Predict iQ
Contenidos de la página
Atención: Estás leyendo acerca de una función a la que no todos los usuarios tienen acceso. Si está interesado en esta función, contacto con su Ejecutivo de Cuenta para ver si calificas.
Acerca de Predict iQ
Cuando los clientes abandonan una empresa, muchas veces nos tomamos por sorpresa. Si hubiéramos sabido que este cliente estaba en riesgo, tal vez podríamos habernos comunicado con él antes de que perdiera totalmente la confianza en nosotros. Ojalá hubiera una manera de predecir la probabilidad de que un cliente abandone la empresa.
Predict iQ aprende de las respuestas de la encuesta y de los datos embebidos para predecir si el encuestado eventualmente abandonará la plataforma. Luego, cuando llegan nuevas respuestas a la encuesta , Predict iQ puede predecir la probabilidad de que los encuestados abandonen la encuesta en el futuro. Para predecir si un cliente se dará de baja, Predict iQ utiliza redes neuronales (un subconjunto de las cuales se denomina aprendizaje profundo) y regresión para construir modelos candidatos. Prueba variaciones de esos diferentes modelos para cada conjunto de datos y luego elige el modelo que mejor se ajusta a los datos.
Preparando sus datos
Antes de crear un modelo de predicción de abandono, deberá asegurarse de que sus datos estén listos.
Predict iQ funciona mejor cuando tienes al menos 500 encuestados que han abandonado el sistema. Sin embargo, 5.000 encuestados que se dieron de baja o más le brindarán los mejores resultados.
Configuración de una variable de abandono
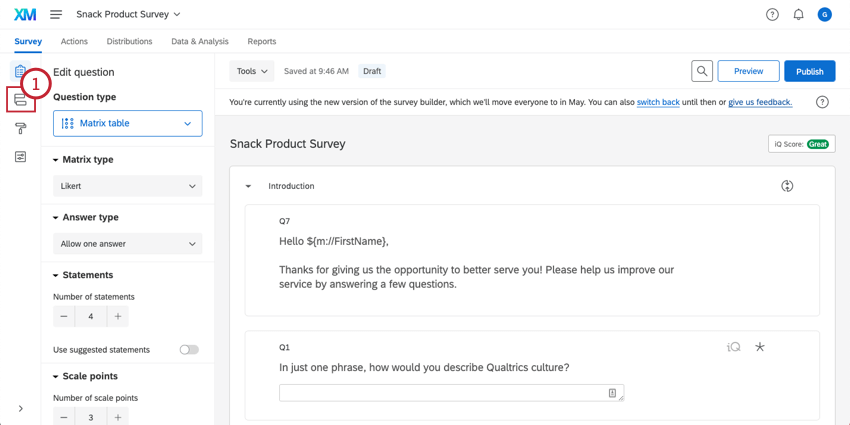
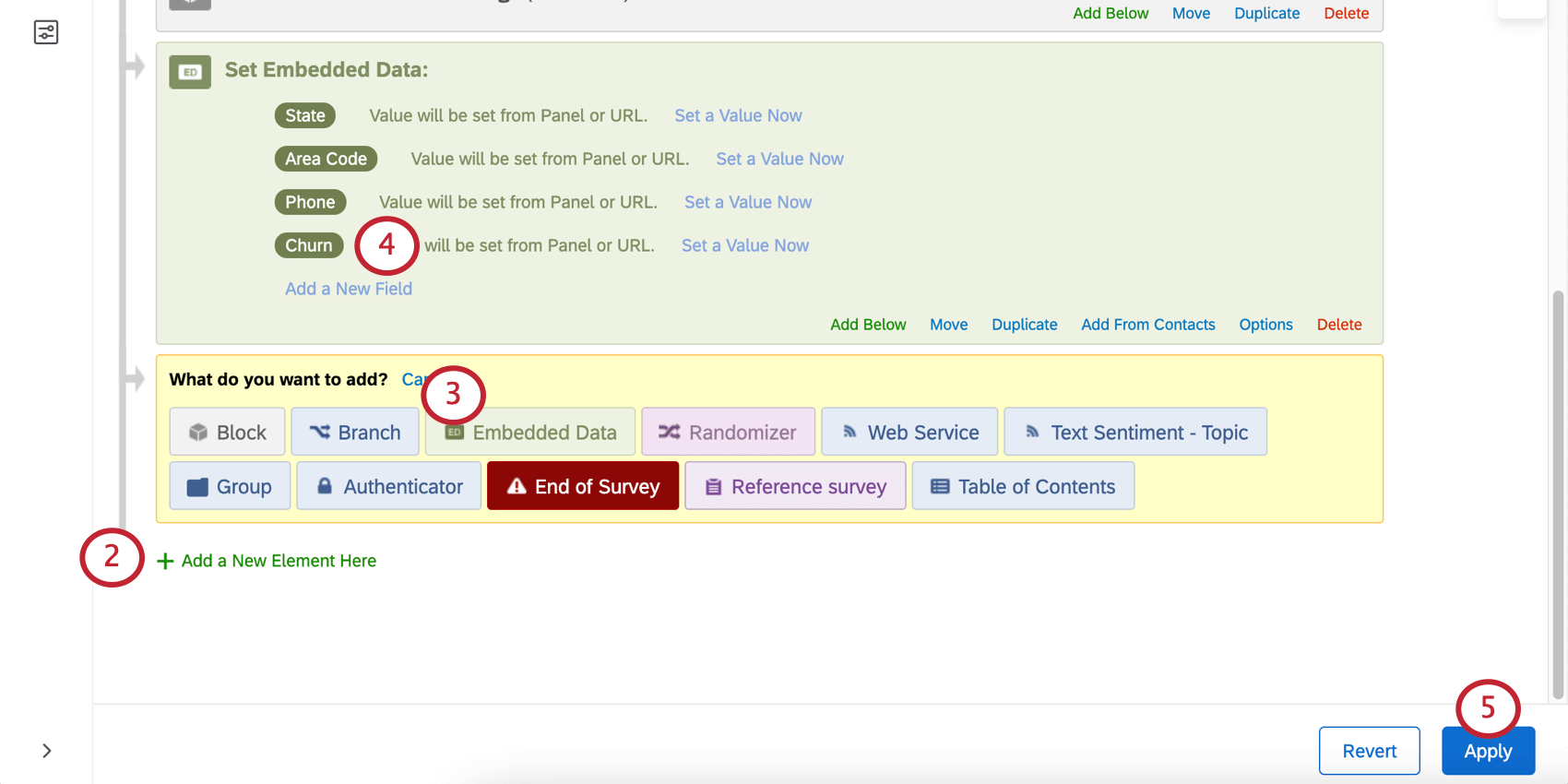
Grabación de datos
Una vez que tenga una variable de abandono, puede Importa datos históricos a tu encuesta , incluyendo una columna para Churn donde indicas con Sí o No si el cliente se dio de baja.
