-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Conector de entrada para carga de archivos ad hoc
Acerca del conector de entrada de carga de archivos ad hoc
Puede utilizar el conector entrante de carga de archivos ad-hoc para cargar datos del cliente a través de una carga de archivo. Los trabajos de carga de archivos ad-hoc ocurren una sola vez y cada trabajo debe programarse por separado.
Los trabajos de archivos ad-hoc le permiten cargar datos en las siguientes formatos :
- Archivos de texto delimitados planos (CSV, TSV, etc.)
- XLS o XLSX
- JSON
- WebVTT
Configuración de un trabajo de carga de archivos ad hoc
Consejo Q: “Gestionar trabajos” permiso Es necesario para utilizar esta función.
- En la pestaña Trabajos, haga clic en Nuevo trabajo .
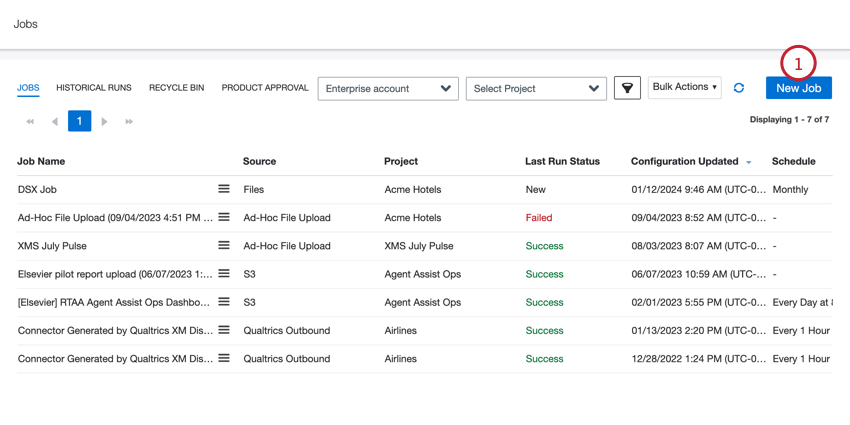
- Seleccionar Carga de archivos ad hoc .

- Dale un nombre a tu trabajo para que puedas identificarlo.
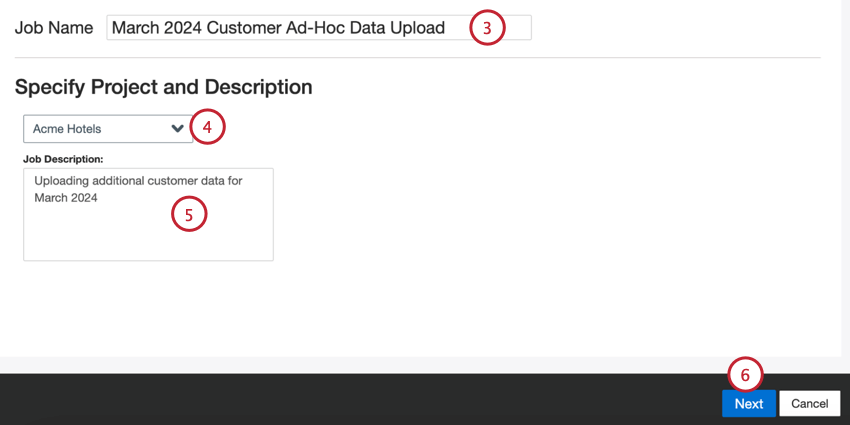
- Seleccione el proyecto en el que desea cargar datos.
- Dale una descripción a tu trabajo para que conozcas su propósito.
- Haga clic en Siguiente.
