-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Analyse des correspondances (BX)
À propos de l’analyse des correspondances
L’analyse des liens révèle les liens relatifs entre et au sein de deux groupes de variables, sur la base des données figurant dans un tableau de contingence. Pour les perceptions de l’organisation, ces deux groupes sont les suivants :
- Organisations
- Attributs qui s’appliquent à ces organisations
Supposons par exemple qu’une entreprise souhaite savoir quels attributs les consommateurs associent à différentes marques de boissons. L’analyse des liens permet de mesurer les similitudes entre les organisations et la force des marques en termes de liens avec différents attributs. La compréhension des liens relatifs permet aux propriétaires de marques de mettre en évidence les effets des actions précédentes sur les différents attributs liés à la marque et de décider des mesures suivantes à prendre.
L’analyse des correspondances est précieuse dans le domaine de la perception des organisations pour plusieurs raisons. Lorsqu’on tente d’examiner les liens relatifs entre les marques et les attributs, la taille de la marque peut avoir un effet trompeur ; l’analyse des liens supprime cet effet. L’analyse des liens permet également d’obtenir une vue rapide et intuitive des liens entre les attributs de la marque (sur la base de la proximité et de la distance par rapport à l’origine), ce qui n’est pas le cas de nombreux autres graphiques.
Sur cette page, nous allons voir un exemple de la façon d’appliquer l’analyse des correspondances à un cas d’utilisation pour différentes marques (fictives) de produits de soda.
Commençons par le format des données d’entrée – un tableau de contingence.
Tableaux de contingence
Un tableau de contingence est un tableau à deux dimensions dont les lignes et les colonnes sont constituées de groupes de variables. Si nos groupes, tels que décrits ci-dessus, étaient des marques et leurs attributs associés, nous organiserions des enquêtes et obtiendrions différents nombres de réponses associant différentes marques aux attributs donnés. Chaque cellule du tableau représente le nombre de réponses ou de comptages associant cet attribut à cette organisation. Cette “association” serait mise en évidence par une question d’enquête telle que “Choisissez dans la liste ci-dessous les marques qui, selon vous, présentent ___ attribut.”
Ici, les deux groupes sont les “organisations” (lignes) et les “attributs” (colonnes). La cellule en bas à droite représente le nombre de réponses pour l’organisation “Brawndo” et l’attribut “économique”.
| Savoureux | Esthétique | Économique | |
| Bière au beurre | 5 | 7 | 2 |
| Le chat sauvage | 18 | 46 | 20 |
| Slurm | 19 | 29 | 39 |
| Boisson de levage pétillante | 12 | 40 | 49 |
| Brawndo | 3 | 7 | 16 |
Résidus (R)
Dans l’analyse des correspondances, nous voulons examiner les résidus de chaque cellule. Un résidu quantifie la différence entre les données observées et les données attendues, en supposant qu’il n’existe aucun lien entre les catégories de la ligne et de la colonne (ici, il s’agit de la marque et de l’attribut). Un résidu positif indique que le nombre de paires d’attributs de la marque est beaucoup plus élevé que prévu, ce qui suggère un lien étroit ; à l’inverse, un résidu négatif indique une valeur plus faible que prévu, ce qui suggère un lien plus faible. Voyons comment calculer ces résidus.
Un résidu (R) est égal à : R = P – E, où P représente les proportions observées et E les proportions attendues pour chaque cellule. Décortiquons ces proportions observées et attendues !
Proportions observées (P)
Une proportion observée (P) est égale à la valeur d’une cellule divisée par la somme totale de toutes les valeurs du tableau. Ainsi, pour notre tableau de contingence ci-dessus, la somme totale serait : 5 + 7 + 2 + 18 … + 16 = 312. En séparant la valeur de chaque cellule par le total, on obtient le tableau de résultats ci-dessous pour les proportions observées (P).
