-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Préparation de votre fichier de participant pour l’importation (EX)
À propos de la préparation de votre fichier de participants
Lorsque vous importez des participants dans votre projet Employee Experience, gardez à l’esprit quelques points importants. Par exemple, chaque importation nécessitera les colonnes suivantes :
- Prénom : Prénom du salarié.
- Nom de famille : nom de famille de l’employé.
- E-mail : Adresse e-mail de l’employé. Ce détail est le plus important. L’e-mail peut servir de nom d’utilisateur pour chaque participant ou de moyen de se souvenir des utilisateurs qui existent déjà dans le répertoire.
Attention : si le champ E-mail de votre fichier des participants n’est pas renseigné, un e-mail artificiel sera généré en utilisant le format UniqueID@BrandID.fake comme espace réservé pour renseigner les informations sur la personne. Étant donné que l’e-mail généré est artificiel, les distributions EX ne seront pas envoyées au participant tant que l’e-mail n’aura pas été mis à jour à une adresse valide. Ce comportement ne s’applique pas si votre organisation dispose d’une authentification unique car vous devez inclure des adresses e-mail lors du téléchargement des participants sur le serveur.
- UniqueIdentifier : Précisez les participants par n’importe quel identifiant que votre société préfère. Vous pouvez utiliser n’importe quel identifiant numérique interne en nom d’utilisateur, pour répéter la colonne IDEmployé (mais uniquement si cela est unique au sein de l’organisation et qu’il ne sera partagé avec personne dans un autre projet).
Astuce Qualtrics : consultez la page d’assistance Identifiants uniques pour plus de détails.
Si vous créez un projet d’engagement, vous devrez vous assurer d’avoir choisi la bonne hiérarchie pour votre projet car cela affecte les métadonnées, ou les colonnes personnalisées des données des participants, que vous allez inclure dans votre fichier CSV/TSV. Par exemple, le fichier de hiérarchie parent-enfant doit inclure des colonnes pour l’ID de l’employé et l’ID du responsable, tandis que le fichier de hiérarchie basé sur le niveau doit avoir des colonnes Niveau différentes. Nous passons en revue les métadonnées que vous devez inclure pour chaque hiérarchie sur cette page.
Si vous oubliez d’inclure les métadonnées correctes pour commencer, c’est OK ! Vous pouvez toujours mettre à jour les métadonnées de vos participants après le fait en suivant les étapes de la section liée.
Importer des participants pour une hiérarchie parent-enfant
Les hiérarchies parent-enfant sont le type de hiérarchie le plus couramment utilisé. Il s’agit de la meilleure option si vos données RH sont formatées de sorte que vous disposez d’une liste d’ID de salariés et que les responsables de chaque salarié sont subordonnés jusqu’à.
Cliquez ici pour accéder au modèle de fichier de hiérarchie parent-enfant.
Métadonnées requises
Vous devez inclure deux colonnes de métadonnées pour créer une hiérarchie parent-enfant :
- ID salarié : il s’agit de l’identification du salarié du participant. Il est préférable d’utiliser les identifiants attribués en interne par le service du personnel de votre entreprise, plutôt que d’essayer de constituer de nouveaux identifiants générés de manière aléatoire.
- ManagerID : il s’agit de l’identification du responsable du participant.
Exemple : dans l’image ci-dessous, EmployeeID de John Doe est égal à 1, sa colonne EmployeeID indique donc 1. Jill Davis, Sammy External et Joseph Miller dépendent directement de John Doe, de sorte que leurs colonnes ManagerID indiquent 1.
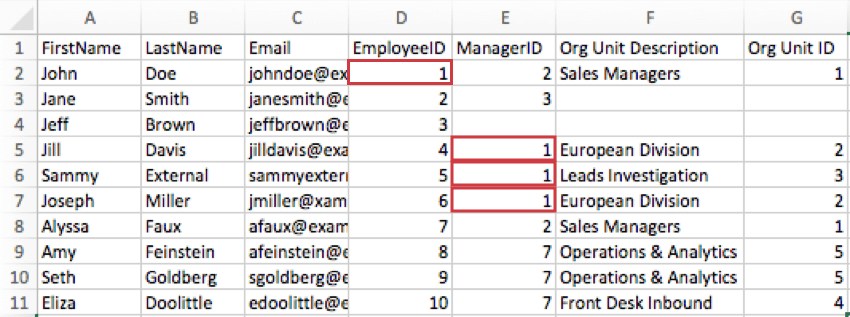
Astuce Qualtrics : d’un point de vue technique, vous pouvez nommer l’IDEmployé et le ManagerID comme vous le souhaitez. Par exemple, si votre organisation préfère le terme “matricule du salarié” ou possède un terme spécial tel que “QID”, n’hésitez pas à donner ces noms à vos colonnes. Ce qui est important, c’est que vous incluiez ces concepts et que vous les saisissiez dans les champs appropriés lorsque vous générez votre hiérarchie parent-enfant.