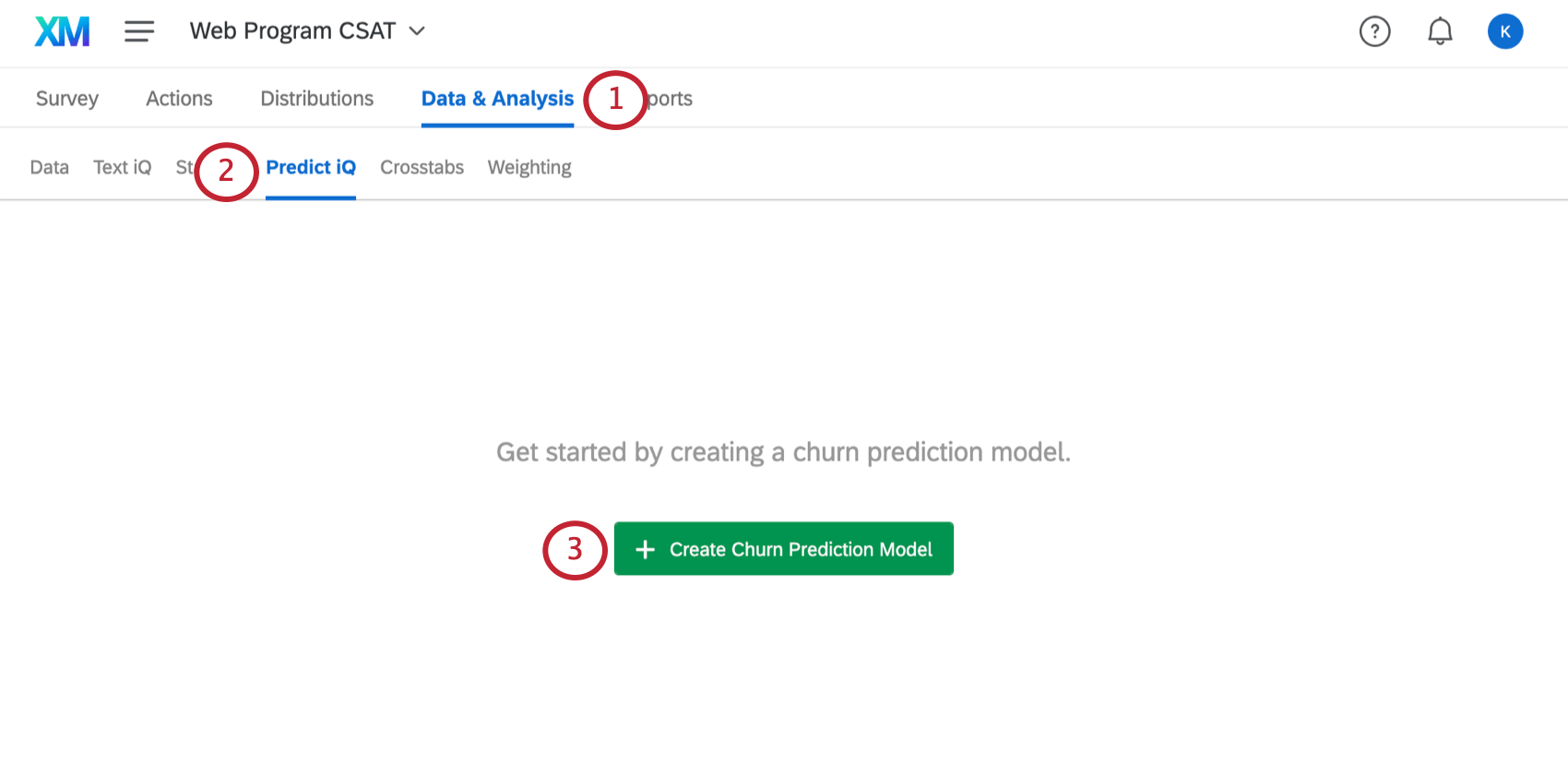
Creación de un modelo de predicción de abandono
Una vez que su variable de abandono esté configurada y tenga suficientes datos, estará listo para abrir Predict iQ.
Consejo Q: Predict iQ solo predice resultados que tienen 2 opciones posibles, como Sí/No o Verdadero/Falso. No predice resultados numéricos (por ejemplo, una escala de 1 a 7) ni resultados categóricos con más de 2 valores (por ejemplo, Sí/Tal vez/No).
