-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Utilisation et modification de la source de données de votre Organisation Tracker
A propos de l’utilisation et de la modification de la source de données de votre Organisation Tracker
Les programmes BX collectent des données sur votre organisation ainsi que sur les marques concurrentes et le marché dans son ensemble, ce qui rend l’ensemble de données plus complexe que les projets standard. Les programmes BX utilisent un ensemble de données empilées (Organisation Tracker Data Source, ou BTDS) pour identifier plus facilement les informations contenues dans vos données.
Comprendre la source de données BX
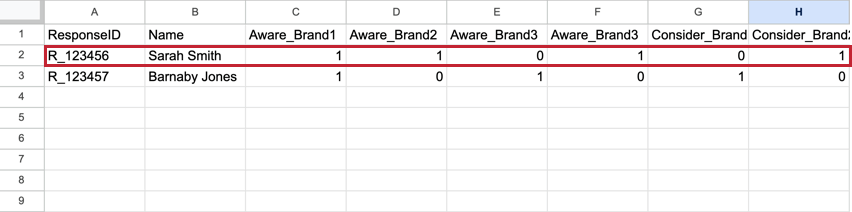
Le BTDS diffère de ce que l’on trouve dans un ensemble de données standard. Dans un ensemble de données standard, chaque personne interrogée dispose d’une ligne qui contient toutes ses réponses, la mesure de chaque organisation constituant sa propre colonne. Ces ensembles de données sont généralement très vastes et comportent des centaines de colonnes.
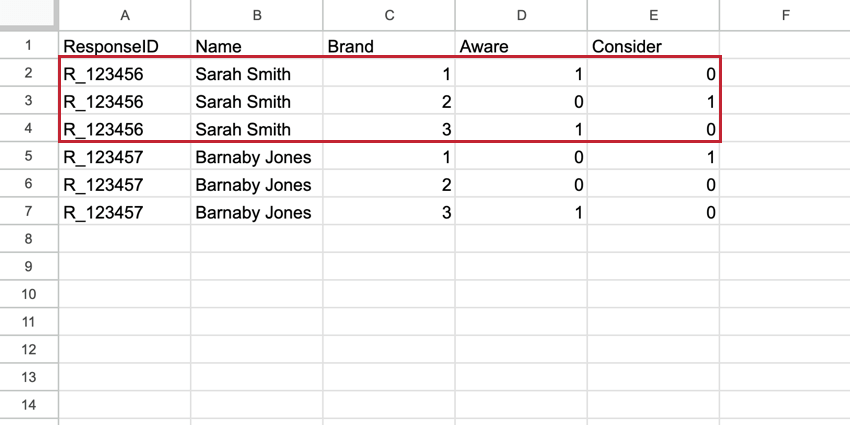
Dans le BTDS, l’Organisation devient une colonne de première classe dans l’ensemble de données et chaque répondant a une ligne pour chaque marque. La ligne de la marque contient toutes les données relatives à cette seule marque. Ces ensembles de données comportent plus de lignes que l’ensemble de données standard, mais beaucoup moins de colonnes, ce qui les rend plus faciles à lire.
RESPONSEID
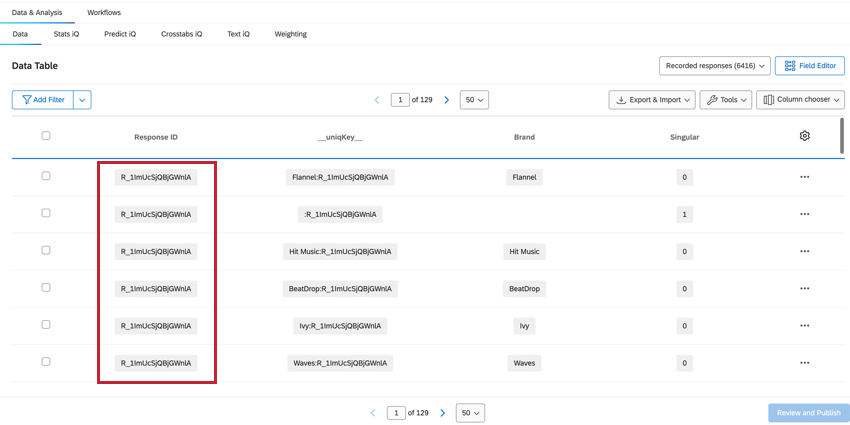
Le champ ResponseID nous aide à identifier les lignes qui appartiennent au même répondant. Cette valeur provient de l’enquête originale et est répétée pour chaque ligne appartenant à ce répondant.
