-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Predict iQ
À propos de Predict iQ
Lorsque les clients quittent une entreprise, nous sommes souvent pris au dépourvu. Si seulement nous avions su que ce client était à risque, nous aurions peut-être pu le contacter avant qu’il ne perde totalement confiance en nous. Si seulement il existait un moyen de prédire la probabilité qu’un client quitte l’entreprise.
Predict iQ s’appuie sur les réponses des enquêtés et les données intégrées pour prédire si l’enquêté se désabonnera. Ensuite, lorsque de nouvelles réponses à l’enquête sont reçues, Predict iQ peut prédire la probabilité que les répondants à l’enquête se désabonnent à l’avenir. Pour prédire si un client va se désabonner, Predict iQ utilise des réseaux neuronaux (dont un sous-ensemble est appelé Deep Learning) et la régression pour construire des modèles candidats. La Technologie de l’information essaie des variantes de ces différents modèles pour chaque ensemble de données et choisit ensuite le modèle qui correspond le mieux aux données.
Préparation des données
Avant de créer un modèle de prédiction de désabonnement, vous devez vous assurer que vos données sont prêtes.
Predict iq fonctionne mieux lorsque vous avez au moins 500 répondants qui ont changé de fournisseur. Cependant, 5 000 répondants ou plus vous permettront d’obtenir les meilleurs résultats.
Mise en place d’une variable de désabonnement
- Dans l’enquête où vous souhaitez prédire le taux de désabonnement, accédez au flux d’enquête.
- Cliquez Ajouter un nouvel élément ici .
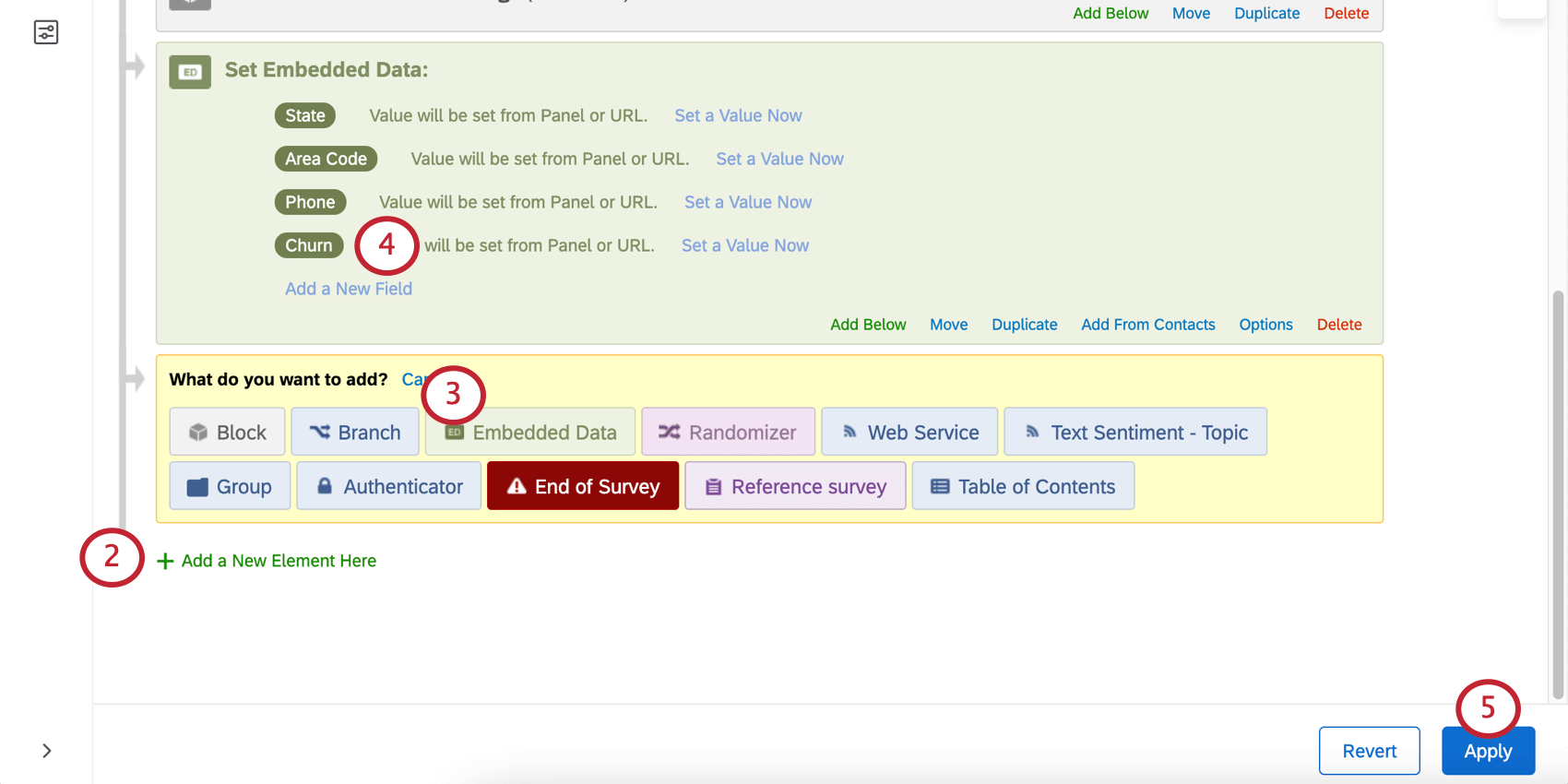
- Sélectionnez Données intégrées.
- La technologie vous demande de saisir un nom de champ. Vous pouvez saisir le nom de champ de votre choix. Dans le cas présent, nous avons choisi la méthode simple du désabonnement.
- Cliquez sur Appliquer).
