Comprendre votre ensemble de données
Contenus de cette page
À propos de votre ensemble de données de réponses
Pour une analyse complémentaire en dehors de Qualtrics, vous pouvez télécharger un fichier de données pour n’importe quelle enquête. Cet ensemble de données inclut toutes les données de réponses brutes de votre enquête, qui couvrent tout, des réponses aux questions de l’enquête aux métadonnées supplémentaires telles que la durée et les dates, en passant par les données intégrées, etc.
Sur cette page, nous allons :
- Expliquez les différentes colonnes d’informations que vous pourriez voir dans votre fichier de données.
- Expliquez comment les réponses peuvent être mises en forme dans ce fichier de données, en fonction de la colonne.
- Créez un lien vers d’autres ressources qui vous permettent de comprendre ou de personnaliser votre téléchargement de données.
Cependant, cette page ne traite pas de l’analyse statistique, ni ne vous indique comment interpréter les résultats de vos données, au-delà du littéral (par exemple, ce répondant a indiqué qu’il était très satisfait). Il y a tant de variables et de projets différents qui se lancent dans la recherche, et alors que nous aimerions dire que nous savons tout, cela dépend vraiment des spécificités de votre étude et de la manière dont vous l’avez mise en place !
Attention : le fichier utilisé dans les captures d’écran de cette page a été téléchargé au format CSV et est ouvert dans Excel. Il a également été mis en forme à l’aide de la fonction de renvoi automatique à la ligne pour faciliter la lecture. D’autres formats de fichier incluent les mêmes points de données, mais peuvent afficher le contenu avec une disposition légèrement différente.
Types d’ensembles de données de réponses couverts par cette page
Cette page peut vous aider à comprendre les données brutes que vous exportez à partir des types de projets suivants :
Il existe quelques autres types de projets pour lesquels vous pouvez exporter des données de réponses. Toutefois, il existe des différences importantes à garder à l’esprit :
- Pour les projets 360, voir Comprendre votre jeu de données de réponses (360).
- Pour tous les autres projets relatifs à l’Employee Experience, voir Comprendre votre ensemble de données de réponses (EX).
Techniquement, les ensembles de données conjointe et différence maximum sont également formatés comme décrit sur cette page lorsqu’ils sont exportés à partir de Données et analyse. Toutefois, cette exportation de données exclut les données spécifiques àConjoint et Différence maximum.
Principes de base du format de fichier
Chaque ligne du fichier correspond à une réponse différente à l’enquête (mais pas nécessairement à des répondants différents, si vous laissez les gens répondre plusieurs fois). Chaque colonne correspond à un type de données d’enquête.

Les fichiers CSV et TSV sont fournis avec 3 lignes d’en-têtes. Le premier en-tête est l’ID Qualtrics interne du champ (par ex., EndDate, Q1, Q2, etc.). Le deuxième en-tête correspond au nom ou au texte du champ (par ex., Date de fin, Quel est votre degré de satisfaction concernant Qualtrics ?). Le troisième en-tête contient des ID d’importation. Ces trois en-têtes sont inclus car ils sont nécessaires pour télécharger les données vers une enquête. Les données des répondants commencent sur la quatrième ligne du fichier.
Astuce Qualtrics : selon le format de fichier que vous avez téléchargé (SPSS, Excel, etc.), différents en-têtes peuvent s’afficher. Pour plus d’informations sur les formats disponibles, voir Formats d’exportation.
Informations sur le répondant
Les premières colonnes d’un ensemble de données incluent des informations sur chaque répondant et sa réponse, telles que son nom, son adresse IP, les dates de soumission des réponses, etc. Nous allons répertorier chacune de ces colonnes et comprendre leur contenu ici.
Astuce Qualtrics: le fuseau horaire utilisé pour toutes les dates et heures enregistrées dans votre compte Qualtrics correspond au fuseau horaire défini dans vos paramètres de compte.
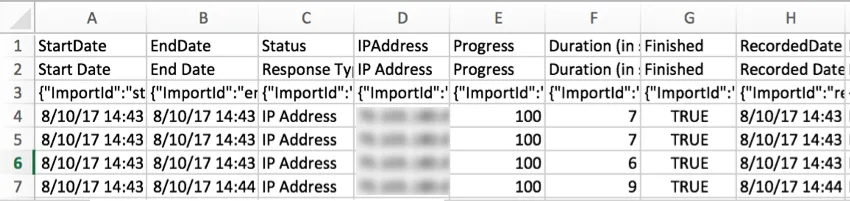
StartDateCes
valeurs de date et d’heure indiquent le moment où les personnes interrogées ont cliqué pour la première fois sur le lien de l’enquête.
Astuce Qualtrics : Si vos colonnes Date de début et Date de fin dans Excel contiennent ######, essayez d’élargir les colonnes. Excel utilise les symboles # lorsqu’une date est trop longue pour entrer dans la colonne.
Date de finCes
valeurs de date et d’heure indiquent quand la personne interrogée a soumis son enquête. Si la valeur saisie est une réponse incomplète, cette date indiquera la dernière fois que le répondant a interagi avec l’enquête.
Astuce : Lorsque vous importez une réponse, vous pouvez lui donner la date de fin ou de début de votre choix. Cependant, une fois qu’une réponse enregistrée, la date de fin et la date de début sont fixées et ne peuvent pas être modifiées.
