-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Chargeur de données (Designer)
A propos de Data Loader
Le chargeur de données est utilisé pour importer des données dans vos projets dans XM Discover via un service API en temps réel. Pour accéder au chargeur de données, allez sur la page Admin, sélectionnez votre projet, puis allez sur l’onglet Data Loader.
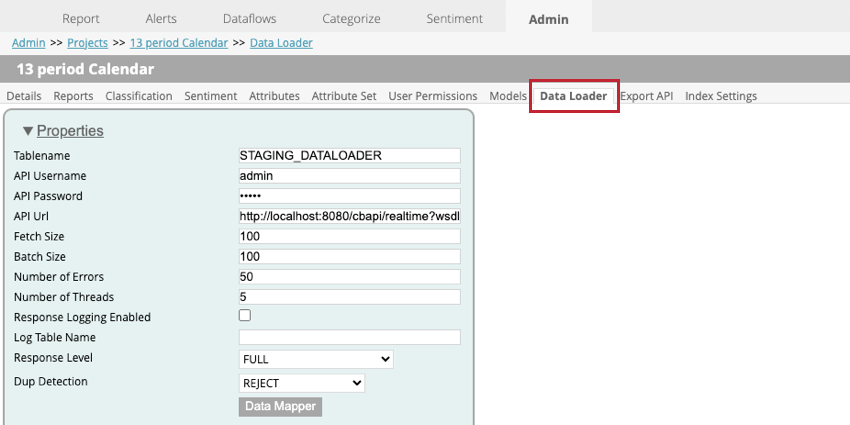
Paramètres du chargeur de données
Les paramètres suivants sont disponibles lors de la configuration du chargeur de données au sein d’un projet :
- Nom de la table : saisissez le nom de la table de préparation qui contient les données à importer dans XM Discover.
- Nom d’utilisateur API: saisissez le nom d’utilisateur de l’utilisateur API qui peut exécuter l’appel API.
- Mot de passe API. Saisissez le nom d’utilisateur de l’utilisateur de l’API.
- API Url: Saisissez l’URL du service API utilisé pour récupérer les données.
- Fetch Size: Spécifiez le nombre de lignes à importer.
- Taille du lot: Indiquez le nombre de lignes qui doivent être importées dans un lot. Si la taille du lot est supérieure à la taille de la recherche, plusieurs appels seront effectués jusqu’à ce que toutes les données soient importées.
- Nombre d’erreurs: Si votre importation échoue en raison d’erreurs, vous pouvez spécifier combien de fois l’appel est retenté.
- Nombre de threads: Saisissez le nombre maximal de threads qui doivent s’exécuter sur une seule instance de transformateur.
- Activation de l’enregistrement des réponses: Lorsqu’elle est activée, cette option permet de créer un journal des résultats du traitement des documents.
- Nom du tableau d’enregistrement: Si vous enregistrez vos résultats, un nouveau tableau sera créé pour vous. Entrez un nom de champ pour la table dans ce champ.
Astuce : Vous ne devez indiquer quelque chose dans ce champ que si l’option d ‘enregistrement des réponses est activée.
- Niveau de réponses: Cette option doit être réglée sur SAUVEGARDE UNIQUEMENT.
- Détection des doublons: Choisissez la manière dont les dupliqués sont traités. Vos options comprennent :
- AUCUN: Les dupliqués sont importés.
- REJET: Les dupliqués sont rejetés.
- METTRE À JOUR LES ATTRIBUTS: Seuls les attributs structurés sont mis à jour pour les dupliqués.
- Fonction de mappage des données: La fonction de mappage des données permet de choisir les champs extraits de la table de mise à disposition qui seront utilisés dans XM Discover. Voir la sous-section Fonction de mappage des données ci-dessous pour plus d’informations.
Fonction de mappage des données
La fonction mappage des données permet d’extraire les données de votre table de mise à disposition pour les utiliser dans XM Discover. La fonction mappage des données n’inclura que les champs qui se trouvent dans votre table de préparation.
- Dans les paramètres de votre chargeur de données, cliquez sur Data Mapper.
- Choisissez le champ qui indique la source des données.
