-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Connecteur Zendesk Inbound
À propos du connecteur Zendesk Inbound
Vous pouvez utiliser le connecteur entrant Zendesk pour charger les données de chat de Zendesk dans XM Discover.
Astuce : Pour établir la connexion, vous aurez besoin des paramètres suivants concernant votre compte Zendesk :
- Votre adresse e-mail Zendesk
- Votre clé API Zendesk
- Le sous-domaine Zendesk de votre organisation
Configuration d’un job Zendesk Inbound
Astuce : L’autorisation “Manage Jobs” est requise pour utiliser cette fonction.
- Sur la page Emplois, cliquez sur Nouveau travail.
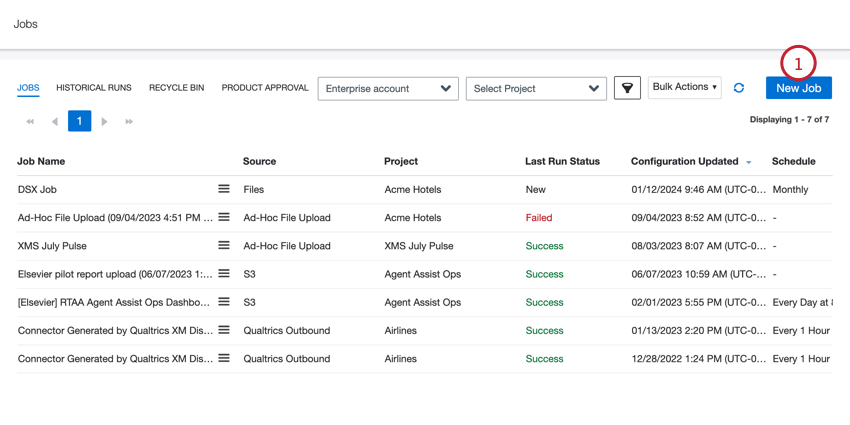
- Sélectionnez Zendesk.

- Donnez un nom à votre travail afin de pouvoir l’identifier.
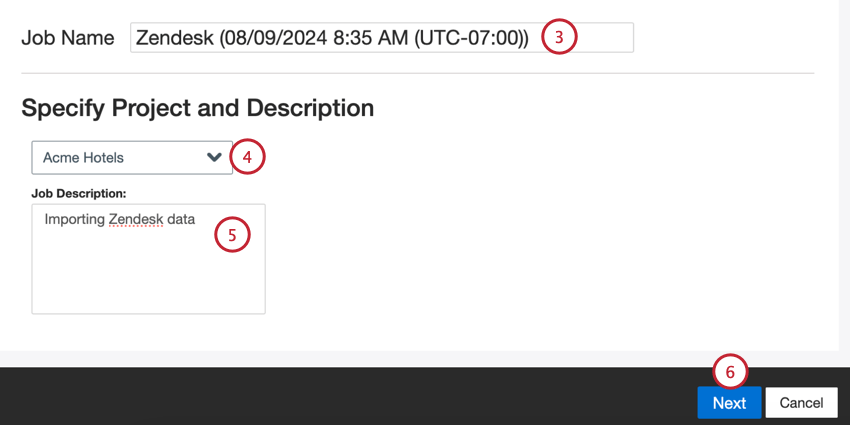
- Choisissez le projet dans lequel vous souhaitez charger les données.
- Donnez une description de votre poste afin d’en connaître l’objectif.
- Cliquez sur Suivant.
- Choisissez le compte Zendesk à utiliser, ou sélectionnez Ajouter nouveau pour en ajouter un nouveau.
