-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Anonymat (EX)
À propos de l’anonymat
Il existe deux niveaux d’anonymat : de base et renforcé. L’anonymat de base est activé par défaut dans chaque tableau de bord, tandis que l’anonymat renforcé peut être activé pour des couches de protection supplémentaires. Pour plus d’informations, voir Basic vs. Anonymat renforcé.
Toute modification apportée aux paramètres d’anonymat sera immédiatement appliquée à votre tableau de bord.
Base vs. Anonymat amélioré
Anonymat de base
Les seuils d’anonymat de base déterminent le nombre de réponses à inclure pour un point de données donné avant qu’il n’apparaisse dans votre tableau de bord. C’est un excellent moyen de protéger la confidentialité des réponses des employés. Le seuil d’anonymat s’applique à chaque point de données pour les métriques (score de favorabilité, moyenne, etc.) mais pas aux comptages de données (nombre de réponses).
L’anonymat de base est un moyen simple de protéger les réponses des employés tout en permettant une certaine souplesse dans l’analyse des données.
Lorsque vous ajoutez des filtres à une page, vous pouvez sélectionner des valeurs inférieures au seuil, mais vous ne verrez aucune donnée tant que la valeur totale de toutes les données sélectionnées dans les filtres n’aura pas atteint votre seuil d’anonymat. Pour plus d’informations, voir Filtrer les tableaux de bord.
Lors de la ventilation des données sur un seul champ, toutes les mesures inférieures au seuil d’anonymat seront masquées et les chiffres seront affichés. Lors de la ventilation des données sur plusieurs champs, les métriques et les comptes inférieurs au seuil d’anonymat seront masqués.Les
widgets des taux de réponses afficheront les comptages inférieurs au seuil d’anonymat.
Anonymat amélioré
Outre les fonctions couvertes par l’anonymat de base, l’anonymat renforcé ajoute des couches supplémentaires aux filtres et aux découpages de widgets qui peuvent améliorer l’anonymat dans certains cas d’utilisation. Avec l’anonymat renforcé, le seuil d’anonymat s’applique à tous les points de données (métriques et comptages) pour les champs sensibles, mais à aucun point de données pour les champs non sensibles.
L’anonymat renforcé offre une protection avancée des réponses des employés, ce qui réduit la flexibilité de l’analyse des données.
Seuil d’anonymat
Le seuil d’anonymat détermine le nombre de réponses qui doivent être incluses pour un point de données ou un commentaire donné avant qu’il n’apparaisse dans votre tableau de bord. Les points de données peuvent être aussi vastes qu’un widget ou aussi spécifiques qu’un diagramme à barres dans un graphique.
Le seuil d’anonymat par défaut est fixé à 5 pour les points de données et les commentaires.
Pour afficher et modifier les seuils d’anonymat, procédez comme suit :
- Lorsque vous consultez votre tableau de bord, cliquez sur Paramètres.
- Allez dans l’onglet Anonymat .
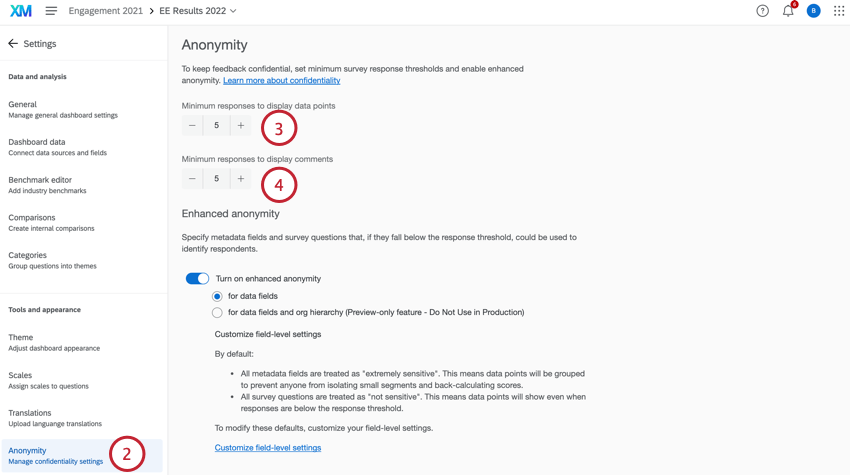
- Sous Minimum de réponses pour afficher les points de données, déterminez le nombre de réponses à collecter avant que les données ne s’affichent dans les widgets. Cette limite est appliquée à tous les découpages de données dans tous les widgets.