- Elige el tipo de archivo que deseas cargar:
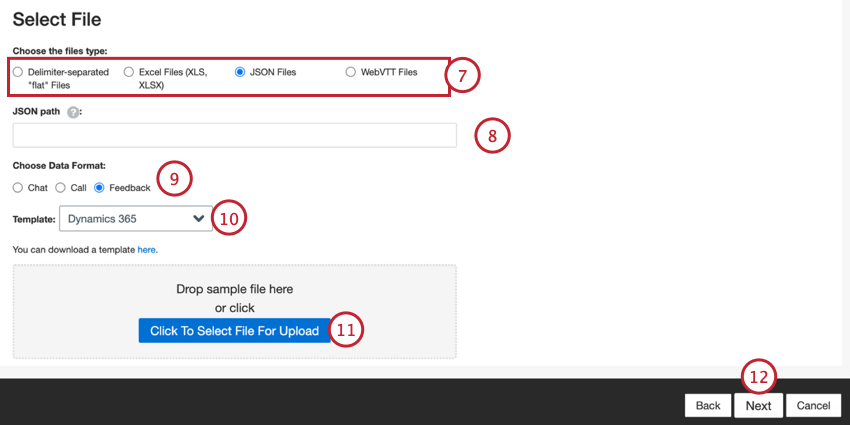
- Archivos “planos” separados por delimitadores
- Archivos de Excel (XLS, XLSX)
- Archivos JSON
- Archivos WebVTT
- Dependiendo del tipo de archivo seleccionado, complete las configuraciones de archivo adicionales:
- Archivos planos separados por delimitadores :Para archivos separados por delimitadores, elija lo siguiente:
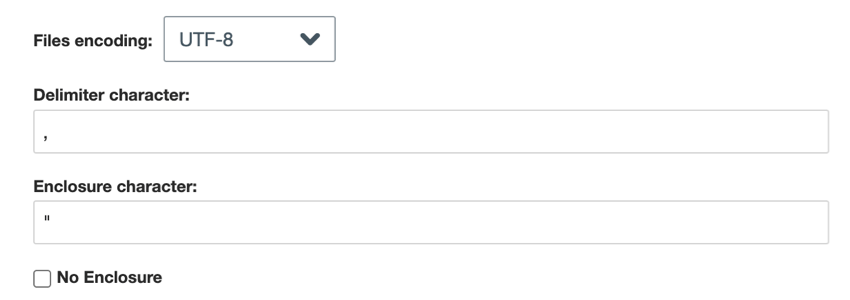
- Codificación de archivos : Elija el sistema de codificación del archivo (UTF-8, ASCII, etc.).
- Carácter delimitador :Introduzca el carácter utilizado para delimitar las entradas de datos. De forma predeterminada, se trata de una coma para los archivos CSV .
- Carácter de recinto :Introduzca el carácter que encierra la entrada de datos. Deje este campo en blanco si Sin recinto está seleccionado
- Sin recinto :Habilite esta opción si su archivo no contiene caracteres adjuntos.
- JSON :Ingresa el Ruta JSON que contiene los datos del documento que desea cargar en XM Discover. Deje este campo en blanco si sus documentos están en el nivel raíz.

- Saltar al siguiente paso para Excel y WebVTT archivos.
- Archivos planos separados por delimitadores :Para archivos separados por delimitadores, elija lo siguiente:
- Elija el tipo de datos que desea importar:
- Charlar :Interacciones digitales con múltiples líneas de diálogo entre 2 o más participantes.
- Llamar : Transcripciones de llamadas con múltiples líneas de diálogo entre 2 o más participantes.
- Opinión :Documentos presentados como objetos de una sola fila o “planos”.
Consejo Q: Dependiendo del tipo de archivo, algunos tipos de datos no son compatibles. Por ejemplo, los archivos WebVTT solo se pueden usar para cargar transcripciones de llamadas.
- Si es necesario, puede seleccionar una Plantilla archivo para descargar. Haga clic en el aquí Enlace para descargar la plantilla seleccionada. Utilice este archivo para agregar los datos que desea importar a XM Discover. Ver el Formatos de datos de XM Discover Página de soporte para obtener información de formato específica sobre cada archivo y tipo de datos.
- Haga clic en el Haga clic aquí para seleccionar el archivo que desea cargar Botón y selecciona tu archivo en tu computadora. Sus datos aparecerán como una vista previa en la parte inferior de la página.
Consejo Q: Ver Errores de archivos de Muestra Si necesita ayuda para solucionar problemas con su archivo de carga.
- Haga clic en Siguiente.
- Si es necesario, ajuste su asignaciones de datos . Ver el Soporte de mapeo de datos página para obtener información detallada sobre el mapeo de campos en XM Discover. El Asignación de datos predeterminada La sección tiene información sobre los campos específicos de este conector y la Campos de conversación Esta sección cubre cómo mapear datos para datos conversacionales.