SINGULAIRE
Le nombre de Réponses enregistrées dans l’onglet Données et analyse nous donnera le nombre total de toutes les lignes, qui sera supérieur au nombre total de réponses uniques. Pour déterminer les répondants uniques, nous pouvons filtrer pour le champ Singulier.
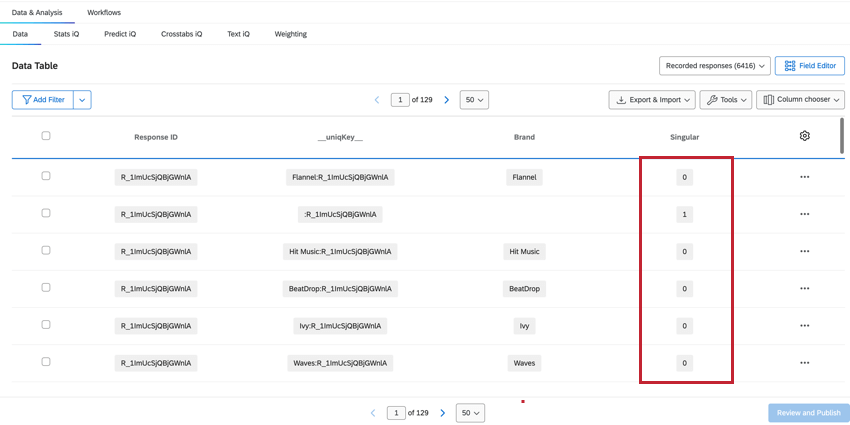
- Lorsque Singular = 1, nous obtenons des lignes de répondants uniques sans aucune information sur l’organisation. Il y a une ligne de répondant unique par réponse.
Astuce: La création d’un filtre pour Singulier = 1 affichera le nombre de répondants individuels.
- Lorsque Singular = 0, la ligne contient des données relatives à l’organisation. Il y a plusieurs lignes de données sur l’organisation pour chaque personne interrogée.
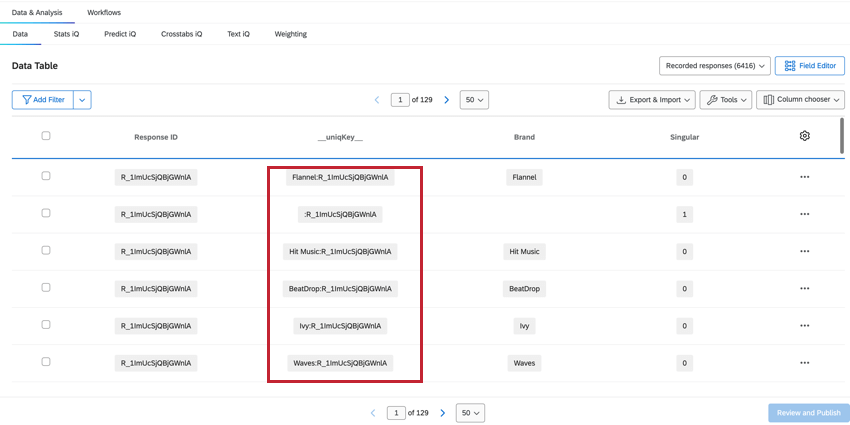
UNIQKEY
Le champ __uniqKey__ combine le ResponseID et le nom de l’organisation, sous la forme BrandName:ResponseID. Pour la ligne du répondant unique sans information sur l’organisation, la même ligne où Singular = 1, la __uniqKey__ sera :ResponseID. Cette technologie est utile pour déterminer la réponse exacte à laquelle ces données se rapportent, ainsi que l’organisation sur laquelle elles donnent des informations.