Statut / Type de réponseLa
valeur de la colonne Statut indique le type de réponses collectées. Il s’agit des états possibles, présentés sous forme de valeurs et d’étiquettes:
- 0 / Adresse IP : une réponse normale
- 1 / Aperçu de l’enquête : A réponse de la prévisualisation
- 2 / Test d’enquête : une réponse test
- 4 / Importé : An réponses importées
- 16 / Hors ligne : A Application hors ligne de Qualtrics réponse
- 17 / Aperçu hors ligne : Prévisualisation des documents soumis par l’intermédiaire de l’application Application hors ligne de Qualtrics. Cette fonctionnalité est obsolète dans les dernières versions de l’application.
- 256 / Synthétique : Une réponse synthétique du panel.
Astuce : les anciens fichiers peuvent également porter les codes 6, 8 ou 12, relatifs au spam. Tous les statuts de spam ont été supprimés. Pour des outils plus performants qui vous aideront à identifier les spams, consultez les rubriques Détection de la fraude et Qualité des réponses.
Astuce : Si vous exportez vos données en activant l’option Exporter les étiquettes, votre exportation contiendra le texte de chaque statut (par exemple, Aperçu de l’enquête) au lieu du code numérique.
Astuce Qualtrics : les réponses sous licence sont des réponses complétées qui ne sont pas des aperçus d’enquête ou des tests d’enquête. Les réponses complétées incluent les enquêtes terminées et les enquêtes incomplètes qui ont été retirées des réponses en cours et enregistrées. Contactez votre Commercial pour connaître les prix des réponses importées. Si vous souhaitez consulter le nombre de réponses que vous avez utilisées, allez dans les Paramètres du compte, puis dans la rubrique Utilisation du compte.
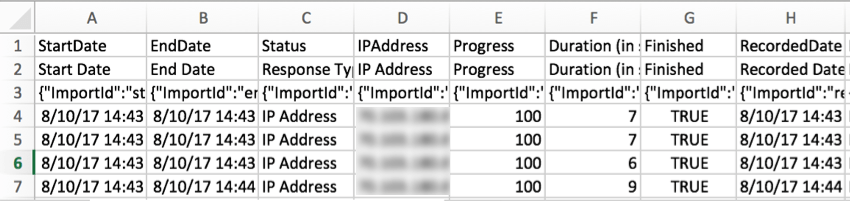
IPAddressCette
colonne contient l’adresse IP du répondant. Ces données ne seront pas disponibles si les réponses ont été complètement anonyme.
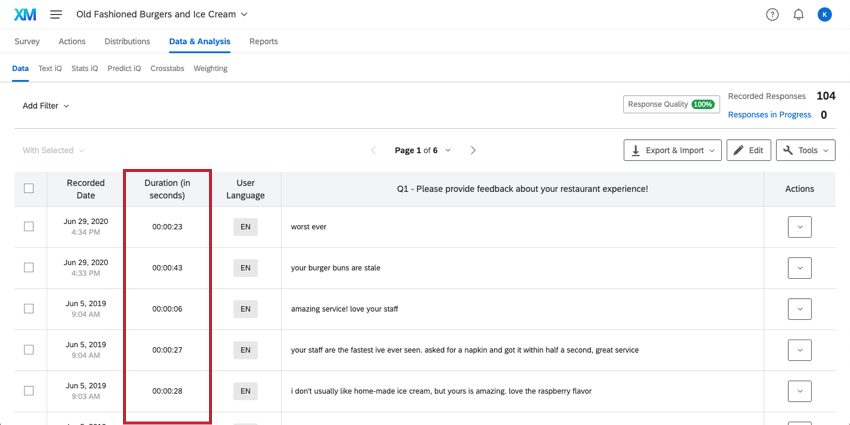
DuréeLe
nombre de secondes qu’il a fallu à la personne interrogée pour répondre à l’enquête. Il s’agit de la durée totale de la réponse ; si un répondant s’arrête au milieu de l’enquête, ferme le navigateur et revient un autre jour, ce temps est compté.
Astuce Qualtrics : alors que l’exportation mesure la durée en secondes, dans l’onglet Données, ce champ est affiché au format heures:minutes:secondes.

{kind=link}
{kind=link}
{kind=link}
Fini et ProgrèsLa
colonne Fini indique si la réponse a été soumise ou clôturée. Un “1” ou un “Vrai” indique que la personne interrogée a atteint un point final dans son enquête (en appuyant sur le dernier bouton Suivant/Soumettre, en étant éliminée par la Logique de Saut ou de Branche, etc.) Un “0” ou un “Faux” indique que la personne interrogée a quitté l’enquête avant d’atteindre un point final et que la réponse a été fermée manuellement ou en raison de l’expiration de la session.
La colonne Progression indique l’état d’avancement de la personne interrogée dans l’enquête avant qu’elle ne la termine. Pour ceux qui sont marqués “1” ou “Vrai” dans la colonne Terminé, le Progrès est marqué 100. Pour les personnes dont les réponses sont marquées “0” ou “Faux”, vous obtiendrez un pourcentage exact de l’état d’avancement de l’enquête en fonction de la question à laquelle elles se sont arrêtées.
Astuce : Le pourcentage d’avancement est calculé sur la base de tous les éléments de l’enquête, y compris les éléments du flux d’enquête. Si votre enquête contient de nombreux éléments, le pourcentage d’avancement peut être inférieur à 1 %, même si des réponses sont apportées aux questions. Les progrès inférieurs à 1 % sont arrondis à 0 %.