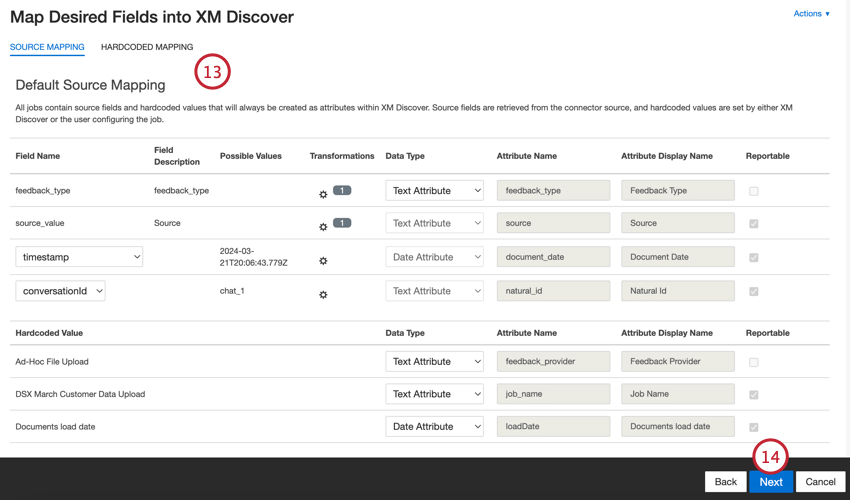
- Haga clic en Siguiente.
- Si lo desea, puede agregar Reglas de sustitución y redacción de datos para ocultar datos confidenciales o reemplazar automáticamente ciertas palabras y frases en los opinión e interacciones de los clientes. Ver el Sustitución y redacción de datos Página de soporte para obtener más información.
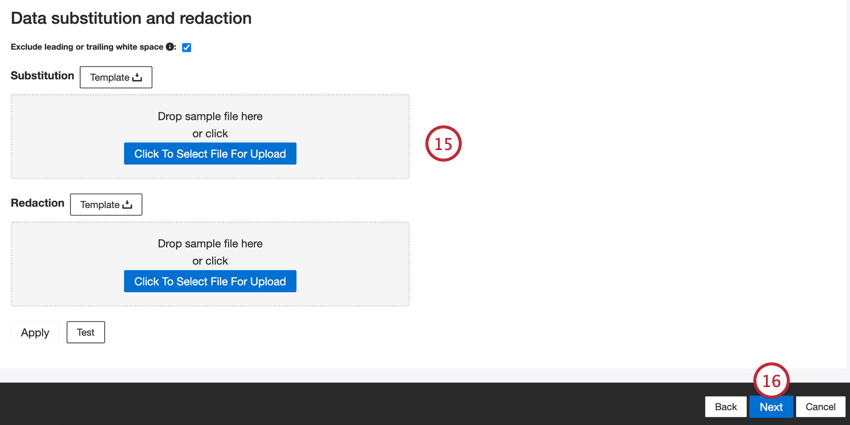
- Haga clic en Siguiente.
- Si lo desea, puede agregar un filtro de conector para filtro los datos entrantes y limitar qué datos se importan.
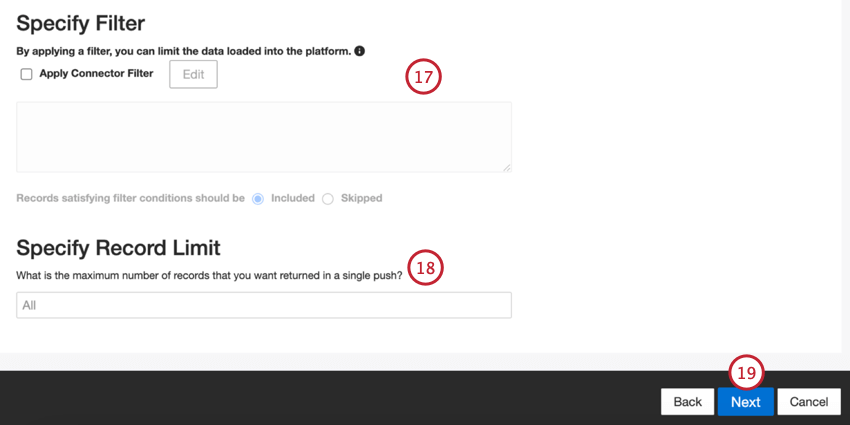
- También puedes limitar el número de registros importado en un solo trabajo ingresando un número en el Especificar límite de registro caja. Introduzca “Todos” si desea importar todos los registros.
