Guide convivial de la régression linéaire
Contenus de cette page
Qu’est-ce que la régression ?
La
régression estime une formule mathématique qui relie une ou plusieurs variables d’entrée à une variable de sortie.
Par exemple, disons que vous tenez un stand de limonade et que vous vous intéressez à ce qui génère des revenus. Vos données comprennent les “recettes” de chaque jour, la “température” élevée, le “nombre d’enfants qui passent”, le “nombre d’adultes qui passent”, la “signalisation” que vous avez utilisée ce jour-là et les “recettes des concurrents” à proximité
| Chiffre d’affaires | Température (Celsius) | Minutes de pause | Nombre d’enfants qui se sont promenés | Nombre d’adultes qui sont passés par là | Signalisation | Recettes des concurrents |
|---|---|---|---|---|---|---|
| 44 USD | 28,2 | 30 | 43 | 380 | Peint à la main | $20 |
| 23 USD | 21,4 | 42 | 28 | 207 | LED | 30 USD |
| 43 USD | 32,9 | 14 | 43 | 364 | Peint à la main | $34 |
| 30 USD | 24,0 | 24 | 18 | 103 | LED | $15 |
| etc. | etc. | etc. | etc. | etc. | etc. | etc. |
  ;
Vous pensez que la “Température” (une variable d’entréeou explicative) pourrait avoir un impact sur le “Revenu” (une variable de sortieou réponse). Lorsque vous utilisez la régression pour analyser ce lien, vous pouvez obtenir la formule suivante
: Lien = 2,71 * Température – 35Cette
formule est utile pour deux raisons.
Tout d’abord, elle permet de comprendre un lien : des journées plus chaudes entraînent plus de “recettes” En particulier, les 2,71 avant “Température” (appelés coefficient) signifient que pour chaque degré d’augmentation de la “Température”, il y aura en moyenne 2,71 dollars de plus de “Recettes” Cette idée peut vous amener à décider de ne pas vendre de limonade par temps froid.
Deuxièmement, et dans le même ordre d’idées, elle peut également vous aider à faire des prédictions spécifiques. Si la “température” est de 24, on peut estimer que puisque…
Revenu = 2,71 * Température – 35
Revenu = 2,71 * 24 – 35
Revenu = 30
… on aura environ 30 $ de “revenu” Cette information peut être utile pour savoir si vous serez en mesure d’effectuer un paiement ce jour-là, à condition que vous soyez sûr de l’exactitude de votre modèle.
Nous allons maintenant passer en revue le processus de création de cette équation de régression.
Préparation à la création d’un modèle de régression
1. Réfléchissez à la théorie de votre régression
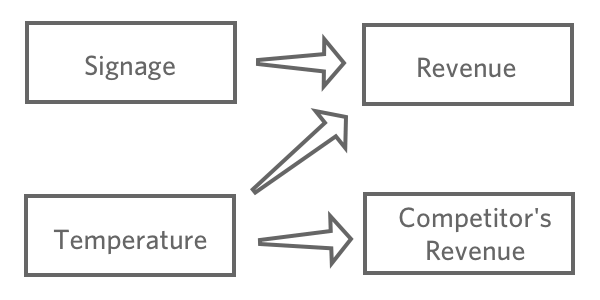
Une fois que vous avez choisi une variable de réponse, “Réponses“, émettez des hypothèses sur la façon dont les différentes informations peuvent être liées à cette variable. Par exemple, vous pouvez penser qu’une “température” plus élevée entraînera un “chiffre d’affaires” plus important, vous n’êtes peut-être pas sûr de la manière dont les différents panneaux de signalisation affecteront le “chiffre d’affaires“, et vous pouvez penser que les “ventes des concurrents” sont affectées par la “température” mais n’ont aucun impact sur votre stand de limonade.