Lors de l’ajout d’ID d’employé et de responsable, gardez à l’esprit certains éléments importants :
- La colonne Identifiant unique de vos données peut être utilisée pour votre champ ID Collaborateur lors de la génération d’une hiérarchie parent-enfant. Voici comment se présenterait l’exemple précédent dans cette situation :
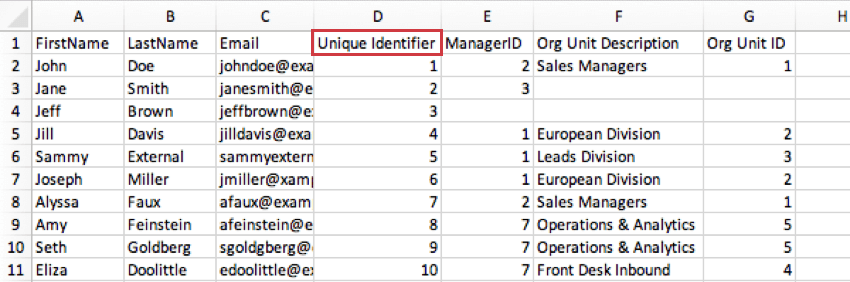
- Chaque participant doit également avoir un ID de collaborateur unique. Plusieurs participants ne peuvent pas partager le même ID. Il peut être identique à l’identifiant unique.
- Chaque participant doit avoir un responsable. La seule exception concerne les membres les plus élevés de l’entreprise que vous incluez dans votre hiérarchie (par exemple, les PDG). Laissez la colonne Responsable vide pour indiquer que cette personne ne dépend de personne.
- Les colonnes ID Collaborateur et ID manager d’un collaborateur individuel ne doivent jamais être identiques. Les employés ne se rendent pas compte à eux-mêmes !
- Chaque ID de manager doit renvoyer à un employé. Tout participant ayant un ID de responsable qui ne correspond pas à un ID de collaborateur existant sera affecté à un responsable inconnu. Notez qu’une fois qu’une personne est affectée à un responsable inconnu, les membres de la hiérarchie en dessous de cette personne seront également rompus. Pour résoudre ce problème, vous devez corriger manuellement les données et regénérer la hiérarchie.
- Faites attention à la logique circulaire. Si John Doe est sous la responsabilité de Jane Smith et que Jane Smith est sous la responsabilité de Joseph Miller, Joseph Miller ne peut pas le signaler à John Doe. Vous ne pouvez pas gérer le responsable de votre responsable.
Métadonnées facultatives
Vous pouvez ajouter des métadonnées supplémentaires lorsque vous téléchargez votre liste de participants. Il est possible d’inclure tous les éléments, depuis l’anniversaire de chaque salarié jusqu’aux locaux de son bureau. Cependant, il existe deux métadonnées facultatives qui peuvent vous aider à mettre en forme votre hiérarchie parent-enfant.
- ID entité organisationnelle : les ID d’entité organisationnelle vous aident à identifier la même équipe au fil du temps, même si le nom de l’équipe change. Il sert le même objectif qu’un matricule unique, mais pour une entité au lieu d’un salarié. L’ajout d’un ID d’entité organisationnelle stable signifie que vous n’avez pas besoin de mapper manuellement les données de hiérarchie ; le système reconnaît l’ID et le mappe de manière appropriée.
Astuce Qualtrics : avez-vous des équipes différentes avec le même nom ? Ou disposez-vous d’ensembles d’équipes et de responsables distincts qui dépendent d’une même division ? Vous pouvez réutiliser la même description de l’entité organisationnelle en définissant des zones d’ID d’entité organisationnelle distinctes. Par exemple, un directeur commercial peut diriger une équipe appelée Ventes avec un ID d’entité organisationnelle 001 et un autre responsable peut diriger une équipe appelée Ventes avec un ID d’entité organisationnelle de 002.