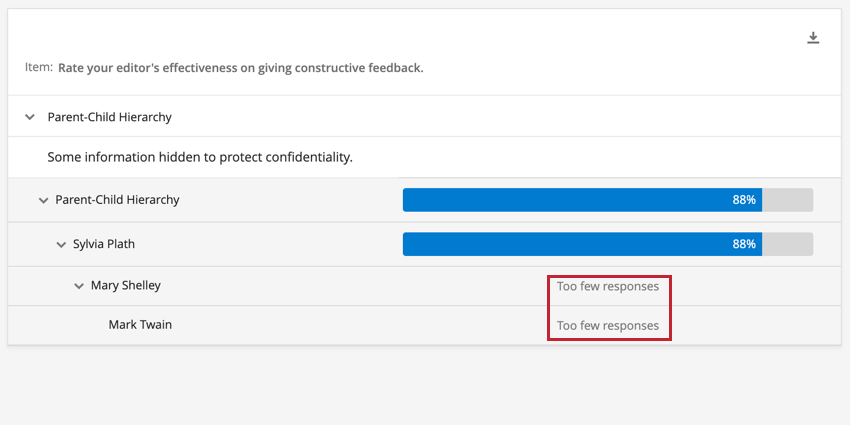
Exemple : L’image ci-dessous montre un widget de Comparaison ventilé selon la Hiérarchie d’organisation active. Si les unités ont un nombre du nombre de réponses inférieur au Seuil d’anonymat, ces unités n’afficheront aucune donnée dans le Widget. Les unités dont le nombre de réponses est supérieur au seuil d’anonymat affichent les données normalement. Le nombre de réponses pour les unités Mary Shelley et Mark Twain étant inférieur au seuil d’anonymat, le widget affiche le message “Trop peu de réponses” pour ces unités.
- Sous Réponses minimales pour l’affichage des commentaires, déterminez le nombre de réponses à collecter avant que les réponses aux questions ouvertes ne s’affichent dans les widgets.
Permettre un anonymat renforcé
L’anonymat renforcé peut être activé et désactivé au niveau du tableau de bord pour améliorer l’anonymat.
Par exemple, supposons que l’équipe de Barnaby compte 15 personnes. Lorsque nous examinons les notations d’engagement de son équipe, nous ne savons pas vraiment comment chaque membre de l’équipe a répondu aux questions sur l’efficacité de leur Manager. Toutefois, supposons qu’il n’y ait que deux femmes dans son équipe. Les seuils d’anonymat habituels garantissent que nous ne pouvons pas voir directement les réponses des femmes. Cependant, si nous ajoutons un filtre de genre, nous pouvons deviner assez bien ce que chacune des femmes de son équipe avait à dire. L’anonymat renforcé permet de détecter les disparités de ce type. La technologie permet de s’assurer que les données des groupes qui ne respectent pas le seuil d’anonymat sont combinées avec celles du groupe le plus petit suivant afin de masquer leurs réponses lors de la ventilation des données ou de l’utilisation de filtres.
- Lorsque vous consultez votre tableau de bord, cliquez sur Paramètres.
- Allez dans l’onglet Anonymat .
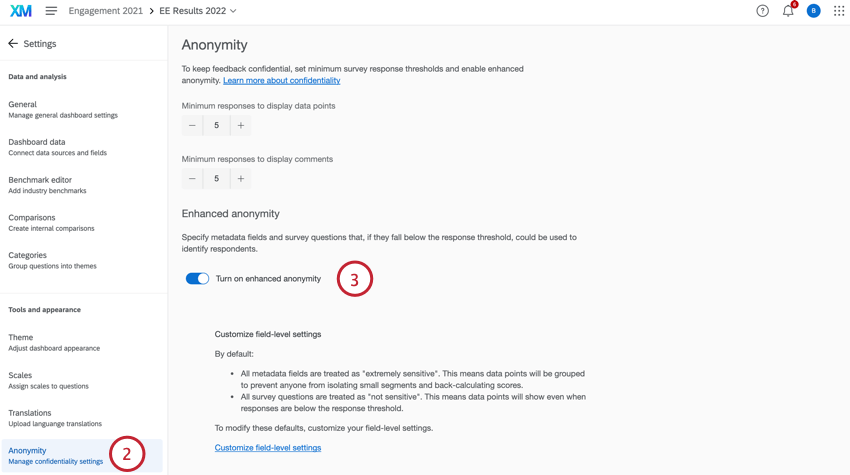
- Activer Activer l’anonymat renforcé.
