Cartographie des données (Discover)
Contenus de cette page
À propos de la cartographie des données dans Discover
L’objectif du mappage des données est de définir la structure et le format des données dans votre projet XM Discover. Lorsque vous téléchargez des données dans XM Discover, vous devez mettre en correspondance les champs de données d’une source externe (telle qu’un service tiers ou un fichier) avec les champs de données de votre projet XM Discover.
Lorsque vous cartographiez des données dans XM Discover, vous pouvez.. :
- Définir les valeurs des champs de données par défaut dans XM Discover.
- Choisissez les champs de données qui doivent être téléchargés en tant que nouveaux attributs et ceux qui doivent être connectés à des attributs existants.
- Définir le type de données pour les nouveaux champs.
- Ignorez les champs que vous ne souhaitez pas télécharger.
Accessibilité des données Cartographie
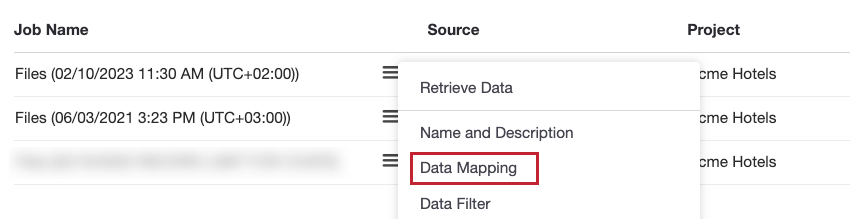
Il existe deux façons d’accéder aux options de mappage des données pour un travail :
- Lors de la création d’un travail : Vous pouvez effectuer la configuration initiale du mappage des données sur la page Mapper les champs souhaités dans XM Discover .

- Pour les travaux existants : Vous pouvez accéder à la configuration du mappage des données en sélectionnant l’option Mappage des données dans le menu des actions du travail.

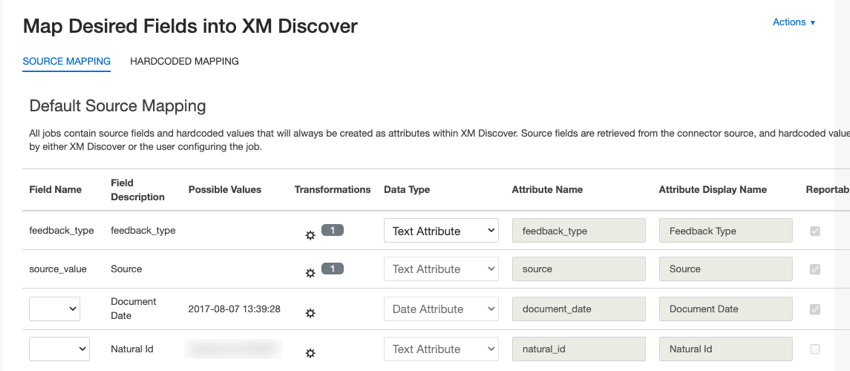
Mappage des données
Suivez les étapes de cette section lorsque vous mappez des données dans XM Discover :
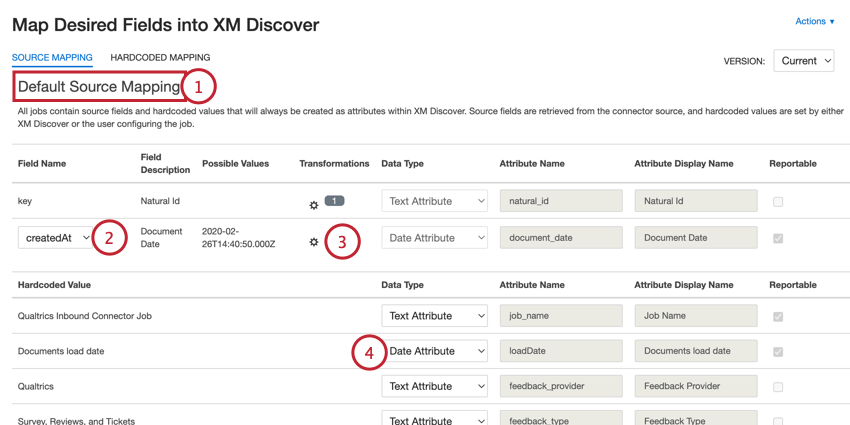
Astuce : si vous souhaitez annuler la mise en correspondance d’un champ existant, changez son type de données en “Ne pas mettre en correspondance”
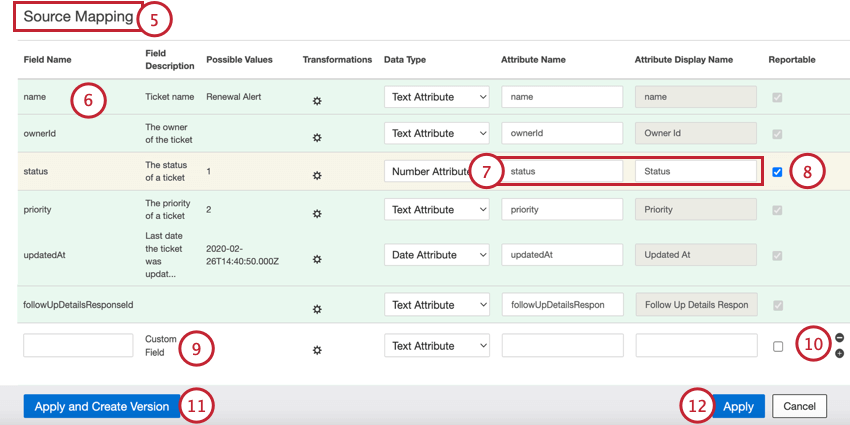
- Blanc: Le champ est mappé à un nouvel attribut, ce qui signifie que XM Discover n’a pas trouvé d’attribut dans le projet qui corresponde à ce champ.