Les ID d’entité organisationnelle sont également utiles si un manager dépasse plusieurs équipes. Cela signifie que si mon responsable est John Doe, mais que John Doe est le manager de l’équipe A et de l’équipe B, je peux indiquer à quelle équipe j’appartiens dans la zone ID d’unité.
- Description de l’entité organisationnelle : lors de la création de votre hiérarchie, les unités seront automatiquement nommées pour un responsable. L’option Description de l’entité organisationnelle vous permet de nommer vos entités en fonction des noms ou des descriptions des entités.
La description de l’entité organisationnelle est essentiellement le nom fourni pour l’ID d’entité organisationnelle fourni et apparaîtra comme étiquette de l’entité dans les tableaux de bord lors du filtrage ou du découpage par unité. Les colonnes ne doivent pas nécessairement contenir les mêmes valeurs exactes, mais si ID est numérique, Description est descriptif. Par exemple, la description de l’unité organisationnelle de l’ID org. 2 peut être Division européenne.
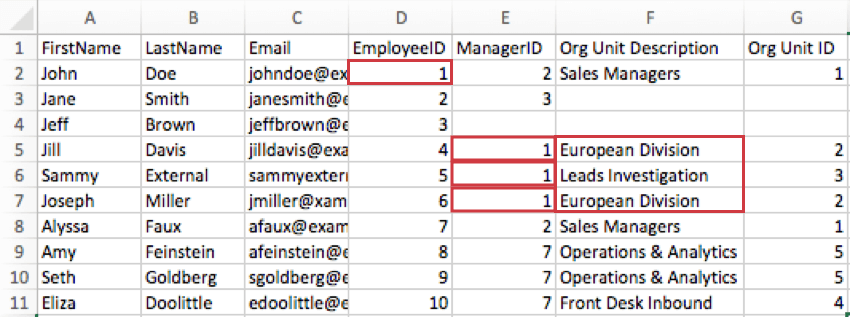
Exemple : Sur l’image ci-dessous, John Doe gère deux équipes différentes : la Division européenne et Lead Investigation. La colonne Description de l’entité organisationnelle indique à laquelle de ces équipes appartiennent ses 3 subordonnés directs. On voit que Jill Davis et Joseph Miller sont en division européenne, mais Sammy External est dans Lead Investigation.
Importation de participants pour une hiérarchie basée sur les niveaux
Les hiérarchies basées sur les niveaux sont une bonne option si vos données du personnel incluent chaque niveau vers lequel le salarié dépend, du haut de la hiérarchie jusqu’à l’emplacement du salarié. Avec les hiérarchies basées sur les niveaux, vous n’avez pas nécessairement besoin de savoir qui est le responsable du salarié ; il vous suffit de connaître la chaîne de commande pour chaque salarié que vous incluez dans le projet. Ce format de données est souvent plus courant avec les sociétés qui organisent les données des employés selon des niveaux, des sites ou des découpages fonctionnels distincts.
Cliquez ici pour accéder au modèle de fichier de hiérarchie basée sur les niveaux.
Métadonnées requises
Vous aurez besoin d’une colonne distincte pour chaque niveau de votre organisation que vous souhaitez définir. Le dernier niveau renseigné pour un participant indique sa place dans la hiérarchie. Pour les personnes plus haut, cela signifie généralement que la première colonne Niveau est renseignée, mais pas les autres.
Métadonnées du responsable
Si vous souhaitez affecter des responsables à des unités dans vos hiérarchies basées sur les niveaux, il existe deux façons de le faire.
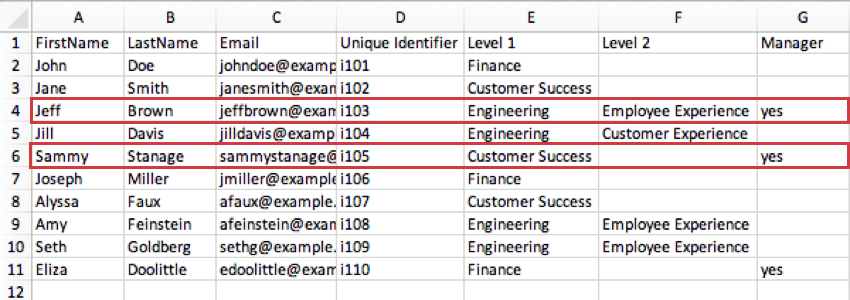
- Responsable : cette colonne indique si le participant est un responsable. Le participant sera désigné comme responsable du niveau le plus bas indiqué. La plupart des utilisateurs utilisent « oui » pour indiquer un responsable, mais vous pouvez également utiliser « 1 », « responsable » ou tout format que vous souhaitez, tant que vous avez une valeur dans la colonne qui indique que le participant est un responsable.