Par exemple, dans la cellule en bas à droite, nous avons pris notre valeur initiale de 16/312 = 0,051. Cela nous indique la proportion de l’ensemble de notre tableau que représentent les paires Brawndo et Economic sur la base des données collectées.
| Savoureux | Esthétique | Économique | |
| Bière au beurre | 0.016 | 0.022 | 0.006 |
| Le chat sauvage | 0.058 | 0.147 | 0.064 |
| Slurm | 0.061 | 0.093 | 0.125 |
| Boisson de levage pétillante | 0.038 | 0.128 | 0.157 |
| Brawndo | 0.01 | 0.022 | 0.051 |
Masse des lignes et des colonnes
Un élément que nous pouvons calculer facilement à partir des proportions observées, et qui sera très utilisé par la suite, est la somme des lignes et des colonnes de notre tableau de proportions, que l’on appelle la masse des lignes et la masse des colonnes. La masse d’une ligne ou d’une colonne est la proportion des valeurs de cette ligne/colonne. La masse de la rangée pour “Butterbeer”, en regardant notre tableau ci-dessus, serait 0,016 + 0,022 + 0,006, ce qui nous donne 0,044.
En effectuant des calculs similaires, nous obtenons
| Savoureux | Esthétique | Économique | Masses en rangée | |
| Bière au beurre | 0.016 | 0.022 | 0.006 | 0.044 |
| Le chat sauvage | 0.058 | 0.147 | 0.064 | 0.269 |
| Slurm | 0.061 | 0.093 | 0.125 | 0.279 |
| Boisson de levage pétillante | 0.038 | 0.128 | 0.157 | 0.324 |
| Brawndo | 0.01 | 0.022 | 0.051 | 0.083 |
| Masses de la colonne | 0.182 | 0.413 | 0.404 |
Proportions attendues (E)
Les proportions attendues (E) correspondent à ce que l’on s’attend à voir dans la proportion de chaque cellule, en supposant qu’il n’y a pas de lien entre les lignes et les colonnes. Notre valeur attendue pour une cellule serait la masse de la ligne de cette cellule multipliée par la masse de la colonne de cette cellule.
Dans la cellule en haut à gauche, la masse de la ligne pour Butterbeer multipliée par la masse de la colonne pour Tasty, 0,044 * 0,182 = 0,008.
| Savoureux | Esthétique | Économique | |
| Bière au beurre | 0.008 | 0.019 | 0.018 |
| Le chat sauvage | 0.049 | 0.111 | 0.109 |
| Slurm | 0.051 | 0.115 | 0.113 |
| Boisson de levage pétillante | 0.059 | 0.134 | 0.131 |
| Brawndo | 0.015 | 0.034 | 0.034 |
Nous pouvons maintenant calculer notre tableau des résidus (R), où R = P – E. Les résidus quantifient la différence entre les proportions de données observées et les proportions de données attendues, si nous supposons qu’il n’y a pas de lien entre les lignes et les colonnes.
En prenant notre valeur la plus négative de -0,045 pour Squishee et Economic, nous interpréterions ici qu’il existe une association négative entre Squishee et Economic ; Squishee est beaucoup moins susceptible d’être perçue comme “Economic” que nos autres marques de boissons.
| Savoureux | Esthétique | Économique | |
| Bière au beurre | 0.008 | 0.004 | -0.012 |
| Le chat sauvage | 0.009 | 0.036 | -0.045 |
| Slurm | 0.01 | -0.022 | 0.012 |
| Boisson de levage pétillante | -0.021 | -0.006 | 0.026 |
| Brawndo | -0.006 | -0.012 | 0.018 |
Résidus indexés (I)
La simple lecture des résidus pose toutefois certains problèmes.
En examinant la première ligne du tableau de calcul des résidus ci-dessus, nous constatons que tous ces chiffres sont très proches de zéro. Il ne faut pas en tirer la conclusion évidente que la Butterbeer n’a aucun rapport avec nos attributs, car cette hypothèse est erronée. L’explication réelle serait que les proportions observées (P) et les proportions attendues (E) sont faibles parce que, comme nous l’indique notre masse de rangée, seuls 4,4 % de l’échantillon sont des Butterbeer.