{kind=link}
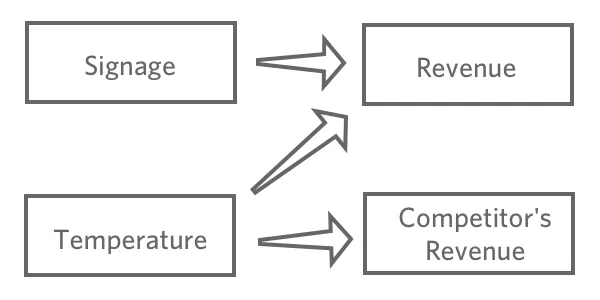
L’objectif de la régression est généralement de comprendre le lien entre plusieurs entrées et une sortie. Dans ce cas, vous déciderez probablement de créer un modèle expliquant le “Revenu” avec la “Température”et la “Signalisation”(également appelé “prédire le Revenu à partir de la Température et de la Signalisation“, même si vous êtes plus intéressé par l’explication que par la prédiction proprement dite).
Vous n’incluriez probablement pas les “ventes des concurrents” dans votre régression. La Technologie de l’information est probablement en corrélation avec le “Revenu”, mais elle ne le précède pas dans la chaîne de causalité, de sorte que son inclusion perturberait votre modèle.
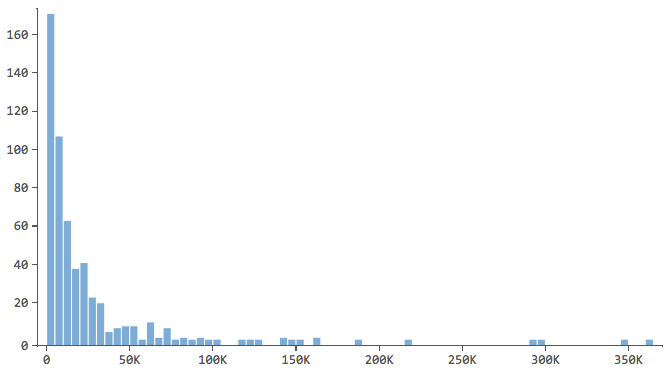
2. “Décrivez toutes les variables qui pourraient être utiles à votre modèle
Commencez par décrire la variable de réponse, en l’occurrence les “Réponses”, et par vous familiariser avec elle. Faites de même pour vos variables explicatives.
Note qui ont une forme comme celle-ci..
{kind=link}
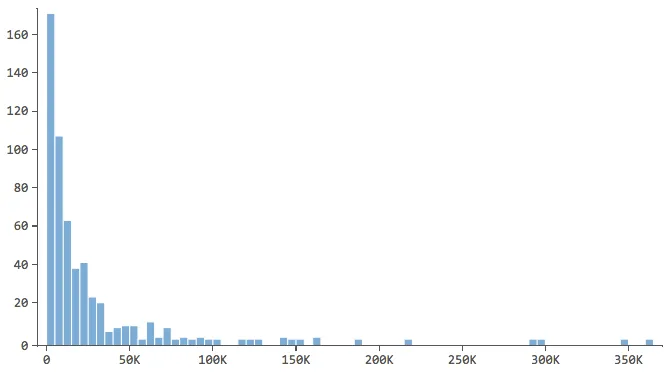
…où la plupart des données se trouvent dans les premières cases de l’histogramme. Ces variables devront faire l’objet d’une attention particulière ultérieurement.
3. “Mettre en relation” toutes les variables explicatives possibles avec la variable réponse
Stats iQ classera les résultats en fonction de la force du lien statistique. Jetez un coup d’œil et ayez une apparence des résultats, en notant quelles variables sont liées aux “recettes” et comment.
Si vous avez déjà une bonne idée des variables qui devraient théoriquement déterminer la sortie (par exemple, à partir de documents universitaires antérieurs), vous pouvez sauter cette étape. Mais si votre analyse est de nature un peu plus exploratoire (comme une enquête auprès des clients), il s’agit d’une étape utile et importante.
4. Commencer à construire la régression
La construction d’un modèle de régression est un processus itératif. Vous passerez par les trois étapes suivantes autant de fois que nécessaire.