- Vert: Le champ est associé à un attribut existant et porte le même nom.
- Jaune: Le champ est associé à un attribut existant, mais le nom ne correspond pas exactement. Exemple : Si votre source possède un champ appelé NOM et que vous avez un attribut existant appelé NAMES, vous les verrez très probablement mappés sur un fond jaune.

- Rouge: Le champ présente un problème de mise en correspondance, tel qu’une incompatibilité de type de données ou un nom incorrect. Exemple : Le type de données d’un champ est défini sur “Attribut texte”, mais un champ portant le même nom existe déjà dans XM Discover en tant qu'”Attribut nombre” Pour y remédier, sélectionnez le bon type de données dans le menu déroulant Type de données.
- Attribut Name (Nom de l’attribut) : Nom du champ tel qu’il sera enregistré dans XM Discover. Ce nom ne peut pas contenir d’espaces et ne peut pas dépasser 21 caractères pour un champ de données structuré, ou 30 caractères pour un champ de verbatim. Astuce : Si vous souhaitez associer un nouveau champ à un champ existant, saisissez le nom de l’attribut existant dans cette colonne.

- Nom d’affichage de l’attribut: Nom du champ tel qu’il sera présenté aux utilisateurs (par exemple, dans les rapports). Ce nom peut contenir des espaces et ne peut excéder 99 caractères. Astuce : Pour les champs verbatim, le Nom d’affichage de l’attribut est automatiquement défini pour correspondre au Nom de l’attribut.
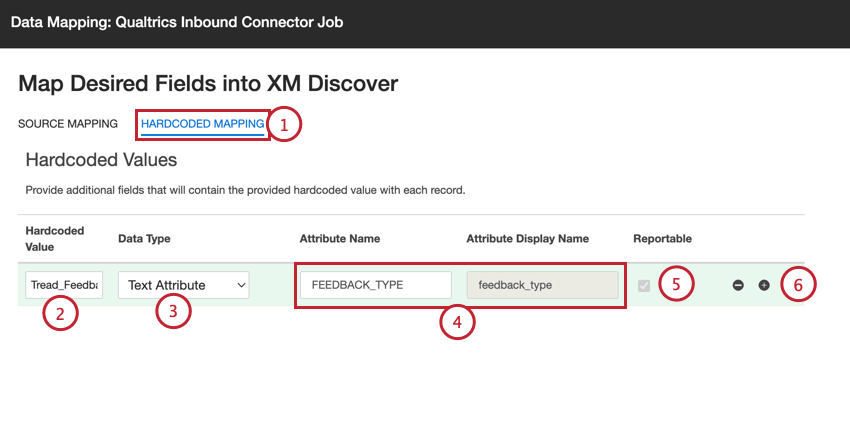
Mises en correspondance de données codées en dur
Si vous le souhaitez, vous pouvez ajouter des correspondances de données codées en dur, qui appliqueront les valeurs codées en dur spécifiées pour tous les enregistrements téléchargés via la tâche :
{kind=link}

Astuce : Veillez à cliquer sur Appliquer pour enregistrer vos modifications.