- Vous pouvez également répéter ce processus pour d’autres données que vous souhaitez intégrer, en particulier les données opérationnelles qui pourraient être utiles pour prédire le taux de désabonnement (par exemple, l’ancienneté ou le nombre d’achats).
Enregistrement des données
Une fois que vous disposez d’une variable relative au taux de désabonnement, vous pouvez importer des données historiques dans votre enquête, y compris une colonne pour le taux de désabonnement dans laquelle vous indiquez par Oui ou Non si le client a désabonné.
Création d’un modèle de prédiction de désabonnement
Une fois que votre variable de désabonnement est configurée et que vous disposez de suffisamment de données, vous êtes prêt à ouvrir Predict iQ.
- Dans votre enquête, cliquez sur Données et analyse.
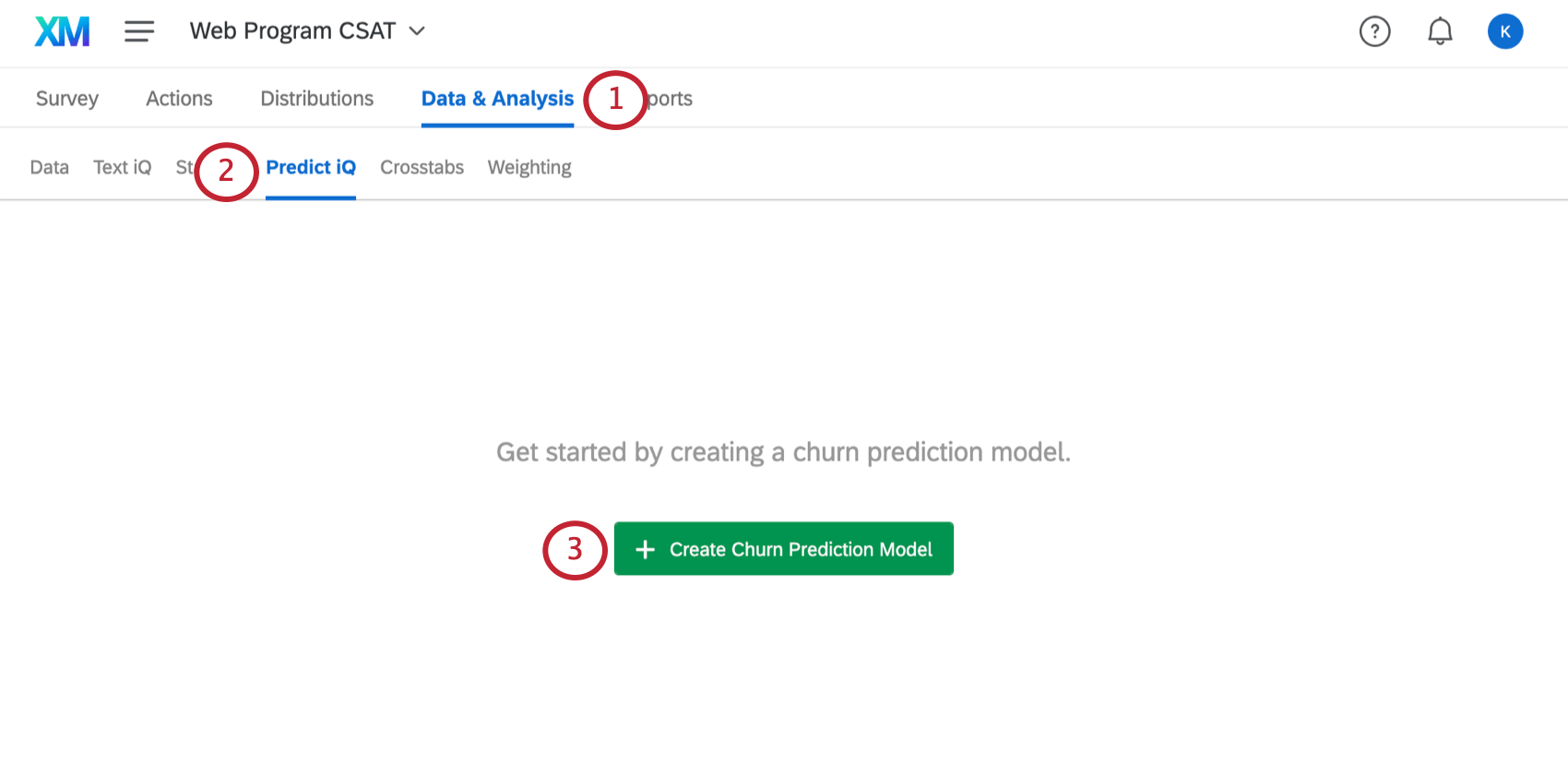
- Sélectionnez Predict iQ.
- Cliquez sur Create Churn Prediction Model (Créer un modèle de prédiction de désabonnement).
- Sélectionnez la variable que vous avez créée dans la section précédente. Dans cet exemple, il s’agit du taux de désabonnement.