Cela soulève un problème important concernant l’examen des résidus, dans la mesure où, comme nous ne tenons pas compte du nombre réel d’enregistrements dans les lignes et les colonnes, nos résultats sont faussés en faveur des lignes/colonnes ayant les masses les plus importantes. Nous pouvons y remédier en séparant nos résidus par nos proportions attendues (E), ce qui nous donne un tableau de nos résidus indexés (I, I = R / E) :
| Savoureux | Esthétique | Économique | |
| Bière au beurre | 0.95 | 0.21 | -0.65 |
| Le chat sauvage | 0.17 | 0.32 | -0.41 |
| Slurm | 0.2 | -0.19 | 0.11 |
| Boisson de levage pétillante | -0.35 | -0.04 | 0.2 |
| Brawndo | -0.37 | -0.35 | 0.52 |
Les résidus indexés sont faciles à interpréter : plus la valeur est éloignée du tableau, plus la proportion observée est importante par rapport à la proportion attendue.
Par exemple, si l’on prend la valeur en haut à gauche, Butterbeer a 95 % plus de chances d’être perçue comme “Savoureuse” que ce à quoi on s’attendrait s’il n’y avait pas de lien entre ces marques et ces attributs. Alors qu’en haut à droite, la Butterbeer a 65 % moins de chances d’être considérée comme “économique” que ce à quoi nous nous attendrions – en l’absence de lien entre nos marques et nos attributs.
| Savoureux | Esthétique | Économique | |
| Bière au beurre | 0.95 | 0.21 | -0.65 |
| Le chat sauvage | 0.17 | 0.32 | -0.41 |
| Slurm | 0.2 | -0.19 | 0.11 |
| Boisson de levage pétillante | -0.35 | -0.04 | 0.2 |
| Brawndo | -0.37 | -0.35 | 0.52 |
Compte tenu de nos résidus indexés (I), de nos proportions attendues (E), de nos proportions observées (P) et de nos masses en ligne et en colonne, calculons les valeurs de l’analyse des correspondances pour notre graphique !
Calcul des coordonnées pour l’analyse des correspondances
Décomposition en valeurs singulières (SVD)
La première étape consiste à calculer la décomposition en valeurs singulières (SVD). L’UDS nous donne des valeurs pour calculer la variance et tracer nos lignes et nos colonnes (organisations et attributs).
Nous calculons la SVD sur le résidu standardisé (Z), où Z = I * sqrt(E), où I est notre résidu indexé et E nos proportions attendues. En multipliant par E, nous obtenons une Pondération de notre SVD, de sorte que les cellules ayant une valeur attendue plus élevée se voient attribuer une pondération plus élevée, et vice versa, ce qui signifie que, puisque les valeurs attendues sont souvent liées à la taille de l’échantillon, les “petites” cellules du tableau, où l’erreur d’échantillonnage aurait été plus importante, sont pondérées à la baisse. Ainsi, l’analyse des correspondances à l’aide d’un tableau de contingence est relativement robuste aux valeurs aberrantes causées par l’erreur d’échantillonnage.
Revenons à notre SVD, nous avons : SVD = svd(Z). Une décomposition en valeurs singulières génère 3 sorties :
Un vecteur, d, contenant les valeurs singulières.
| 1ère dimension | 2ème dimension | 3ème dimension |
| 2.65E-01 | 1.14E-01 | 4.21E-17 |
Une matrice, u, contenant les vecteurs singuliers de gauche (marques).
| 1ère dimension | 2ème dimension | 3ème dimension | |
| Bière au beurre | -0.439 | -0.424 | -0.084 |
| Le chat sauvage | -0.652 | 0.355 | -0.626 |
| Slurm | 0.16 | -0.0672 | -0.424 |
| Boisson de levage pétillante | 0.371 | 0.488 | -0.274 |
| Brawndo | 0.469 | -0.06 | -0.588 |
Une matrice, v, contenant les vecteurs singuliers de droite (attributs).
| 1ère dimension | 2ème dimension | 3ème dimension | |
| Savoureux | -0.41 | -0.81 | -0.427 |
| Esthétique | -0.489 | >0.59 | -0.643 |
| Économique | 0.77 | -0.055 | -0.635 |
Les vecteurs singuliers de gauche correspondent aux catégories dans les lignes du tableau, et les vecteurs singuliers de droite correspondent aux colonnes. Chacune des valeurs singulières, pour le calcul de la variance, et les vecteurs correspondants (c’est-à-dire les colonnes de u et v), pour le tracé des positions, correspondent à une dimension. Les coordonnées utilisées pour tracer les catégories des lignes et des colonnes de notre tableau d’analyse des correspondances sont dérivées des deux premières dimensions.