Cartographie des champs conversationnels
Astuce : Les transformations ne sont pas prises en charge pour les champs verbatim conversationnels.
Cette section explique comment mapper les champs conversationnels pour les données conversationnelles, telles que les interactions d’appel et de chat. Dans la section Source de données, vous pouvez configurer les champs de données conversationnels suivants :
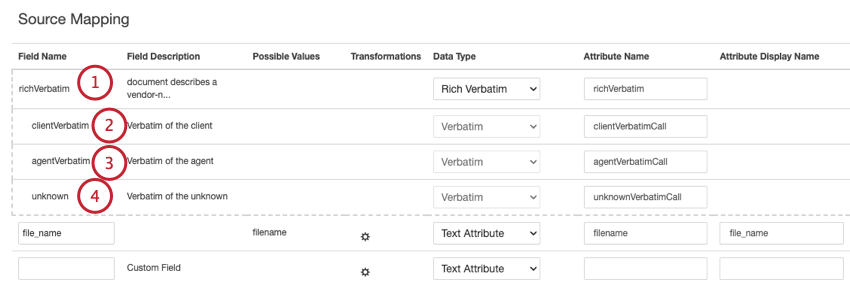{kind=link}

- clientVerbatim: Retrace la côte à côte du client dans la conversation.
- agentVerbatim: Retrace la côte à côte du représentant dans la conversation.
- inconnu: Piste d’autres parties de la conversation où l’identité de l’interlocuteur n’est pas claire, ou l’interlocuteur n’est ni le client ni l’agent. Astuce : Le même verbatim ne peut pas être utilisé pour différents types de données conversationnelles. Si vous souhaitez que votre projet accueille plusieurs types de conversation, utilisez des paires distinctes de verbatims conversationnels par type de conversation.
- clientVerbatimChat pour les interactions numériques.
- clientVerbatimCall pour les interactions d’appel.
- agentVerbatimChat pour les interactions numériques.
- agentVerbatimCall pour les interactions d’appel.
- unknownVerbatimChat pour les interactions numériques.
- unknownVerbatimCall pour les interactions d’appel.
Types de données
Lorsque vous définissez des champs dans XM Discover, vous pouvez définir le type de données du champ sur l’un des éléments suivants :
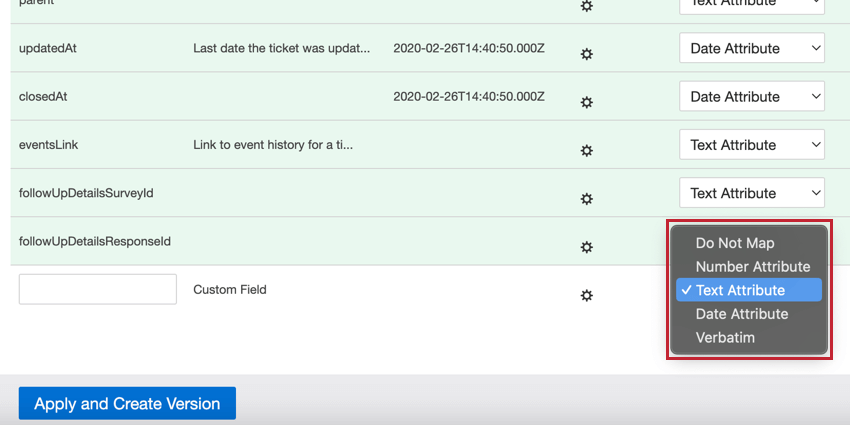{kind=link}
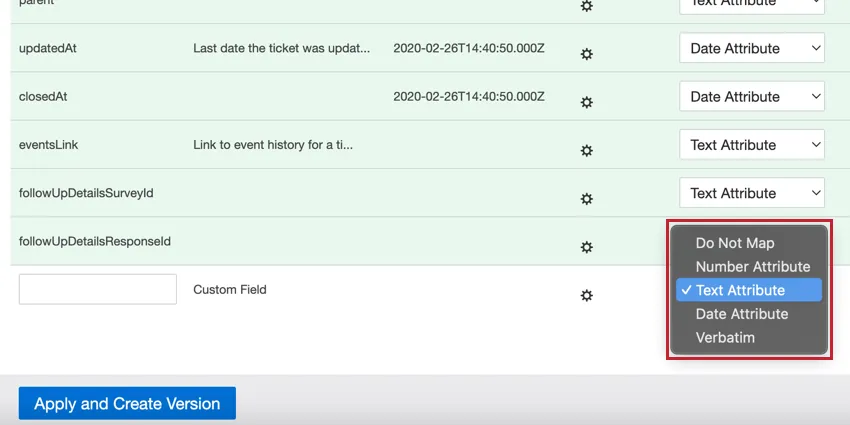
- Ne pas cartographier: Ne pas charger ce champ dans XM Discover.