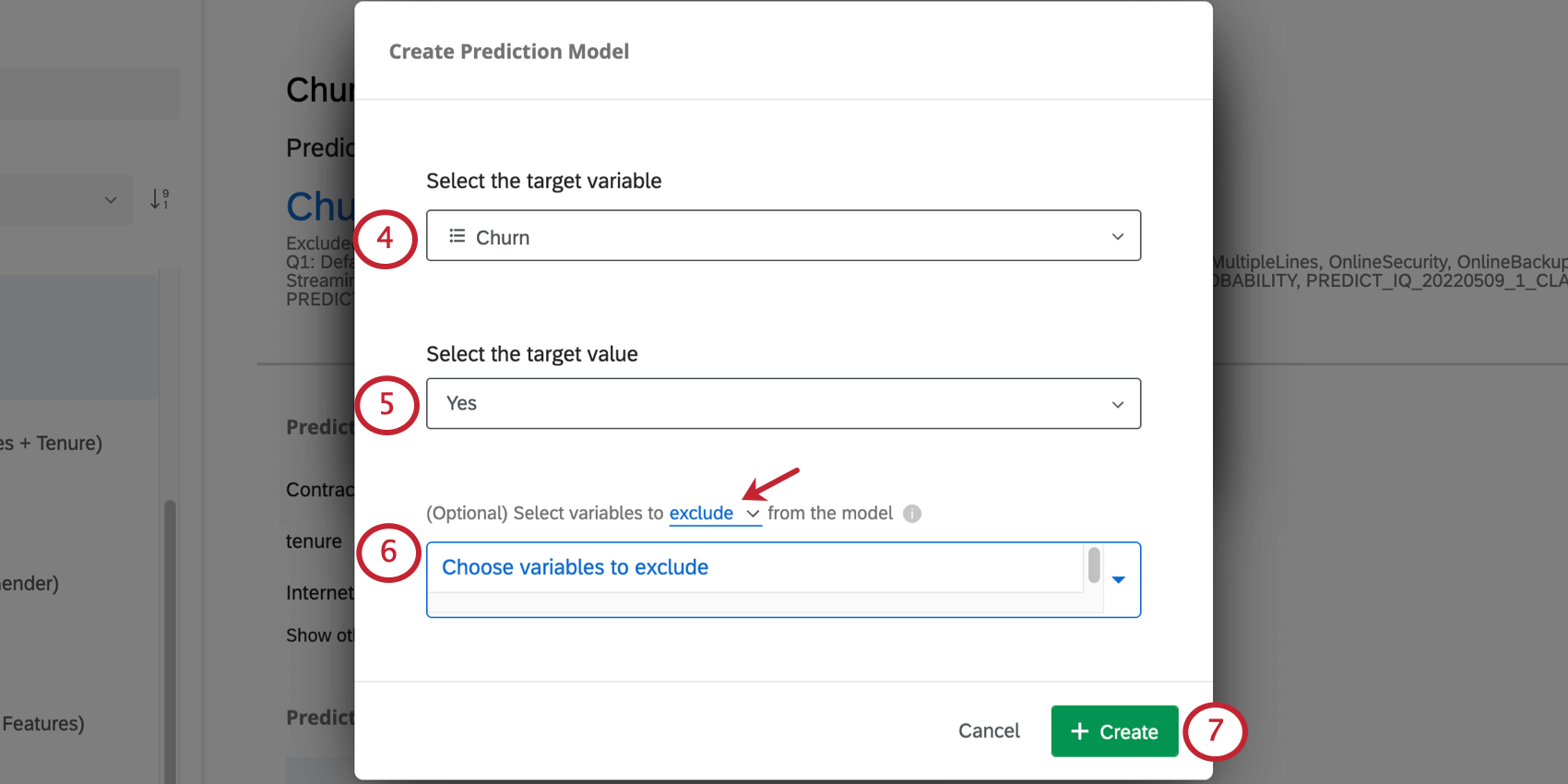 Astuce: Predict iQ ne prédit que les résultats comportant deux choix possibles, tels que Oui/Non ou Vrai/Faux. La technologie de l’information ne permet pas de prédire les résultats numériques (par exemple, une échelle de 1 à 7) ou les résultats catégoriels comportant plus de deux valeurs (par exemple, oui/peut-être/non).
Astuce: Predict iQ ne prédit que les résultats comportant deux choix possibles, tels que Oui/Non ou Vrai/Faux. La technologie de l’information ne permet pas de prédire les résultats numériques (par exemple, une échelle de 1 à 7) ou les résultats catégoriels comportant plus de deux valeurs (par exemple, oui/peut-être/non). - Sélectionnez la valeur qui indique que le client s’est désabonné.
Exemple : Parce que dans cet exemple notre variable est nommée Churn, une personne dont le Churn est égal à Yes a effectué un churn. Mais supposons que vous ayez nommé votre variable ” Staying with our company” (rester dans notre entreprise). Dans ce cas, le non indiquerait que la personne n’est pas restée dans l’entreprise et qu’elle a changé d’employeur.
- Sélectionnez les variables à exclure du modèle ou à inclure dans le modèle. Cliquez sur exclure/inclure pour passer de l’un à l’autre.
- Exclure : Par exemple, si vous disposez d’une variable mesurant la “raison du désabonnement” dans vos données historiques, vous voudrez peut-être l’exclure de l’analyse, car elle ne sera pas disponible pour les nouvelles personnes interrogées au moment où la prédiction est faite.
Astuce : Vous pouvez exclure plusieurs variables. Cliquez sur le X suivant une variable pour la supprimer de la liste des variables exclues.

- Inclure : Sélectionner les variables à inclure dans le modèle ; toutes les autres seront ignorées.
- Exclure : Par exemple, si vous disposez d’une variable mesurant la “raison du désabonnement” dans vos données historiques, vous voudrez peut-être l’exclure de l’analyse, car elle ne sera pas disponible pour les nouvelles personnes interrogées au moment où la prédiction est faite.
- Cliquez sur Créer.
Une fois votre modèle de prédiction terminé, la page Predict iQ sera remplacée par des informations sur le modèle de prédiction de désabonnement que vous venez de créer.
Comment votre ensemble de données est-il divisé pour l’apprentissage du modèle ?
Lors du processus de formation de votre modèle, votre ensemble de données est divisé en données de formation, de validation et de test. 80 % de vos données sont utilisées pour la formation. 10 % de vos données sont utilisées pour la validation, et 10 % de vos données sont utilisées pour le test.
Informations variables
La section Résultats et configuration du modèle de prédiction indique le nom de votre variable Données intégrées Churn et la valeur qui indique qu’un client est susceptible de se désabonner. Cette section dresse également la liste des variables exclues.