Variance exprimée par nos dimensions
Les valeurs singulières au carré sont appelées valeurs propres (d^2). Les valeurs propres dans notre exemple sont 0,0704, 0,0129 et 0,0000. L’expression de chaque valeur propre en proportion de la somme totale nous indique la quantité de variance capturée dans chaque dimension de notre analyse des correspondances, sur la base de la valeur singulière de chaque dimension ; nous obtenons 84,5 % de la variance exprimée par notre première dimension, et 15,5 % dans notre deuxième dimension (notre troisième dimension explique 0 % de la variance).
Analyse de la correspondance standard
Nous disposons maintenant des ressources nécessaires pour calculer la forme de base de l’analyse des correspondances, en utilisant ce que l’on appelle les coordonnées standard, calculées à partir de nos vecteurs singuliers gauche et droit. Auparavant, nous pondérions les résidus indexés avant d’effectuer la SVD. Afin d’obtenir des coordonnées qui représentent nos résidus indexés, nous devons maintenant dépondérer les résultats de la SVD, en divisant chaque ligne des vecteurs singuliers de gauche par la racine carrée des masses des lignes, et en divisant chaque colonne des vecteurs singuliers de droite par la racine carrée des masses des colonnes, ce qui nous permet d’obtenir les coordonnées standard des lignes et des colonnes pour le tracé.
Coordonnées standard de l’Organisation :
| 1ère dimension | 2ème dimension | 3ème dimension | |
| Bière au beurre | -2.07 | -2 | -0.4 |
| Le chat sauvage | -1.27 | 0.68 | -1.21 |
| Slurm | 0.3 | -1.27 | -0.8 |
| Boisson de levage pétillante | 0.65 | 0.86 | -0.48 |
| Brawndo | 1.62 | -0.21 | -2.04 |
Attribut Standard Coordinates :
| 1ère dimension | 2ème dimension | 3ème dimension | |
| Savoureux | -0.96 | -1.89 | -1 |
| Esthétique | -0.76 | 0.92 | >-1 |
| Économique | 1.21 | -0.09 | -1 |
Nous utilisons les deux dimensions pour lesquelles la variance capturée est la plus élevée pour le tracé, la première dimension étant placée sur l’axe X et la seconde sur l’axe Y, ce qui génère notre graphique standard d’analyse des correspondances.
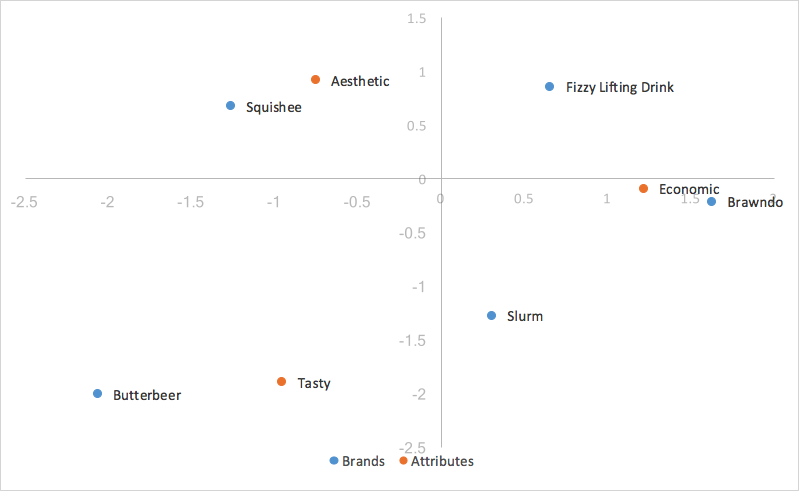
Dans la section suivante, nous examinerons les avantages et les inconvénients des différents styles d’analyse des correspondances et nous verrons lequel convient le mieux à notre objectif d’aider à l’analyse de la perception des organisations.