- Attribut de nombre: Pour les champs numériques. Vous pouvez effectuer des calculs sur ces attributs. Astuce : Ne sélectionnez Attribut du nombre que si vous souhaitez effectuer des calculs sur ce nombre. L’âge est un bon exemple d’attribut numérique, car il peut être intéressant de connaître l’âge moyen des participants à l’enquête. Un mauvais exemple d’attribut numérique est l’année de fabrication d’une voiture, qu’il vaudrait mieux choisir comme Attribut texte.
- Attribut de texte: Pour les champs de texte avec un ensemble discret de valeurs. Astuce : Lorsque Connectors crée un nouvel attribut de texte, celui-ci est sensible à la casse par défaut. Si vous souhaitez disposer d’un attribut de texte insensible à la casse, créez-le d’abord dans le Designer.
- Attribut de date: Pour les champs de date.
- Verbatim: Pour les champs verbatim et les commentaires textuels. Utilisez le mot à mot pour les champs contenant des données non structurées que vous souhaitez faire traiter par le moteur NLP de XM Discover.
Astuce : Si un champ est associé à un attribut existant, vous ne pouvez pas en modifier le type. Toutefois, vous pouvez annuler la cartographie du champ en sélectionnant Ne pas cartographier.
Actions de cartographie des données
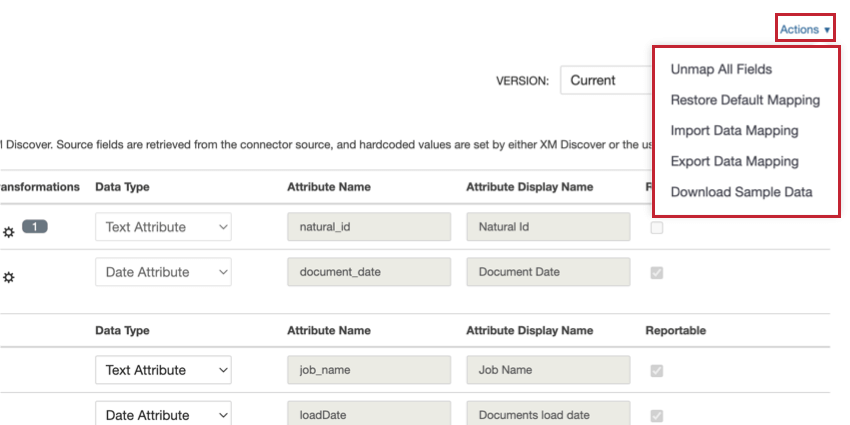
Le menu Actions vous permet d’effectuer les tâches suivantes :
{kind=link}

- Unmap All Fields: Supprime la mise en correspondance de tous les champs dans la section “Source Mapping” de la mise en correspondance des données, en réglant tous les champs sur “Do Not Map” (ne pas mettre en correspondance)
- Restaurer le mappage par défaut: Supprime tout mappage de champ personnalisé et rétablit le mappage de données par défaut pour le connecteur.
- Importer la cartographie des données: Vous permet d’importer un fichier contenant votre cartographie de données. Pour plus d’informations, voir Importation et exportation de mappages de données.