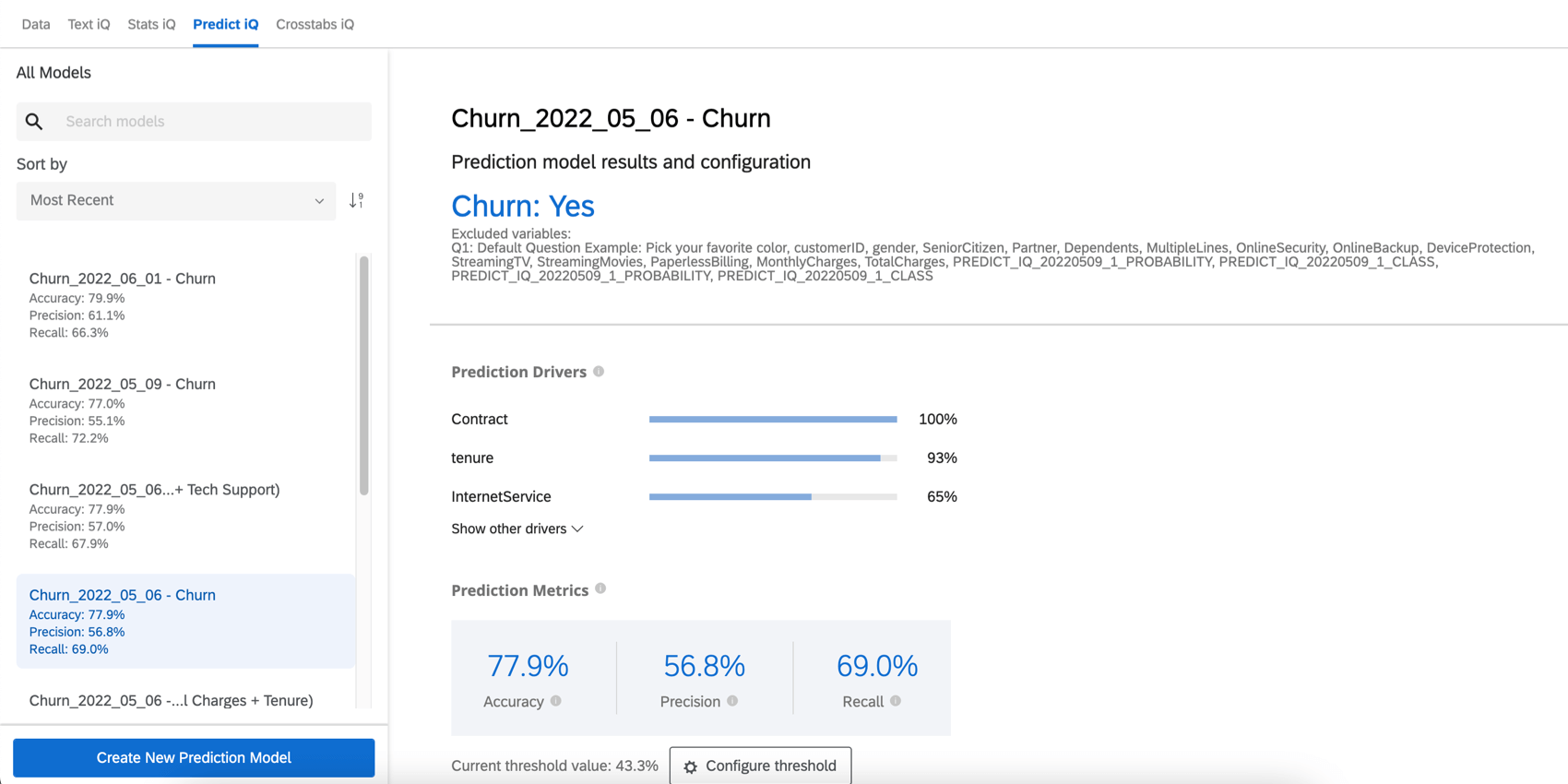
Points de prédiction
Les facteurs de prédiction sont les variables qui ont été analysées pour créer votre modèle de prédiction, classées par ordre d’importance dans la prédiction du taux de désabonnement. Il s’agit de toute variable qui n’a pas été exclue de l’analyse. Dans l’exemple ci-dessous, les scores NPS et les notations de fiabilité permettent de prédire le taux de désabonnement.
Cliquez sur Afficher les autres pilotes pour développer la liste.
Astuce : Pour créer ce graphique, chaque variable fait l’objet d’une régression logistique simple par rapport à la variable du taux de désabonnement. La valeur de r-carré la plus élevée est fixée à 1, et les valeurs des autres variables sont échelonnées en conséquence. Par exemple, si le r-carré le plus élevé est de 0,5, la longueur de la barre de chaque variable sera r-carré * 2, la longueur de la barre étant de 1.
Le graphique est donc un indicateur de la force relative des variables dans la prédiction du taux de désabonnement et n’est pas de nature multivariable. L’évaluation de l’impact de chaque variable sur les résultats d’un modèle basé sur un algorithme d’apprentissage profond est un domaine de recherche universitaire actif, sans qu’aucune meilleure pratique ne soit acceptée à ce jour.
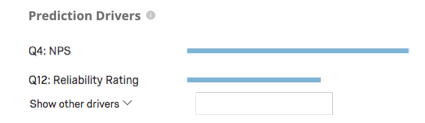
Mesures de prédiction
Predict iq “retient” (met de côté) 10 % des données avant de créer le modèle. Une fois le modèle créé, il permet d’établir des prévisions pour ces 10 %. La technologie de l’information compare ensuite ses prédictions à ce qui s’est réellement passé, à savoir si ces clients ont effectivement changé de fournisseur. Ces résultats sont utilisés pour alimenter les mesures de précision ci-dessous. Il convient de noter que, bien qu’il s’agisse d’une méthode efficace pour estimer la précision du modèle, elle ne constitue pas une garantie de la précision future du modèle.