Consejo Q: Para los datos conversacionales, el límite se aplica en función de las conversaciones en lugar de las filas.
- Haga clic en Siguiente.
- Elige cuándo quieres recibir notificaciones. Ver Notificaciones de trabajo Para más información.
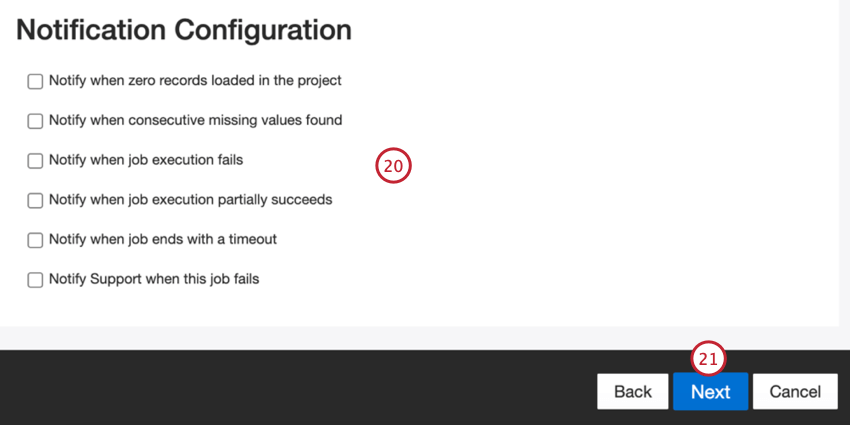
- Haga clic en Siguiente.
- Elija cómo se gestionarán los documentos duplicar . Ver Manejo de Duplicar Para más información.
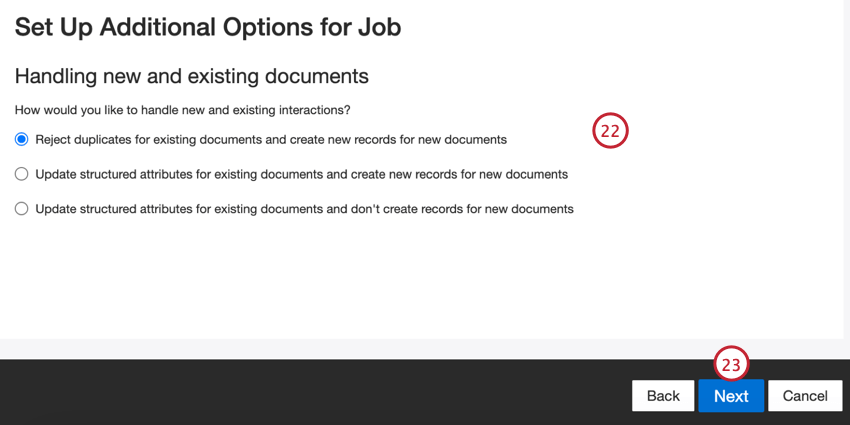
- Haga clic en Siguiente.
- Revise su configuración. Si necesita cambiar una configuración específica, haga clic en el Editar Botón para ir a ese paso en la configuración del conector.
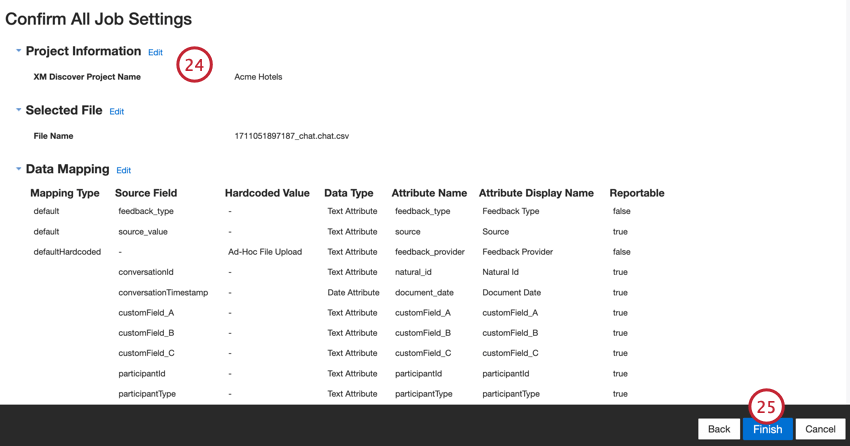
- Hacer clic Finalizar para salvar el trabajo.