Réglages au niveau du terrain
Lorsque l’anonymat renforcé est activé, vous pouvez personnaliser le niveau d’anonymat pour chaque champ de votre tableau de bord en marquant les champs comme Extrêmement sensible, Assez sensible ou Non sensible. Cela modifie la façon dont les découpages sont traités et affichés dans les widgets, et vous permet de regrouper les points de données inférieurs au seuil de réponse sur certains champs tout en masquant les points de données inférieurs au seuil de réponse sur d’autres.
Certains champs du tableau de bord permettant d’identifier les participants peuvent être considérés comme sensibles et doivent être marqués comme extrêmement sensibles ou assez sensibles, tandis que les champs qui ne sont pas sensibles doivent être marqués comme non sensibles. Par exemple, la titularisation, le sexe et l’équipe à laquelle appartient une personne peuvent tous être utilisés pour déterminer qui elle est. Toutefois, les questions posées dans le cadre d’une enquête sur l’Employee Experience ne sont presque jamais sensibles, à l’exception des questions démographiques telles que la langue, la localisation du bureau et l’âge.
Lorsque les champs sont marqués comme extrêmement sensibles, les données des groupes qui n’atteignent pas le seuil d’anonymat seront combinées avec le groupe le plus petit suivant afin de protéger l’identité des répondants. Lorsque les champs sont marqués comme quelque peu sensibles, les données des groupes qui ne respectent pas le seuil d’anonymat ne seront pas affichées. Lorsque les champs sont marqués comme non sensibles, le regroupement n’a pas lieu à moins que vous ne filtriez ou ne sépariez par un champ sensible.
Pour modifier les champs qui sont sensibles et ceux qui ne le sont pas, vous devez procéder comme suit :
- Allez dans Paramètres.
- Sélectionnez Anonymat.
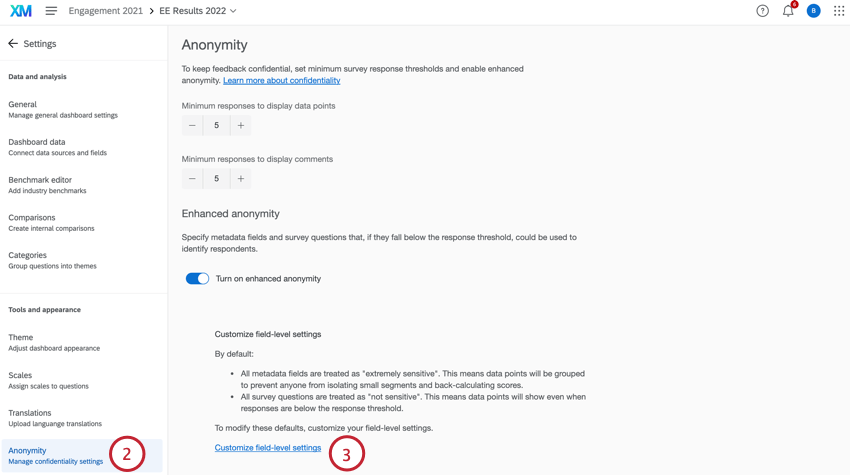
- Sélectionnez Personnaliser les paramètres au niveau du champ.
- Utilisez le menu déroulant suivant pour sélectionner le degré de sensibilité de chaque information. Vous pouvez choisir parmi les options suivantes :
- Extrêmement sensible : Ces champs contiennent des informations permettant d’identifier les participants. Lorsqu’un point de données se situe en dessous du seuil d’anonymat, des réponses d’anonymat renforcées s’appliquent et les données sont regroupées avec le(s) point(s) de données le(s) plus petit(s) suivant(s). Ces champs étaient auparavant appelés champs identifiables.
Astuce : Tous les champs de métadonnées sont marqués comme extrêmement sensibles par défaut.
- Assez sensible : Ces champs contiennent des informations qui peuvent permettre d’identifier les participants. Les points de données qui se situent en dessous du seuil d’anonymat ne seront pas affichés, comme dans le cas de l’anonymat de base. Cette option est utile pour les champs tels que les dates ou les périodes de temps.
Astuce : Avec cette option, il est toujours possible de savoir quel participant a fourni une certaine réponse ; pour plus de sensibilité, les champs doivent être marqués comme extrêmement sensibles.
