-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Attributs Vue d’ensemble de base
À propos des attributs Vue d’ensemble de base
Un attribut est une propriété d’un document qui le caractérise d’une certaine manière. Le nom de l’auteur et la date de création sont des exemples courants d’attributs.
Vous pouvez créer des attributs personnalisés pour vos projets. Vous pouvez également utiliser divers attributs du système. Vous pouvez également mettre en place des entités intelligentes qui détectent automatiquement les attributs sur la base du texte du document (par exemple, lorsqu’une organisation ou un produit est mentionné dans les commentaires d’un client).
Après avoir ajouté des attributs, il est possible de créer des attributs dérivés supplémentaires pour mieux comprendre vos données. Vous pouvez également organiser vos attributs en ensembles d’attributs, ce qui facilite l’établissement de rapports sur ces attributs.
Types de champ d’attribut
Les types de champ suivants sont pris en charge pour les attributs :
- Texte
- Nombre
- Date
Accès aux attributs
Les attributs sont gérés au niveau du projet. Pour accéder aux attributs d’un projet :
- Dans le Designer, allez dans l’onglet Admin et trouvez le projet qui vous intéresse.
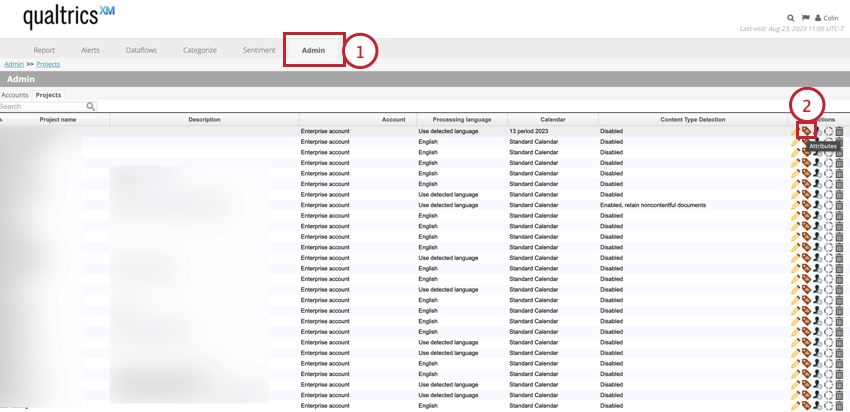
- Cliquez sur l’option Attributs dans la colonne Actions.
La table des attributs s’ouvre et contient les informations suivantes sur chaque attribut du projet :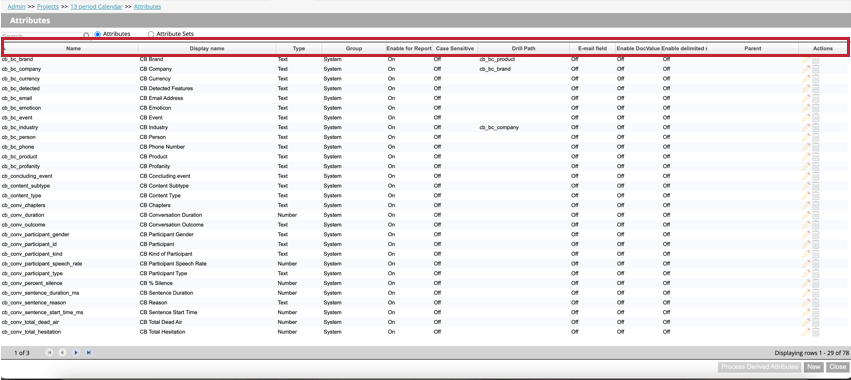
- Nom: Nom du système de l’attribut. Voir Attribut Naming pour les exigences en matière de dénomination.
- Nom d’affichage: le nom d’affichage de l’attribut, qui apparaît dans les rapports, les filtres, etc. Voir Attribut Naming pour les exigences en matière de dénomination.