Types d’analyse des correspondances
Analyse principale des correspondances ligne/colonne
L’analyse standard des correspondances est facile à calculer et des résultats solides peuvent en être tirés. Cependant, la correspondance standard est un mauvais choix pour nos besoins ; les distances entre les coordonnées des lignes et des colonnes sont exagérées, et il n’y a pas d’interprétation directe des liens entre les catégories des lignes et des colonnes. Ce que nous voulons pour interpréter les liens entre les coordonnées des lignes (marques) et interpréter les liens entre les catégories des lignes et des colonnes, c’est la normalisation principale des lignes (ou, si nos marques se trouvaient sur nos colonnes, la normalisation principale des colonnes).
Pour la normalisation principale des lignes, vous voulez utiliser les coordonnées standard calculées ci-dessus pour les valeurs de vos colonnes (attributs), mais vous voulez calculer les coordonnées principales pour les valeurs de vos lignes (organisations). Pour calculer les coordonnées principales, il suffit de prendre les coordonnées standard et de les multiplier par les valeurs singulières correspondantes (d). Pour nos lignes, il suffit donc de multiplier nos coordonnées de ligne standard par nos valeurs singulières (d), comme indiqué dans le tableau ci-dessous. Pour la normalisation du principal des colonnes, il suffit de multiplier nos colonnes au lieu de nos lignes par nos valeurs singulières (d).
| 1ère dimension | 2ème dimension | 3ème dimension | |
| Bière au beurre | -0.55 | -0.23 | 0 |
| Le chat sauvage | -0.33 | 0.08 | 0 |
| Slurm | 0.08 | -0.14 | 0 |
| Boisson de levage pétillante | 0.17 | 0.1 | 0 |
| Brawndo | 0.43 | -0.02 | 0 |
En remplaçant les coordonnées principales de nos lignes (marques), nous obtenons :
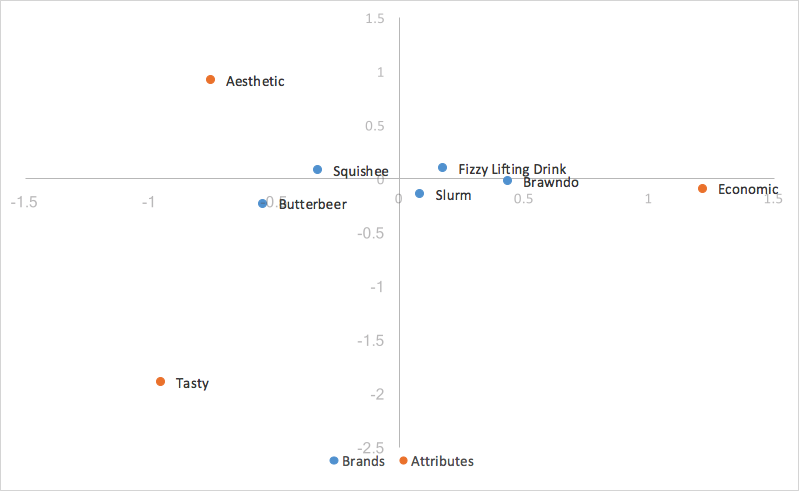
Étant donné que nous avons mis à l’échelle nos valeurs singulières, les coordonnées principales de nos lignes représentent la distance entre les profils des lignes de notre tableau original ; on peut interpréter les liens entre les coordonnées de nos lignes dans notre tableau d’analyse des correspondances en fonction de la proximité des unes par rapport aux autres.
La distance entre les coordonnées de nos colonnes, étant donné qu’elles sont basées sur des coordonnées standard, est encore exagérée. En outre, notre mise à l’échelle par nos valeurs singulières dans une seule des deux catégories (lignes/colonnes) nous a donné un moyen d’interpréter les liens entre les catégories de lignes et de colonnes. Étant donné une valeur de ligne et une valeur de colonne, par exemple, Butterbeer (ligne) et Tasty (colonne), plus leur distance par rapport à l’origine est grande, plus leur association avec d’autres points de la carte est forte. En outre, plus l’angle entre les deux points (Butterbeer et Tasty) est faible, plus la corrélation entre les deux est élevée.
