-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Analyse de cluster
À propos de l’analyse Cluster
Lorsque nous analysons nos données, nous nous intéressons souvent à différents groupes démographiques et nous segmentons les répondants en fonction du revenu, de la région, de l’âge, etc. Mais ces étiquettes sont parfois réductrices – après tout, le fait de savoir que vous avez beaucoup de répondants masculins ne vous indique pas le type de campagne publicitaire qu’ils aimeraient voir. Votre public est-il principalement composé de jeunes du millénaire ? Les pères footballeurs ? Les deux ? Comment traduire les caractéristiques personnelles en termes qui peuvent être décomposés à des fins de marketing ?
L’analyse Cluster est un moyen de détecter les groupes qui se trouvent naturellement dans l’ensemble des données de votre enquête. Pour ce faire, il convient d’analyser les qualités démographiques, comportementales et/ou basées sur les croyances qui sont les plus fortement corrélées.
Préparation d’une enquête en vue d’une analyse Cluster
Pour effectuer une analyse Cluster, vous devez collecter les données correctes dans votre enquête.
- Poser les bonnes questions :
- Données démographiques : Demandez des informations descriptives de base, telles que l’âge, la tranche de revenus, la race ou le sexe.
- Comportement : Demandez comment les clients interagissent avec votre organisation et vos produits, ou quels sont les comportements qui peuvent être liés à leur comportement d’achat. Par exemple, vous pouvez demander à quel rythme le client fait ses courses.
- Donnéesopérationnelles : Il s’agit d’informations telles que le temps passé sur votre site web ou l’ancienneté d’un employé dans votre entreprise.
Astuce : Vous souhaitez chronométrer le temps passé sur une page ? Dans ce cas, vous pourriez être intéressé par notre fonction de retour d’information sur le site web. Contactez votre Commercial si vous souhaitez en savoir plus.
- Attitudes et convictions : Enquêtez vos répondants sur leurs valeurs fondamentales, leurs attitudes et leurs croyances. Il peut s’agir de convictions religieuses ou politiques, mais vous pouvez également poser des questions sur les convictions directement liées au fonctionnement de votre entreprise. Par exemple, vous pouvez leur demander d’évaluer l’importance des interactions en face-à-face avec les services d’assistance.
- Formats des questions : Formulez les questions sur les comportements et les croyances sous forme d’échelles. L’étendue d’une échelle peut nous aider à comprendre quels points de l’échelle sont corrélés et donc à peu près dans le même cluster ; les questions de type Oui/Non et à choix unique ne sont pas aussi utiles pour l’analyse des clusters.
Exemple : Si vous posez la question “Quel type d’acheteur êtes-vous ?” et que vous donnez les options “Préfère faire du shopping dans les centres commerciaux”, “Préfère faire du shopping en ligne” et “Préfère faire du shopping dans les boutiques”, l’algorithme de clustering voudra séparer les personnes interrogées en trois groupes, un pour chaque réponse. Si vous posez plutôt une série de questions (par exemple, “Aimez-vous faire du shopping dans les centres commerciaux ?”) avec des réponses de 1 à 7, l’algorithme de clustering sera plus à même de discerner réellement ce qui distingue les différents acheteurs les uns des autres.Astuce : Les questions à choix multiple sont les plus adaptées pour recueillir des données scalaires.
- Types de variables: Lorsque vous êtes prêt à effectuer une analyse dans Stats iq, veillez à formater vos variables sous forme de catégories ou de nombres. Les dates sont incompatibles avec l’analyse en cluster.
Réalisation d’une analyse Cluster
- Assurez-vous que les types de variables de vos questions sont définis comme étant des nombres ou des catégories.
- Sélectionnez les variables que vous souhaitez analyser sur la gauche.
- Cliquez sur Cluster.