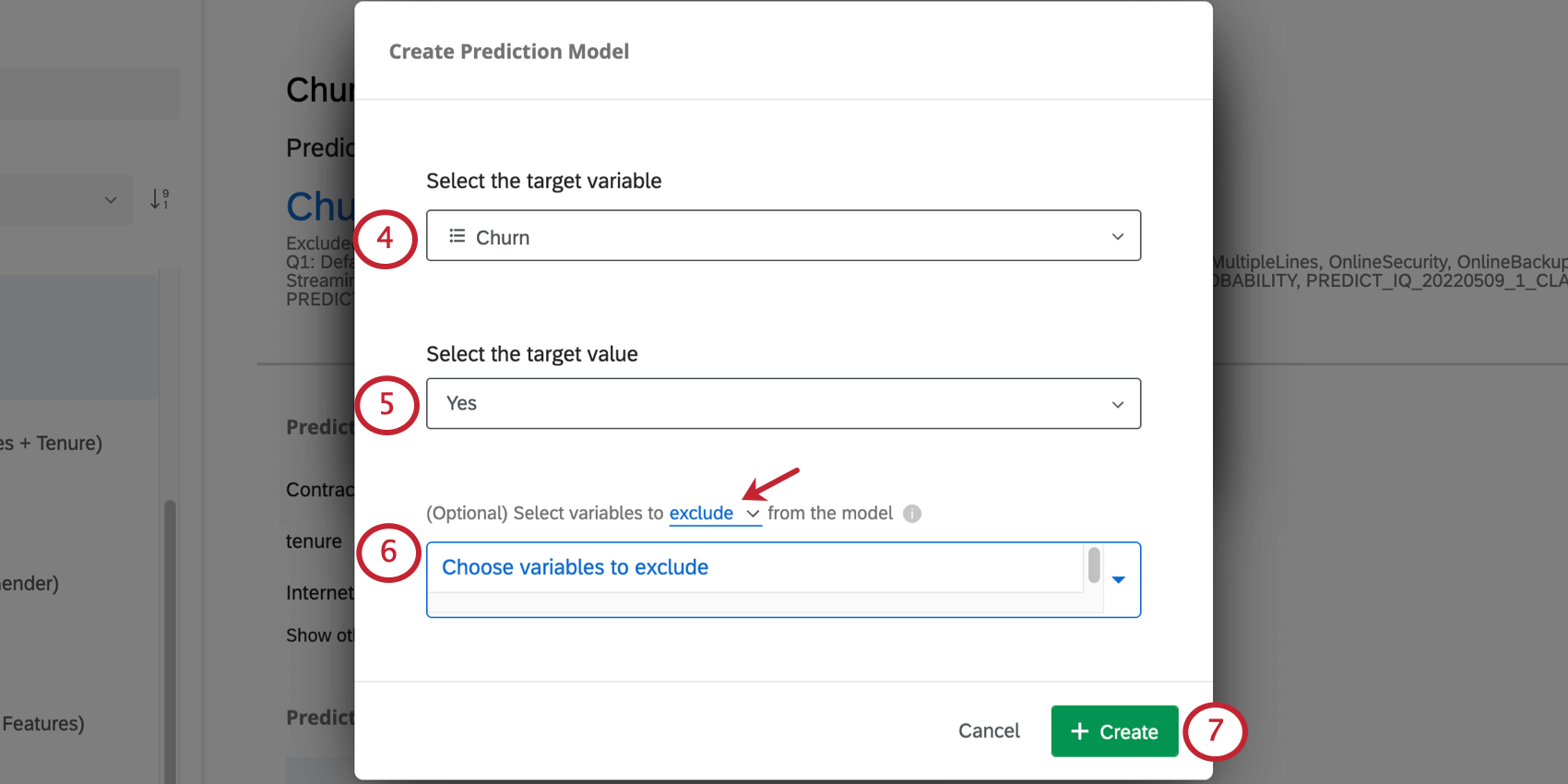
Ejemplo: Debido a que en este ejemplo nuestra variable se llama Churn, alguien con Batir igual a Sí se ha agitado. Pero digamos que nombraste tu variable Permanecer en nuestra empresa en cambio. Entonces No indicaría que la persona no permanecía en la empresa y se fue.
- Excluir: Por ejemplo, si tiene una variable que mide el “Motivo de la pérdida” en sus datos históricos, es posible que desee excluirla del análisis, ya que no estará disponible para los nuevos encuestados cuando se realice la predicción. Consejo Q: Puede excluir varias variables. Haga clic en el incógnita siguiente a una variable para eliminarla de la lista de variables excluidas.


- Incluir: Seleccione las variables que desea incluir en el modelo; todas las demás serán ignoradas.

Consejo Q: Es posible que su modelo de abandono predictivo tarde algún tiempo en finalizar el cálculo. Puede salir de la página para trabajar en otros proyectos o sitios web sin perder su progreso.
