-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Guide pratique de la régression logistique
Qu’est-ce que la régression logistique ?
La régression logistique estime une formule mathématique qui relie une ou plusieurs variables d’entrée à une variable de sortie.
Par exemple, disons que vous tenez un stand de limonade et que vous souhaitez savoir quels types de clients ont tendance à revenir. Vos données comprennent une entrée pour chaque client, son premier achat et s’il est revenu le mois suivant pour acheter d’autres limonades. Vos données pourraient ressembler à ceci :
| Retour | Âge du client | Le sexe | Temp. au premier achat | Couleur limonade | Longueur du pantalon |
|---|---|---|---|---|---|
| Ne l’a pas fait | 21 | Un homme | 24 | Rose | Short |
| Renvoyé | 34 | Une femme | 20 | Jaune | Short |
| Renvoyé | 13 | Une femme | 25 | Rose | Pantalon |
| Ne l’a pas fait | 25 | Une femme | 27 | Jaune | Robe |
| etc. | etc. | etc. | etc. | etc. | etc. |
  ;
Vous pensez que “l’âge du client” (une variable d’entréeou explicative) pourrait avoir un impact sur “la Réponse” (une variable de sortieou réponse). Une régression logistique pourrait donner le résultat suivant
: à l’âge de 12 ans (l’âge le plus bas), la probabilité d’être “retourné” est de 10 %.
Pour chaque année supplémentaire d’âge, il y a 1,1 fois plus de “retour”
Cette connaissance est utile pour deux raisons.
Tout d’abord, elle vous permet de comprendre un lien : les clients plus âgés sont plus susceptibles de revenir. Cette information peut vous inciter à orienter votre publicité vers les clients plus âgés, qui seront plus susceptibles de devenir des clients réguliers.
Deuxièmement, et dans le même ordre d’idées, elle peut également vous aider à faire des prédictions spécifiques. Si un client de 24 ans passe par là, on peut estimer que s’il achète de la limonade, il y a 26 % de chances qu’il revienne plus tard.
Comprendre la multiplication des probabilités
Notez que si nous disons que “retourné” est “1,5 fois plus probable” dans une situation donnée que dans une autre, nous faisons ce qui suit
:Les chances sont de 1:9, également écrites 1/(1+9) = 10 %.
La “cote pour” (le 1) est multipliée par 1,5.
Maintenant 1,5:9, également écrit 1,5/(1,5+9) = 14%.
Autre exemple, cette fois-ci pour passer d’une probabilité de 50 % à une probabilité trois fois plus élevée
: Les chances étaient de 1:1, également écrites 1/(1+1) = 50 %.
La “cote pour” (le 1 de la côte à côte) est multipliée par 3.
Maintenant 3:1, également écrit 3/(3+1) = 75%.
Nous allons maintenant passer en revue le processus de création de ce modèle de régression.
Préparation à la création d’un modèle de régression
1. Réfléchissez à la théorie de votre régression.
Une fois que vous avez choisi une variable de réponse, “Réponses“, émettez des hypothèses sur la façon dont les différentes informations peuvent être liées à cette variable. Par exemple, vous pouvez penser qu’une “température au premier achat” plus élevée entraînera une plus grande probabilité de “retour”, vous n’êtes peut-être pas sûr de l’influence de l'”âge” sur le “retour“, et vous pouvez penser que le “pantalon”(par opposition au short) est affecté par la “température” mais n’a pas d’impact sur votre stand de limonade.
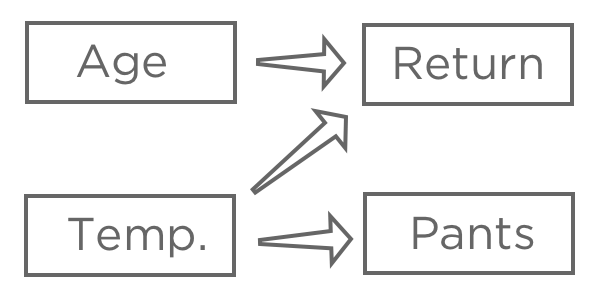
L’objectif de la régression est généralement de comprendre le lien entre plusieurs entrées et une sortie. Dans ce cas, vous déciderez probablement de créer un modèle expliquant le “rendement” avec la “température”et l'”âge”(également appelé “prédire le rendement à partir de la température et de l’âge” ,même si vous êtes plus intéressé par l’explication que par la prédiction proprement dite).