Les trois étapes de la construction d’un modèle de régression
Étape 1 : Ajouter ou soustraire une variable
Commencez à ajouter, une à une, les variables dont vos analyses précédentes ont montré qu’elles étaient liées aux “recettes” (ou ajoutez les variables que vous avez une raison théorique d’ajouter). Il n’est pas strictement nécessaire de procéder une à une, mais cela facilite l’identification et la résolution des problèmes au fur et à mesure et vous aide à vous familiariser avec le modèle.
Supposons que vous commenciez par prédire les “recettes” à l’aide de la “température” Vous trouvez un lien solide, vous évaluez le modèle et vous le jugez satisfaisant (plus de détails dans une minute).
Revenu = 2,71 * Température – 35Vous
ajoutez ensuite le “Nombre d’enfants qui sont passés” et votre modèle de régression comporte désormais deux termes, qui sont tous deux des variables prédictives statistiquement significatives. Par exemple
:Revenu = 2,5 * Température +
0
,3 * Nombre d’enfants qui sont passés – 12Puis
vous ajoutez “Nombre d’adultes qui sont passés”, et les résultats du modèle montrent maintenant que le “Nombre d’adultes” est statistiquement significatif dans le modèle, mais que le “Nombre d’enfants” ne l’est plus. En règle générale, vous supprimez le “nombre d’enfants” du modèle. Aujourd’hui, c’est le cas :
Recettes = 2,6 * Température + 0,4 * Nombre d’adultes ayantmarché – 14
Cela signifie que le “nombre d’adultes” est le meilleur indicateur du “chiffre d’affaires” ; en d’autres termes, si vous savez combien d’adultes passent, savoir combien d’enfants passent n’apporte aucune nouvelle information – cela ne vous aide pas à prévoir les ventes.
Peut-être vous souvenez-vous que les enfants n’achètent jamais votre limonade, et qu’il est donc logique que cette variable n’ait pas sa place dans le modèle.
Mais pourquoi la technologie de l’information était-elle statistiquement significative dans le premier modèle ? Probablement parce que le “Nombre d’enfants” est corrélé avec le “Nombre d’adultes” , et comme le “Nombre d’adultes” n’était pas encore dans le modèle, le “Nombre d’enfants”agissait comme une approximation du “Nombre d’adultes”
L’interprétation des résultats d’une régression nécessite une bonne dose de jugement, et le fait qu’une variable soit statistiquement significative ne signifie pas qu’elle soit réellement causale. Mais en ajoutant et en soustrayant soigneusement des variables, en notant comment le modèle change et en pensant toujours à la théorie qui sous-tend votre modèle, vous pouvez dégager des liens intéressants dans vos données.
Étape 2 : Évaluation du modèle
Chaque fois que vous ajoutez ou soustrayez une variable, vous devez évaluer la précision du modèle en examinant son r-carré (R2), son AICR et ses graphiques résiduels. Chaque fois que vous modifiez le modèle, comparez les nouveaux graphiques r-carré, AICR et résiduel aux anciens pour déterminer si le modèle s’est amélioré ou non.
R au carré (R2)
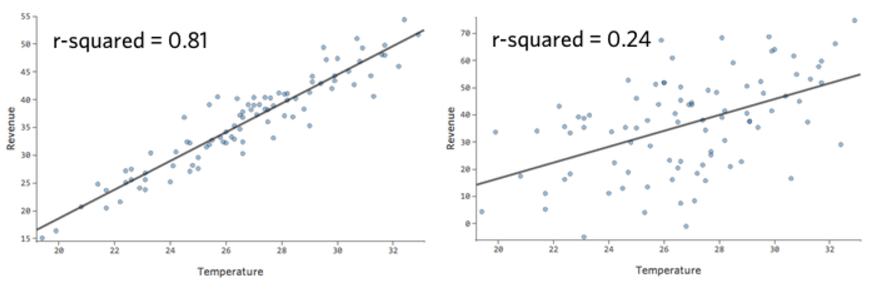
La mesure numérique permettant de quantifier la précision de la prédiction du modèle est connue sous le nom de r-carré, qui se situe entre zéro et un. Un zéro signifie que le modèle n’a aucune valeur prédictive, et un un signifie que le modèle prédit parfaitement tout.