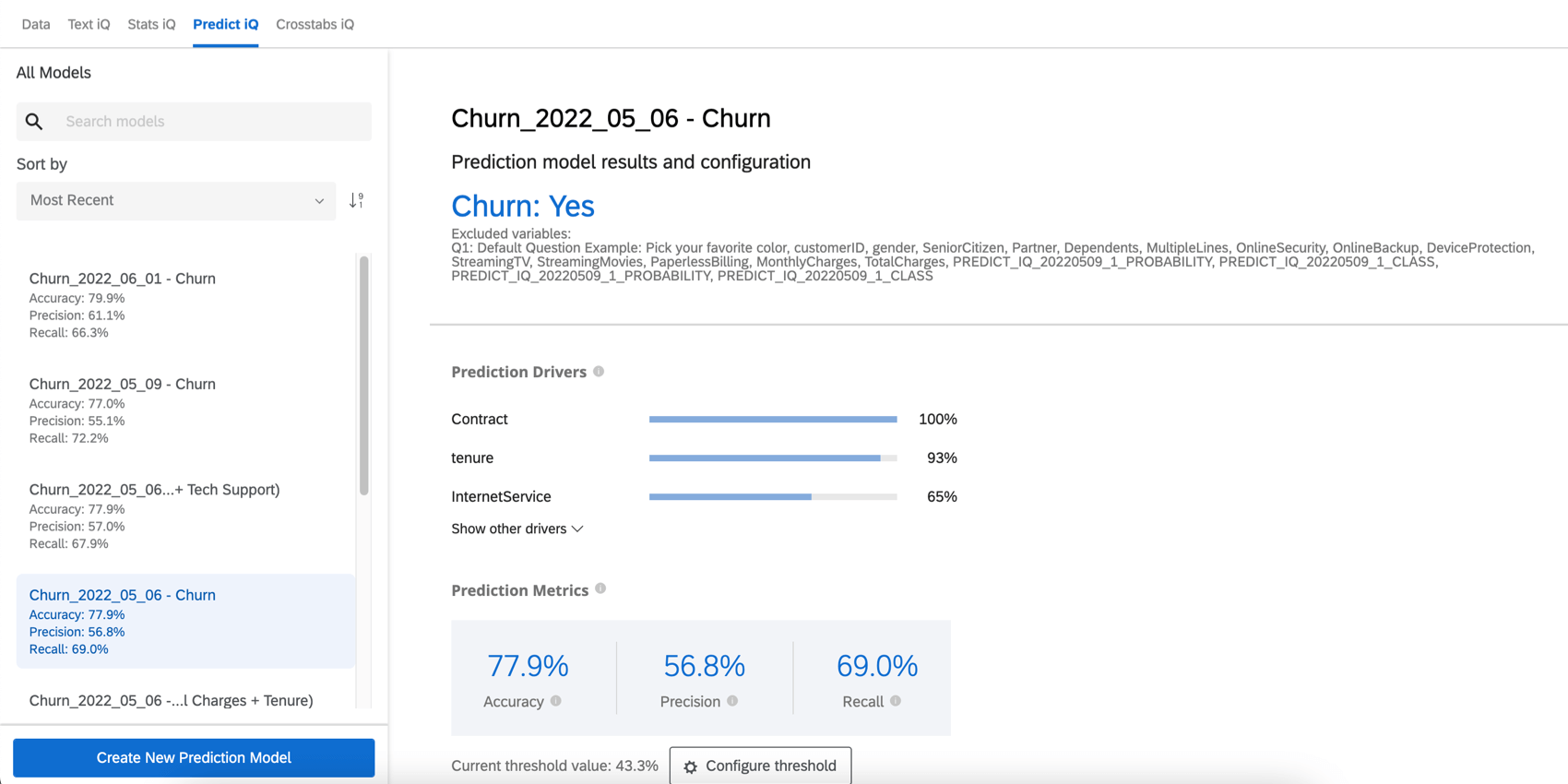
Una vez que su modelo de predicción esté completo, la página Predict iQ será reemplazada con información sobre el modelo de predicción de abandono que acaba de crear.
{kind=link}
¿Cómo se divide su conjunto de datos para el capacitación del modelo?
En el proceso de capacitación de su modelo, su conjunto de datos se divide en datos de capacitación, validación y prueba. 80% de sus datos se utilizan para capacitación. 10% de sus datos se utilizan para validación, y 10% de sus datos se utilizan para realizar pruebas.
Información variable
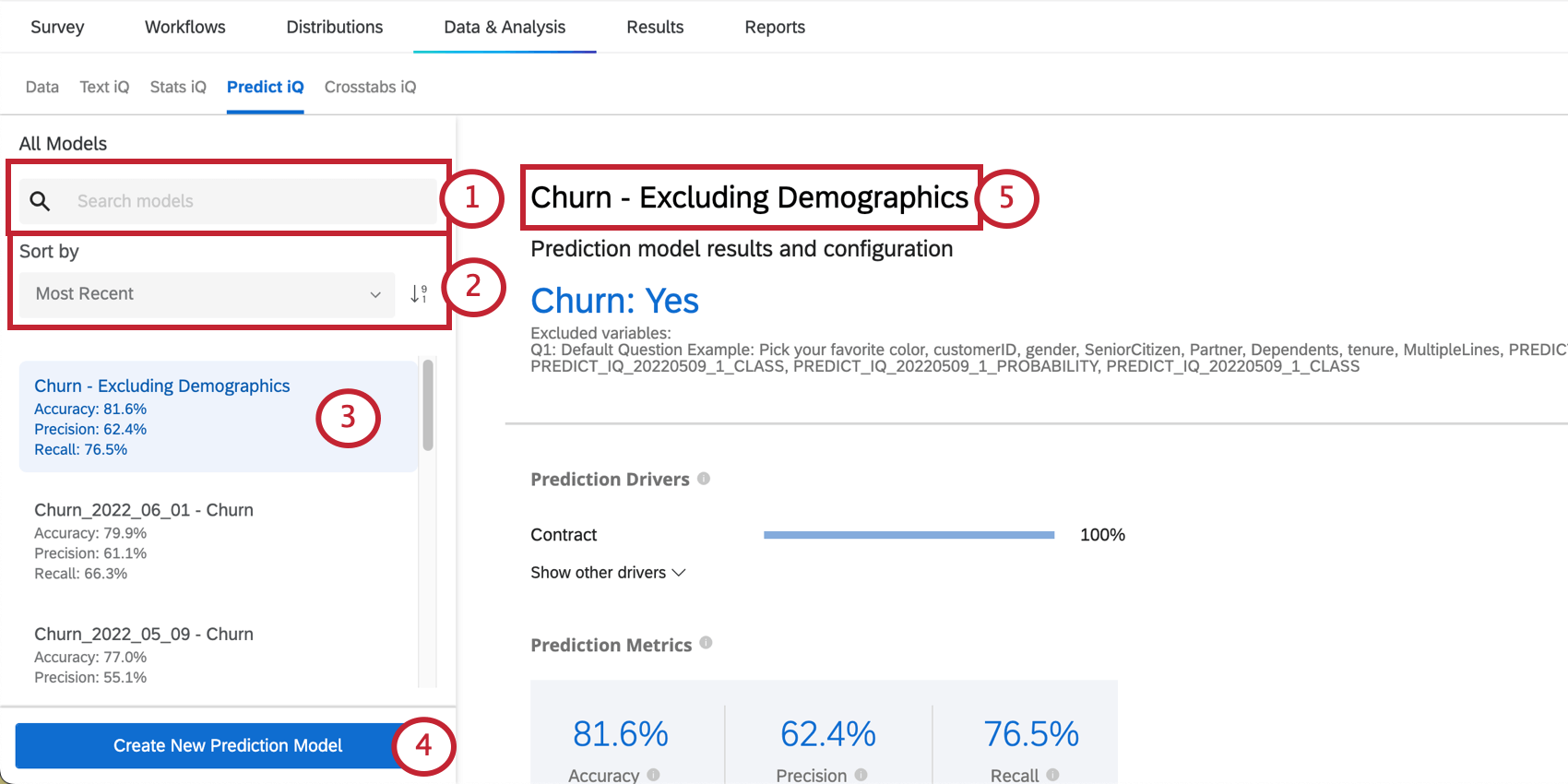
El resultados y configuración del modelo de predicción La sección proporciona el nombre de la variable de datos embebidos Churn y el valor que indica que es probable que un cliente abandone. Esta sección también enumera las variables excluidas.
{kind=link}

Impulsores de predicción
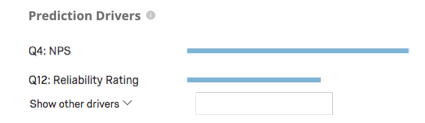
Los impulsores de predicción son las variables que se analizaron para crear su modelo de predicción, ordenados por su importancia para predecir la pérdida de clientes. Esto incluye cualquier variable que no haya sido excluida del análisis. En el siguiente ejemplo, los puntajes NPS y las calificaciones de confiabilidad impulsan la predicción de abandono.
{kind=link}

Hacer clic Mostrar otros conductores Para ampliar la lista.