- Exporter la cartographie des données: Vous permet d’exporter un fichier contenant votre cartographie de données. Pour plus d’informations, voir Importation et exportation de mappages de données.
- Mettre à jour le mappage à partir d’un fichier échantillon: Cette option n’est disponible que pour les connecteurs XM Discover Link et Files. Permet de mettre à jour votre cartographie en téléchargeant l’un des échantillons de fichiers de format de données XM Discover.
- Télécharger des échantillons de données: Lorsque vous mettez en correspondance des champs de données provenant de services tiers, vous pouvez télécharger une feuille de calcul Excel contenant des échantillons de données afin de mieux comprendre le type de données auxquelles vous pouvez vous attendre dans votre projet. Cette feuille de calcul contient 2 feuilles :
- Données standard: Champs source non mappés avec des noms et des valeurs par défaut (avant mappage).
- Données mappées: Champs mappés avec des noms et des valeurs transformés (après mappage).
Importation et exportation de données Mapping
Vous pouvez exporter votre cartographie de données vers une feuille de calcul Excel, ce qui vous permet d’apporter des modifications à votre cartographie en dehors de XM Discover. Vous pouvez ensuite importer ce fichier pour mettre à jour votre cartographie. Ces options vous permettent également de réutiliser rapidement vos mappages de données d’un travail à l’autre.
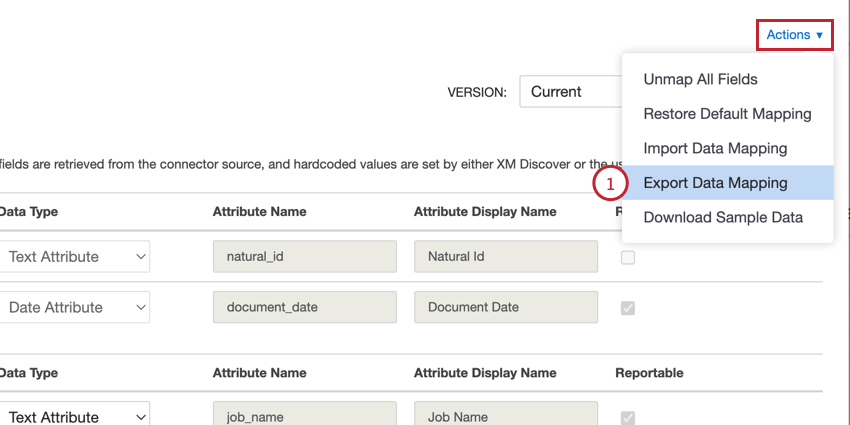
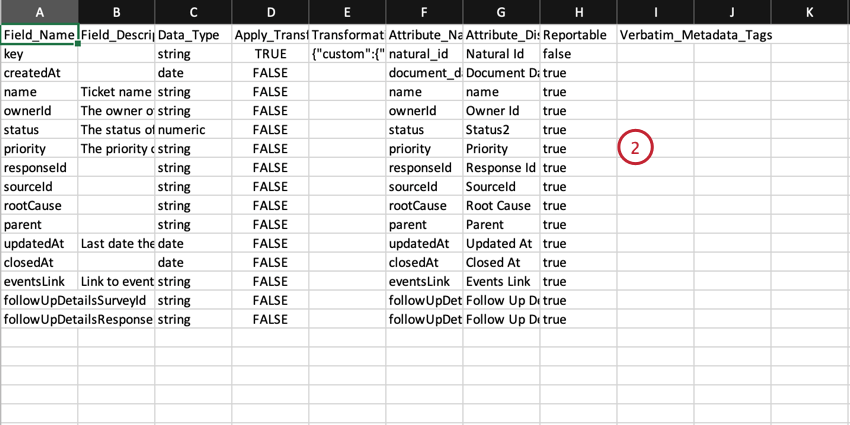
- Les noms des colonnes correspondent aux colonnes affichées dans la fenêtre de mappage des données dans Discover.
- Vous pouvez créer de nouveaux champs personnalisés en ajoutant de nouvelles lignes.
- N’ajoutez pas de nouvelles colonnes.
- Enregistrez votre fichier sous forme de fichier XLS os XLSX.