- Précision : La proportion des prédictions du modèle qui seront exactes.
- Précision : La proportion de clients dont on prédit qu’ils vont se désabonner et qui vont effectivement se désabonner.
- Rappel : La proportion de ceux qui ont effectivement chronométré et dont le modèle avait prédit à l’avance qu’ils le feraient.
Predict iQ calculera la valeur seuil optimale en maximisant la notation F1. Votre modèle sera réglé par défaut sur le seuil optimal, mais vous pouvez l’ajuster ; voir Configurer le seuil ci-dessous.
Cliquez sur Sortie avancée sous le tableau des mesures prédictives pour faire apparaître les tableaux Matrice de confusion et Mesures prédictives avancées.
Précision et rappel
La
précision et le rappel sont les mesures de prédiction les plus importantes. Ils ont un lien inverse, et vous devez donc souvent réfléchir à un compromis entre le fait de savoir exactement quels clients vont se désabonner et le fait de savoir que vous avez identifié tous ou la plupart des clients susceptibles de se désabonner.
Configurer le seuil
Cliquez sur Configurer le seuil pour définir un seuil à partir duquel un client doit être étiqueté comme susceptible de changer de fournisseur. Ce pourcentage seuil correspond à la probabilité individuelle de désabonnement.
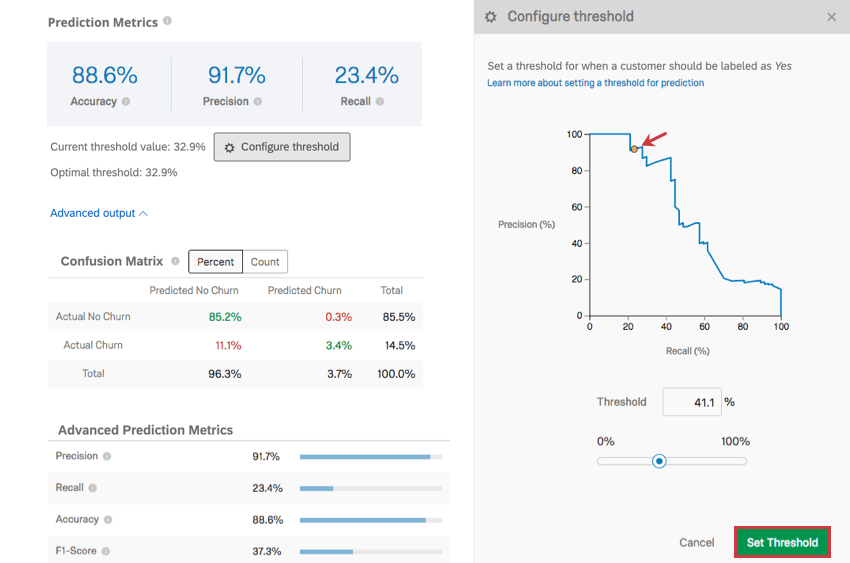
Cliquez et faites glisser le point sur le graphique pour ajuster le seuil, ou tapez un % de seuil et observez comment le graphique change. Lorsque vous avez terminé, cliquez sur Définir le seuil pour enregistrer vos modifications. Vous pouvez également annuler les modifications en cliquant sur Annuler en bas à droite ou sur le X en haut à droite.
L’ajustement du seuil permet d’ajuster la précision sur l’axe des y et le rappel sur l’axe des x. Ces paramètres ont un lien inverse. Plus les mesures sont précises, plus le rappel est faible, et inversement.
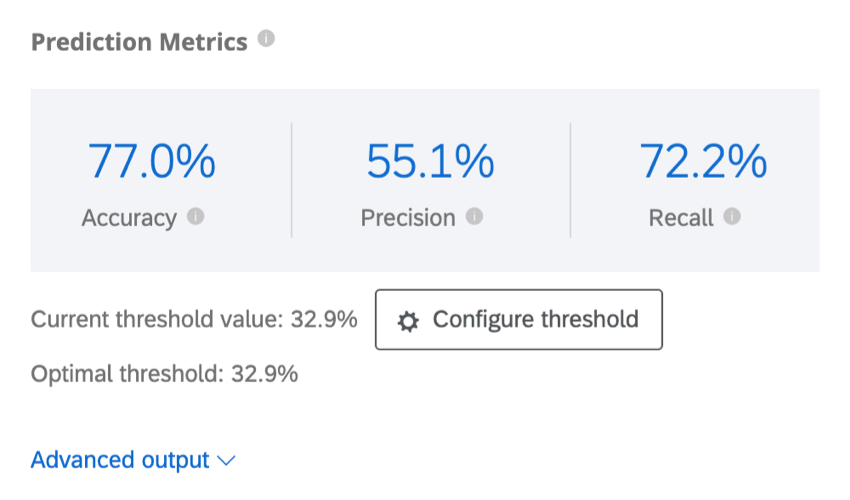
Matrice de confusion
Lorsque Predict iQ construit un modèle de prédiction, il “retient” (ou met de côté) 10 % des informations. Pour vérifier l’exactitude du modèle généré, les données du nouveau modèle sont comparées à celles de la réserve de 10 %. Cela permet de faire une comparaison entre ce qui est prévu et ce qui s’est “réellement passé”
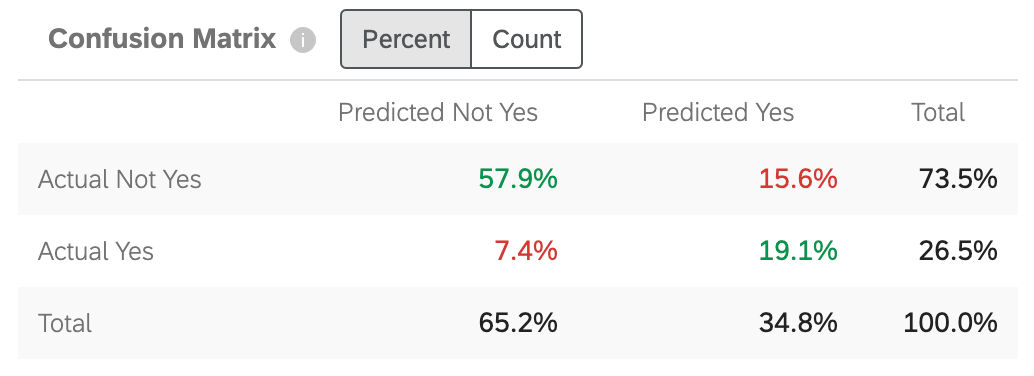
la mention “Oui” dans ce tableau sera remplacée par la valeur cible que vous avez indiquée à l’étape 5 de la configuration.