Consejo Q: Para crear este gráfico, cada variable se ejecuta en una regresión logística simple contra la variable de abandono. El valor r cuadrado más alto se establece en 1 y los valores de las demás variables se escalan en consecuencia. Por ejemplo, si el r-cuadrado más alto es 0,5, entonces la longitud de la barra de cada variable será r-cuadrado * 2, donde la longitud de la barra es 1.
Por lo tanto, el gráfico es un indicador de la fuerza relativa de las variables a la hora de predecir la rotación del cliente y no es multivariable por naturaleza. La calificación del impacto de cada variable en el resultado de un modelo basado en un algoritmo de aprendizaje profundo es un área de investigación académica activa, sin una mejor práctica aceptada en este momento.
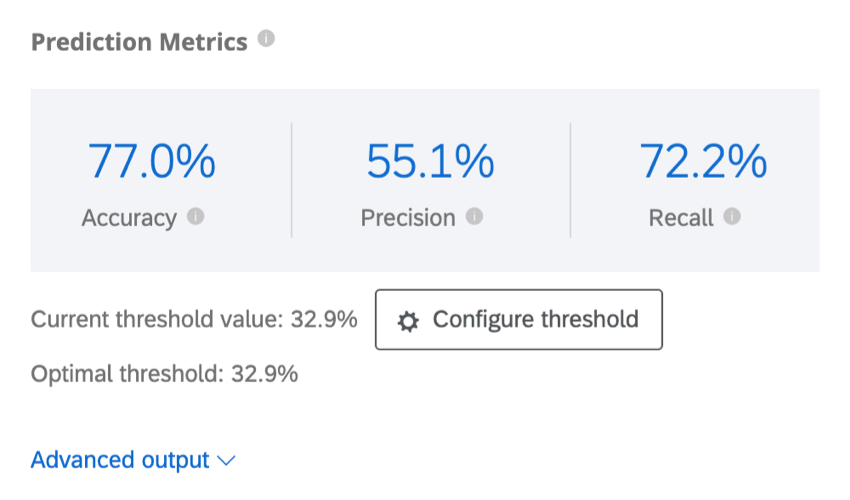
Métricas de predicción
Predict iQ “reserva” (deja de lado) el 10% de los datos antes de crear el modelo. Una vez creado el modelo, se crean predicciones para ese 10%. Luego compara sus predicciones con lo que realmente ocurrió, es decir, si esos clientes efectivamente abandonaron la empresa. Estos resultados se utilizan para impulsar las métricas de precisión que aparecen a continuación. Tenga en cuenta que si bien este es un método recomendado y eficaz para estimar la precisión del modelo, no es una garantía de la precisión futura del modelo.