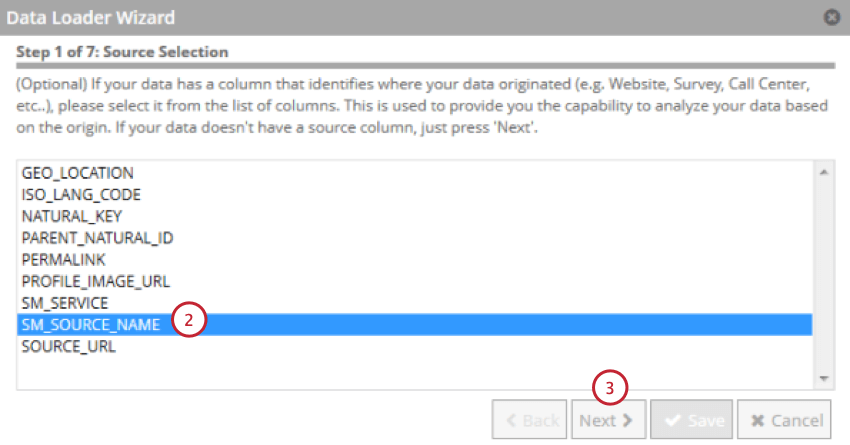
- Cliquez sur Suivant.
- Choisissez le champ à utiliser comme clé naturelle, puis cliquez sur la flèche orientée vers la droite ( > ; ). Vous pouvez sélectionner plusieurs champs et la clé naturelle sera une concaténation des champs dans l’ordre où vous les avez sélectionnés.
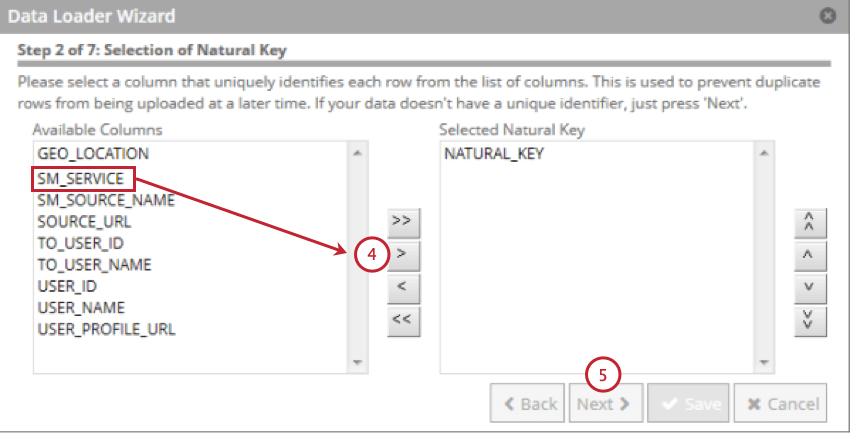 Astuce : Les champs de plus de 256 caractères sont exclus. Les clés naturelles sont tronquées à 256 caractères.
Astuce : Les champs de plus de 256 caractères sont exclus. Les clés naturelles sont tronquées à 256 caractères. - Cliquez sur Suivant.
- Sélectionnez le champ qui contient les verbatims du client, puis cliquez sur la flèche orientée vers la droite ( > ; ).
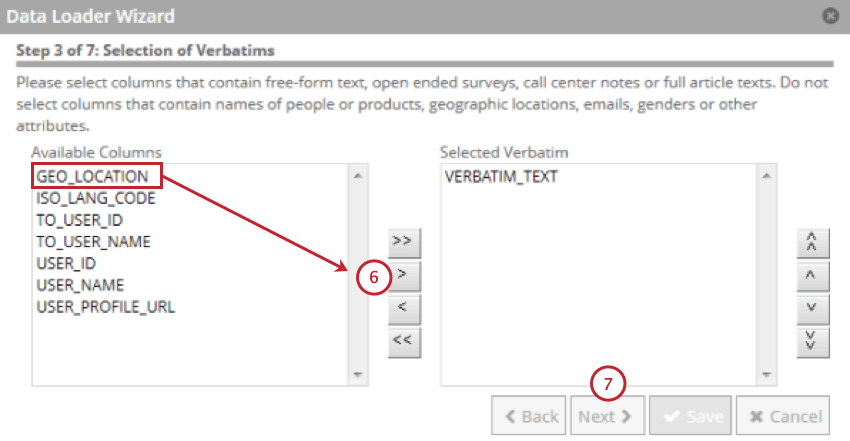
- Cliquez sur Suivant.
- Sélectionnez les champs qui contiennent vos attributs structurés, puis cliquez sur la flèche orientée vers la droite ( > ; ). Vous pouvez sélectionner jusqu’à 500 attributs structurés.
