-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Filtrado por datos estructurados (Diseñador)
Acerca del filtrado por datos estructurados
Utilice atributos de datos estructurados para filtro los opinión en modelos que categorizan y muestran la información más relevante de su conjunto de datos. Para obtener información sobre cómo crear y editar filtros, consulte Filtrado de datos (Diseñador).
Filtrado por Sentimiento
XM Discover utiliza el análisis de sentimiento para determinar el sentimiento general de los opinión. El Sentimiento está disponible como un atributo del sistema con bandas predefinidas:
- Sentimiento negativo: Opinión con una puntuación de sentimiento de -5,0 a -1,0
- Sentimiento neutral: Opinión con una puntuación de sentimiento de -0,99 a 0,99
- Sentimiento positivo: Opinión con una puntuación de sentimiento de 1 a 5,0
Filtrar por idioma
Utilice los siguientes atributos del sistema de discover para filtro por tipo de datos:
- Idioma detectado automáticamente por CB ( _idioma detectado ): Los opinión sobre el idioma se enviaron si su proyecto utiliza detección automática de idioma.
- Lenguaje procesado CB ( _idioma ): Los opinión sobre el idioma se enviaron en. Si el idioma no es compatible con XM Discover, se marcará como “OTRO”.
XM Discover es capaz de reconocer y etiquetar datos con más de 150 idiomas utilizando la función de Detección automática de idioma. Sin detección automática de idioma, están disponibles los siguientes idiomas:
- Árabe
- Bengalí
- Chino (simplificado y tradicional)
- Neerlandés
- Inglés
- Francés
- Alemán
- Hindi
- Indonesio
- Italiano
- Japonés
- Coreano
- Polaco
- Portugués
- Rumano
- Ruso
- Español
- Sueco
- Tagalo
- Tailandés
- Turco
- Vietnamita
Filtrado por tipo de datos
Para filtro los opinión según el tipo de datos enviados, utilice los siguientes atributos del sistema:
- Identificación de la fuente ( _id_fuente ): La fuente de datos de las oraciones.
- Tipo Verbatim ( _tipo literal ): El nombre del campo textual por el que desea filtro . Esto es útil si tiene varias columnas textuales.
Filtrado por tipo de contenido
Para los proyectos con detección de tipo de contenido habilitada, use los siguientes atributos del sistema para filtro opinión de anuncios, spam y otros datos no procesables:
- Tipo de contenido CB ( tipo_contenido_cb ): Si los documentos están marcados como con contenido, es decir, que contienen contenido, o sin contenido.
- Subtipo de contenido CB ( subtipo de contenido cb ): Agrupa los documentos marcados como sin contenido en anuncios, cupones, enlaces a artículos o “indefinidos”.
Filtrar por tipo de oración
XM Discover utiliza análisis semántico para identificar intenciones que sean relevantes para sus análisis. Estas categorías se utilizan en el atributo del sistema a nivel de oración: Tipo de oración CB ( tipo_de_oración_cb ). Analizar el tipo de intención utilizada en sus datos puede ayudar a comprender cómo se puede mejorar la experiencia del cliente .
Haga clic en los siguientes tipos de oraciones para ver qué se identifica utilizando el atributo de tipo de oración:
- Sentencias procesables
- Sugerencias y recomendaciones sobre cómo mejorar la experiencia del cliente, así como temas que requieren atención inmediata.
- Batir: Amenaza de perder clientes.
- Grito de ayuda: Solicita ayuda y asistencia.
- Pedido:Contiene una solicitud implícita o explícita, como un llamado a la acción o información.
- Sugerencia: Contiene una sugerencia implícita o explícita para cambiar algo.
- Tenencia:Cuánto tiempo ha utilizado un cliente un servicio o producto.
- Cancelación:Contiene una amenaza o intención de cancelar su membresía, servicio u otra transacción. Este tipo también captura la no renovación, la cancelación de la inscripción o la terminación.