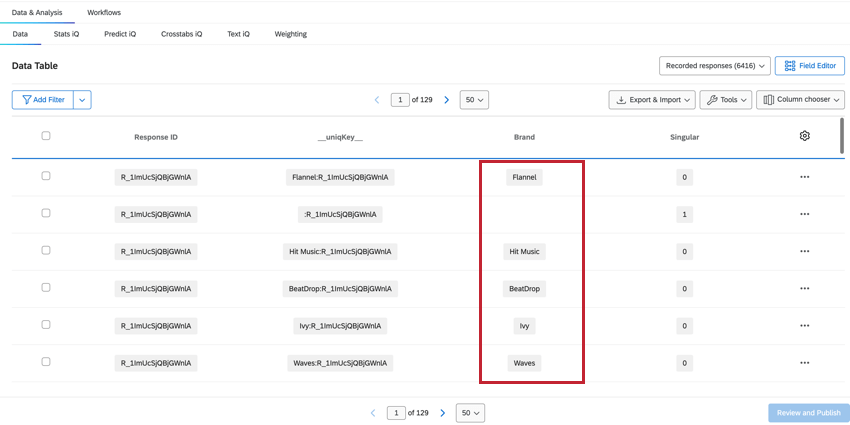
ORGANISATION
Le champ Organisation indique la marque à laquelle les données de cette colonne se réfèrent, ce qui vous permet de voir et de filtrer facilement les données relatives à la marque.
DONNÉES MULTI-SÉLECTIONNÉES PILOTÉES PAR ATTRIBUT
Les questions basées sur les attributs contiennent les marques comme choix de réponses. Il s’agit généralement de questions à choix multiples, et plusieurs colonnes contiennent des données correspondant à cette question.
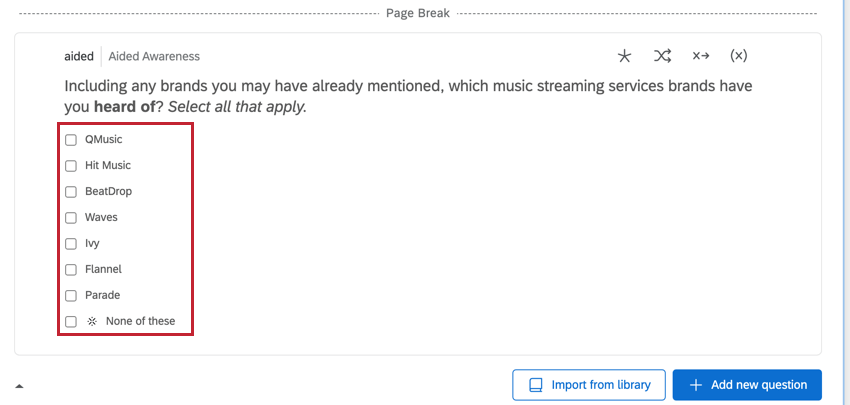
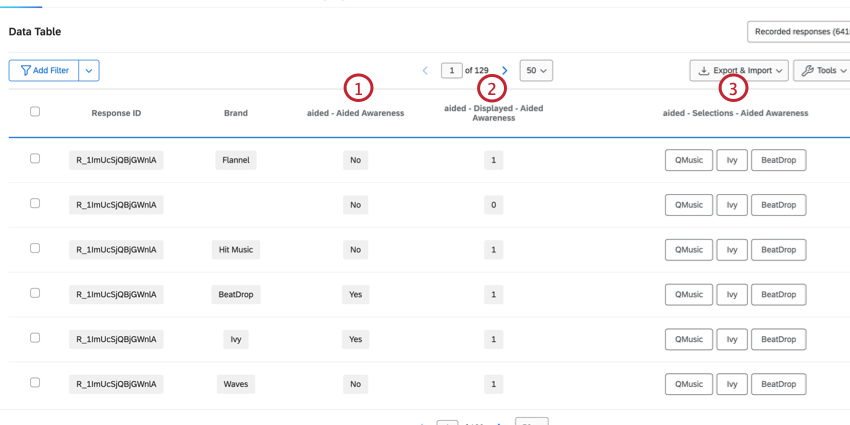
- Question: Détermine si l’organisation a été sélectionnée pour cette question. La donnée sera un 1 (“Oui”) ou un 0 (“Non”).
- Question – Affichée: Détermine si l’organisation a été affichée pour cette question. Les données seront 1 (affichées) ou 0 (non affichées).
- Question – Sélections: Contient toutes les organisations qui ont été sélectionnées pour cette question. Il y aura plusieurs valeurs dans cette colonne et la liste des valeurs sera la même pour toutes les lignes de ce répondant.
