Utilisez les attributs de système de découverte suivants pour filtrer par type de données :
- Langue détectée automatiquement par CB ( _languagedetected ) : Le retour d’information sur la langue a été soumis si votre projet utilise la détection automatique de la langue.
- Langue traitée par CB ( _language ) : La langue dans laquelle le feedback a été soumis. Si la langue n’est pas prise en charge par XM Discover, elle sera marquée comme “OTHER”.
XM Discover est capable de reconnaître et de baliser les données dans plus de 150 langues grâce à la fonction de détection automatique de la langue. Sans détection automatique de la langue, les langues suivantes sont disponibles :
- Arabe
- Bengali
- Chinois (simplifié et traditionnel)
- Néerlandais
- Anglais
- Français
- Allemand
- Hindi
- Indonésien
- Italien
- Japonais
- Coréen
- Polonais
- Portugais
- Roumain
- Russe
- Espagnol
- Suédois
- Tagalog
- Thaï
- Turc
- Vietnamien
Filtrer par type de données
Pour filtrer le retour d’information en fonction du type de données soumises, utilisez les attributs de système suivants :
- Source ID ( _id_source ) : La source de données des phrases.
- Type de verbatim ( _verbatimtype ) : Le nom du champ de verbatim sur lequel vous souhaitez filtrer. Ceci est utile si vous avez plusieurs colonnes de verbatim.
Filtrer par type de contenu
Pour les projets dont la détection du type de contenu est activée, utilisez les attributs système suivants pour filtrer le retour d’information des publicités, du spam et d’autres données ne pouvant donner lieu à une action :
- Type de contenu CB ( cb_content_type ) : Indique si les documents sont marqués comme contenant, c’est-à-dire s’ils contiennent du contenu, ou comme non contenant.
- Sous-type de contenu CB ( cb_content_subtype ) : Regroupe les documents marqués comme non-contenus dans les catégories suivantes : annonces, coupons, liens d’articles ou “non défini”.
Filtrer par type de phrase
XM Discover utilise l’analyse sémantique pour identifier les intentions pertinentes pour vos analyses. Ces catégories sont utilisées dans l’attribut du système au niveau de la phrase : CB Sentence Type ( cb_sentence_type ). L’analyse du type d’intention utilisé dans vos données peut aider à comprendre comment l’expérience client peut être améliorée.
Cliquez sur les types de phrases suivants pour voir ce qui est identifié à l’aide de l’attribut de type de phrase :
- Phrases exploitables
- Suggestions et recommandations sur la manière d’améliorer l’expérience client, ainsi que sur les problèmes nécessitant une attention immédiate.
- Churn : Menace de perdre des clients.
- Demande de l’aide : Demande de l’aide et de l’assistance.
- Demande: Contient une demande implicite ou explicite, telle qu’un appel à l’action ou à l’information.
- Suggestion : Contient une suggestion implicite ou explicite de changer quelque chose.
- Durée d’utilisation: Depuis combien de temps un client utilise un service ou un produit.
- Annulation: Contient une menace ou une intention d’annuler leur adhésion, service ou autre transaction. Ce type d’assurance couvre également les cas de non-renouvellement, de désinscription ou de résiliation.
- Phrases liées au sentiment
- Identifie le sentiment des phrases qui ne contiennent pas de recommandations exploitables.
- Apathique: N’exprime aucun intérêt ou préoccupation.
- Négatif générique: Sentiment négatif qui n’a pas de cible précise.
- Éloge générique: Sentiment positif dépourvu de cible spécifique.
- Recommande: Recommande l’expérience de ce client.
- A déconseiller : Déconseille l’expérience de ce client.
- Phrases questions/réponses
- Types de retour d’information obtenus en répondant aux questions de l’Enquête.
- Excuses: Contient des excuses explicites.
- Référence croisée: Fait référence à un commentaire ou à une réponse précédente.
- Je ne sais pas: Le retour d’information n’est pas en mesure de fournir une réponse. Par exemple, “J’aurais aimé savoir”.
- Tout: les réponses qui couvrent toutes les options proposées.
- Liste: Contient une liste d’éléments.
- Pas de commentaire: Le répondant refuse de commenter ou de laisser une réponse. Par exemple, “N/A”.
- Oui: contient des affirmations génériques.
- Phrases de remarques sociales
- Rétroaction liée aux aspects sociaux de l’interaction avec le client, tels que les salutations, les rires et la gratitude.
- Bonjour/au revoir : Salutations et au revoir.
- Rire: L’expression du rire, soit verbalement, soit par l’utilisation d’emojis. Par exemple, “Haha ! xD”.
- Remerciements: Les expressions de gratitude.
- Phrases de divulgation légale
- Retour d’information contenant des mentions légales.
- Divulgation: Contient des déclarations d’information. Par exemple, “Cet appel peut être écouté ou enregistré”
- Mini-Miranda: Applicable aux États-Unis, contient un avertissement juridique Mini-Miranda. Par exemple, “L’objectif de la communication est de recouvrer une dette”
- Phrases spécifiques à la conversation
- Feedback spécifique aux conversations du centre de contact. Ces types de phrases ne sont disponibles qu’avec les données conversationnelles.
- Empathie: l’empathie est exprimée, par exemple en présentant des excuses, en manifestant de l’intérêt ou en reconnaissant les difficultés.
- Mise en attente : Les clients sont mis en attente.
- Transfert: Les clients demandent à être transférés ou les représentants transfèrent un client.