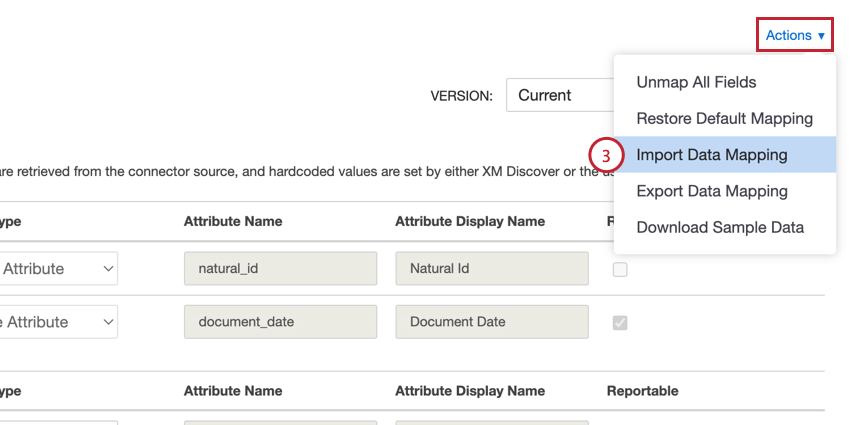
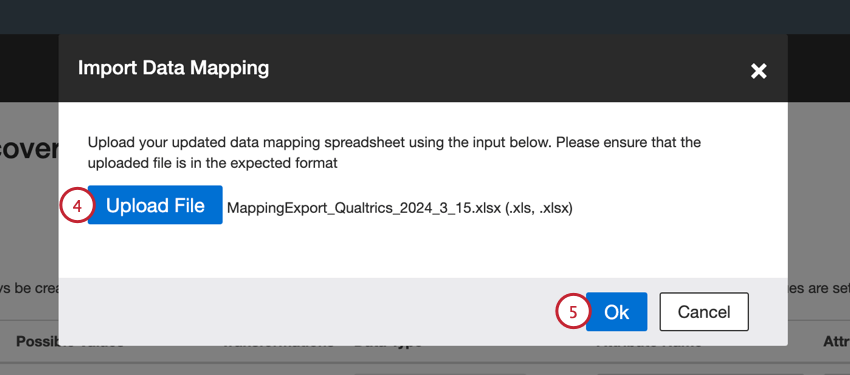
Astuce : Veillez à cliquer sur Appliquer pour enregistrer vos modifications.
Versions de la cartographie des données
Le Fonction mappage des données d’un travail conserve jusqu’à 30 des dernières versions sauvegardées du mappage des données de votre travail. Vous pouvez restaurer n’importe lequel de ces mappages de données sauvegardés si nécessaire.
Attention : Une version de mappage de données est un instantané quotidien de la configuration du mappage de données d’un travail. Une version est créée chaque fois qu’une cartographie de données est sauvegardée. En cas de modifications multiples de la cartographie des données au cours de la journée, chacune d’entre elles est d’abord enregistrée séparément. À la fin de chaque journée, s’il existe plusieurs versions pour cette journée, le système conserve la version la plus récente et supprime les autres.