- Non sensibles : Ces champs ne contiennent pas d’informations permettant d’identifier les participants. Tous les points de données sont affichés, même lorsque les réponses sont inférieures au seuil de réponse. Ces champs étaient auparavant appelés champs non identifiables.
Astuce : Tous les champs de questions sont marqués comme non sensibles par défaut.
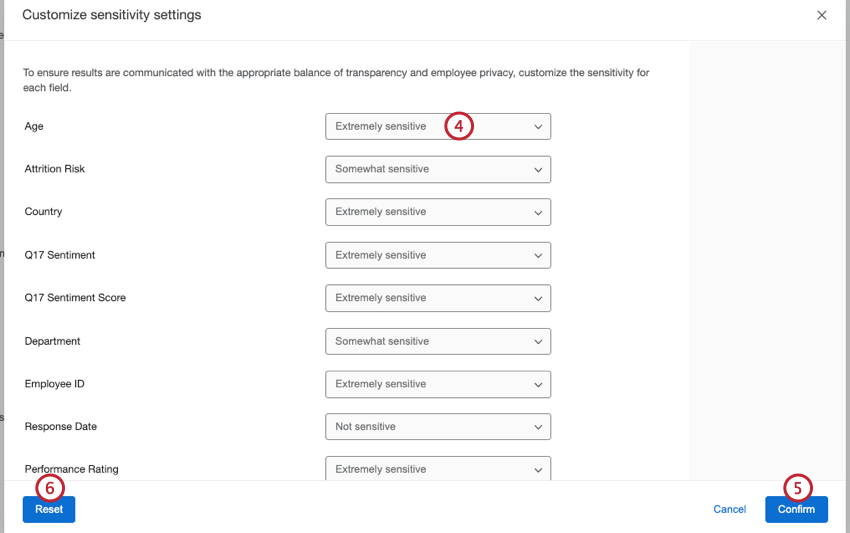
- Extrêmement sensible : Ces champs contiennent des informations permettant d’identifier les participants. Lorsqu’un point de données se situe en dessous du seuil d’anonymat, des réponses d’anonymat renforcées s’appliquent et les données sont regroupées avec le(s) point(s) de données le(s) plus petit(s) suivant(s). Ces champs étaient auparavant appelés champs identifiables.
- Cliquez sur Confirmer.
- Pour revenir à la configuration d’origine et supprimer toutes vos modifications, cliquez sur Réinitialiser.
Exemple : Dans notre tableau de bord, nous n’avons pas marqué les questions d’engagement comme étant identifiables, car elles ne sont pas démographiques et ne peuvent en aucun cas être utilisées pour identifier leurs répondants.

Supposons que le seuil du tableau de bord soit de 5. Si nous créons un tableau affichant les réponses des employés à un champ non identifiable tel que “Je suis fier de dire aux gens où je travaille”, les réponses ne seront pas regroupées. Voir ci-dessous comment apparaît la mention “Pas du tout d’accord”, bien qu’il n’y ait qu’une seule réponse.
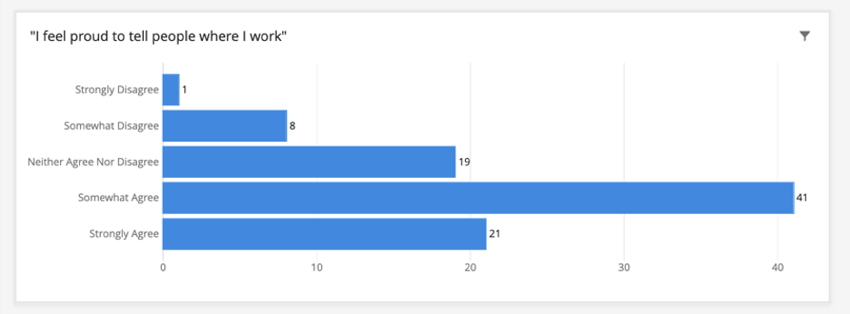
Notez que le nombre total de réponses dans le widget doit toujours respecter le seuil. Ce graphique comporte un nombre total de 90 réponses. S’il en avait moins de 5, le graphique serait vide car le comportement par défaut du seuil d’anonymat est de masquer les données des widgets qui n’atteignent pas le seuil.
Interactions sur le terrain
Si vous utilisez un tableau ou un graphique pour afficher un champ extrêmement sensible ou quelque peu sensible avec un champ non sensible, vos données doivent être regroupées de la même manière, quelle que soit la façon dont vous transposez les données. La logique de regroupement est appliquée de manière cohérente en fonction des paramètres du champ, quel que soit le champ configuré en tant que ligne ou colonne.