BOUCLE ET FUSION DES DONNÉES DE LA QUESTION
Il y a également plusieurs colonnes pour les questions qui introduisent le nom de l’organisation à l’aide de la boucle et de la fusion.
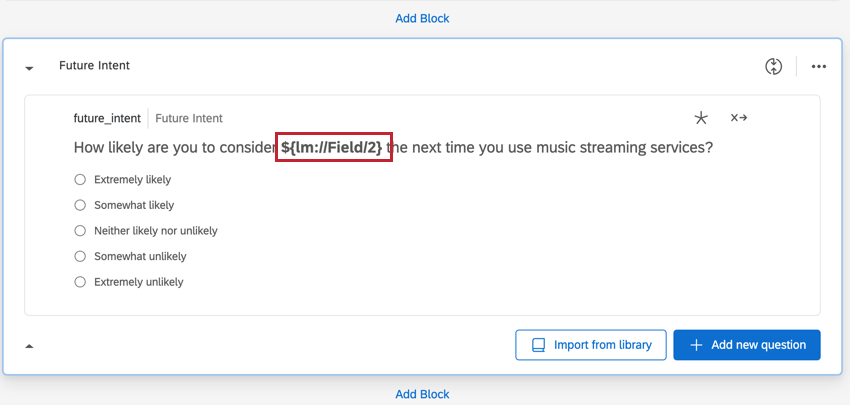
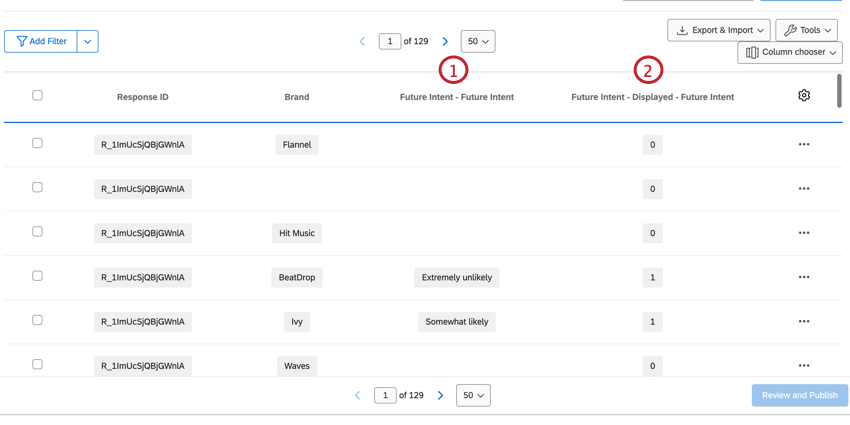
- Question: Indique le choix de réponse sélectionné pour la question.
- Question – Affichée: Détermine si l’organisation a été affichée pour cette question. Les données seront 1 (affichées) ou 0 (non affichées).
DONNÉES NON EMPILÉES
Les données non empilées ne sont pas liées à l’organisation, comme les questions standard (par exemple, les données démographiques) et les champs de données intégrés non empilés. Ces champs sont répétés pour chaque organisation, ce qui permet de conserver les informations disponibles, qu’il s’agisse d’une organisation spécifique ou de l’ensemble des organisations.
Générer le BTDS
Si vous créez un programme BX à partir de zéro, la Source de données du Suivi de l’organisation n’est pas générée automatiquement et doit l’être avant la collecte des données. Les données collectées avant la création du BTDS ne seront pas empilées.
- Créer un programme BX.
- Naviguez jusqu’à votre enquête BX.
- Saisissez le flux d’enquête.
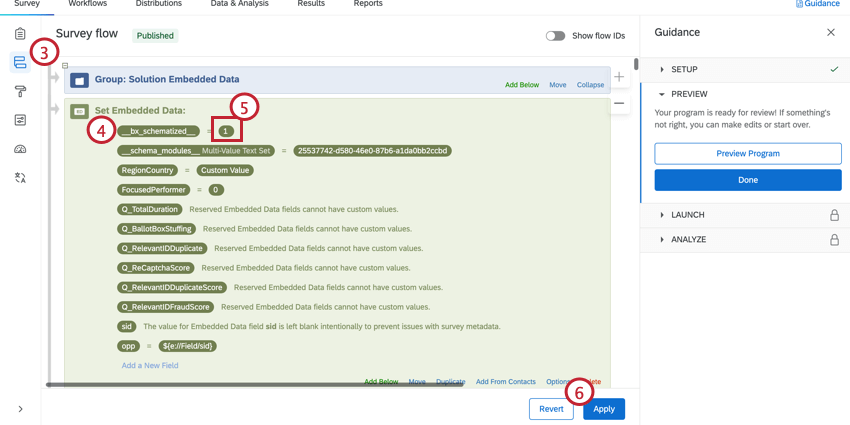
- Trouver le __bx_schematized__. Il doit s’agir du premier champ de données intégrées dans le flux d’enquête.