- Type: Le type de l’attribut. Pour les attributs standard, les valeurs peuvent être un texte, un nombre ou une date. Pour les attributs dérivés, les valeurs peuvent être Consultation dimensionnelle, Enroulement de gamme, Note de satisfaction ou Dérivé de la catégorie.
- Groupe: Le groupe de l’attribut qui représente son origine et son utilisation prévue. Les valeurs sont l’une des suivantes :
- Catégorie dérivée: attributs dérivés de modèles ou de catégories.
- Système: attributs du système.
- Défini par le client: tous les attributs personnalisés disponibles à partir de la source de données de votre choix (y compris les extrapolations dimensionnelles, les extrapolations par plage et les notations de satisfaction).
- Scorecard: attributs utilisés dans la notation intelligente.
- Activer pour les rapports. Rapports: Rapports si un attribut est activé pour les rapports (On) ou non (Off).
- Sensible à la casse: Indique si un attribut est sensible à la casse lors de l’affichage des valeurs dans l’Explorateur de documents, le Surligneur de sources, l’exportation personnalisée et l’exportation de l’aperçu des phrases.
- Chemin de forage: Affiche le chemin de forage personnalisé s’il a été défini. S’il n’y a pas de champ personnalisé, ce champ sera vide.
- Champ E-mail: Indique si un attribut contient une adresse électronique.
- Enable DocValue: Indique si les valeurs de doc ElasticSearch sont utilisées pour cet attribut.
- Activer les valeurs multiples délimitées: Indique si les valeurs multiples sont activées pour cet attribut.
- Parent: si l’attribut est un attribut dérivé, ce champ affichera “parent” Ce champ sera vide pour les attributs personnalisés et standard.
- Actions: Effectuez les actions suivantes sur l’attribut :
- Modifier l’attribut
- Créer un attribut dérivé
- Supprimer l’attribut
Manager les ensembles d’attributs
Utilisez le bouton de basculement des ensembles d’ attributs en haut de la page pour afficher vos ensembles d’attributs. Cela vous permet de créer de nouveaux ensembles d’attributs et de supprimer des ensembles existants. Sélectionnez Attributs pour afficher vos attributs individuels. 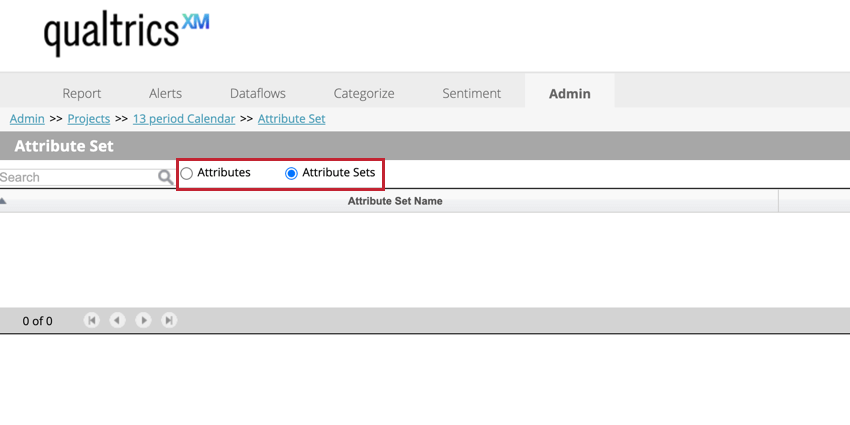
Attributs du système
Un certain nombre d’attributs système, tels que la date du document et l’identifiant de la source, sont automatiquement appliqués à chaque document téléchargé dans XM Discover. Ces attributs vous aident à gérer les informations en retour dans XM Discover, ainsi qu’à les enrichir avec les données XM dérivées par le moteur NLP.
Vous trouverez ci-dessous un tableau des différents attributs du système, regroupés selon les différentes catégories d’attributs. Ce tableau contient les informations suivantes sur chaque attribut :
- Nom: Le nom de l’attribut qui apparaît dans les rapports, les filtres, etc.