Résultats de l’analyse Cluster
Tableau de résistance et de statique
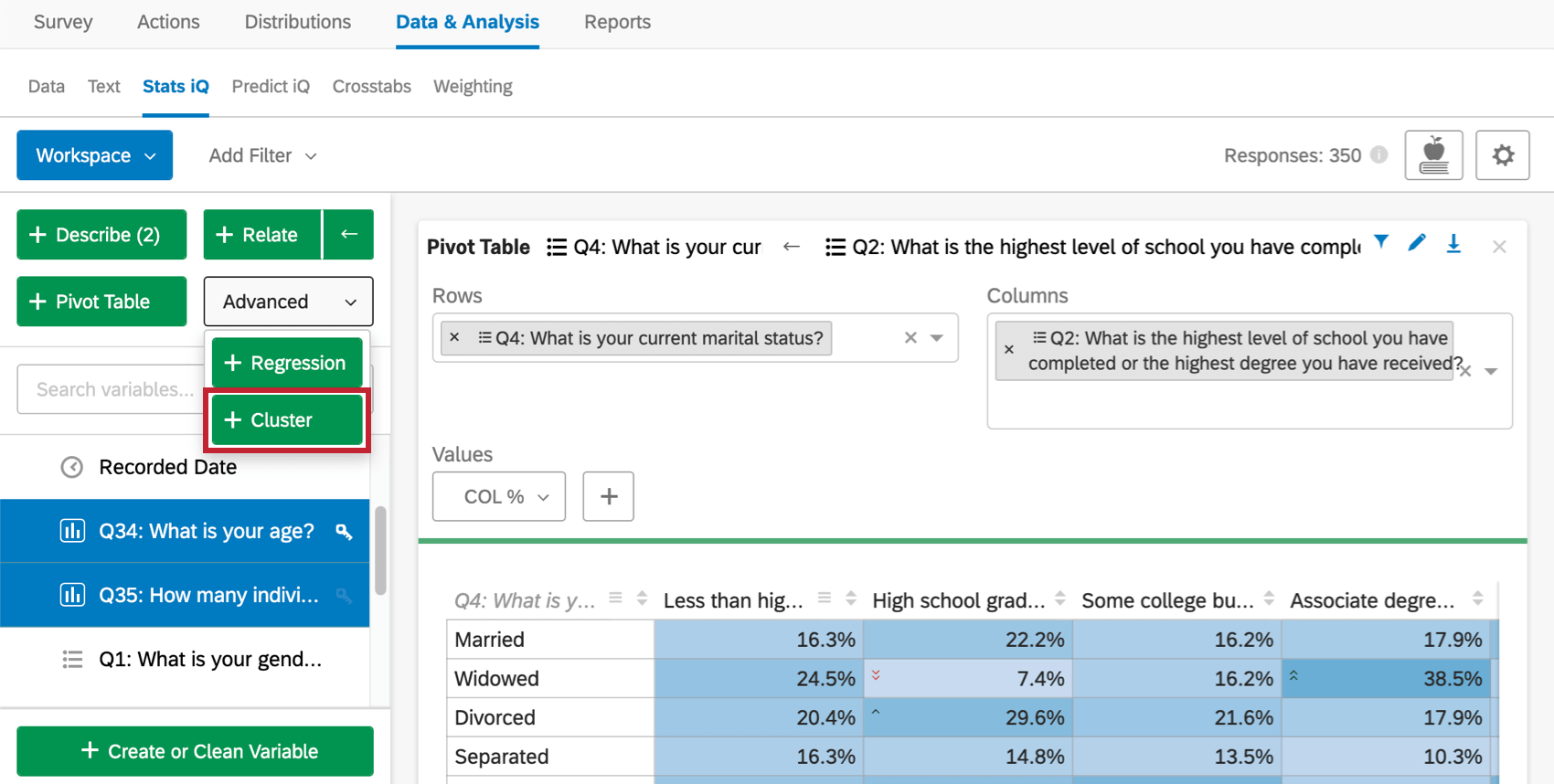
Le tableau indique la taille de l’échantillon (combien de répondants ont fourni des données pour cette analyse), le nombre de clusters et la notation de la silhouette. La notation de la silhouette est interprétée par des phrases comme “très fortement” dans la phrase du haut.