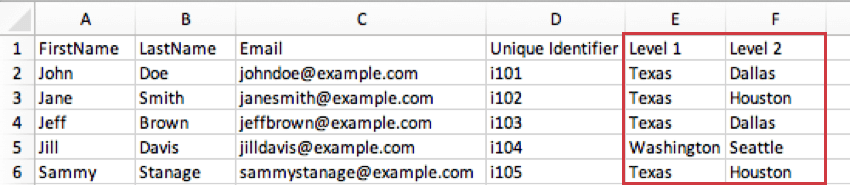
Exemple : dans l’image ci-dessous, le niveau le plus bas défini pour Sammy Stanage est le niveau 1, où il occupe un rôle Customer Success. Le « oui » dans sa colonne Responsable indique qu’il est responsable de l’ensemble de Customer Success. Dans le même temps, le dernier niveau défini par Jeff Brown est l’expérience employé au sein de l’ingénierie. Cela signifie qu’au sein de l’ingénierie, il est responsable du niveau Employee Experience.
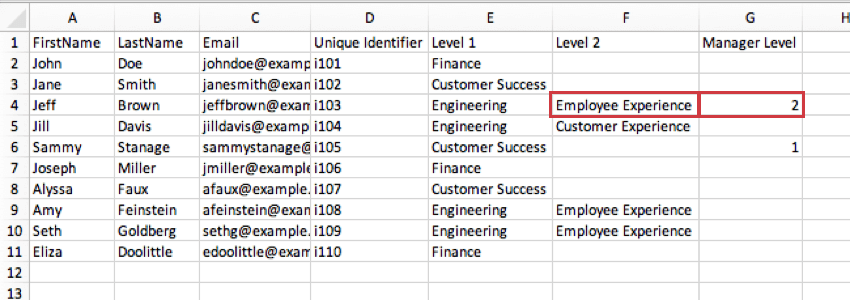
- Niveau responsable : le niveau responsable est un moyen d’identifier les responsables en indiquant le niveau spécifique qu’ils gèrent. Dans l’exemple précédent, la même valeur (“oui”) indique si un participant est un gestionnaire ou non ; pour le niveau de gestionnaire, cependant, il existe des valeurs distinctes pour chaque niveau.
Exemple : dans l’image ci-dessous, le niveau de manager de Jeff Brown est 2 pour indiquer qu’il est responsable de son poste de niveau 2 dans Employee Experience, et non de son poste de niveau 1 dans l’ingénierie.
Métadonnées facultatives
ID entité organisationnelle : les ID d’entité organisationnelle vous aident à identifier la même équipe au fil du temps, même si le nom de l’équipe change. L’inclusion d’un ID d’entité organisationnelle stable signifie que vous n’avez pas besoin de mapper manuellement les données de hiérarchie ; le système reconnaît l’ID et le mappe de manière appropriée. Il sert le même objectif qu’un matricule unique, mais pour une entité au lieu d’un salarié. Vous devez inclure autant d’ID d’entité organisationnelle que de niveaux, afin de pouvoir fournir un ID pour chaque niveau.
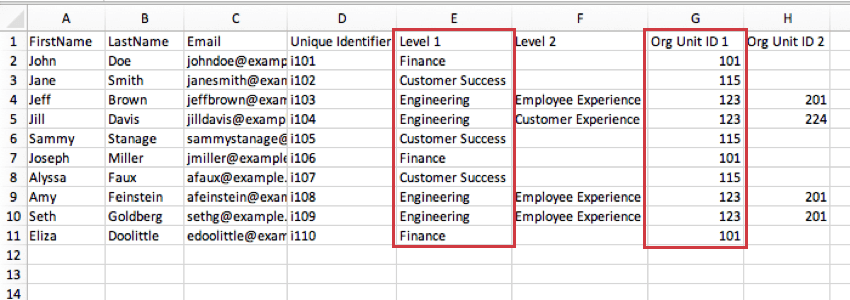
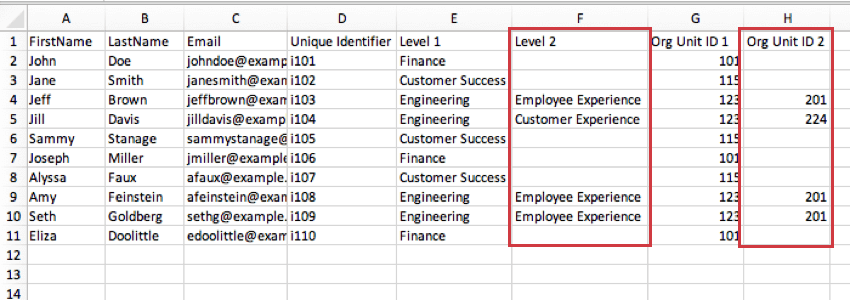
Dans la capture d’écran ci-dessous, les entités du niveau 2 correspondent à la colonne ID entité organisationnelle 2. L’équipe d’ingénierie Employee Experience est l’unité 201 et l’équipe d’ingénierie Customer Experience 224.