Vous n’incluriez probablement pas “Pantalon” dans votre régression. La technologie peut être corrélée avec le “retour” parce que les deux sont liés à la “température”, mais elle ne précède pas le “retour” dans la chaîne de causalité, de sorte que l’inclure rendrait votre modèle confus.
2. “Décrivez toutes les variables qui pourraient être utiles à votre modèle.
Commencez par décrire la variable de réponse, en l’occurrence les “Réponses”, et par vous familiariser avec elle. Faites de même pour vos variables explicatives.
Note qui a une forme comme celle-ci..
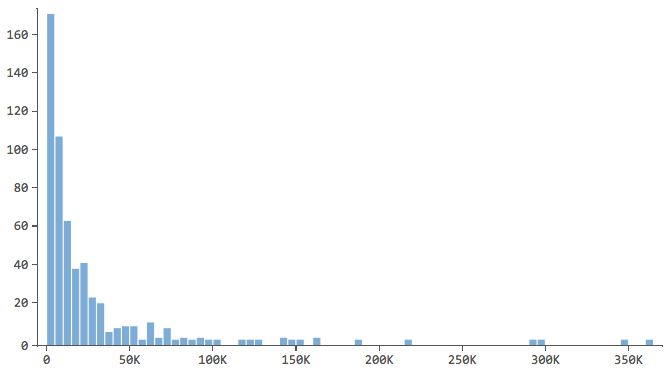
…où la plupart des données se trouvent dans les premières cases de l’histogramme. Ces variables devront faire l’objet d’une attention particulière ultérieurement.
3. “Mettre en relation” toutes les variables explicatives possibles avec la variable réponse.
Stats iQ classera les résultats en fonction de la force du lien statistique. Jetez un coup d’œil et ayez une apparence des résultats, en notant quelles variables sont liées aux “recettes” et comment.
4. Commencer à construire la régression.
La construction d’un modèle de régression est un processus itératif. Vous passerez par les trois étapes suivantes autant de fois que nécessaire.
Les trois étapes de la construction d’un modèle de régression
  ;
Étape 1 : Ajouter ou soustraire une variable.
Commencez à ajouter, une à une, les variables dont vos analyses précédentes ont montré qu’elles étaient liées au “revenu”(ou ajoutez les variables que vous avez une raison théorique d’ajouter). Il n’est pas strictement nécessaire de procéder une à une, mais cela facilite l’identification et la résolution des problèmes au fur et à mesure et vous aide à vous familiariser avec le modèle.
Supposons que vous commenciez par prédire les “recettes” à l’aide de la “température” Vous trouvez un lien solide, vous évaluez le modèle et vous le jugez satisfaisant (plus de détails dans une minute).
Vous
ajoutez ensuite la “couleur de la limonade” et votre modèle de régression comporte désormais deux termes, qui sont tous deux des variables prédictives statistiquement significatives. Par exemple
: Revenu <- Température & ; Couleur de la limonadePuis
vous ajoutez “Sexe”, et les résultats du modèle montrent maintenant que “Sexe” est statistiquement significatif dans le modèle, mais que “Couleur de la limonade” ne l’est plus. En règle générale, vous devez supprimer la “couleur limonade” du modèle.
En
d’autres termes, si vous connaissez le sexe du client, le fait de savoir quelle couleur de limonade il a commandée ne vous donne pas plus d’informations sur le fait qu’il reviendra ou non.
Vous pourriez enquêter et découvrir que les femmes ont tendance à cueillir la limonade jaune plus que les hommes et que les femmes sont plus susceptibles de revenir. Ainsi, il semblait initialement que le fait de choisir le jaune augmentait la probabilité qu’un client revienne, mais en fait, la “couleur limonade” n’est liée au “retour” que par l’intermédiaire du “sexe” Ainsi, lorsque vous incluez le “sexe” dans la régression, la “couleur de la limonade” disparaît de la régression.
L’interprétation des résultats d’une régression nécessite une bonne dose de jugement, et le fait qu’une variable soit statistiquement significative ne signifie pas qu’elle soit réellement causale. Mais en ajoutant et en soustrayant soigneusement des variables, en notant comment le modèle change et en pensant toujours à la théorie qui sous-tend votre modèle, vous pouvez dégager des liens intéressants dans vos données.