RecordedDateCette
colonne indique la date à laquelle une enquête a été enregistrée dans Qualtrics. Pour les utilisateurs répondant aux enquêtes en ligne, cette date et cette heure seront très similaires à la date de fin. En revanche, pour les réponses importées ou téléchargées depuis l’application hors ligne, la date d’enregistrement est souvent différente de la date de fin, indiquant quand vous avez téléchargé manuellement les résultats, et non quand le répondant à l’enquête a terminé.
Astuce Qualtrics : vous remarquez une différence de plusieurs minutes entre la date de fin et la date d’enregistrement ? Une connexion Internet lente peut retarder le délai entre le moment où le répondant soumet ses données d’enquête et celui où Qualtrics les enregistre officiellement sur le site Web.
Astuce Qualtrics : l’ordre d’exportation des réponses est organisé en fonction de la date enregistrée, la réponse enregistrée la plus ancienne apparaissant en premier.
{kind=link}

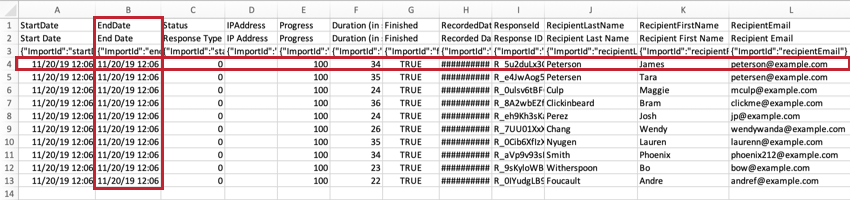
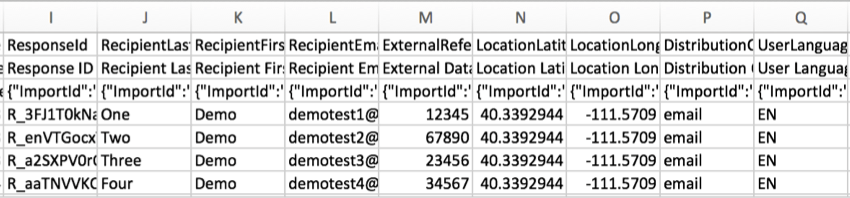
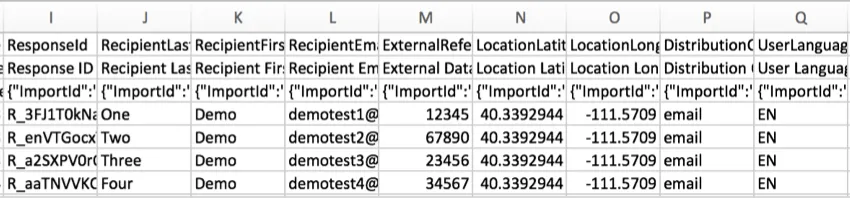
ResponseIDLe
ResponseID est l’identifiant utilisé par Qualtrics pour identifier chaque réponse dans la base de données. Cet identifiant unique est fourni comme référence et n’est généralement pas utilisé dans l’analyse des données.
RecipientLastName, RecipientFirstName, and RecipientEmailLes
noms et adresses e-mail des
répondants s
‘affichent dans ces colonnes si votre enquête a été distribuée à l’aide d’une liste de contacts. Voici quelques-unes des distributions courantes qui utilisent des listes de contacts :
Pour toutes les autres réponses, telles que celles collectées avec un lien anonyme ou avec certaines Options de l’Enquête activées, ces colonnes seront vides. Veuillez noter que toute distribution peut être rendue anonyme, quelle que soit la méthode de distribution.
Astuce : Les noms des répondants seront tirés au sort à partir de la liste des participants liste de contacts sur laquelle la distribution a été basée. La suppression de la liste de contacts ou des informations de la liste de contacts n’aura aucun impact sur les données de réponse, sauf si vous y procédez avant que le répondant commence l’enquête (ou avant l’envoi de la distribution). Si vous supprimez ou modifiez une liste de contacts une fois la réponse collectée, la réponse contiendra toujours les données de contact d’origine. Vous pouvez toujours modifier la réponse si nécessaire.
Astuce : Pour les questions relatives à la confidentialité des répondants et au RGPD, consultez notre page de support Qualtrics & ; RGPD Compliance.
Référence de données externeFréquemment
utilisée lors du téléchargement d’une liste de contacts à Qualtrics pour utilisation dans un authentificateur et occasionnellement dans un e-mail distribution, une référence externe de données peut être incluse pour chaque participant. Il s’agit d’un champ générique qui peut stocker toutes les informations de votre choix (et qui est le plus souvent utilisé pour les identifiants uniques tels que les ID d’employé ou d’étudiant). Si une référence externe de données a été ajoutée à la liste de contacts, elle s’affichera dans cette colonne. Si vous n’avez pas choisi d’utiliser ce champ, la colonne sera vide.
Astuce Qualtrics : pour plus de flexibilité avec les distributions par e-mail et les données collectées à partir de liens d’enquête avec chaînes de requête, nous vous recommandons généralement de télécharger des détails supplémentaires sous la forme de données intégrées plutôt que d’utiliser une référence externe de données.