Asignación de datos predeterminada
Esta sección contiene información sobre los campos predeterminados para trabajos entrantes de carga de archivos ad hoc.
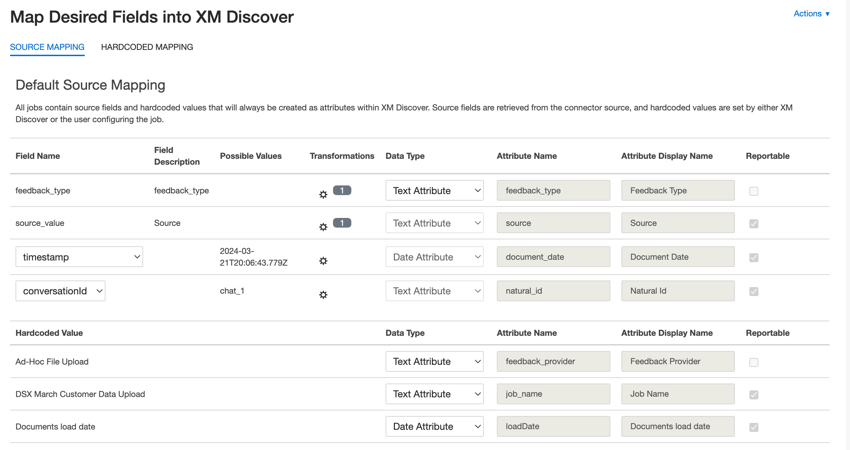
- tipo_de_retroalimentación :Identifica datos según su tipo. Esto es útil para generar informes cuando su proyecto contiene diferentes tipos de datos (por ejemplo, encuestas y opinión en las redes sociales). De forma predeterminada, el valor de este atributo se establece en “llamada” para transcripciones de llamadas, “chat” para interacciones digitales o “opinión” para opinión individuales. Usar transformaciones personalizadas para establecer un valor personalizado, definir una expresión o asignarlo a otro campo.
- valor_fuente :Identifica datos obtenidos de una fuente específica. Esto puede ser cualquier cosa que describa el origen de los datos, como el nombre de una encuesta o una campaña de marketing móvil. De forma predeterminada, el valor de este atributo se establece en “Carga de archivos ad hoc”. Usar transformaciones personalizadas para establecer un valor personalizado, definir una expresión o asignarlo a otro campo.
- fecha del documento :El campo de fecha principal asociado a un documento. Esta fecha se utiliza en informes , tendencias, alertas, etc. de XM Discover . Puede utilizar cualquier campo de fecha en su conjunto de datos para la fecha del documento. También puedes configurar un fecha específica del documento .
- identificación natural :Un identificador único de un documento. Es muy recomendable tener un ID único para cada documento para procesar los duplicados correctamente. Para Natural ID, puede seleccionar cualquier campo de texto o numérico de sus datos. Alternativamente, puedes generar identificaciones automáticamente agregando un campo personalizado.
- proveedor de retroalimentación :Identifica los datos obtenidos de un proveedor específico. Para las cargas de archivos, el valor de este atributo se establece en “Carga de archivos ad hoc” y no se puede cambiar.
- nombre_del_trabajo :Identifica los datos según el nombre del trabajo utilizado para cargarlos. Puede modificar el valor de este atributo durante la configuración a través del Nombre del puesto campo que se muestra en la parte superior de cada página durante la configuración.
- Fecha de carga :Indica cuándo se cargó un documento en XM Discover. Este campo se configura automáticamente y no se puede cambiar.
Consejo Q: Ver Mapeo de campos conversacionales para obtener información sobre cómo mapear datos conversacionales.