Étape 2 : Évaluation du modèle.
Chaque fois que vous ajoutez ou soustrayez une variable, vous devez évaluer la précision du modèle en examinant son r-carré (R2), son AICc et les éventuelles alertes de Stats iQ. Chaque fois que vous changez de modèle, comparez le nouveau r-carré, l’AICc et les graphiques de diagnostic aux anciens pour déterminer si le modèle s’est amélioré ou non.
R au carré (R2)
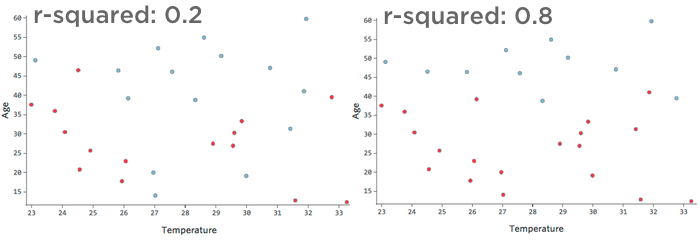
La mesure numérique permettant de quantifier la précision de la prédiction du modèle est connue sous le nom de r-carré, qui se situe entre zéro et un. Un zéro signifie que le modèle n’a aucune valeur prédictive, et un un signifie que le modèle prédit parfaitement tout.
Par exemple, les données représentées à gauche conduiront à un modèle beaucoup moins précis que les données représentées à droite. Imaginez que vous essayiez de tracer une ligne à travers le nuage de points ; vous pourriez presque complètement séparer le bleu (“retourné”) du rouge (“pas retourné”) sur la côte droite, mais il serait difficile de le faire sur la côte gauche.
En d’autres termes, la côte à côte a un r-carré élevé ; si vous connaissez la “température” et l'”âge”, vous pouvez déterminer “retourné” contre “retourné”. “N’a pas” assez facilement. La partie gauche a un r-carré faible à moyen ; si vous connaissez la “température” et l'”âge”,vous pouvez assez bien deviner si l’objet sera “retourné” ou “retourné”. “Non, mais il y aura beaucoup d’erreurs.
Il n’existe pas de définition fixe d’un “bon” r-carré. Dans certaines situations, il peut être intéressant d’observer un quelconque effet, tandis que dans d’autres, votre modèle peut s’avérer inutile s’il n’est pas extrêmement précis.
Chaque fois que vous ajoutez une variable, le r-carré augmente. L’objectif n’est donc pas d’obtenir le r-carré le plus élevé possible, mais plutôt d’équilibrer la précision du modèle (r-carré) et sa complexité (en général, le nombre de variables).
AICc
L’AICc est une mesure qui met en balance la précision et la complexité – une plus grande précision conduit à de meilleures notations et une complexité accrue (plus de variables) conduit à de moins bonnes notations. Le modèle avec l’AICc le plus bas est le meilleur.
Notez que la métrique AICc n’est utile que pour comparer les AICc de modèles qui ont le même nombre de lignes de donnéesetla même variable de sortie.
Alertes
De temps à autre, Stats iQ vous proposera des moyens d’améliorer votre modèle. Par exemple, Stats iQ peut vous suggérer de prendre le logarithme d’une variable(détails sur ce que cela signifie).
Matrice de confusion et courbe de rappel de précision
La matrice de confusion et la courbe de précision-rappel sont également des outils utiles pour comprendre le degré de précision de votre modèle. Et si vous souhaitez faire des prédictions sur la base de votre modèle, ces outils vous y aideront. Elles ne sont pas strictement nécessaires pour bien comprendre ce que vous dit votre modèle, c’est pourquoi nous les avons placées dans une section différente consacrée à la matrice de confusion et à la courbe de précision-rappel
Étape 3 : Modifier le modèle en conséquence.
Si votre évaluation du modèle est satisfaisante, vous avez terminé ou vous pouvez revenir à l’étape 1 et entrer d’autres variables.
Si votre évaluation révèle des lacunes dans le modèle, vous utiliserez les alertes de Stats iQ pour résoudre les problèmes.
Au fur et à mesure que vous modifiez le modèle, notez continuellement l’évolution du r-carré, de l’AICR et des diagnostics résiduels, et décidez si les changements que vous apportez aident ou nuisent à votre modèle.