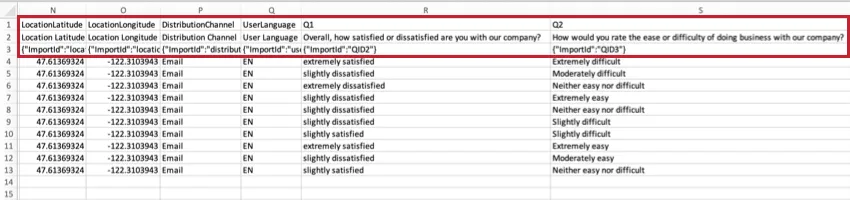
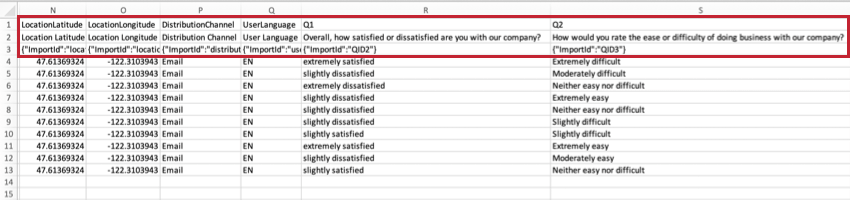
LieuLatitude et LieuLongitudeSi
le répondant a rempli l’enquête à l’aide de l’option Application hors ligne de Qualtrics sur un appareil équipé d’un GPS, ces données seront une représentation exacte de la localisation du répondant.
Pour tous les autres répondants, l’emplacement est une approximation déterminée en comparant l’adresse IP du participant à une base de données d’emplacements. Aux États-Unis, ces données offrent généralement une précision à l’échelle de la ville. En dehors des États-Unis, ces données n’offrent généralement qu’un niveau de précision à l’échelle du pays.
Ces données ne seront pas disponibles si les réponses ont été complètement anonymisées.
Astuce Qualtrics : les valeurs de données de latitude et de longitude sont basées sur la ville/le code postal et ne peuvent pas être utilisées pour identifier un lieu ou un individu spécifique.
DistributionCette
colonne décrit la méthode de distribution de l’enquête.
Dans l’exemple ci-dessus, l’enquête a été envoyée par e-mail aux participants.
Astuce Qualtrics : si cette colonne indique « test », il s’agissait d’une réponse test. La mention « Aperçu » fait référence à une réponse complétée par le lien d’aperçu.
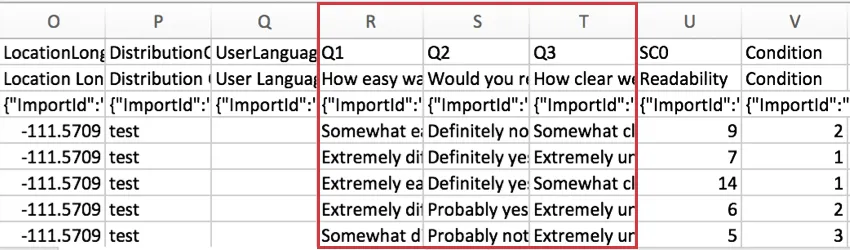
UserLanguageSi
votre enquête comporte plusieurs langues, le code de langue de la personne interrogée sera affiché dans cette colonne.
Astuce Qualtrics : pour en savoir plus sur la définition de la langue d’un participant, consultez la page de support associée.
Astuce Qualtrics : pour configurer la logique d’affichage et personnaliser le contenu en fonction des langues des utilisateurs, essayez Q_Language plutôt que UserLanguage.
Même si une enquête ne comporte qu’une seule langue, chaque réponse doit contenir des données dans la colonne UserLanguage, y compris les aperçus. La seule exception à cela sont les réponses test, qui auront une colonne UserLanguage vide.
Réponses aux questions
Les colonnes suivantes de l’ensemble de données affichent les réponses fournies pour chaque question de l’enquête. Les colonnes sont précédées des numéros de question (par exemple, Q1), puis des premières lignes du texte de la question (par exemple, dans quelle mesure vous a-t-il semblé facile de comprendre l’énoncé de lecture ?).
Les questions simples (saisie de texte, choix multiple – 1 réponse, etc.) seront contenues dans 1 colonne, mais les questions plus complexes avec des énoncés multiples (tableau matriciel, côte à côte, etc.) seront réparties sur plusieurs colonnes.
{kind=link}
Astuce Qualtrics : les différents types de questions stockent les données de différentes façons. Nous vous recommandons donc de générer des échantillons de données et de vérifier le formulaire téléchargé avant de lancer votre enquête. Vous vous assurez ainsi d’obtenir le type de résultats que vous souhaitez.
Par défaut, les données sont téléchargées sous forme d’étiquettes (c’est-à-dire le texte exact des questions et des réponses). Toutefois, vous pouvez également choisir de l’exporter sous forme de valeurs (appelées “Valeurs recodées“) pour chaque choix de réponse. Par exemple, sur une échelle de 5 points, « Tout à fait d’accord » s’afficherait sous la forme d’un « 5 », ce qui faciliterait la recherche d’une moyenne ou la réalisation d’une autre analyse statistique.
Astuce : Pour plus de détails sur l’exportation au format étiquette ou valeur, et sur d’autres options d’exportation susceptibles d’affecter le formatage des données, voir Options d’exportation.