Définition de la (des) source(s) de données du Tableau de bord
Lorsque vous utilisez l’anonymat renforcé, si vous utilisez également des sources historiques dans votre tableau de bord, il est important d’aller dans les paramètres généraux du tableau de bord et de limiter les filtres de page aux données de l’année en cours.
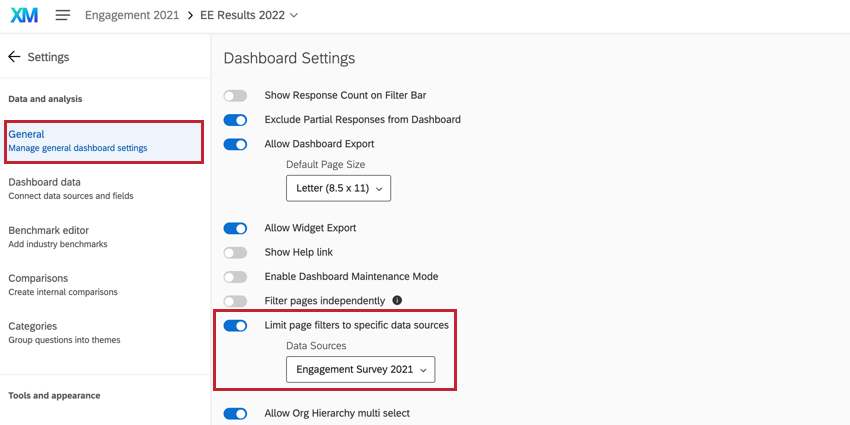
Sinon, les filtres du tableau de bord, à l’exception du filtre Hiérarchie de l’organisation, qui utilise par défaut la source de données principale, incluront les données de toutes les sources de données dans les données dutableau de bord . Cela signifie que les données historiques peuvent être incluses dans le nombre de réponses et peuvent fausser les regroupements anonymes. Par exemple, si les résultats actuels et historiques d’une petite équipe sont pris en compte au lieu des seuls résultats de l’année en cours, la petite équipe semble plus importante qu’elle ne l’est en réalité et risque de ne pas passer sous le seuil d’anonymat. Le fait de limiter les filtres à la source de données principale (c’est-à-dire le projet en cours ou les données de l’année en cours) résout ce problème.
Comportement du filtre
Une fois que vous avez activé l’anonymat renforcé et ajouté un filtre à votre tableau de bord, vos paramètres d’anonymat détermineront le comportement des filtres.
Le comportement du filtre de page dépend des paramètres de chaque champ au niveau du champ :
- Champs non sensibles : Ces champs permettent de sélectionner n’importe quelle valeur, même si elle est inférieure au seuil.
- Champs assez sensibles : Ces champs ne permettent de sélectionner que les valeurs qui atteignent ou dépassent le seuil.
- Champs extrêmement sensibles : Ces champs regroupent toutes les valeurs inférieures au seuil. Les résultats inférieurs au seuil seront combinés avec l’option la plus petite suivante dans le filtre avant toute sélection. Si un seul groupe se trouve en dessous du seuil, il sera combiné avec le groupe suivant le plus petit, que ce dernier atteigne ou non le seuil. Cela permet de s’assurer que même si un seul groupe n’atteint pas le seuil, ses données sont protégées.
Au fur et à mesure que des filtres sont ajoutés ou supprimés, l’anonymat renforcé en tiendra compte et modifiera les regroupements en conséquence.
Exemple : Dans la capture d’écran ci-dessous, nous essayons de filtrer par département. Il s’agit d’une petite entreprise, de sorte que la finance, le support et les ressources humaines ont des équipes très réduites, en dessous du seuil d’anonymat que nous avons fixé.