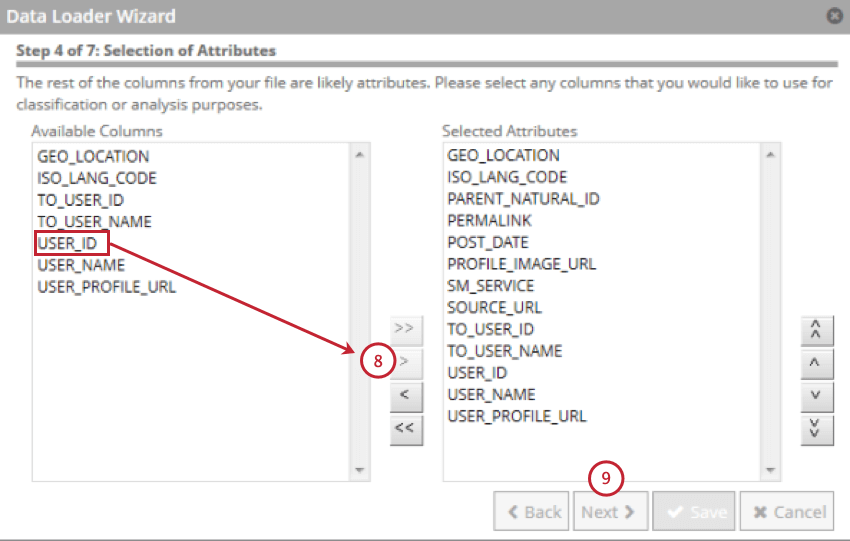
- Cliquez sur Suivant.
- Évaluez vos attributs et modifiez-les si nécessaire. Vous pouvez modifier le nom d’affichage de l’attribut, son type, la disponibilité des rapports et indiquer si le champ est un courriel.
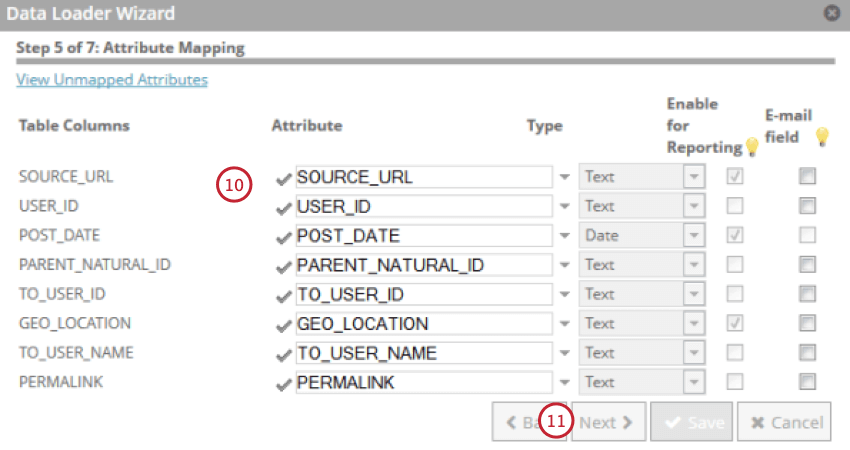
- Cliquez sur Suivant.
- Sélectionnez le champ qui contient la date de création du document. Cette date sera utilisée comme date d’enregistrement dans XM Discover.
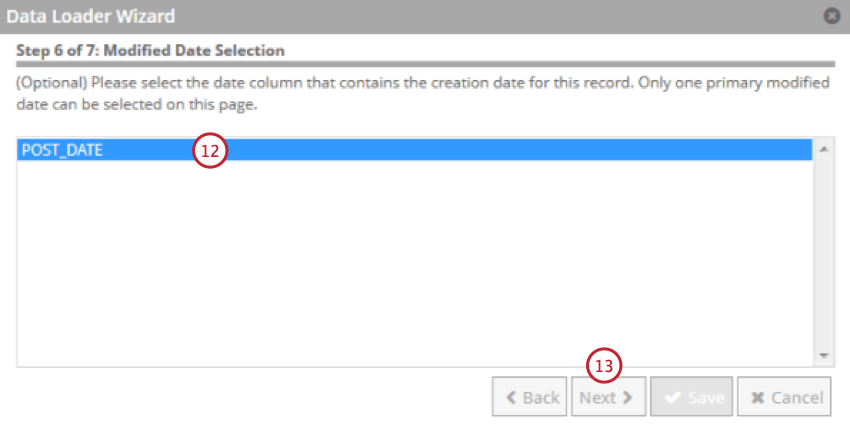
- Cliquez sur Suivant.