Si le codage numérique de vos choix ne correspond pas à vos attentes, vous pouvez toujours revenir à l’onglet Enquête pour les modifier, puis exporter à nouveau vos données. Vous pouvez aussi exporter votre enquête vers Word pour récupérer un livre de codes décrivant la manière dont chaque choix est codé dans l’ensemble de données.
Guide des types de questions spécifiques
Les données exportées auront souvent un aspect différent en fonction des types de questions que vous avez choisi d’inclure. Ces différences sont expliquées sur la page individuelle de la question. Nous avons fait le lien avec les sections pertinentes ci-dessous.
- Choix multiple (y compris mode d’affichage des exportations à réponses multiples)
- Tableau de matrice
- Saisie du texte
- Champ de formulaire
- Curseur
- Ordre de classement
- Côte à côte
- Somme constante
- Sélectionner, grouper et classifier
- Zone de focalisation
- Carte thermique
- Curseur d’images
- Analyse par tri successif
- Net Promoter® Score
- Surbrillance
- Signature
- Chronomètre
- Méta-informations
- Téléchargement de fichier
Questions sur les blocs Boucle et fusion
Quand vous affichez vos données, chaque boucle est traitée comme un ensemble distinct de questions. Si vous avez 5 boucles possibles, vous verrez les questions en boucle répétées 5 fois dans vos données. Même si un répondant ne voit pas toutes les boucles, toutes les boucles possibles seront représentées dans vos données.
Voir Visualisation de l’ordre des boucles dans vos données.
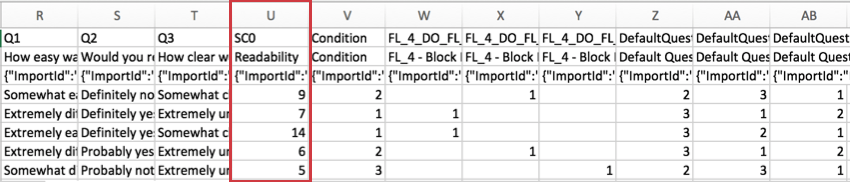
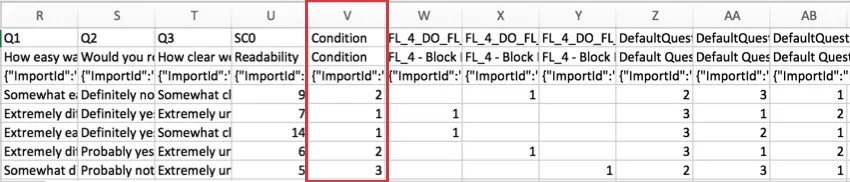
Résultats de notation
Pour les enquêtes utilisant la Notation, la note de chaque catégorie est incluse dans l’ensemble de données. Chaque catégorie de score possède sa propre colonne de données. Dans l’exemple ci-dessous, l’enquête ne comportait qu’une seule catégorie de notation, appelée “Lisibilité”
Ce score est la somme des points gagnés par le répondant dans la catégorie, et non une moyenne.
{kind=link}
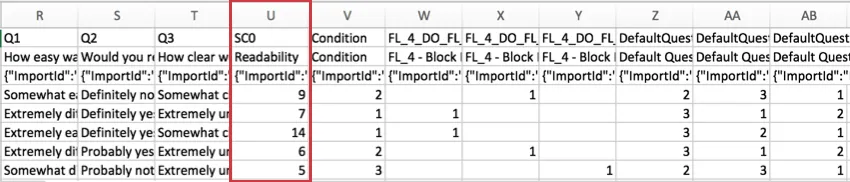
La mention « SC » dans l’en-tête fait référence à la « Catégorie de notation » (SC, de l’anglais Scoring Category) et le nombre représente la catégorie de nombre, en partant de zéro. Comme l’enquête ci-dessus comporte une seule catégorie de notation, nous voyons SC0, mais s’il y en avait plusieurs, nous verrions SC1, SC2, etc.
Astuce Qualtrics : pour les données sur la notation moyenne, minimum, maximum et les autres statistiques, consultez vos Résultats. Il existe généralement un tableau de statistiques pour vos catégories de notation en bas du rapport.
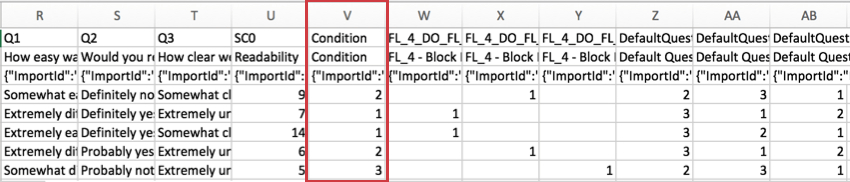
Données intégrées
Pour les enquêtes utilisant des données intégrées, les informations sur les données intégrées sont incluses dans les colonnes qui suivent les informations sur la notation.
{kind=link}
Seuls les champs de données intégrées enregistrés dans le flux d’enquête sont inclus dans l’ensemble de données téléchargé. Les champs de données intégrées avec des valeurs provenant d’une liste de contacts ou d’une URL peuvent être enregistrés dans le flux d’enquête à tout moment avant ou après la collecte des données.
Astuce Qualtrics : en plus de pouvoir créer vos propres données intégrées, Qualtrics propose également une liste de champs prédéfinis parmi lesquels choisir. Voir Champ de Données intégrées pour plus de détails sur le fonctionnement de chacun d’entre eux et le type de données qu’ils produisent.