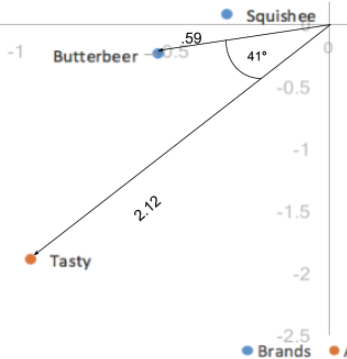
La distance à l’origine combinée à l’angle entre les deux points équivaut au produit de points ; le produit de points entre une valeur de ligne et une valeur de colonne mesure la force de l’association entre les deux. En effet, lorsque la première et la deuxième dimension expliquent toute la variance des données (100 %), le produit en points est directement égal au résidu indexé des deux catégories. Ici, le produit en points serait la distance à l’origine des deux points multipliée par le cosinus de l’angle qui les sépare ; 0,59*2,12*cos(41) = 0,94. Compte tenu des erreurs d’arrondi, elle est identique à notre valeur résiduelle indexée de 0,95. Ainsi, les angles inférieurs à 90 degrés représentent un résidu indexé positif et donc une association positive, et les angles supérieurs à 90 degrés représentent un résidu indexé négatif ou une association négative.
Analyse des correspondances principales par rangées échelonnées
En regardant notre graphique ci-dessus pour la normalisation du principal des lignes, nous faisons une observation facile – les points de nos colonnes (traits) sont beaucoup plus étalés, et les points de nos lignes (marques) sont clusterisés autour de l’origine. Cela peut rendre l’analyse de notre graphique difficile et peu intuitive, et il est parfois impossible de lire les catégories de lignes si elles se chevauchent toutes. Heureusement, il existe un moyen simple de mettre à l’échelle notre graphique pour y intégrer nos colonnes, tout en conservant la possibilité d’utiliser le produit de points (distance par rapport à l’origine et angle entre les points) pour analyser les liens entre les points de nos lignes et de nos colonnes, ce que l’on appelle la normalisation des lignes à l’échelle.
La normalisation du principal de la ligne prend la normalisation du principal de la ligne et met à l’échelle les coordonnées de la colonne de la même manière que nous avons mis à l’échelle l’axe x des coordonnées de la ligne – en d’autres termes, nos coordonnées de la colonne sont mises à l’échelle par la première valeur de nos valeurs singulières (d). Nos valeurs de ligne restent les mêmes que celles de la normalisation principale de ligne, mais nos coordonnées de colonne sont maintenant réduites d’un facteur constant.
| 1ère dimension | 2ème dimension | 3ème dimension | |
| Savoureux | -0.2544 | -0.501 | -0.265 |
| Esthétique | -0.201 | 0.2438 | -0.265 |
| Économique | 0.321 | -0.02 | -0.265 |
Cela signifie pour nous que les coordonnées de nos colonnes sont mieux adaptées aux coordonnées de nos lignes, ce qui facilite grandement l’analyse des tendances. Comme nous avons mis à l’échelle toutes les coordonnées de nos colonnes par le même facteur constant, nous avons réduit la dispersion des coordonnées de nos colonnes sur la carte, mais nous n’avons rien changé à leurs relativités ; nous utilisons toujours le produit de points pour mesurer la force des associations. Le seul changement est que lorsque nos première et deuxième dimensions couvrent toute la variance des données, au lieu que le résidu indexé soit égal au produit de points des deux catégories, il est maintenant égal au produit de points échelonné des deux catégories, qui est le produit de points échelonné par une valeur constante de notre première valeur singulière (d). L’interprétation du graphique reste la même que pour la normalisation de la ligne principale.