{kind=link}
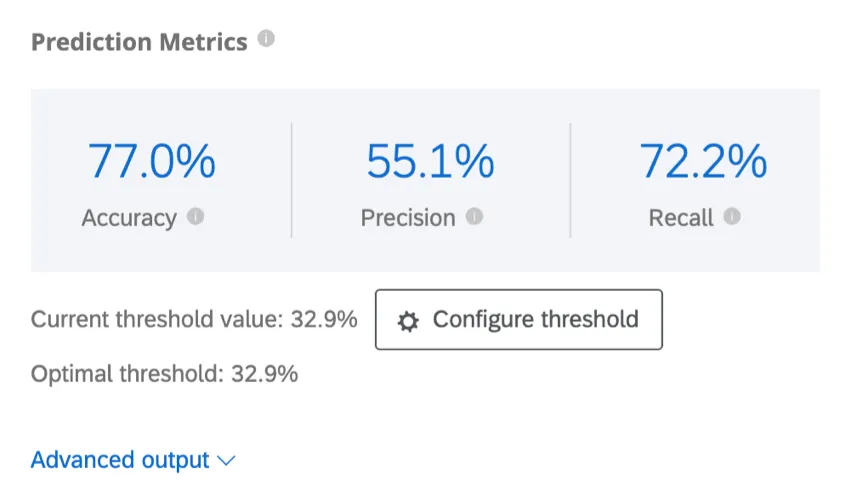
- Exactitud: La proporción de las predicciones del modelo que serán precisas.
- Precisión: La proporción de clientes que se prevé que abandonarán el servicio y que realmente lo harán.
- Recordar: La proporción de aquellos que realmente abandonaron su empleo que el modelo predijo de antemano que lo harían.
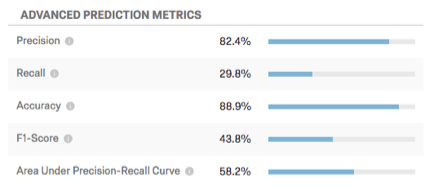
Ejemplo: En esta captura de pantalla, las predicciones del modelo serán precisas el 88,9% del tiempo. Es bastante preciso decir que el 82,4% de los clientes que se prevé que abandonen la empresa, lo harán. La métrica de recuperación indica que el modelo identificará correctamente aproximadamente el 29,8 % de los clientes que realmente abandonarán la compra.
Predict iQ calculará el valor de umbral óptimo maximizando la puntuación F1. Su modelo se establecerá en el umbral óptimo de forma predeterminada, pero puede ajustarlo; consulte Configurar umbral a continuación.
Hacer clic Salida avanzada debajo de la tabla de Métricas Predictivas para revelar las tablas de Matriz de Confusión y Métricas de Predicción Avanzadas.
Precisión y recuperación
Precisión y recordar son las métricas de predicción más importantes. Tienen una relación inversa, por lo que a menudo hay que pensar en el equilibrio entre saber exactamente qué clientes se van a dar de baja y saber que se han identificado todos o la mayoría de los clientes que probablemente se darán de baja.
Ejemplo: Imagínese si hiciera un seguimiento de cada uno de sus clientes. Definitivamente, usted se comunicaría con todos los que abandonan el servicio (recuerdo del 100 %), pero desperdiciaría muchos recurso y tiempo en clientes que nunca consideraron irse (baja precisión). Por otro lado, si solo haces un seguimiento del individuo que tiene más probabilidades de abandonar el servicio, probablemente tendrás una precisión del 100 %, pero perderás muchos clientes que finalmente se irán (recuerdo muy bajo).
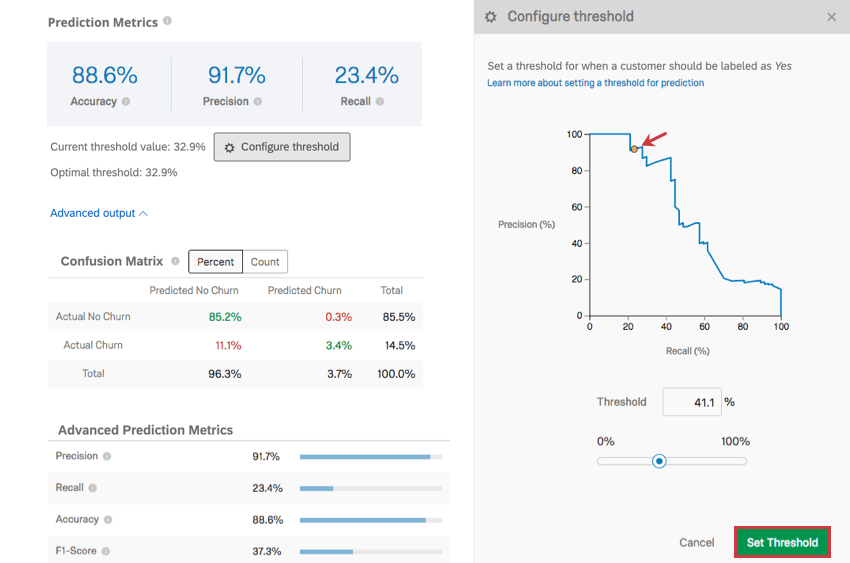
Configurar umbral
Hacer clic Configurar umbral establecer un umbral para determinar cuándo un cliente debe ser etiquetado como propenso a abandonar el servicio. Este porcentaje umbral es la probabilidad individual de abandono.
Ejemplo: El modelo produce una estimación de la probabilidad de abandono de cualquier cliente. Imaginemos que hay tres clientes, con probabilidades de abandono del 10%, 40% y 75%. Si el umbral se establece en 30%, tanto el 40% como el 75% de los clientes se marcan como propensos a abandonar el servicio y, por lo tanto, recibirán un correo electrónico o una llamada telefónica. Sin embargo, si el umbral se establece en el 50%, solo el cliente con un porcentaje del 75% se marca como propenso a abandonar el servicio.