Astuce Qualtrics : Vous voulez en savoir plus sur la colonne Q_DataPolicyViolations ? Consultez la Politique relative aux données sensibles. Les politiques relatives aux données sensibles ne sont pas activées pour chaque licence. Par conséquent, si cette colonne est vide, ne vous inquiétez pas.
Astuce Qualtrics : pour obtenir de l’aide sur l’interprétation des champs de détection de fraude (détection de bots, soumissions de doublons, etc.), voir Détection de fraude.
Données de randomisation
Astuce Qualtrics : pour obtenir des instructions détaillées sur la manière d’inclure des données de randomisation dans l’exportation de vos données de réponses, voir Exportation de données randomisées.
Les colonnes de randomisation suivront les données de réponse à vos questions. Il y aura une colonne pour chaque élément randomisé dans l’enquête. Par exemple, si vous générez aléatoirement un bloc contenant 5 questions, vous aurez 5 colonnes, 1 pour chaque question. Si vous aviez un générateur de randomisation dans votre flux d’enquête avec 7 éléments sous lui, vous auriez 7 colonnes, 1 pour chaque élément qui a été randomisé.
Si vous randomisez l’ordre de tous les éléments présentés, la colonne indiquera l’ordre dans lequel cet élément a été présenté, par ex. 1, 2, 3, etc.
Exemple : dans la capture d’écran ci-dessous, l’ordre des questions a été randomisé et les colonnes indiquent l’ordre dans lequel chaque question est apparue dans la séquence. Notez que les numéros des questions figurent dans les en-têtes.

{kind=link}
Lorsque vous présentez au hasard un élément parmi plusieurs listes, les éléments qui ont été présentés seront marqués comme 1. Les éléments qui n’ont pas été présentés au répondant seront laissés en blanc.
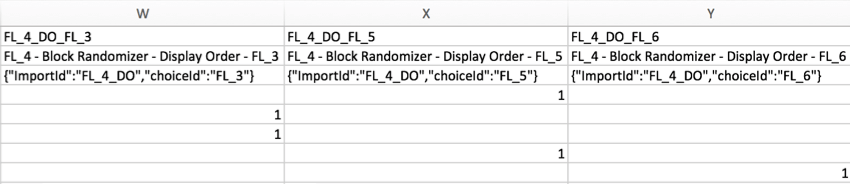
Exemple: dans l’exemple ci-dessous, un élément a été présenté au hasard parmi une liste de trois : Dans l’exemple ci-dessous, un élément a été présenté au hasard parmi une liste de 3. Les colonnes indiquent quel élément a été montré à l’enquêté en plaçant un 1 sous la colonne étiquetée pour l’élément présenté.

{kind=link}
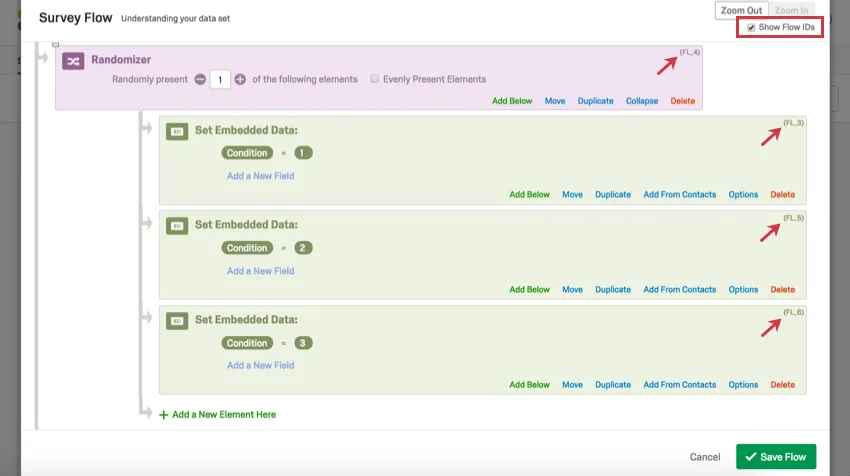
Astuce Qualtrics : vous avez des doutes quant à la façon de lire les en-têtes du deuxième exemple ? Comme le générateur de randomisation du flux d’enquête a été utilisé dans cet exemple, la colonne affiche les ID de flux au lieu des ID de question. Vous pouvez extraire les ID de flux en accédant au flux d’enquête et en sélectionnant Afficher les ID de flux en haut à droite. Les ID de flux ne peuvent pas être modifiés.
{kind=link}
Dépannage d’un fichier de données
Cette section aborde certaines questions courantes et les préoccupations de nombreux utilisateurs concernant leur fichier de données. Nous mettrons également en avant certaines fonctionnalités utiles que vous pouvez utiliser pour personnaliser vos exportations de données.
Guide de l’exportation de données & ; toutes les options disponibles
Pour obtenir des instructions sur la manière d’exporter des données, consultez les pages de support suivantes :
- Exportation des données des réponses : instructions et conseils étape par étape.
- Options d’exportation de données: Guide des options supplémentaires, telles que l’exportation de données randomisées, l’étiquetage des questions vues mais restées sans réponse, l’exportation en format valeur vs. étiquette, etc.
- Formats d’exportation des données : guide des différents types de fichiers que vous pouvez exporter.