- Actual Not Yes / Predicted Not Yes : Le pourcentage de clients dont le modèle prédit qu’ils ne se désabonneront pas et qui ne se désabonneront pas en réalité.
- Oui réel / Non prédit : le pourcentage de clients qui, selon le modèle, ne quitteraient pas l’entreprise et qui, à l’inverse, l’ont quittée.
- Non oui réel / Oui prédit : Pourcentage de clients qui, selon le modèle, allaient se désabonner et qui, à l’inverse, ne se sont pas désabonnés.
- Oui réel / Oui prédit : Le pourcentage de clients que le modèle prévoyait de désabonner et qui ont effectivement désabonné.
Les chiffres sont verts pour indiquer que vous souhaitez qu’ils soient aussi élevés que possible, car ils reflètent des suppositions correctes. Les chiffres sont en rouge pour indiquer que vous souhaitez qu’ils soient faibles, car ils reflètent des suppositions erronées.
Vous pouvez ajuster la matrice pour qu’elle affiche soit le pourcentage, soit le nombre. Ce décompte comprend les 10 % de vos données diffusées, et non l’ensemble des données.
Mesures de prédiction avancées
Ce tableau présente des mesures de prédiction supplémentaires.
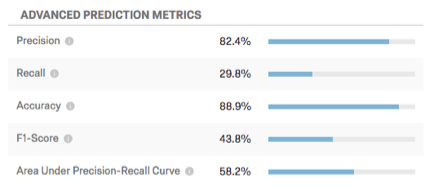
- Précision : La proportion de clients dont on prédit qu’ils vont se désabonner et qui vont effectivement se désabonner.
- Rappel : La proportion de ceux qui ont effectivement chronométré et dont le modèle avait prédit à l’avance qu’ils le feraient.
- Précision : La proportion des prédictions du modèle qui seront exactes.
- Notation F1 : Le score F1 est utilisé pour sélectionner un seuil qui équilibre la précision et le rappel. Une notation F1 plus élevée est généralement préférable, même si le seuil à fixer doit être déterminé en fonction des objectifs de votre entreprise.
- Aire sous la courbe de précision-rappel : La courbe de précision-rappel est la courbe que vous observez sur le graphique lorsque vous cliquez sur Configurer le seuil. La surface totale sous la courbe est une mesure de la précision globale du modèle (indépendamment de l’endroit où vous avez fixé le seuil). Une aire sous la courbe de 50 % est égale à la généralisation de la randomisation ; 100 % correspond à une précision parfaite.
Faire des prédictions
Prédiction par lot (CSV)
Outre l’analyse des réponses que vous avez recueillies dans votre enquête, vous pouvez également télécharger un fichier de données spécifique que vous souhaitez faire évaluer par Predict iQ.
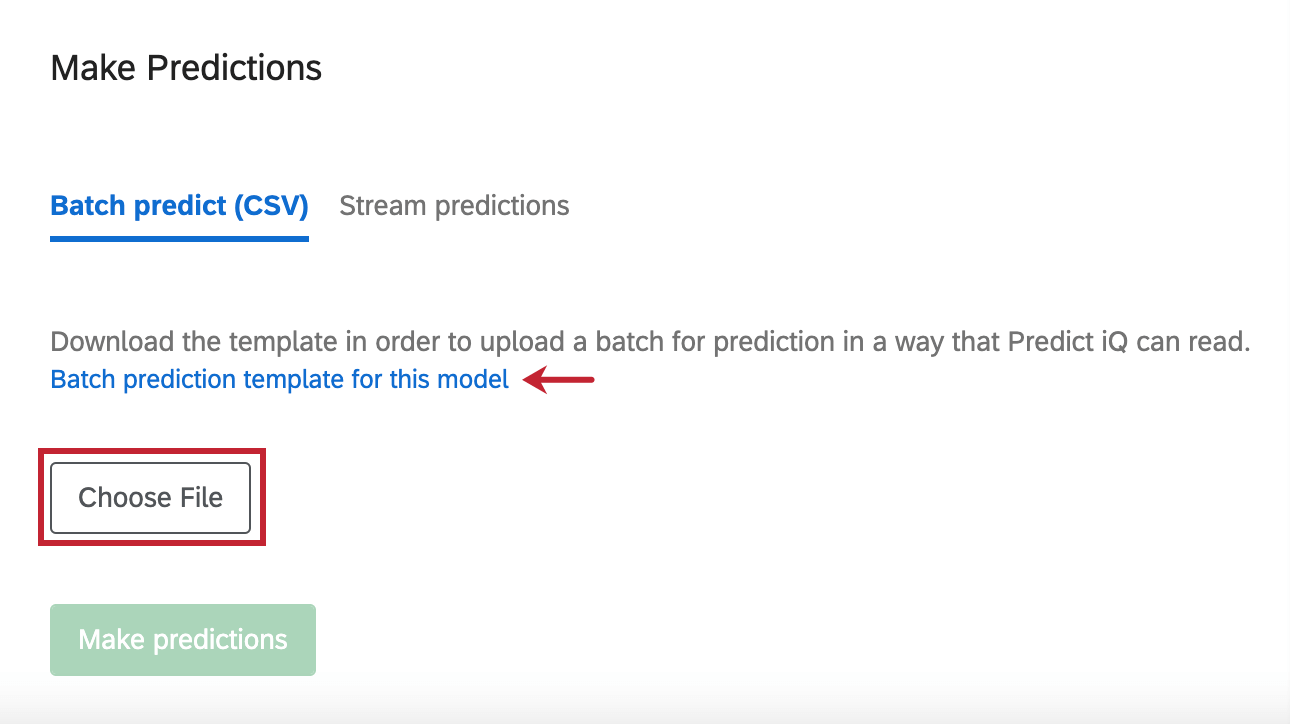
Pour obtenir un modèle de fichier, cliquez sur Modèle de prédiction par lot pour ce modèle.