Filtrer par nombre de mots
Utilisez les attributs “nombre de mots de la phrase” ou “nombre de mots du document” pour filtrer vos données en fonction du nombre de mots de la phrase ou de l’enregistrement. La fourchette définie dans ces attributs est inclusive de valeurs. Si le nombre de mots est égal à zéro, la phrase/l’enregistrement ne contient pas de texte ou a été chargé(e) avant que la fonction ne soit activée.
- CB Sentence Word Count ( cb_sentence_word_count ) : L’attribut au niveau de la phrase vous permet de filtrer les données en fonction du nombre de mots dans une phrase.
Astuce: Pour afficher les phrases de 10 mots ou moins, utilisez la plage cb_sentence_word_count : [1 TO 10].
- Nombre de mots du document CB ( cb_document_word_count ) : Cet attribut au niveau de l’enregistrement permet de filtrer les données en fonction du nombre de mots dans un enregistrement. Il s’agit également de la somme de tous les mots de la phrase.
Astuce: Pour afficher les documents contenant 50 mots ou plus, utilisez cb_document_word_count : [50 TO 200].
Filtre par quartile de phrase
L’attribut CB Sentence Quartile ( cb_sentence_quartile ) identifie la partie du verbatim dans laquelle une phrase s’inscrit. Les valeurs sont comprises entre 1 et 4, chaque section représentant 25 % de la longueur du verbatim. Si un enregistrement comporte plusieurs verbatims, il y aura des quartiles pour chaque verbatim de l’enregistrement.
Appliquer la phrase Quartile
Si vos données historiques ne contiennent pas de données sur les quartiles de peine, vous pouvez les ajouter à vos données.
- Accédez à l’onglet Catégoriser de votre projet.
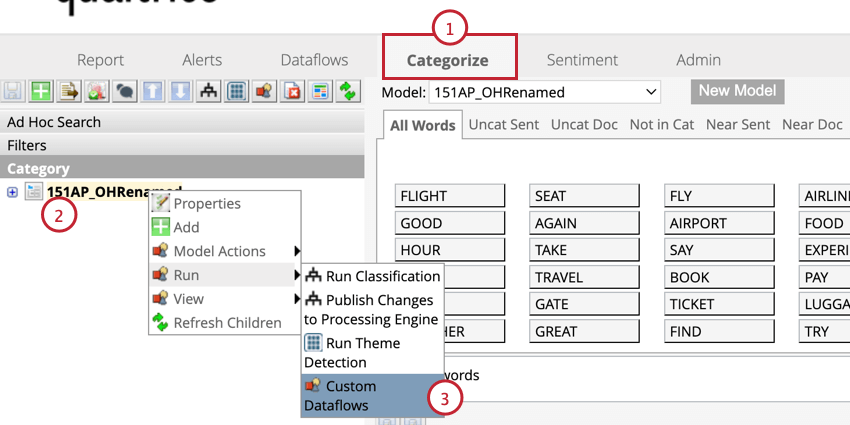
- Cliquez avec le bouton droit de la souris sur un modèle de catégorie.
- Passez la souris sur Exécuter et sélectionnez Flux de données personnalisés.
- Sélectionnez Retraiter les attributs dérivés de la langue.
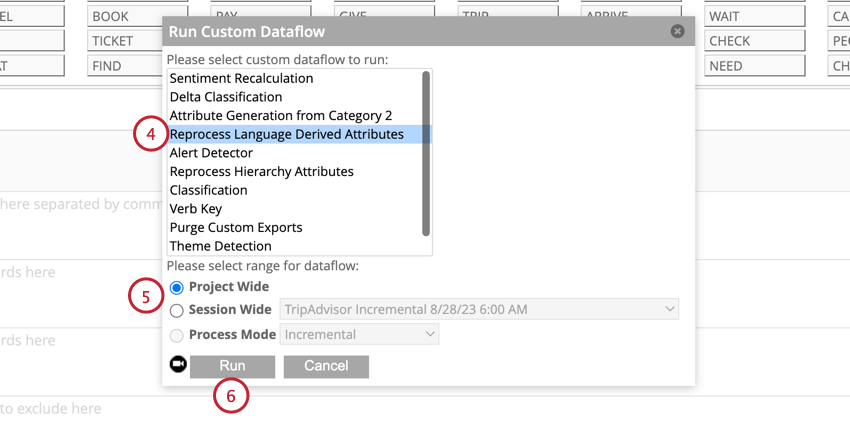
- Sélectionnez si vous souhaitez traiter toutes les données du projet ou les données d’une session spécifique.
- Cliquez sur Exécuter.
Filtrer par l’effort
L
‘effort CB mesure le niveau d’effort exprimé par les clients au cours de leur expérience. Cet attribut est disponible au niveau de la phrase sur une échelle de -5 à 5, -5 indiquant l’expérience la plus difficile et 5 l’expérience la plus facile. L’intervalle de valeurs est inclusif.
Filtre sur la durée de la fidélité
CB Loyalty Tenure vous permet de filtrer les données en fonction de la durée, en années, pendant laquelle un client a utilisé un service ou possédé un produit. Cet attribut est disponible au niveau de la phrase dans les phrases ayant le type de phrase “tenure”. L’intervalle de valeurs est inclusif.
Filtrer par type d’interaction
CB Interaction Type ( cb_interaction_type ) définit les données en fonction du type d’interaction XM, ce qui permet de distinguer le retour d’information régulier des données conversationnelles. Cet attribut est disponible au niveau du document, du verbatim et de la phrase.
Le type d’interaction peut avoir les valeurs suivantes :
- Chat: Données conversationnelles issues des canaux numériques.
- Retour d’information: Données de retour d’information régulières (telles que les enquêtes, les revues, etc.).
- Voix: Données conversationnelles issues de conversations transcrites sur support audio.