- Oraciones relacionadas con los sentimientos
- Identifica el sentimiento de las oraciones que carecen de recomendaciones prácticas.
- Apático:No expresa ningún interés ni preocupación.
- Negativo genérico: sentimiento negativo que carece de un objetivo específico.
- Elogio genérico: sentimiento positivo que carece de un objetivo específico.
- Recomendar:Recomienda la experiencia de este cliente.
- No recomendado: Desaconseja la experiencia de este cliente.
- Oraciones de pregunta/respuesta
- Tipos de opinión al responder preguntas de la encuesta .
- Disculpa:Contiene una disculpa explícita.
- Referencia cruzada:Hace referencia a un comentario anterior o una respuesta.
- No lo sé: Los Opinión no pueden proporcionar una respuesta. Por ejemplo, “Ojalá lo supiera”.
- Todo:Respuestas que cubren todas las opciones sugeridas.
- Lista:Contiene una lista de elementos.
- Sin comentarios:El encuestado se niega a comentar o dejar una respuesta. Por ejemplo, “N/A”.
- Sí:Contiene afirmaciones genéricas.
- Oraciones de observación social
- Opinión relacionados con los aspectos sociales de la interacción con el cliente, como saludos, risas y gratitud.
- Hola/Adiós:Saludos y despedidas.
- Risa:Expresiones de risa, ya sea verbalmente o mediante el uso de emojis. Por ejemplo, “¡Jaja! xD”.
- Gracias:Expresiones de gratitud.
- Oraciones de divulgación legal
- Opinión que contienen información legal.
- Divulgación:Contiene declaraciones de divulgación. Por ejemplo, “Esta llamada puede ser monitoreada o grabada”.
- Mini Miranda:Aplicable en Estados Unidos, contiene una advertencia legal Mini-Miranda. Por ejemplo, “El propósito de la comunicación es cobrar una deuda”.
- Oraciones específicas de una conversación
- Opinión específicos sobre las conversaciones del centro de contacto . Estos tipos de oraciones solo están disponibles con datos conversacionales.
- Empatía:Se expresa empatía, como disculparse, demostrar interés o reconocer las dificultades.
- Sostener: Los clientes quedan en espera.
- Transferir:Los clientes solicitan ser transferidos o los representantes transfieren a un cliente.
Filtrar por recuento de palabras
Utilice los atributos de recuento de palabras de la oración o del documento para filtro sus datos por la cantidad de palabras en su oración o registro. El rango establecido en estos atributos incluye valores. Si el recuento de palabras es cero, la oración/registro no tiene texto o se cargó antes de que se habilitara la función .
- Recuento de palabras de la oración CB ( recuento_de_palabras_de_la_oración_cb ): El atributo a nivel de oración le permite filtro datos por la cantidad de palabras en una oración.
Consejo Q:Para ver oraciones con 10 palabras o menos, use el rango recuento_de_palabras_de_la_sentencia_cb: [1 A 10].
- Recuento de palabras del documento CB ( recuento de palabras del documento cb ): El atributo a nivel de registro le permite filtro datos por la cantidad de palabras en un registro. Esta es también la suma del número de palabras de todas las oraciones.
Consejo Q:Para ver registros con 50 palabras o más, utilice recuento de palabras del documento cb: [50 a 200].
Filtrado por cuartil de oración
El Cuartil de oración CB ( cuartil_de_oración_cb ) El atributo identifica la parte del texto literal a la que sigue una oración. Los valores son de 1 a 4, y cada sección representa el 25% de la longitud del texto literal. Si un registro tiene múltiples verbatims, habrá cuartiles para cada verbatim en el registro.
Aplicación del cuartil de oraciones
Si a sus datos históricos les faltan datos de cuartiles de oraciones, puede agregarlos a sus datos.
- Navegar hasta el Clasificar por categorías pestaña de su proyecto.