Importation de participants pour une hiérarchie de squelettes
Les hiérarchies de squelettes sont utilisées lorsque vous connaissez l’identité de vos responsables, mais pas leurs subordonnés directs. Au lieu d’organiser une hiérarchie autour d’une liste de subordonnés directs et de la chaîne de commande au-dessus d’eux, vous créez une liste de responsables et d’unités auxquelles ils sont rattachés.
Voici un exemple de hiérarchie de squelettes pour vous aider à démarrer. Créez un fichier CSV/TSV et créez une ligne avec chaque gestionnaire associé. Vous devez au moins disposer d’informations sur le responsable pour créer une hiérarchie Skeleton.
Pour chaque responsable, ajoutez une colonne pour le prénom, le nom, l’e-mail, du responsable et les métadonnées supplémentaires que vous souhaitez inclure. Vous devez ensuite ajouter les métadonnées suivantes :
- ID entité organisationnelle : ID de l’entité gérée par le salarié.
- ID d’entité parent : ID de l’entité directement au-dessus de cette unité. Il s’agit de l’unité à laquelle le salarié est rattaché.
- Description de l’organisation : ces métadonnées sont facultatives. Elle vous permet de créer un nom pour l’unité gérée par le salarié. Il peut s’agir du nom de l’équipe, ou même du nom du manager.
Exemple : dans l’exemple ci-dessous, le service informatique est un service plus important sous lequel l’ingénierie est imbriquée. Jean Dupont est le responsable informatique, sa colonne ID entité organisationnelle indique donc 1 pour indiquer que l’ID d’unité IT est 1. Geoff Brown et Jill Davis sont les responsables de l’ingénierie, ils ont donc tous deux un ID d’organisation parent de 1 pour indiquer que le service informatique est l’unité parente de l’ingénierie.

Répondants vs. Non-répondants
Un répondant est un participant qui peut répondre à votre enquête. Un non-répondant est un participant qui ne peut pas accéder à l’enquête. Il peut être utile de désigner certains participants comme non-répondants si vous souhaitez qu’ils puissent afficher les résultats du tableau de bord ou valider des hiérarchies d’organisation, mais que vous ne voulez pas qu’ils remplissent une enquête.
Vous pouvez déterminer si le participant que vous ajoutez est un répondant au projet en incluant un en-tête appelé Répondant, puis en utilisant l’une des valeurs suivantes :
- 0 – Non-répondant
- 1 – Répondant
Si vous n’incluez pas la colonne Répondant dans votre fichier, tous vos participants seront définis comme répondants par défaut.
Caractères maximum et pris en charge
Nombre maximal de caractères pour chaque champ
- Prénom : 50 caractères pour chaque prénom.
- Nom : 50 caractères pour chaque nom de famille.
- E-mail : 100 caractères pour chaque e-mail.
- UniqueIdentifier : 100 caractères pour chaque identifiant unique.
- Toutes les autres métadonnées : les noms de métadonnées sont limités à 90 caractères chacun, tandis que les valeurs sont limitées à 1 000 caractères chacune.
Caractères non pris en charge
Les caractères suivants ne peuvent être utilisés dans aucun de vos noms ou valeurs de métadonnées :
|
&
;
$
%
< >
( de
{ }
*
+
,,
`Vous pouvez utiliser une barre oblique (/ ) dans les valeurs des zones telles que les dates, mais vous ne pouvez pas l’utiliser dans le nom de zone de métadonnées.