Lorsque vous avez terminé de modifier votre fichier dans Excel et que vous êtes prêt à le télécharger à nouveau, cliquez sur Choisir un fichier pour sélectionner le fichier. Cliquez ensuite sur Faire des prédictions pour lancer l’analyse.
Prédictions de flux
Les prévisions de flux sont mises à jour au fur et à mesure de l’arrivée des données dans l’Enquête. Dans cette section, vous pouvez décider quand ces mises à jour de prédiction ont lieu.
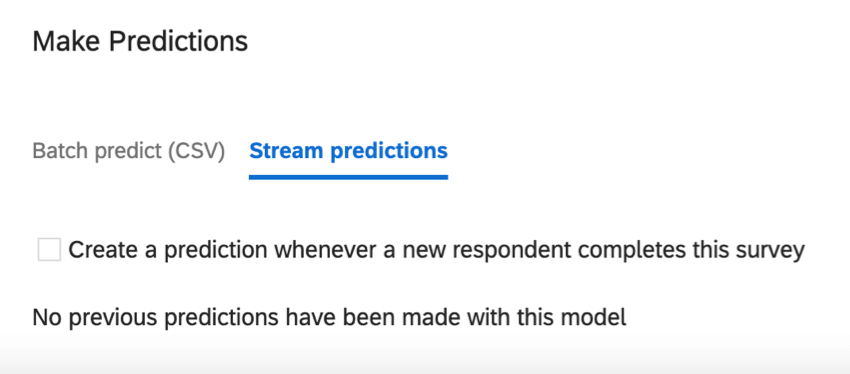
Créer une prédiction chaque fois qu’un nouveau répondant complète cette enquête : Ce paramètre permet de créer des prédictions en temps réel. Vos données comporteront deux colonnes supplémentaires : Probabilité de désabonnement, la probabilité de désabonnement au format décimal ; et Prédiction de désabonnement, une variable Oui/Non. La prédiction de désabonnement est basée sur le seuil configuré.
Manager les modèles
Sur la gauche de la page, vous verrez un menu dans lequel vous pourrez faire défiler et sélectionner les modèles de prédiction que vous avez créés par le passé.
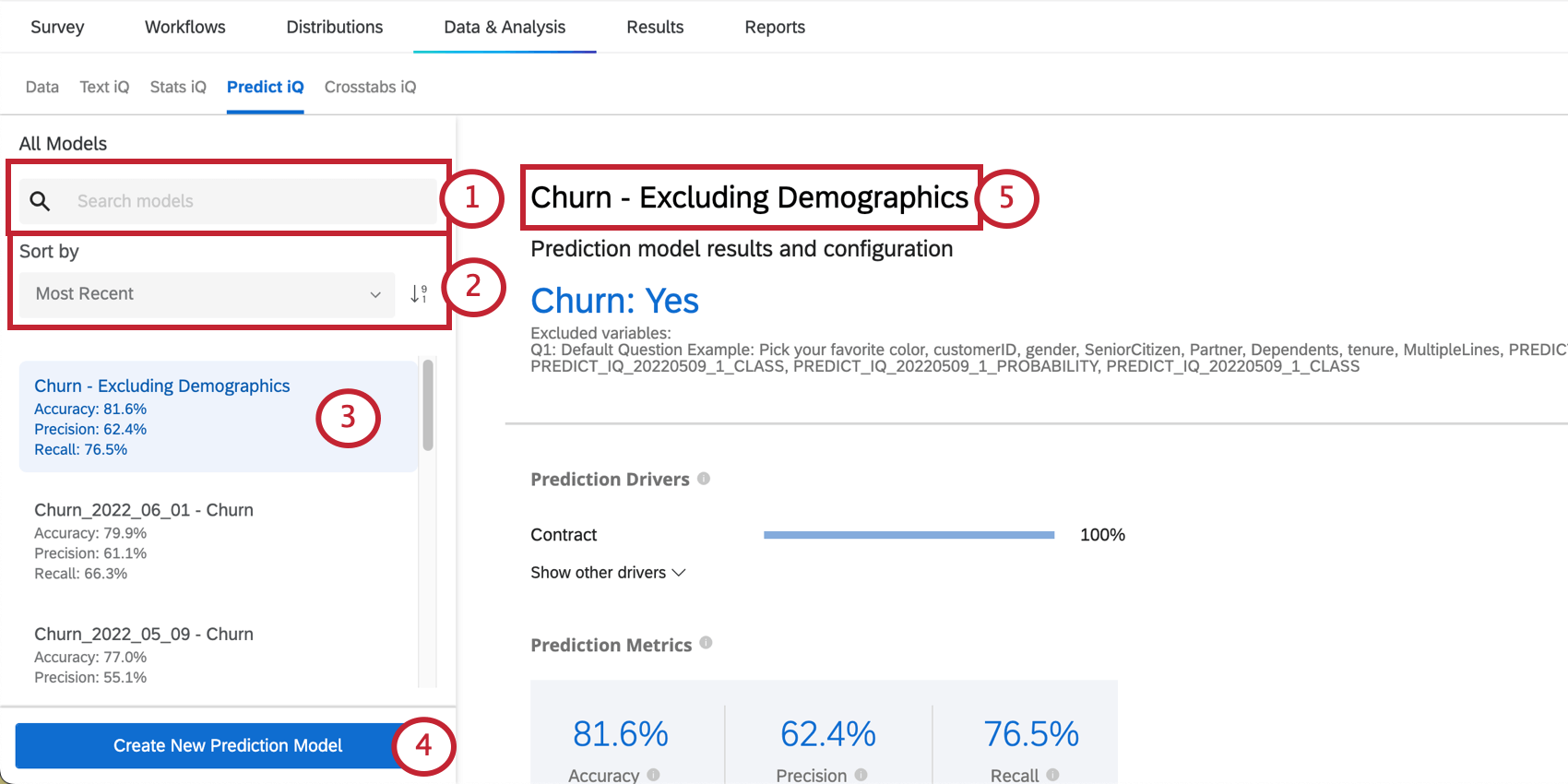
- Recherche par nom de modèle.