Par exemple, le modèle de gauche est plus précis que celui de droite ; en d’autres termes, si vous connaissez la “température”, vous avez une assez bonne idée de ce que sera la “recette”à gauche, mais pas vraiment à droite.
{kind=link}
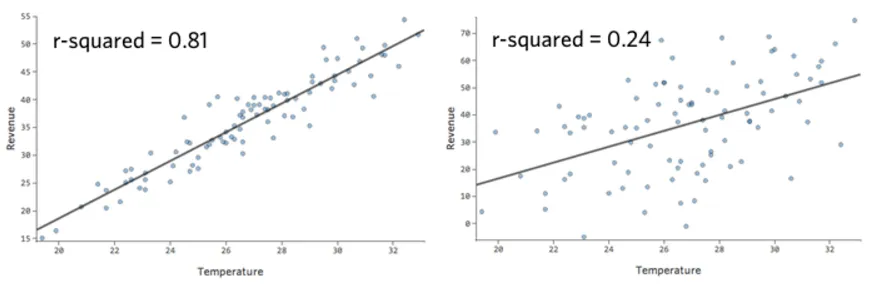
Il n’existe pas de définition fixe d’un “bon” r-carré. Dans certaines situations, il peut être intéressant d’observer un quelconque effet, tandis que dans d’autres, votre modèle peut s’avérer inutile s’il n’est pas extrêmement précis.
Chaque fois que vous ajoutez une variable, le r-carré augmente. L’objectif n’est donc pas d’obtenir le r-carré le plus élevé possible, mais plutôt d’équilibrer la précision du modèle (r-carré) et sa complexité (en général, le nombre de variables).
AICR
L’AICR est une mesure qui équilibre la précision et la complexité – une plus grande précision conduit à de meilleures notations, une plus grande complexité (plus de variables) conduit à de moins bonnes notations. Le modèle dont l’AICR est le plus faible est le meilleur.
Notez que la métrique AICR n’est utile que pour comparer les AICR de modèles qui ont le même nombre de lignes de donnéesetla même variable de sortie.
Intervalles de prédiction
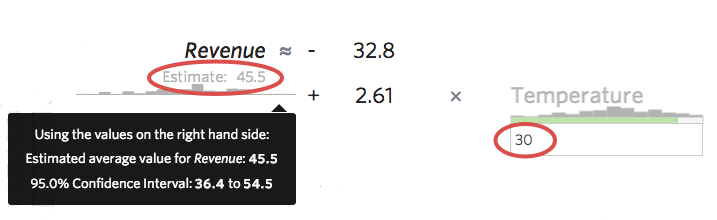
Un autre moyen utile de se faire une idée de la précision de votre modèle est d’introduire des échantillons dans votre formule et de voir l’intervalle de prédiction calculé par Stats iQ. Par exemple, si vous introduisez le chiffre 30 dans la formule, Stats iQ vous dira que la valeur prédite est de 45,5, mais que l’intervalle de confiance à 95 % est compris entre 36,4 et 54,5, ce qui signifie que vous pouvez être sûr à 95 % que si demain il fait 30 degrés, vous obtiendrez un “revenu” compris entre 36,40 et 54,50 dollars On peut imaginer un modèle plus précis lorsque l’intervalle de prédiction est une bande étroite, comme 44 à 48 dollars, ou un modèle moins précis lorsque l’intervalle est large, comme 20 à 72 dollars.
{kind=link}

Cette approche n’est utile que si vos graphes résiduels semblent sains (voir ci-dessous), sinon ils seront inexacts.
Résidus
Les résidus sont le principal outil de diagnostic pour évaluer et améliorer la régression, c’est pourquoi une section entière est consacrée à l’interprétation des résidus en vue d’améliorer votre modèle. Vous apprendrez ou vous rafraîchirez la mémoire sur ce que sont les résidus, comment les utiliser pour évaluer et améliorer le modèle, et comment réfléchir à la précision dont vous avez besoin pour votre modèle.
Nous vous recommandons de la lire dans son intégralité, car elle couvre tout ce dont vous avez besoin pour produire un modèle de qualité. Mais vous pouvez toujours y revenir, bien sûr.