Personnalisation des colonnes incluses dans l’exportation
Pour personnaliser les colonnes de vos exportations,
Exportation de données filtrées
Pour exporter des données filtrées,
Fonctionnalités qui n’ont pas de données à inclure dans une exportation
Si vous avez inclus un texte descriptif (tel qu’un paragraphe d’introduction sans question jointe) ou un graphique (tel qu’une image sans question jointe), ces champs n’auront pas leurs propres colonnes dans l’exportation de données, puisqu’ils n’ont pas de réponses à sélectionner par le répondant. Si vous avez remarqué que les numéros de questions étaient « ignorés » dans l’exportation de votre enquête, cela peut être dû au fait que vous avez des champs tels que celui-ci inclus.
Cependant, si vous avez randomisé lorsque des champs de texte descriptif ou d’image sont affichés aux répondants, vous pouvez trouver ces données en exportant les données randomisées. Voir Exportation de données randomisées pour obtenir des instructions étape par étape et voir Données de randomisation pour obtenir un guide sur la lecture des résultats.
Certains choix de réponse sont exclus du fichier/Comment exclure des valeurs de l’analyse
Voir Exclure de l’analyse. Certaines valeurs, en fonction de la façon dont elles sont formulées, sont exclues par défaut. Ces réponses sont enregistrées et peuvent être rajoutées aux données à tout moment sans problème.
Astuce : Si aucune valeur n’est exclue de l’analyse et que vous n’avez pas encore collecté beaucoup de données, il se peut qu’aucune personne interrogée n’ait encore sélectionné cette réponse. S’il s’agit d’une réponse avec une logique d’affichage, assurez-vous de vérifier à nouveau les conditions de la logique.
Données intégrées exclues du fichier
Assurez-vous que la Données intégrée est ajoutée au flux d’enquête et qu’elle est tirée dans tous les champs de contact.
Pour un dépannage plus approfondi concernant les données intégrées, consultez les pages de support liées.
Autres zones exclues du fichier
Assurez-vous que vous avez sélectionnéTélécharger tous les champs lorsque vous exportez vos données. Les données randomisées ne sont pas incluses par défaut, mais peuvent être ajoutées conformément à ces instructions.
Voir les options d’exportation supplémentaires.
Personnaliser les numéros de questions
Voir Numérotation automatique des questions et Numéros de questions.
Personnaliser la formulation de la question ou de la réponse dans l’exportation des données, mais pas dans l’enquête
Vous pouvez utiliser les étiquettes de question pour modifier la formulation des questions elles-mêmes dans l’exportation, sans affecter la façon dont les questions apparaissent aux personnes interrogées dans le cadre de l’enquête. Vous pouvez utiliser les noms de variable pour modifier la formulation des choix de réponse. Vous pouvez modifier les libellés des questions et les noms de variables à tout moment lors de la collecte de l’enquête.
Les étiquettes des questions et les noms des variables ont également une incidence sur la manière dont ces données apparaissent dans les résultats et les rapports.
Exemple : vos questions et réponses sont très longues, et vous souhaitez raccourcir les noms pour un écrémage et un reporting plus faciles.
La formulation des questions/réponses diffère de celle de l’éditeur d’enquête
Si la formulation des questions est différente de ce que vous voyez dans l’éditeur d’enquête, vérifiez qu’aucune étiquette de question n’a été ajoutée. Si la formulation de vos réponses diffère de ce que vous voyez dans l’éditeur d’enquête, vérifiez les noms de vos variables dans les options de recodage. Si vous avez créé votre enquête à partir d’une copie d’une version antérieure, ces paramètres peuvent être conservés. Vous pouvez modifier les libellés des questions et les noms de variables à tout moment lors de la collecte de l’enquête.
Problèmes d’exportation CSV
Si votre exportation CSV ne semble pas correcte – par exemple, si elle contient des symboles au lieu du texte attendu ou si les colonnes se chevauchent – exportez plutôt les données au format TSV. TSV est particulièrement utile pour les données qui contiennent des caractères spéciaux.
Pour un dépannage supplémentaire, voir Problème avec les fichiers CSV téléchargés.
Fichiers de réponse des projets 360, Engagement, Cycle de vie et Recherche ponctuelle sur les employés
Pour 360, voir Comprendre votre ensemble de données de réponses (360).
Pour tous les autres projets EX, voir Comprendre l’ensemble de données de votre réponse (EX).
Différences de format de fichier
Bien que tous les types de fichiers téléchargent les mêmes champs de données décrits ci-dessus, chacun présente une disposition qui peut être légèrement différente.
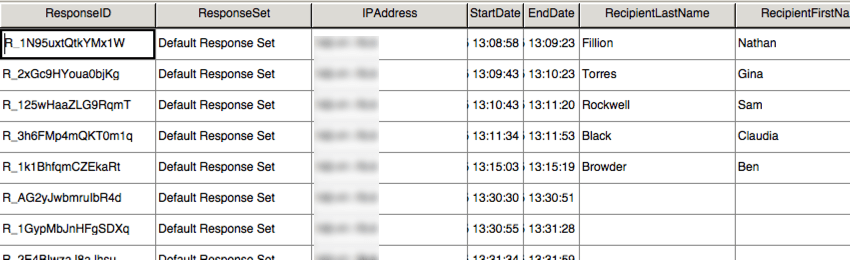
SPSSLa
vue des données dans SPSS comprend exactement la même présentation que le fichier CSV, avec moins d’en-têtes.