- Sélectionnez le champ qui contient la langue du document.
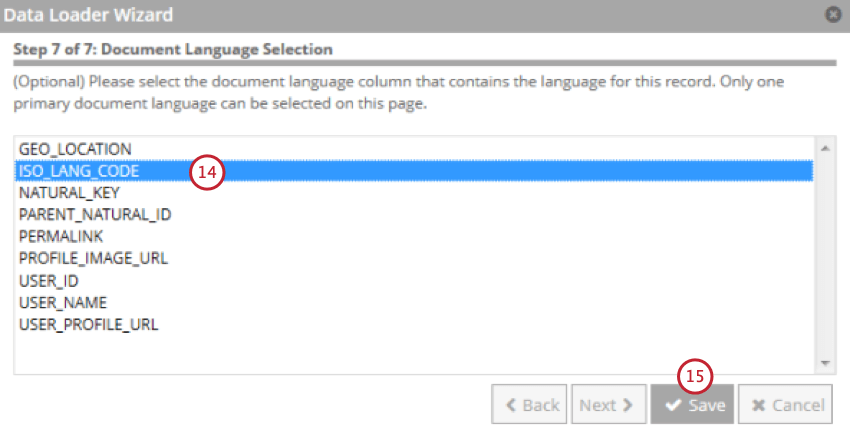
- Cliquez sur Enregistrer.
Importation de données avec le Data Loader
Une fois les données chargées dans une table de préparation via le chargeur de données, vous pouvez traiter ces données pour les utiliser dans XM Discover. Cette section explique comment mettre en place un processus automatisé de chargement des données afin que vos données soient toujours à jour.
- Allez dans l’onglet Flux de données .
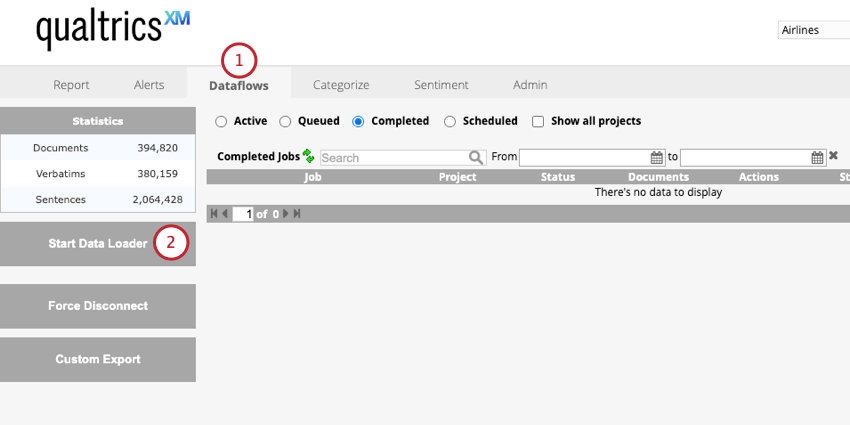
- Cliquez sur Start Data Loader.
- Accédez à la section Planifiés des flux de données.
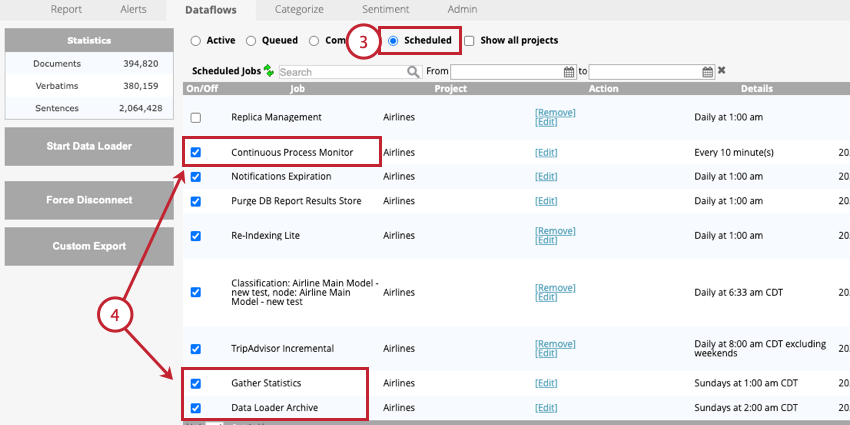
- Activer les travaux suivants :
- Moniteur de processus continu: Cet emploi est requis. Ce flux de données exécute périodiquement le temps réel en aval pour finaliser le traitement des données.