Passez d’une version de mappage de données à l’autre en suivant les étapes ci-dessous :
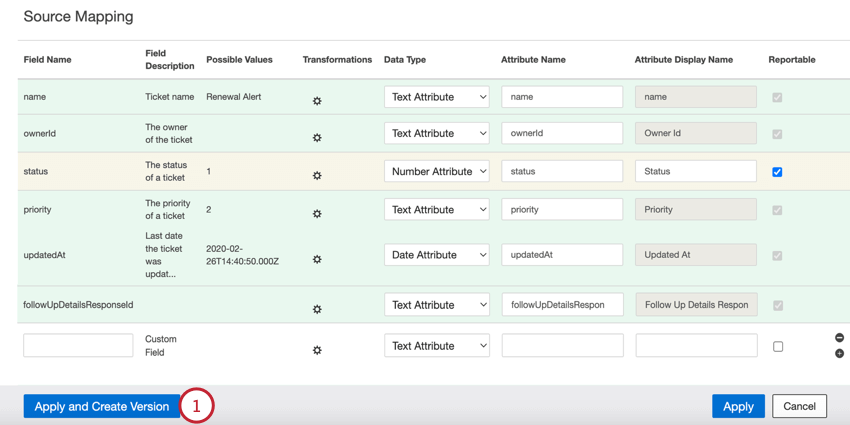
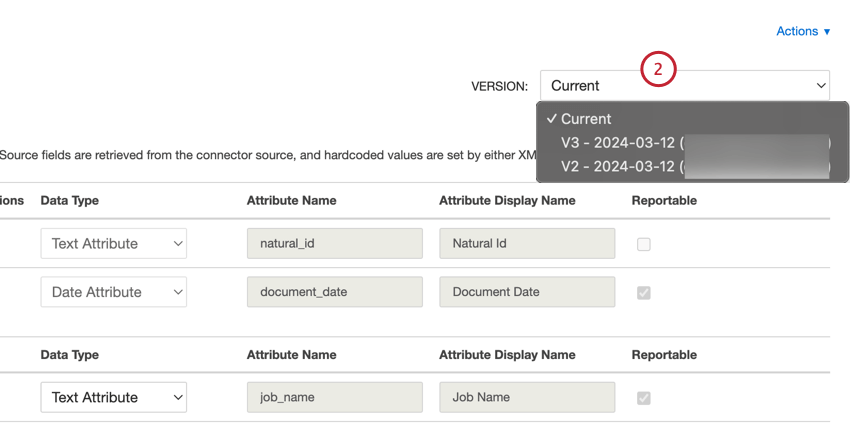
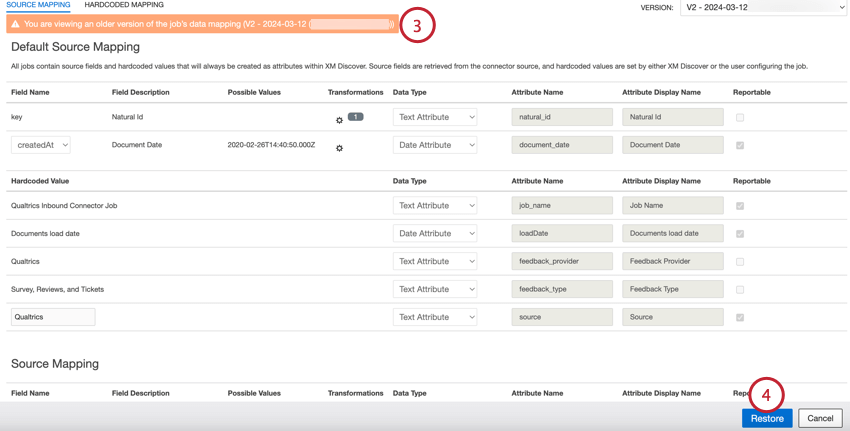
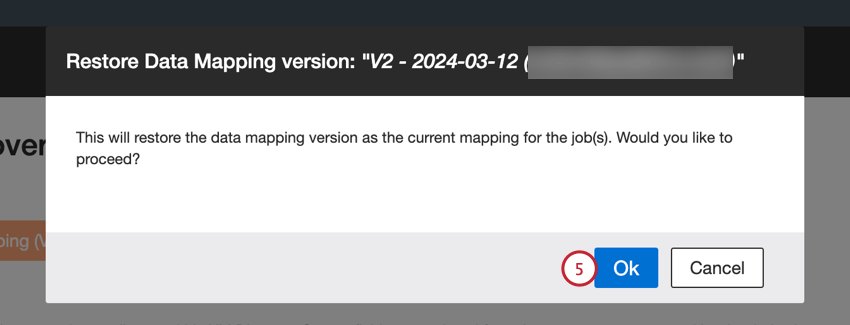
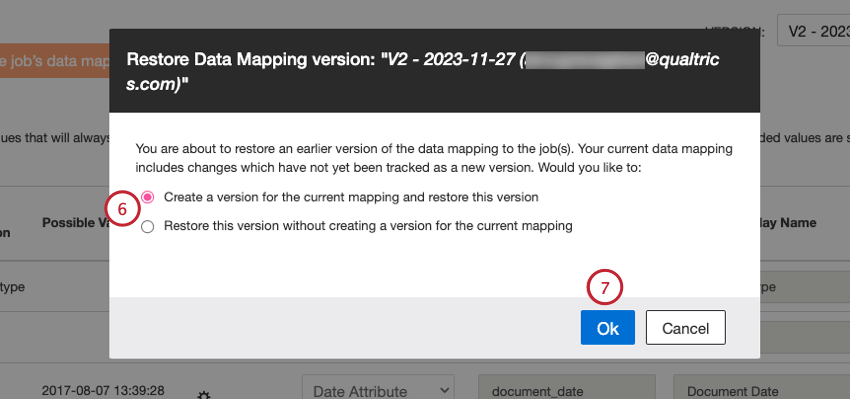
- Créer une version pour le mappage actuel et restaurer cette version: Enregistrer le mappage non sauvegardé en tant que version distincte et restaurer la version sélectionnée.