{kind=link}
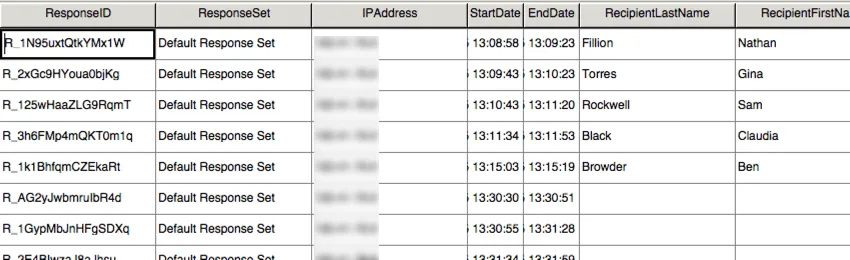
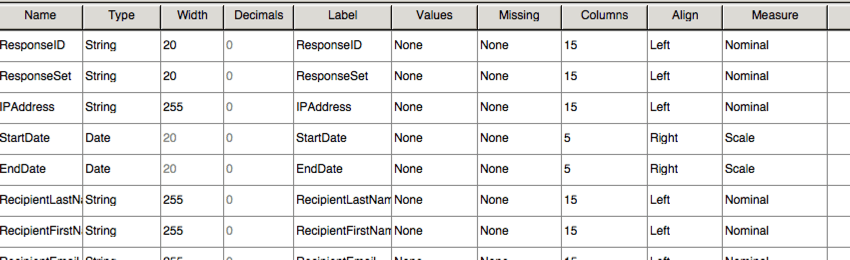
SPSS inclut une autre vue, appelée Vue variable. Cette vue répertorie toutes les variables de votre ensemble de données avec des informations sur chacune d’entre elles, telles que le type de variable et les valeurs possibles.
{kind=link}

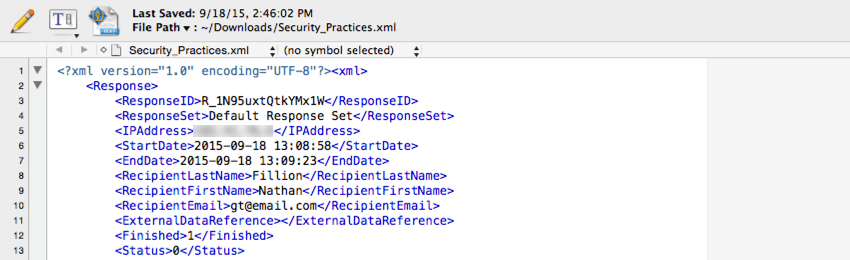
XMLLe
type de fichier XML est souvent utilisé lors de l’intégration des données Qualtrics avec une base de données tierce. Ce type de fichier peut être facilement analysé par un logiciel de base de données courant.
{kind=link}

Un élément XML est fourni pour chaque réponse, avec un élément enfant pour chaque donnée stockée dans cette réponse.
  ;
FAQs
Pourquoi les informations de ma liste de contacts n'apparaissent-elles pas dans les données téléchargées ?
Pourquoi les informations de ma liste de contacts n'apparaissent-elles pas dans les données téléchargées ?
Si vous avez oublié de mettre des données intégrées dans le flux d’enquête, vous pouvez les ajouter à vos données de manière rétroactive, tant qu’il y a des valeurs dans la liste de contacts. See the Embedded Data support page for further instruction.
Notez que si les informations de la liste de contacts que vous essayez de télécharger n’étaient pas incluses dans la liste de contacts au moment où les membres ont participé à l’enquête, l’ajout rétroactif des champs de données intégrées au flux d’enquête n’ajoutera pas ces informations aux données téléchargées ultérieurement.
Quels sont les numéros de mon fichier de données exporté et puis-je les modifier ?
Quels sont les numéros de mon fichier de données exporté et puis-je les modifier ?
Comment puis-je exporter le texte du choix de réponse ou les valeurs recodées que mon répondant a sélectionnées dans l’enquête ?
Comment puis-je exporter le texte du choix de réponse ou les valeurs recodées que mon répondant a sélectionnées dans l’enquête ?
Pourquoi mon fichier de données exporté n'affiche pas toutes mes colonnes de données ?
Pourquoi mon fichier de données exporté n'affiche pas toutes mes colonnes de données ?
Les données peuvent également être exclues de l'exportation si un filtre est appliqué lorsque vous exportez les données.
Si vous manquez des informations stockées dans une liste de contacts, vous devrez vous assurer que vous avez ajouté des données intégrées à votre flux d’enquête afin que votre enquête sache collecter ces informations. Ces données intégrées peuvent être ajoutées rétroactivement si vous avez oublié la première fois. Vous trouverez des instructions à ce sujet sur la page d’assistance Données intégrées.
Si des annotations sont configurées pour un sujet, les données exporteront-elles également ces données ?
Si des annotations sont configurées pour un sujet, les données exporteront-elles également ces données ?
Pourquoi mes champs de contact ont-ils été remplacés par « ****** » ?
Pourquoi mes champs de contact ont-ils été remplacés par « ****** » ?
C'est génial! Merci pour votre avis!
Merci pour votre avis!
Comment puis-je exporter mes données dans un fichier au format CSV ou SPSS ?