- Data Loader Archive: Cette tâche est facultative, mais fortement recommandée. Ce flux de données archive les enregistrements qui sont traités par le chargeur de données. Vous devez adapter la fréquence de cette tâche à celle de votre chargeur de données.
- Rassembler les statistiques: Cette tâche est facultative. Nous recommandons d’exécuter cette tâche une fois par semaine. Ce flux de données actualise les statistiques suivantes du projet :
- Le nombre total de documents, de verbatims et de phrases affichés dans l’onglet Flux de données.
- Le nombre total d’occurrences de mots affichées dans l’onglet Sentiment.
Options du chargeur de données
Une fois que le chargeur de données a démarré, vous pouvez gérer le travail à l’aide des options suivantes :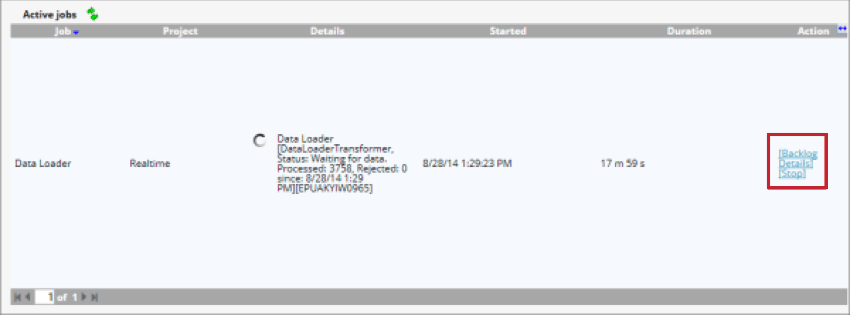
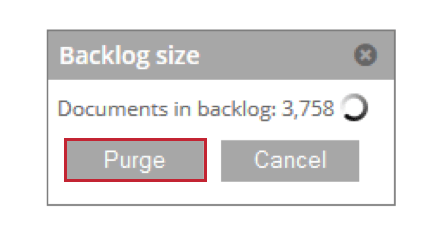
- Arriéré: Indique le nombre de documents en attente de traitement. Vous pouvez cliquer sur Purger pour supprimer ces documents de la table de mise à disposition.
- Détails: Affichez les détails des documents qui ont été ignorés en raison des paramètres de duplication.
- Stop: arrête le traitement des données avec le chargeur de données.
Suppression des données d’un projet
Vous pouvez supprimer les données de votre projet. Cela comprend les verbatims et les valeurs d’attribut structurées. Lors de la suppression des données d’un projet, vous pouvez supprimer toutes les données téléchargées au cours d’une session particulière ou toutes les données du projet.
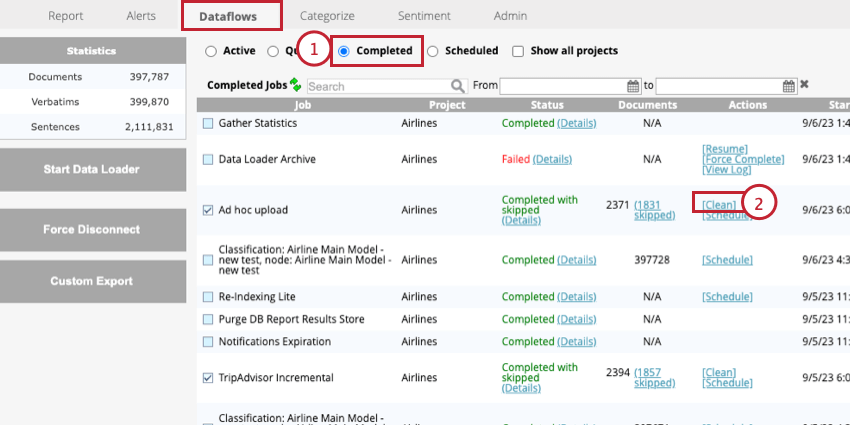
- Allez dans la section Terminé de l’onglet Flux de données.
- Cliquez sur Nettoyer à côté de la tâche de téléchargement ad hoc.
Cette opération supprime toutes les données ajoutées lors du téléchargement sélectionné.