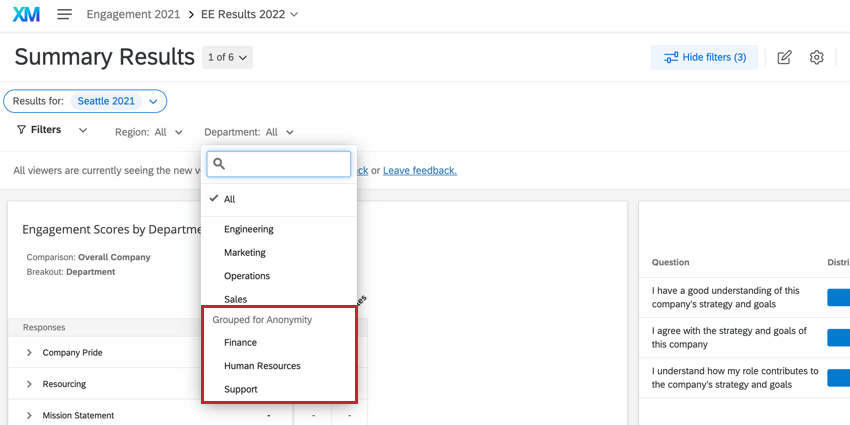
Vous verrez que les rubriques Finance, Support et Ressources humaines se trouvent sous l’en-tête Regroupés pour l’anonymat. Si j’essaie d’en sélectionner un seul, les deux seront automatiquement sélectionnés. Si j’essaie d’en désélectionner un, les deux sont désélectionnés. Cela empêche les utilisateurs de déterminer les valeurs des groupes inférieurs au seuil.
Filtres de Hiérarchie d’organisation
Les niveaux hiérarchiques d’organisation qui ne respectent pas le seuil d’anonymat sont grisés et accompagnés d’une icône de cadenas. Vous ne pourrez pas sélectionner les unités qui ne respectent pas le seuil d’anonymat. Ceci afin de protéger l’anonymat des personnes interrogées.
![]()
Comportement de découpage
Lorsque l’anonymat renforcé est activé, les paramètres de chaque champ déterminent la manière dont les données seront affichées dans les widgets où les données ont été réparties dans certains groupes. Il s’agit notamment des widgets de lignes pour lesquels une dimension de l’axe des x a été définie, des widgets auxquels des comparaisons ont été ajoutées, des widgets de découpage démographique, des widgets de carte thermique et de toute autre configuration de widget permettant d’isoler des groupes dont la taille peut être inférieure au seuil d’anonymat.
- Champs non sensibles : Ces champs afficheront tous les points de données (métriques et comptages), même s’ils sont inférieurs au seuil.
- Champs assez sensibles : Ces champs n’afficheront que les points de données (métriques et comptages) qui atteignent ou dépassent le seuil des réponses.
- Champs extrêmement sensibles : Ces champs regrouperont tous les points de données (métriques et comptages) inférieurs au seuil.
Les exceptions à cette règle sont les widgets répartis selon la hiérarchie d’organisation. Certains widgets (carte thermique, répartition démographique) proposent un découpage “un niveau en dessous” qui affiche des données pour chaque unité fille de l’unité sélectionnée dans le filtre de la hiérarchie d’organisation. D’autres widgets (taux de réponses, comparaison, graphique à bulles) permettent une analyse par tri successif de la hiérarchie, en affichant les données pour chaque unité et en permettant à l’utilisateur de les sélectionner. Pour tout widget ventilé par hiérarchie d’organisation, l’anonymat renforcé n’est pas appliqué. Cela signifie qu’aucune unité ne sera regroupée pour des raisons d’anonymat.
Si vous deviez changer la mesure pour un score d’engagement moyen ou un NPS, l’anonymat renforcé vous empêcherait de comprendre les données du plus petit bureau en ne permettant pas aux utilisateurs du tableau de bord d’isoler les données de ce bureau. Ceci est utile dans les cas où, par exemple, nous ne voulons pas que les notations de chaque membre du plus petit bureau soient facilement calculées.
Exemple:
Dans l’exemple suivant, notre tableau de bord a un seuil d’anonymat défini pour le champ “pays” pour aider à protéger les réponses des employés dans les petits bureaux. Dans le widget ci-dessous, nous avons défini la dimension de l’axe des y d’un diagramme à barres comme étant le pays où se trouve le bureau de l’employé. L’Australie et le Mexique ont de très petits bureaux, en dessous du seuil d’anonymat que nous avons fixé. Par conséquent, leurs réponses ont été combinées.