{kind=link}
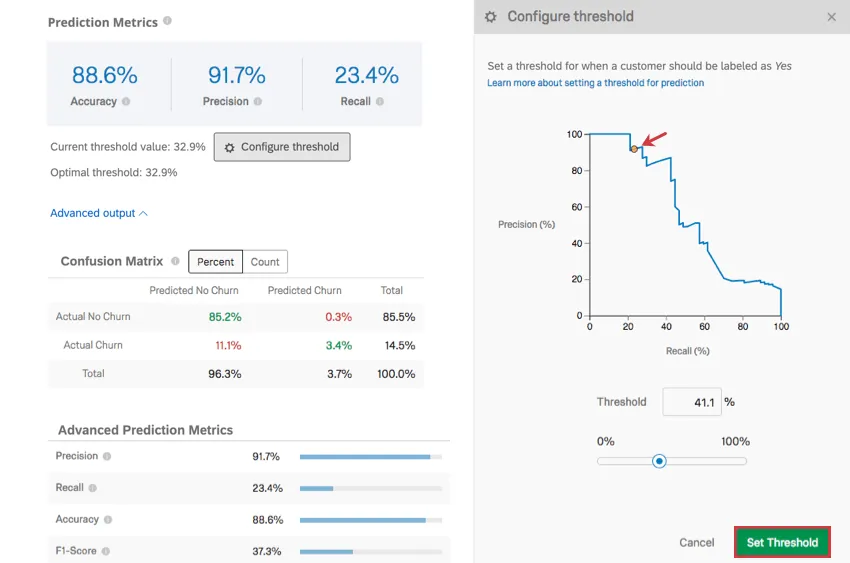
Haga clic y arrastre el punto en el gráfico para ajustar el umbral, o escriba un porcentaje de umbral y observe cómo cambia el gráfico. Cuando haya terminado, haga clic en Establecer umbral para guardar los cambios. También puede cancelar los cambios haciendo clic en Cancelar En la parte inferior derecha o la incógnita En la parte superior derecha.
Al ajustar el umbral se ajusta la precisión a lo largo del eje y y la recuperación a lo largo del eje x. Estas métricas tienen una relación inversa. Cuanto más precisas sean sus mediciones, menor será la recuperación, y viceversa.
Consejo Q: Ajustar el umbral cambia la forma en que se recopilan los datos futuros cuando tiene Crear una predicción cada vez que un nuevo encuestado complete esta encuesta seleccionado en el Predicciones de transmisión sección en la parte inferior de la página Predict iQ . Para sobrescribir los datos de Churn de su modelo anterior, deberá eliminar su variable Churn y agregar una nueva variable. Los umbrales no afectan la variable Probabilidad de abandono, solo el binario Sí/No.
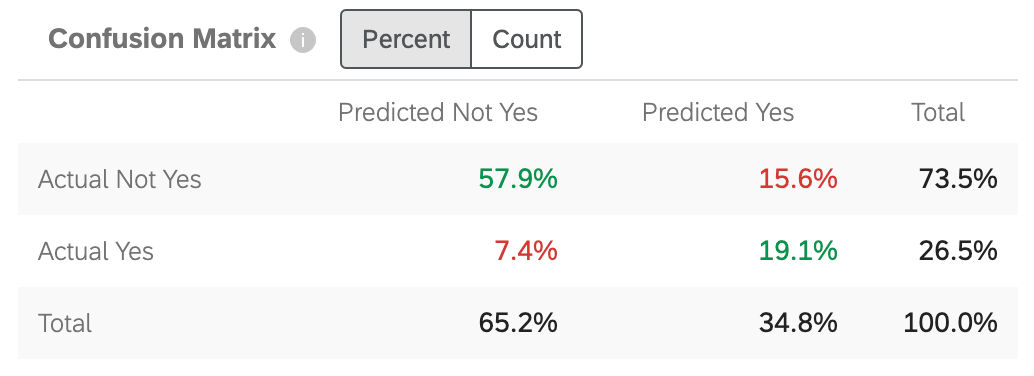
Matriz de confusión
Cuando Predict iQ crea un modelo de predicción, “reserva” (o deja de lado) el 10% de los datos. Para comprobar la precisión del modelo generado, los datos del nuevo modelo se comparan con el límite del 10 %. Esto sirve como comparación entre lo que se predijo y lo que “realmente sucedió”.
{kind=link}
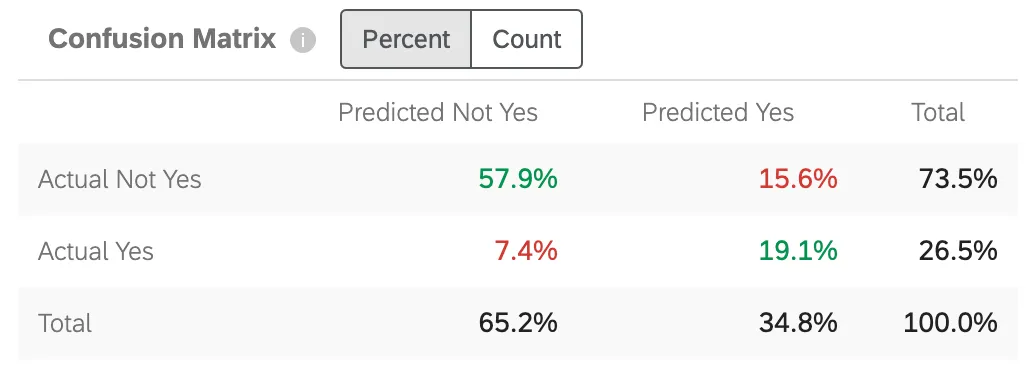
“Sí” en este cuadro será reemplazado por el valor objetivo que haya indicado. Paso 5 de la configuración .