- Restaurer cette version sans créer de version pour le mappage actuel: Perdre le mappage non enregistré et restaurer la version sélectionnée.
Astuce : Veillez à cliquer sur Appliquer pour enregistrer vos modifications.
Rapport de Fonction mappage des données
Le rapport de Fonction mappage des données vous permet de vérifier les correspondances entre les sources à l’aide d’un fichier de correspondance généré automatiquement.
Astuce : Vous ne pouvez télécharger la fonction mappage des données que si tous les projets sélectionnés se trouvent dans le même projet.
Une fois votre fichier téléchargé, les champs suivants sont disponibles dans le rapport :
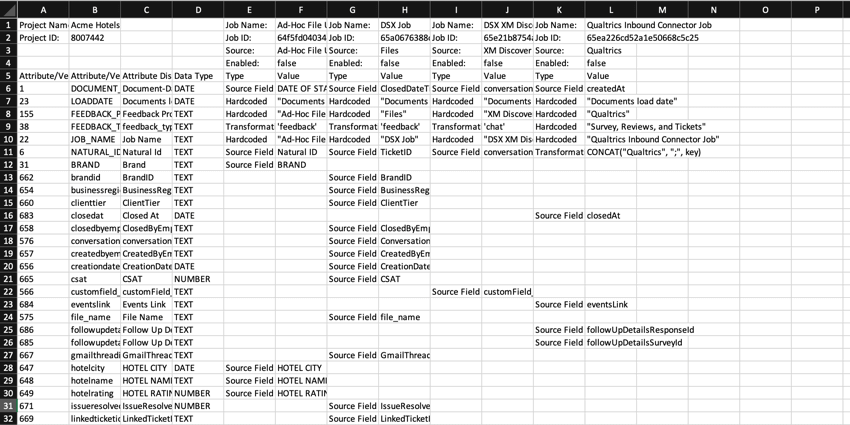{kind=link}
- Nom du projet: Le nom du projet XM Discover dans lequel les données sont téléchargées.
- ID du projet: L’identifiant du projet.
- Nom du travail: Le nom du travail.
- Job ID: L’ID du travail.
- Source: La source de données pour laquelle ce travail est configuré.
- Activé: L’état indique si le travail est activé ou non.
- ID du type d’attribut/verbatime: L’ID de l’attribut/verbatime.
- Attribut/Verbatim Name (Nom de l’attribut/du verbatim) : Le nom système de l’attribut/verbatim enregistré par XM Discover.
- Nom d’affichage de l’attribut: Nom d’affichage de l’attribut enregistré par XM Discover. Vous pouvez laisser la technologie de l’information comme “Attribut de l’utilisateur” ou fournir une version plus conviviale.
- Type de données: Le type de l’attribut. Les valeurs possibles sont les suivantes :
- NUMÉRO: Défini automatiquement pour les champs de type numérique.
- TEXTE: défini automatiquement pour les champs de type texte.
- DATE: défini automatiquement pour les champs de type date.
- VERBATIM: Défini pour les champs verbatim et les commentaires textuels.
- Type: Le type du champ de données mappé. Les valeurs possibles sont les suivantes :
- Source Field (Champ source): Le type du champ de données avec les mappages de source par défaut pour les attributs communs qui sont ajoutés à tous les documents téléchargés via ce travail.
- Codé en dur: Type de champ de données dont les valeurs sont codées en dur pour chaque enregistrement.
- Transformations: Type de champ de données dont les valeurs du champ source ont été transformées et modifiées.
- Valeur: La valeur de l’attribut.
C'est génial! Merci pour votre avis!
Merci pour votre avis!