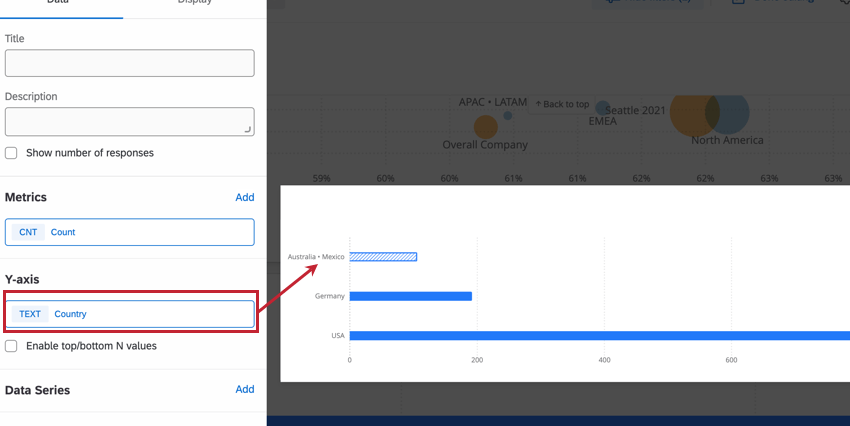
Si vous deviez changer la mesure pour un score d’engagement moyen ou un NPS, l’anonymat renforcé vous empêcherait de comprendre les données du plus petit bureau en ne permettant pas aux utilisateurs du tableau de bord d’isoler les données de ce bureau. Ceci est utile dans les cas où, par exemple, nous ne voulons pas que les notations de chaque membre du plus petit bureau soient facilement calculées.
Découpages multiples
Certains widgets s’étendent sur plusieurs dimensions – par exemple, les widgets de ligne et de barre vous permettent d’ajouter à la fois une valeur sur l’axe des x et une série de données, et les tableaux vous permettent d’ajouter à la fois des lignes et des colonnes.
Plus les données sont ventilées, plus chaque catégorie peut être réduite et plus le nombre de catégories regroupées sous couvert d’anonymat est important. Et parce qu’il y a maintenant 2 dimensions au découpage, il peut y avoir différentes combinaisons de catégories qui doivent être regroupées pour des raisons d’anonymat. Ainsi, les catégories regroupées pour des raisons d’anonymat seront étiquetées ” regroupées pour des raisons d’anonymat” et vous pourrez les survoler pour déterminer quelles catégories spécifiques ont été regroupées.
Vous remarquerez également que dans la légende, les groupes d’anonymat sont étiquetés comme étant regroupés pour l’anonymat, et non comme un nom composé. Il s’agit de tenir compte de la manière dont les regroupements peuvent changer en fonction de l’interaction de plusieurs découpages, et d’éviter les étiquettes trop longues.
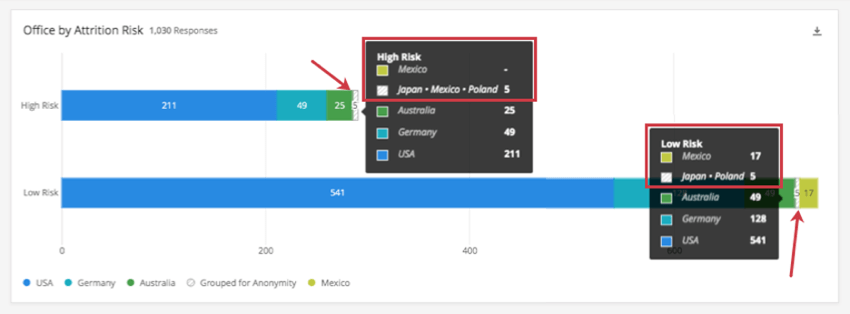
Exemple : Ce tableau de bord a un seuil de 5. Dans le graphique ci-dessous, nous avons réparti les pays dans lesquels travaillent nos employés en fonction du risque d’attrition. Nous pouvons voir un bloc vert clair pour le Mexique dans la barre des risques faibles, mais pas dans la barre des risques élevés.
Lorsque nous surlignons les blocs Grouped for Anonymity pour chaque barre, nous découvrons qu’il y a une différence : Le Mexique a été regroupé avec le Japon et la Pologne dans la barre des risques élevés, mais seuls le Japon et la Pologne ont été regroupés dans la barre des risques faibles.
Regardez la capture d’écran ci-dessous. Dans la catégorie ” risque élevé”, le Mexique n’a pas de données individuelles ( – ), mais le Japon + le Mexique + la Pologne présentent des données, étant donné que ces pays sont regroupés pour des raisons d’anonymat (5). Dans la catégorie ” risque faible”, le Mexique atteint le seuil, il n’a donc pas besoin d’être regroupé et présente des informations individuelles (17), tandis que le Japon et la Pologne sont regroupés (5).