- Triez votre liste de modèles. Cliquez sur la liste déroulante pour choisir le critère de tri et utilisez la flèche située à côté de la liste déroulante pour déterminer si vous souhaitez effectuer un tri par ordre décroissant ou croissant.
- Sélectionnez le modèle que vous souhaitez visualiser.
- Créer un nouveau modèle de prédiction.
- Une fois que vous avez sélectionné un modèle à gauche, vous pouvez cliquer sur son nom en haut de la page pour le modifier.
Données sur le désabonnement
Dans la section Données de l’onglet Données et analyse, vous pouvez exporter vos données sous la forme d’une feuille de calcul pratique. Une fois votre modèle de prédiction chargé, vous aurez des colonnes supplémentaires pour les données de désabonnement sur cette page.
![]()
- Probabilité de désabonnement : Probabilité de désabonnement au format décimal. Apparaît lorsque la prédiction de flux a été activée et est basée sur le seuil défini. Si vous ne voyez pas la colonne Probabilité de désabonnement, vous pouvez également rechercher une colonne de données nommée “[champ de désabonnement sélectionné]_PROBABILITE_PREDICT_IQ”.
- Prévision de désabonnement : Une variable Oui/Non confirmant ou infirmant le désabonnement en fonction du seuil fixé. Apparaît lorsque la prédiction de flux a été activée. Si vous ne voyez pas la colonne Prédiction de désabonnement, vous pouvez également rechercher une colonne de données nommée “[champ de désabonnement sélectionné]_CLASS_PREDICT_IQ”.
Les noms de colonnes comprendront également la date à laquelle le modèle a été formé au format MMDDYYYY. Par exemple, le 14 janvier 2022 sera représenté dans le nom de la colonne par 01142022.
Notez que les probabilités de désabonnement et les prévisions ne sont appliquées qu’aux nouveaux résultats d’enquêtes. Les réponses déjà existantes ne seront pas assorties de probabilités de désabonnement et de prédictions.
Nettoyage automatique des données
Lors de l’entraînement du modèle, Predict iQ ignorera automatiquement certains types de variables qui ne seront pas utiles pour les prédictions, tout en transformant automatiquement d’autres variables.
Variables à cardinalité élevée
Si une variable a plus de 50 valeurs uniques ou si plus de 20 % des valeurs enregistrées sont uniques, elle sera ignorée lors de l’apprentissage du modèle. Les variables ayant trop de valeurs uniques ne sont pas de bonnes colonnes de fonctions pour les prédictions.
Valeurs manquantes pour les colonnes numériques
Pour les variables numériques incluses dans le modèle, les valeurs manquantes sont toujours imputées à 0 (zéro).
Encodage à chaud des catégories
Les variables catégorielles seront codées en une seule fois si la variable n’est pas recodée ou si la variable n’a pas de lien ordinal pour ses catégories.
Astuce : Predict iQ reprend les mêmes paramètres de variables que ceux utilisés dans Stats iQ.
Variables invariantes
Toute variable dont les valeurs enregistrées ne présentent aucune variance sera ignorée pour l’apprentissage du modèle. Cela signifie que si vous avez une variable qui n’a qu’une seule valeur unique, elle ne fera pas partie du modèle. Les variables utiles pour la prédiction trouveront un bon équilibre entre trop peu de valeurs uniques et trop de valeurs uniques. Voir ci-dessus “Variables à forte cardinalité”.
Si des variables invariantes sont exclues lors du nettoyage des données, elles seront listées dans la section Résultats et configuration du modèle de prédiction.
Projets pour lesquels vous pouvez utiliser Predict iQ
Predict iQ n’est pas inclus dans toutes les licences. Cependant, si vous disposez de cette fonction, elle peut être accessible dans quelques types de projets différents :
Predict iQ peut également apparaître dans les projets Engage et Lifecycle, mais compte tenu de la nature des données habituellement collectées par ces types de projets, l’ensemble de données ne serait pas nécessairement le meilleur pour Predict iQ.
Bien que Predict iq apparaisse dans Conjoint et Différence maximum, nous ne recommandons pas de les utiliser ensemble. Les contenus spécifiques aux Conjoints et aux Différences maximum ne sont pas compatibles avec Predict iQ, de sorte que vous ne pouvez analyser que des données démographiques.
Aucun autre type de projet n’est pris en charge.