- Nom du système: Le nom du système de l’attribut que vous utilisez pour interroger ou filtrer vos données.
- Type: Le type d’attribut.
- Description: Brève description de la signification et de l’objectif de l’attribut.
- Granularité: Le niveau de granularité des données associé à un attribut. Par exemple, le nombre de mots de la phrase n’est pertinent qu’au niveau de la phrase, tandis que la date du document est disponible à la fois pour un document et pour chaque phrase de ce document.
ID et références
| Nom | Nom du système | Type | Description | Granularité |
| ID du document | document_id | nombre | L’identifiant système unique du document. Contrairement à l’identifiant naturel, l’identifiant de document est généré automatiquement par XM Discover. | document et phrase |
| ID naturel | natural_id | texte | L’identifiant naturel unique du document. Contrairement à l’ID du document, l’ID naturel est généré à partir des champs spécifiés lorsque vous téléchargez un document. L’identification naturelle est utilisée par la détection des dupliquages et peut également être utile pour remonter à la source du document en dehors de XM Discover. | document et phrase |
| ID de la phrase | id_sentence | nombre | L’identifiant unique de la phrase. Cet identifiant est généré automatiquement.
  ; |
condamnation |
| Identifiant de session | lot_id | nombre | L’identifiant unique de la session de téléchargement au cours de laquelle le document a été chargé dans XM Discover. Cet identifiant est généré automatiquement. | document et phrase |
| Source ID | source_id | texte | Le nom de la source de données. Selon la source de données, elle peut être générée automatiquement ou à partir des champs spécifiés lors du téléchargement du document. | document et phrase |
| ID Verbatim | _id_verbatim | nombre | L’identifiant unique du verbatim. Cet identifiant est généré automatiquement. | verbatim et phrase |
| Type Verbatim | type de verbe | texte | Le nom du champ verbatim. Cet attribut vous permet de distinguer les phrases en fonction des différents champs de données. | verbatim et phrase |
  ;
Date et heure
  ;
| Nom | Nom du système | Type | Description | Granularité |
| CB Date de création | cb_date_créée_utc | date, Chronomètre en millisecondes | Date à laquelle le document a été ajouté à XM Discover. Cette date est générée automatiquement. | document et phrase |
| Date de mise à jour du CB | cb_date_updated | date, Chronomètre en millisecondes | Date de la dernière mise à jour du document. Les mises à jour n’incluent pas les changements de catégorie. Cette date est générée automatiquement. | document |
| Date du document | heure_doc | date, ISO 8601 en secondes | La date principale du document. La date du document est utilisée dans les rapports, les rapports de tendance, les alertes, etc. Cette date est générée à partir des champs spécifiés lors du téléchargement du document. | document et phrase |
| Date du document sans Chronomètre | date_doc | date, format aaaa-mm-jj | La date du document sans l’horodatage.
Cette date est générée à partir des champs spécifiés lors du téléchargement du document. |
document et phrase |
| Chronomètre | heure_du_jour | texte, format hh:mm | L’heure du document, ramenée à l’heure. Par exemple, les commentaires postés à 9:09 et 9:59 remonteront tous deux à 9:00. Cet attribut est généré automatiquement. | document et phrase |
Nombre de mots et position
  ;
| Nom | Nom du système | Type | Description | Granularité |
| Nombre de mots du document CB | cb_document_word_count | nombre | Le nombre de mots dans un document. Le nombre de mots du document est la somme de tous les mots des phrases.
  ; |
document et phrase |
| Quartile de la peine CB | cb_sentence_quartile | nombre | La partie du verbatim dans laquelle se situe une phrase. Cet attribut peut prendre l’une des valeurs suivantes : 1, 2, 3 ou 4. Chaque section représente 25 % de la longueur totale du verbatim. | condamnation |
| CB Phrase Nombre de mots | cb_sentence_word_count | nombre | Le nombre de mots dans une phrase. | condamnation |