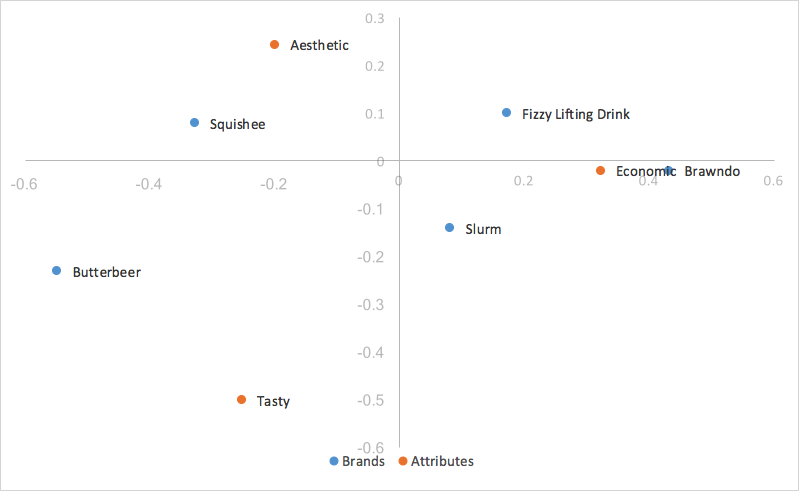
Analyse des correspondances principales
Une dernière forme d’analyse des correspondances que nous mentionnerons est l’analyse des correspondances principales, également connue sous le nom de carte symétrique, d’échelle française ou d’analyse canonique des correspondances. Au lieu de multiplier uniquement les lignes ou les colonnes standard par les valeurs singulières(d) comme dans l’analyse des correspondances principales ligne/colonne, nous multiplions les deux par les valeurs singulières. Les valeurs standard des colonnes, multipliées par les valeurs singulières, sont donc les suivantes :
| 1ère dimension | 2ème dimension | 3ème dimension | |
| Savoureux | -0.2544 | -0.215 | 0 |
| Esthétique | -0.201 | 0.105 | 0 |
| Économique | 0.321 | -0.01 | 0 |
En combinant ces valeurs avec les valeurs des lignes calculées dans l’analyse principale des lignes, nous obtenons :
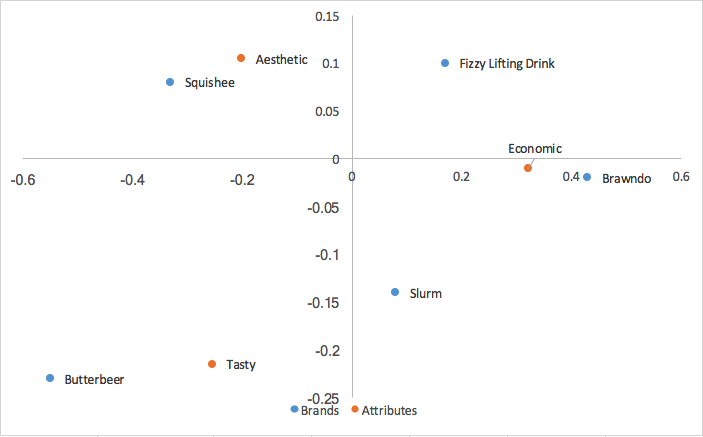
L’analyse canonique des correspondances met à l’échelle les coordonnées des lignes et des colonnes en fonction des valeurs singulières. Cela signifie que nous pouvons interpréter les liens entre nos coordonnées de ligne comme nous l’avons fait dans l’analyse des correspondances principales de ligne (basée sur la proximité), ET que nous pouvons interpréter les liens entre nos coordonnées de colonne comme dans l’analyse des correspondances principales de colonne ; nous pouvons analyser les liens entre les organisations et les liens entre les attributs. Nous perdons également le clustering ligne/colonne au centre de la carte issu de l’analyse principale ligne/colonne. Cependant, ce que nous perdons de l’analyse canonique des correspondances, c’est un moyen d’interpréter les liens entre nos organisations et leurs attributs, ce qui est très utile pour la perception des marques.
Comparaison Côte à côte
Analyse standard des correspondances
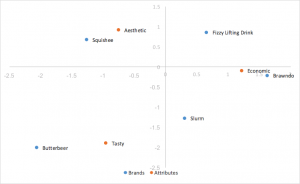
Le style d’analyse des correspondances le plus facile à calculer, utilisant les vecteurs singuliers gauche et droit de la SVD séparés par les masses des lignes et des colonnes. Les distances entre les coordonnées des lignes et des colonnes sont exagérées et il n’y a pas d’interprétation directe des liens entre les catégories des lignes et des colonnes.