- Remplacer la valeur par 1.
- Cliquez sur Appliquer.
- Retournez à l’éditeur d’enquête et cliquez sur Publier pour publier votre enquête.
Compatibilité des jeux de données empilés
Les ensembles de données empilées présentent des limites quant aux types de champs et de questions qui conviennent le mieux au traitement des données. Lors de la création de votre programme BX, il est important de s’assurer que la structure de l’enquête est compatible avec les BTDS qui seront générés.
Le BTDS est compatible avec les types de questions suivants :
- Choix multiple (simple et multi-sélection)
- Saisie du texte, Matrice
- Texte descriptif
- Somme constante
- Curseur
- Ordre de classement
- Méta-informations
Filtrer et exporter le BTDS
Filtrer et exporter le BTDS fonctionne de la même manière que filtrer et exporter à partir de l’onglet Données et analyse. Ces opérations peuvent être utiles pour mieux comprendre les données du tableau de bord, réduire la taille de l’ensemble de données ou afficher des sous-sections spécifiques de l’ensemble de données empilées.
Optimisation
Les programmes BX avec de grandes listes d’organisations peuvent créer des ensembles de données plus importants que nécessaire. Grâce à l’optimisation des marques, vous pouvez limiter vos données aux seules marques significatives.
- Accédez au Flux ENQUÊTE de votre projet BX.
- Dans le bloc de données intégrées, cliquez sur Ajouter un nouveau champ.
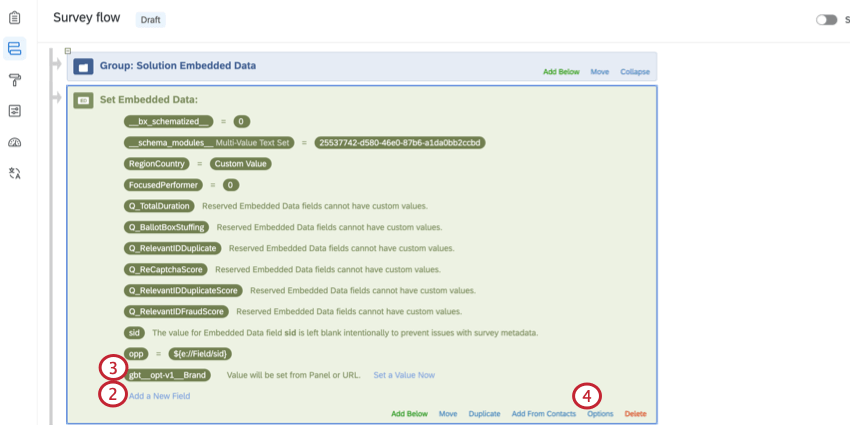
- Nom du champ
gbt__opt-v1__Brand. - Cliquez sur Options.
- Pour la variable créée à l’étape 3, sélectionnez Ensemble de textes à valeurs multiples comme type de variable.
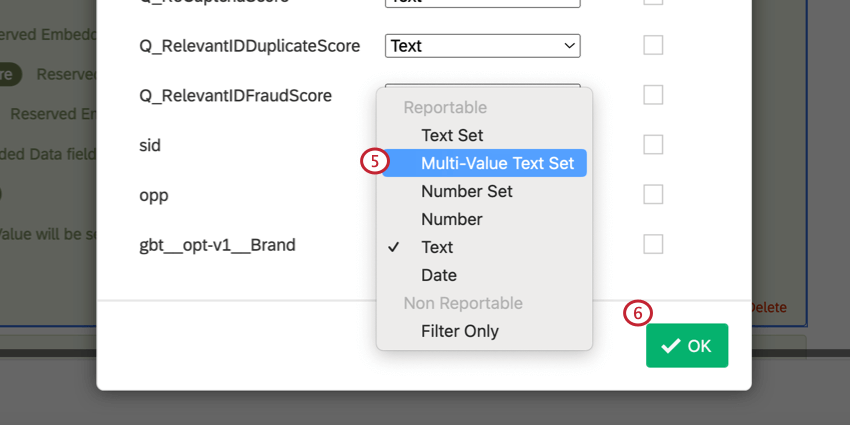
- Cliquez sur OK.