Anonymat de base
Si vous découpez les données en 2 champs ou plus avec un anonymat de base, chacun des champs de découpage sera considéré séparément. Lors de la ventilation des données sur plusieurs champs, les métriques et les points de données de comptage inférieurs au seuil seront masqués.
L’anonymat de base ne comptera pas les réponses sans valeur (vide/nul) lors de la comparaison du nombre de réponses avec le seuil d’anonymat. Il s’agit de protéger les cas où un participant à l’enquête qui pourrait ne pas être éligible pour répondre à une question (par exemple, la logique de l’enquête indique que seuls les managers peuvent répondre à une question) voit ses réponses comptabilisées dans le seuil d’anonymat.
Anonymat amélioré
L’anonymat amélioré comptabilise les réponses sans valeurs (vides/nulles) lors de la comparaison du nombre de réponses avec le seuil d’anonymat.
Le comportement du découpage multi-champs dépend des réglages au niveau des deux champs concernés. Ce tableau montre comment les données seront masquées pour les doubles découpages entre les différents types de champ.
| Non sensible | Assez sensible | Extrêmement sensible | |
| Non sensible | Tous les points de données (métriques et comptages) seront affichés. | Les valeurs du champ quelque peu sensible seront masquées si elles sont inférieures au seuil. | Les valeurs du champ extrêmement sensible seront regroupées si elles sont inférieures au seuil. |
| Assez sensible | Les valeurs du champ quelque peu sensible seront masquées si elles sont inférieures au seuil. | Tous les points de données (métriques et nombres) inférieurs au seuil du nombre de réponses seront masqués. | Les valeurs du champ assez sensible seront cachées si elles sont inférieures au seuil et les valeurs du champ extrêmement sensible seront regroupées si elles sont inférieures au seuil. |
| Extrêmement sensible | Les valeurs du champ extrêmement sensible seront regroupées si elles sont inférieures au seuil. | Les valeurs du champ assez sensible seront cachées si elles sont inférieures au seuil et les valeurs du champ extrêmement sensible seront regroupées si elles sont inférieures au seuil. | Les points de données inférieurs au seuil de réponse seront regroupés. |
  ;
Taux de réponses Comportement
Les taux de réponse indiquent le nombre de réponses que vous avez reçues et le pourcentage de votre liste de participants qui a répondu à l’enquête. Ce type de données est rapporté par les widgets résumé des participants et taux de réponse.
Par défaut, le tableau de bord considère les taux de réponses comme des informations sensibles. Cela signifie que les données relatives au taux de réponse peuvent être utilisées pour identifier les participants. Pour protéger vos participants, les taux de réponse sont donc susceptibles d’être regroupés en fonction de l’anonymat.
Exemple : Lorsque vous créez un widget de taux de réponse, vous pouvez ajouter un champ pour décomposer le widget. Ci-dessous, nous avons réparti nos taux de réponses par pays, ce qui a permis de regrouper l’Australie, l’Allemagne et le Mexique pour des raisons d’anonymat.
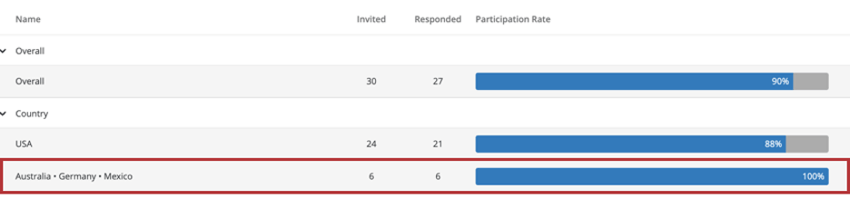
Ainsi, les widgets de taux de réponse affichent le même comportement de découpage que les autres widgets. Si le nombre de réponses est inférieur au seuil, vous ne verrez pas de données dans le résumé Widget des participants.
Lorsque l’anonymat renforcé est activé, le comportement des taux de réponses dépend du réglage au niveau de chaque champ :
- Champs non sensibles : Ces champs affichent tous les points de données, même s’ils sont inférieurs au seuil.
- Champs assez sensibles : Ces champs n’affichent que les points de données qui atteignent ou dépassent le seuil de réponses.
- Champs extrêmement sensibles : Ces champs regroupent tous les points de données inférieurs au seuil.
Paramètres d’anonymat pour l’ensemble de l’organisation
Vous pouvez définir le seuil d’anonymat pour l’ensemble de votre organisation, afin que tous les projets EX respectent les mêmes normes de confidentialité. Voir Réponses anonymes (Admin).