Étape 3 : Modifier le modèle en conséquence
Si votre évaluation du modèle est satisfaisante, vous avez terminé ou vous pouvez revenir à l’étape 1 et entrer d’autres variables.
Si votre évaluation révèle des lacunes, vous utiliserez les alertes de Stats iQ et la section de diagnostic résiduel pour résoudre les problèmes.
Au fur et à mesure que vous modifiez le modèle, notez continuellement l’évolution du r-carré, de l’AICR et des diagnostics résiduels, et décidez si les changements que vous apportez aident ou nuisent à votre modèle.
FAQs
Quelles sont les options d'analyse de mes données dans Stats iQ ?
Quelles sont les options d'analyse de mes données dans Stats iQ ?
- Décrire : en sélectionnant une variable dans la liste, puis en cliquant sur Décrire, vous obtiendrez une visualisation des données contenues dans cette variable. Utilisez cette option lorsque vous souhaitez voir comment les données d'une variable donnée sont distribuées.
- Relier : la sélection de deux variables, puis le fait de cliquer sur Relier entraînent l'exécution d'une analyse statistique de la relation entre les deux variables. Utilisez cette méthode lorsque vous souhaitez savoir à quel point deux variables sont fortement corrélées.
- Tableau croisé dynamique : la sélection de deux variables ou plus et le fait de cliquer sur Tableau croisé dynamique créent un tableau qui affiche les valeurs des variables sous forme de lignes et de colonnes. Les cellules peuvent être définies pour afficher une variété d'informations différentes, notamment le pourcentage de colonne et de ligne, le total et l'écart. Utilisez cette catégorie lorsque vous souhaitez comparer le chevauchement entre des valeurs spécifiques d'un ensemble de variables.
- Régression : en sélectionnant deux variables et en cliquant sur Régression, vous obtiendrez la relation mathématique entre les variables. Utilisez cette catégorie lorsque vous souhaitez prédire des valeurs pour une variable en fonction des valeurs d'une autre variable.
- Cluster : la sélection de deux à dix variables démographiques et le fait de cliquer sur Cluster afficheront les groupes de caractéristiques les plus susceptibles de se produire ensemble, révélant ainsi les segments de population capturés dans vos données.
Je ne sais pas ce que signifie ce terme statistique. Pouvez-vous me le dire ?
Je ne sais pas ce que signifie ce terme statistique. Pouvez-vous me le dire ?
- Essais statistiques : L'ANOVA, le test T et le Chi-carré sont tous des tests statistiques que Stats iQ effectue pour tester si la relation entre deux variables est significative ou non. Ces tests sont utilisés pour générer une Valeur P.
- Valeur P : Cette valeur représente la probabilité que les résultats observés soient vus si aucune corrélation n'existe entre les variables. Une P-Value inférieure signifie plus de données corrélées.
- Taille de l'effet : la taille de l'effet est une mesure de l'importance de la corrélation entre deux variables. Il est mesuré de différentes manières en fonction du type de test statistique effectué. Par exemple, Cohen's d, Pearson's r et Cramer's v. Plus la valeur de la taille de l'effet est grande, plus les variables sont corrélées.
Comment puis-je filtrer les données qui apparaissent dans Stats iQ ?
Comment puis-je filtrer les données qui apparaissent dans Stats iQ ?
Comment puis-je obtenir mes nouvelles réponses pour les afficher dans Stats iQ ?
Comment puis-je obtenir mes nouvelles réponses pour les afficher dans Stats iQ ?
Comment les cartes d'analyse sont-elles classées dans mon espace de travail Stats iQ ?
Comment les cartes d'analyse sont-elles classées dans mon espace de travail Stats iQ ?
Qu'est-ce que Stats iQ ? / Où se trouve Statwing ?
Qu'est-ce que Stats iQ ? / Où se trouve Statwing ?
Que faire si mes données ne se chargent pas correctement ?
Que faire si mes données ne se chargent pas correctement ?
C'est génial! Merci pour votre avis!
Merci pour votre avis!
Comment créer une variable Stats iQ ?