- Après la question qui définit la liste d’organisation, ajoutez une branche. Dans l’exemple ci-dessus, cette branche se trouverait après la question sur les pays.
- Cliquez sur Ajouter une condition.
- Créez la condition qui définira votre liste d’organisation. Dans l’exemple ci-dessus, il s’agirait du “Canada”.
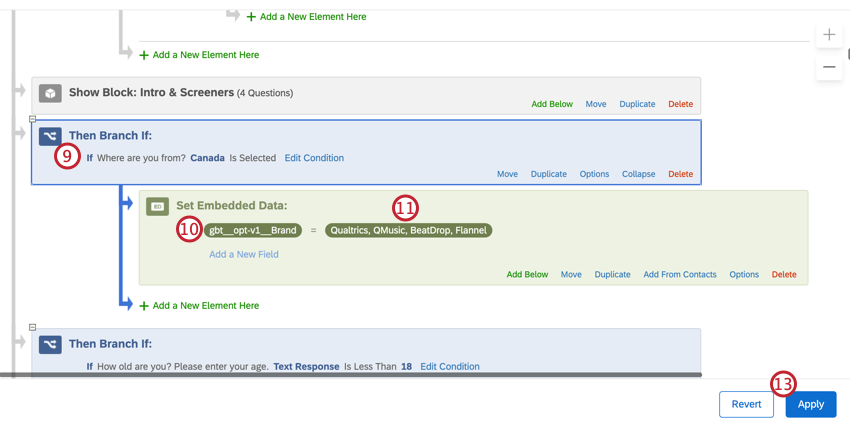
- Ajoutez la variable que vous avez créée à l’étape 3.
- Saisissez les organisations sur lesquelles vous souhaitez établir un rapport. Pour l’exemple ci-dessus, il s’agirait des 4 organisations qui intéressent le Canada.
- Répétez les étapes 7 à 9 pour les autres listes d’organisations que vous souhaitez optimiser.
- Cliquez sur Appliquer.
- Publiez votre enquête.
Lorsque la variable d’optimisation est définie, le BTDS traité supprime les lignes qui ne sont pas incluses dans la liste pour cette variable.
Dépannage avec le BTDS
Les problèmes les plus fréquents avec le BTDS sont les suivants :
- Le nombre de réponses est différent entre le BTDS et le Data & ; Analysis de l’Enquête.
- Les questions ou les champs relatifs à l’organisation ne s’empilent pas ou s’empilent de manière incorrecte après la génération du BTDS.
NOMBRE DE RÉPONSES
Pour comparer les nombres de réponses entre l’ensemble de données de l’enquête et le BTDS, filtrez le BTDS pour Singular = 1. Comparez ce nombre au nombre total dans l’ensemble de données de l’enquête. Si les données circulent correctement, ces deux chiffres doivent correspondre.
Si ces chiffres ne correspondent pas, il se peut que l’enquête contienne des éléments incompatibles. Évaluateur des meilleures pratiques des programmes BX. Si tous les composants semblent corrects, veuillez contacter le support de Qualtrics avec une liste des réponses affectées.
PAS D’EMPILAGE OU EMPILAGE INCORRECT
- Vérifiez la liste de Choix réutilisables et toutes les questions liées à l’organisation. Les noms d’organisation doivent correspondre exactement à la liste de Choix réutilisables.
- Veillez à ce qu’il n’y ait pas de sous-chaînes dans la liste des marques (par exemple, une marque “Qualtrics” et une autre “Qualtrics Employee Experience”).
- Veillez à ce que le texte de la question corresponde exactement à chaque question qui doit être empilée. Des champs de texte inséré différents dans chaque question (par exemple, un texte inséré pour différents logos par organisation) empêcheront les questions d’être empilées les unes sur les autres, ce qui est particulièrement fréquent dans les questions Matrice.
- Vérifiez les résultats de l’évaluation des experts et de l’empilage des données pour voir si des problèmes ont été signalés.