Normalisation de la rangée principale Analyse des correspondances
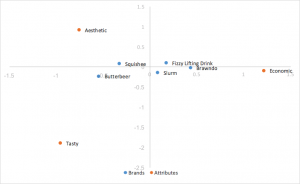
Utilise les coordonnées standard ci-dessus, mais multiplie les coordonnées des lignes par les valeurs singulières pour les normaliser. Les liens entre les lignes (organisations) sont basés sur la distance qui les sépare. Les distances entre les colonnes (attributs) sont encore exagérées. Les liens entre les lignes et les colonnes peuvent être interprétés par le produit de points. Les rangs (organisations) ont tendance à être regroupés au centre.
Normalisation des rangs par la méthode principale Analyse des correspondances
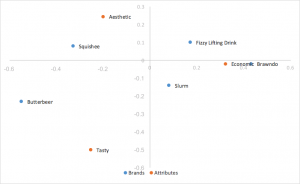
Prend la normalisation principale de la ligne et échelonne les coordonnées de la colonne par une constante de la première valeur singulière. Mêmes interprétations que pour la normalisation principale des rangées, en remplaçant le produit de points par un produit de points échelonné. Permet d’éviter que les rangs ne s’agglutinent au centre. C’est le style d’analyse des correspondances que nous préférons.
Analyse des correspondances par normalisation principale (symétrique, carte française, canonique)
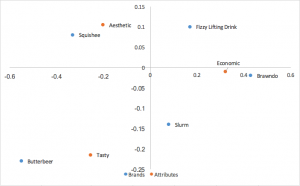
Une autre forme populaire d’analyse des correspondances utilise les coordonnées principales normalisées dans les lignes et les colonnes. Les liens entre les lignes (organisations) peuvent être interprétés en fonction de la distance qui les sépare ; il en va de même pour les colonnes (attributs). Aucune interprétation ne peut être tirée des liens entre les lignes et les colonnes.
Conclusion
En conclusion, l’analyse des correspondances est utilisée pour analyser les liens relatifs entre et au sein de deux groupes ; dans notre cas, ces groupes seraient les organisations et les attributs.
L’analyse des correspondances élimine l’asymétrie des résultats provenant de masses différentes entre les groupes en utilisant des résidus indexés. En ce qui concerne les perceptions des marques pour l’analyse des correspondances, nous utilisons la normalisation principale des lignes (ou principale des colonnes si les marques sont placées sur les colonnes), car cela nous permet d’analyser les liens entre les différentes marques en fonction de leur proximité les unes par rapport aux autres, et nous permet également d’analyser les liens entre les marques et les attributs en fonction de leur distance par rapport à l’origine combinée à l’angle entre eux et l’origine (le produit de points), au risque de mal représenter le lien entre les attributs avec des distances exagérées (ce qui n’a pas d’importance pour nous car nous ne nous intéressons pas aux liens entre les attributs). Nous utilisons la normalisation principale ligne/colonne à l’échelle pour faciliter l’analyse de notre graphique sans frais. N’oublions pas que nous additionnons la variance expliquée à partir des étiquettes des axes X et Y (la première et la deuxième dimension) pour afficher la variance totale capturée dans la cartographique ; plus ce nombre est faible, plus il y a de variance inexpliquée dans les données, et plus l’affichage cartographique est trompeur.
Une dernière chose à retenir est que l’analyse des correspondances ne montre que des relativités puisque nous avons éliminé le facteur de masse de nos données ; notre graphique ne nous dira rien sur les marques qui ont les notations les plus “élevées” en termes d’attributs. Une fois que vous avez compris comment créer et analyser les graphiques, l’analyse des correspondances est un outil puissant qui ne tient pas compte des effets de dimensionnement des marques pour fournir des informations puissantes et faciles à interpréter sur les liens entre et au sein des marques et de leurs attributs applicables.