L’analyse de clusters tente de choisir automatiquement le nombre approprié de clusters en évaluant l’étroitesse du regroupement pour différents nombres, mais en pénalisant les nombres plus élevés de clusters parce qu’ils sont plus difficiles à traiter. Le choix du bon chiffre relève plus de l’art que de la science, et vous devriez expérimenter différents chiffres pour voir ce qui fonctionne le mieux.
Dans certains cas, l’algorithme ne pourra pas produire un certain nombre de clusters et se rabattra sur un nombre plus petit.
Résumé du cluster
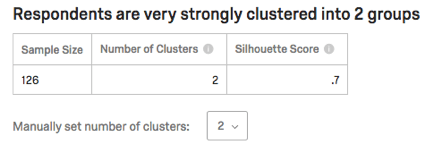
Vos clusters seront listés dans la section Résumé du cluster. Ils seront décrits en fonction des questions auxquelles les membres du cluster ont répondu de la manière la plus similaire.

Exemple : Le Cluster 1 de cette capture d’écran contient des personnes qui sont :
- Marié.e
- Être titulaire d’un master
- Peu de personnes (membres de la famille immédiate, enfants) vivent dans leur foyer
- Jeunes
Cliquez sur le nom d’un cluster pour le renommer.
Astuce : Il est important de renommer vos clusters pour que vos résultats aient plus de sens dans un contexte réel ou marketing.

Tableau de résultats des clusters
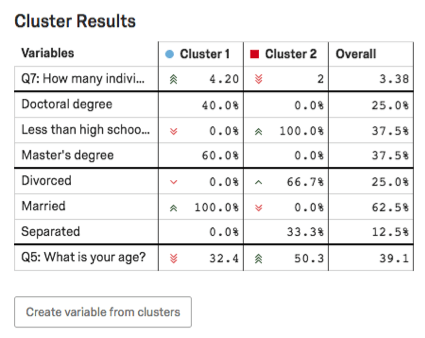
Dans le tableau des Résultats du Cluster, les principales variables du cluster seront surlignées. Pour les variables catégorielles, l’option la plus courante et le pourcentage de personnes interrogées dans le cluster qui ont fourni cette réponse seront indiqués. Pour les variables numériques, vous obtiendrez une réponse moyenne.
Exemple : Dans cette capture d’écran, le niveau d’éducation est catégorique, de sorte que nous voyons un découpage des pourcentages de répondants titulaires d’un doctorat par rapport à ceux titulaires d’un doctorat. Niveau d’études inférieur à l’enseignement secondaire contre niveau d’études inférieur à l’enseignement secondaire. Diplômes de master.
L’âge est ici numérique, nous voyons donc l’âge moyen pour chaque cluster (32,4 pour le Cluster 1, 50,3 pour le Cluster 2).
Pour en savoir plus sur la création de variables à partir de clusters, voir la section Créer une variable à partir de clusters.
Importance de la variable
Le tableau d’importance des variables montre la force du lien entre chaque variable et les clusters. Un lien plus fort indique que la variable a joué un rôle plus important dans la création des clusters.
Pour ce faire, nous effectuons des régressions pour chaque variable. Par exemple, nous comparerons l’âge au résultat du cluster, les heures travaillées au résultat du cluster, etc.
Les valeurs de r-carré résultant de ces régressions sont ensuite mises à l’échelle de manière à ce que le r-carré le plus élevé soit fixé à 1.
Exemple : Supposons que Q7 ait un r-carré de 0,5, le plus élevé du groupe. Cela signifie que si Q13 avait un r-carré de 0,4, il apparaîtrait comme 0,8 dans le graphique ci-dessous.

Création de nouvelles variables à partir des résultats
Une fois que vous avez déterminé les clusters parmi vos répondants, vous pouvez transformer ces catégories en nouvelles variables que vous pouvez analyser dans Stats iQ !