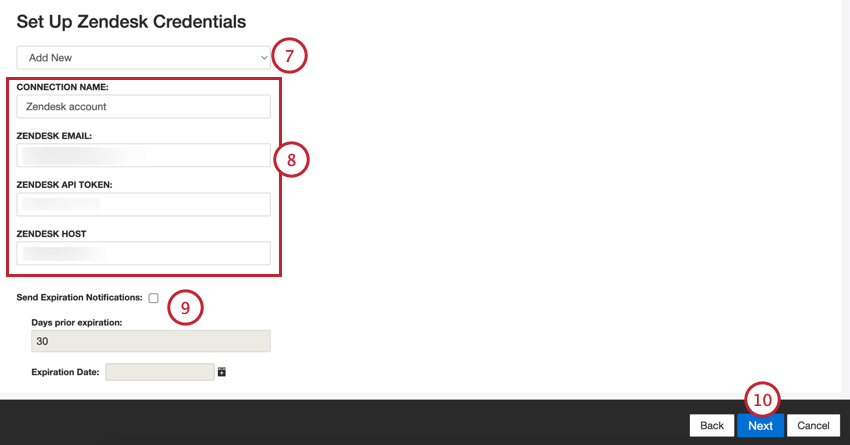
- Si vous ajoutez un nouveau compte, saisissez les informations suivantes concernant votre compte Zendesk :
- Nom de la connexion: Donnez un nom à la connexion afin de pouvoir l’identifier.
- Zendesk Email: L’adresse e-mail de votre compte Zendesk.
- Clé API de Zendesk: Clé API de votre compte Zendesk.
- Zendesk Host: Votre sous-domaine Zendesk.
- Si vous souhaitez que vos informations d’identification expirent, configurez les options suivantes :
- Envoyer des notifications d’expiration: Sélectionnez cette option pour autoriser l’expiration de vos informations d’identification.
- Jours avant l’expiration: Si vous activez les notifications d’expiration, indiquez le nombre de jours avant l’expiration. Vous pouvez saisir une valeur comprise entre 1 et 100 jours.
- Date d’expiration: Définissez la date d’expiration des informations d’identification. Cliquez sur la case pour ouvrir un calendrier et choisir la date.
- Cliquez sur Suivant.
- Choisissez le type de données que vous souhaitez importer dans XM Discover :
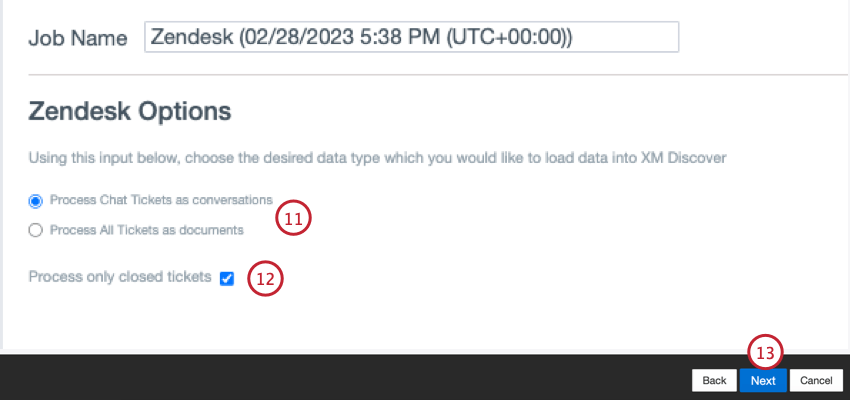
- Traiter les tickets de chat comme des conversations: Les tickets de chat de Création de ticket sont importés en tant que conversations.
- Traiter tous les Tickets comme des documents: Tous les tickets Zendesk sont importés en tant que documents.
- Vous pouvez choisir d’inclure ou non les tickets non créés dans le téléchargement. Sélectionnez l’option Traiter uniquement les tickets clôt urés pour ne télécharger que les tickets clôturés. Désélectionnez cette option pour télécharger à la fois les tickets fermés et les tickets ouverts.
- Cliquez sur Suivant.
- Si nécessaire, ajustez vos correspondances de données. Consultez la page d’assistance sur le mappage des données pour obtenir des informations détaillées sur le mappage des champs dans XM Discover. La section Mappage des données par défaut contient des informations sur les champs spécifiques à ce connecteur et la section Mappage des champs conversationnels explique comment mapper les données pour les données conversationnelles.
- Cliquez sur Suivant.