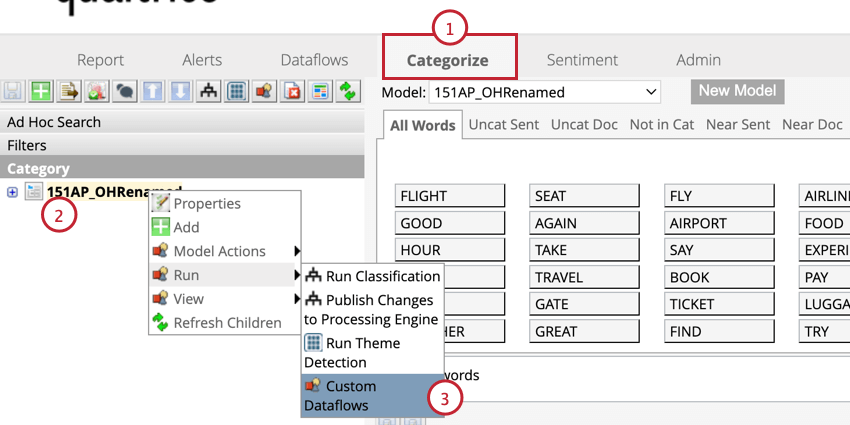
- Haga clic derecho en un modelo de categoría.
- Pase el cursor sobre Correr y seleccione Flujos de datos personalizados .
- Elegir Reprocesar atributos derivados del lenguaje.
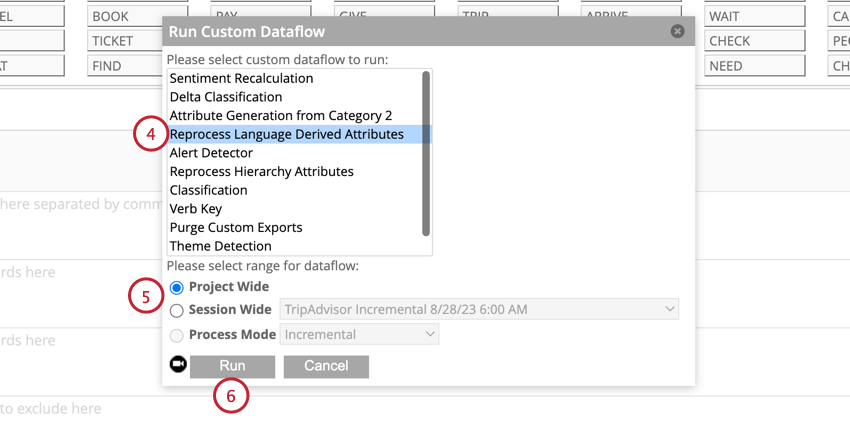
- Seleccione si desea procesar todos los datos del proyecto o los datos de una sesión específica.
- Hacer clic Correr.
Filtrado por esfuerzo
Esfuerzo del CB mide el nivel de esfuerzo expresado por los clientes durante su experiencia. Este atributo está disponible a nivel de oración en una escala de -5 a 5, donde -5 indica la experiencia más difícil y 5 indica la experiencia más fácil. El rango incluye valores.
Filtrar por duración de la lealtad
Duración de la lealtad del CB Le permite filtro datos según el período en años que un cliente ha utilizado un servicio o ha tenido un producto. Este atributo está disponible a nivel de oración en oraciones con el tipo de oración de tenencia. El rango incluye valores.
Filtrado por tipo de interacción
Tipo de interacción CB ( tipo_interacción_cb ) define los datos según el tipo de interacción XM , lo que permite distinguir la opinión regular de los datos conversacionales. Este atributo está disponible a nivel de documento, texto textual y oración.
El tipo de interacción puede tener los siguientes valores:
- Charlar:Datos conversacionales de canales digitales.
- Opinión:Datos de opinión regulares (como encuestas, reseñas, etc.).
- Voz:Datos conversacionales de conversaciones transcritas en audio.