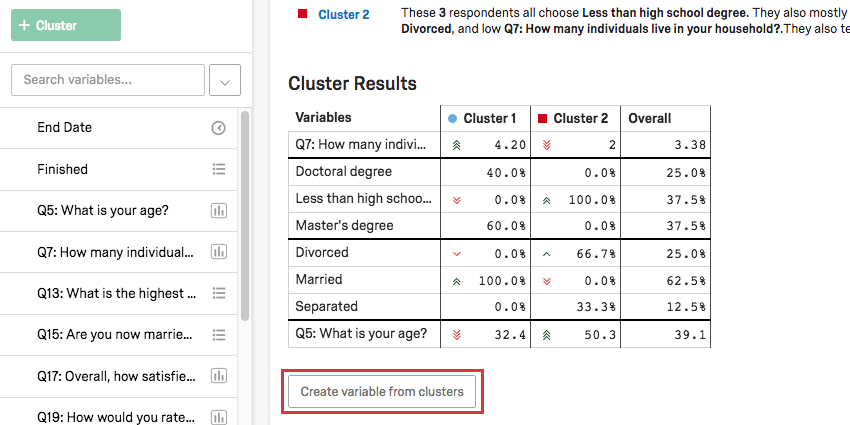
Tout d’abord, veillez à renommer vos clusters en cliquant sur leur nom.
Une fois que vos clusters portent des noms qui vous semblent logiques, cliquez sur Créer une variable à partir des clusters sous le tableau Résultats des clusters. Cela ajoutera automatiquement une variable catégorielle à votre liste de variables sur la gauche.
Remarques techniques
L’analyse Cluster dans Stats iQ utilise l’analyse de classes latentes (LCA) pour répartir les données fournies par l’utilisateur dans les clusters sous-jacents. Contrairement à d’autres algorithmes de clustering, l’algorithme LCA de Stats iQ permet de regrouper différents types de données (numériques, catégorielles et binaires).
Analyse de classes latentes de type mixte
L’analyse des classes latentes (ACL) est un modèle de clustering basé sur les probabilités. Chaque cluster est défini par une collection de fonctions de densité de probabilité qui, sur la base de la valeur des variables d’un point de données, renvoie la probabilité qu’un point de données particulier appartienne à ce cluster.
Exemple : Votre famille peut être divisée en plusieurs générations : les enfants actuels, les parents et les grands-parents. Un modèle ACV représenterait ces trois clusters, chaque cluster étant défini par une fonction de probabilité unique basée sur l’âge :
| Cluster | Fonction de probabilité Moyenne | Fonction de probabilité Écart-type |
| Actuel | 25 | 7 |
| Parents | 48 | 5 |
| Grands-parents | 75 | 3 |
Pour affecter une personne de 30 ans à un cluster, utilisez ces fonctions de densité de probabilité pour calculer qu’il y a 44 % de chances qu’elle se trouve dans Cluster, <1 % de chances qu’elle se trouve dans Parents et <1 % de chances qu’elle se trouve dans Grands-parents. Cette personne serait affectée au cluster le plus probable, Current.
Un modèle d’ACV peut être appliqué à plusieurs variables en multipliant la probabilité qu’un point de données appartienne à un cluster en fonction de chaque variable. Le modèle peut être appliqué à différents types de variables en utilisant différentes fonctions de densité de probabilité :
| Type | Transformation | Fonction de densité de probabilité |
| Catégorique | Chiffre fictif codé (N-1) | Bernoulli |
| Binaire | Bernoulli | |
| Numérique | Normal |
Détermination du nombre de classes
Pour déterminer le nombre optimal de classes, Stats iQ utilise la notation BIC.
Évaluateur de l’adéquation du modèle
Pour évaluer la “qualité” objective d’un modèle, Stats iQ utilise une notation de silhouette basée sur les probabilités. La notation de la silhouette est une mesure de la position de chaque point de données au sein de son cluster. La notation de la silhouette mesure la similitude d’un point particulier avec tous les autres points de son cluster et la compare à sa similitude avec tous les points du cluster de son voisin le plus proche. Pour mesurer la similarité entre deux points de données, Stats iQ calcule la distance de Gower (une mesure de distance qui fonctionne pour les données binaires, catégorielles et numériques) entre les points.