- Si vous le souhaitez, vous pouvez ajouter des règles de substitution de données et de rédaction pour masquer les données sensibles ou remplacer automatiquement certains mots et phrases dans les commentaires et interactions des clients. Voir la page d’aide sur la substitution et la rédaction des données.
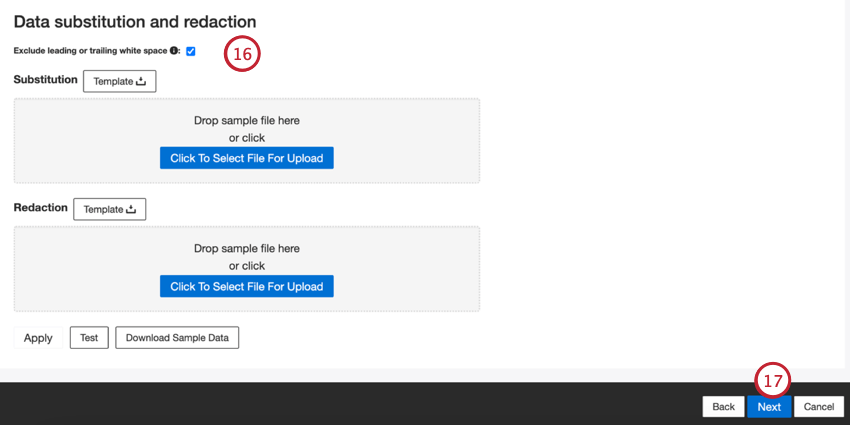 Astuce : Cliquez sur Télécharger des échantillons de données pour télécharger un fichier Excel contenant des échantillons de données sur votre ordinateur.
Astuce : Cliquez sur Télécharger des échantillons de données pour télécharger un fichier Excel contenant des échantillons de données sur votre ordinateur. - Cliquez sur Suivant.
- Si vous le souhaitez, vous pouvez ajouter un filtre de connecteur pour filtrer les données entrantes afin de limiter les données importées.
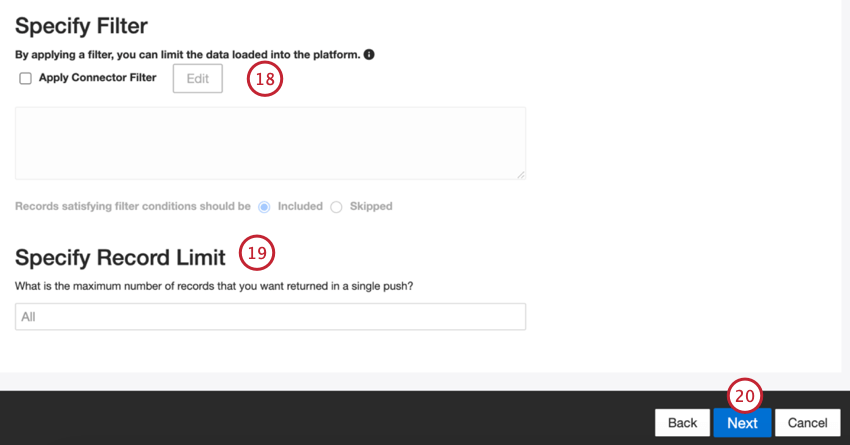
- Vous pouvez également limiter le nombre d’enregistrements importés dans une seule tâche en entrant un nombre dans la case Spécifier la limite d’enregistrements. Saisissez “Tous” si vous souhaitez importer tous les enregistrements.
Astuce : pour les données conversationnelles, la limite est appliquée en fonction des conversations et non des lignes.
- Cliquez sur Suivant.
- Choisissez le moment où vous souhaitez être informé. Pour plus d’informations, voir Notifications d’emploi.

- Cliquez sur Suivant.
- Choisissez le mode de traitement des documents dupliqués. Pour plus d’informations, voir la rubrique Traitement des dupliqués.
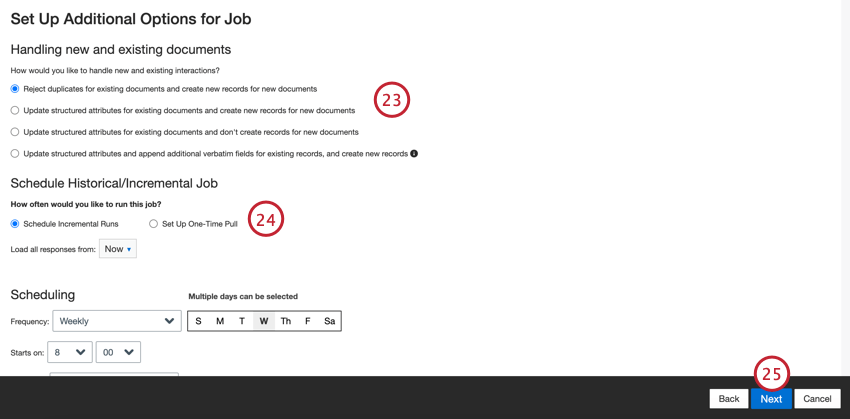
- Choisissez Planifier des exécutions incrémentielles si vous souhaitez que votre travail s’exécute périodiquement selon un calendrier, ou Configurer un tirage unique si vous souhaitez que le travail ne s’exécute qu’une seule fois. Pour plus d’informations, voir Planification des tâches.
- Cliquez sur Suivant.
- Évaluateur. Si vous devez modifier un paramètre spécifique, cliquez sur le bouton Modifier pour accéder à cette étape de la configuration du connecteur.
- Cliquez sur Terminer pour enregistrer le travail.
Mappage des données par défaut
Cette section contient des informations sur les champs par défaut des jobs entrants Zendesk.
- natural_id: Identifiant unique d’un document. Il est fortement recommandé d’avoir un identifiant unique pour chaque document afin de traiter correctement les dupliqués. Pour Natural ID, vous pouvez sélectionner n’importe quel champ textuel ou numérique de vos données. Vous pouvez également générer automatiquement des identifiants en ajoutant un champ personnalisé. Par défaut, XM Discover utilise les identifiants de source préfixés par le nom du connecteur via une transformation personnalisée : Natural ID = Connector-name;Source-ID.
- document_date: Champ de date primaire associé à un document. Cette date est utilisée dans les rapports XM Discover, les tendances, les alertes, etc. Par défaut, ce champ est associé au champ de date sélectionné après avoir spécifié la requête SOQL. Vous pouvez choisir l’une des options suivantes :
- updated_at (par défaut): Date et heure de la dernière mise à jour de l’activité de chat.
- created_at: Date et heure de création de l’activité de chat.
- Vous pouvez également fixer une date spécifique pour le document.
- feedback_provider: Identifie les données obtenues auprès d’un fournisseur spécifique. Pour les téléchargements Zendesk, la valeur de cet attribut est définie sur “Zendesk” et ne peut pas être modifiée.
- valeur_source: Identifie les données obtenues à partir d’une source spécifique. Il peut s’agir de tout ce qui décrit l’origine des données, comme le nom d’une enquête ou d’une campagne de marketing mobile. Par défaut, la valeur de cet attribut est définie sur “Zendesk” Utilisez les transformations personnalisées pour définir une valeur personnalisée, une expression ou une correspondance avec un autre champ.
- feedback_type: Identifie les informations en fonction de leur type. Cela est utile pour les rapports lorsque votre projet contient différents types de données (par exemple, des enquêtes et des commentaires sur les médias sociaux). Par défaut, la valeur de cet attribut est “Messaging Platform”. Utilisez les transformations personnalisées pour définir une valeur personnalisée, une expression ou une correspondance avec un autre champ.
- job_name: identifie les informations en fonction du nom de la tâche utilisée pour les télécharger. Vous pouvez modifier la valeur de cet attribut pendant la configuration via le champ Nom de champ qui s’affiche en haut de chaque page pendant la configuration.
- loadDate: Indique quand un document a été téléchargé dans XM Discover. Ce champ est défini automatiquement et ne peut pas être modifié.
Astuce : Voir Mapping Conversational Fields pour savoir comment mapper les données conversationnelles (richVerbatim, clientVerbatim, agentVerbatim, unknown.