- Actual No Sí / Predicho No Sí: El porcentaje de clientes que el modelo predijo que no abandonarían, y que en realidad no lo hicieron.
- Real Sí / Predicho No Sí: El porcentaje de clientes que el modelo predijo que no abandonarían la tienda y que, por el contrario, sí lo hicieron.
- Actual No Sí / Predicho Sí: El porcentaje de clientes que el modelo predijo que abandonarían la tienda y que, por el contrario, no lo hicieron.
- Real Sí / Predicho Sí: El porcentaje de clientes que el modelo predijo que abandonarían y que realmente abandonaron.
Los números son verdes para indicar que desea que esos números sean lo más altos posible, ya que reflejan conjeturas correctas. Los números son rojos para indicar que desea que estos números sean bajos, ya que reflejan conjeturas incorrectas.
Puede ajustar la matriz para mostrar cualquiera de las siguientes opciones: Por ciento o Contar . Este recuento incluye el 10% de los datos retenidos, no el conjunto de datos completo.
Métricas de predicción avanzadas
Esta tabla muestra métricas de predicción adicionales.
{kind=link}
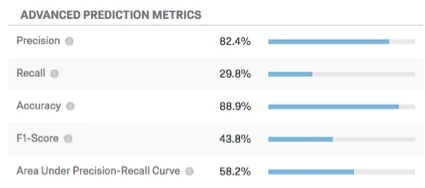
- Precisión: La proporción de clientes que se prevé que abandonarán el servicio y que realmente lo harán.
- Recordar: La proporción de aquellos que realmente abandonaron su empleo que el modelo predijo de antemano que lo harían.
- Exactitud: La proporción de las predicciones del modelo que serán precisas.
- Puntuación F1: La puntuación F1 se utiliza para seleccionar un umbral que equilibra la precisión con la recuperación. Una puntuación F1 más alta generalmente es mejor, aunque el lugar correcto para establecer el umbral debe estar determinado por sus objetivos comerciales.
- Área bajo la curva de precisión-recuperación: La curva de precisión-recuperación es la curva que se observa en el gráfico cuando se hace clic Configurar umbral . El área total bajo la curva es una medida de la precisión general del modelo (independientemente de dónde establezca el umbral). Un área bajo la curva del 50% es igual a una probabilidad aleatoria; el 100% es perfectamente exacto.
Hacer predicciones
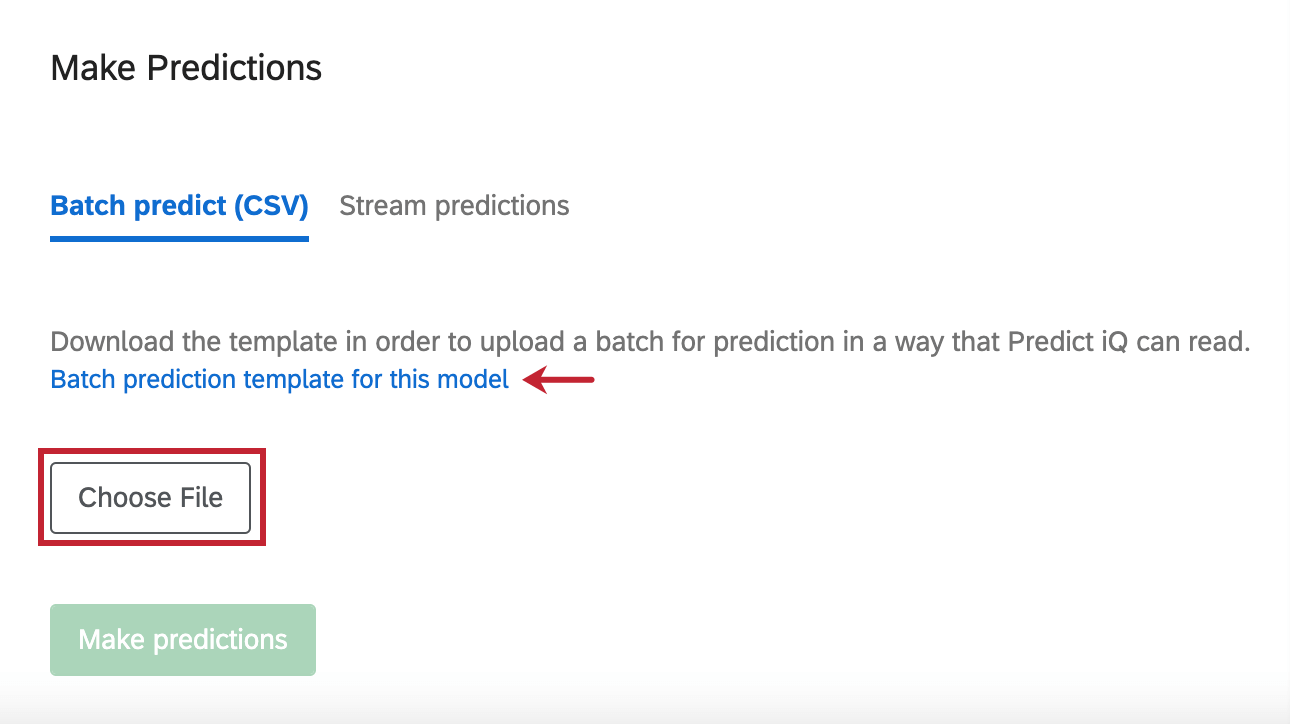
Predicción por lotes (CSV)
Además de analizar las respuestas que ha recopilado en su encuesta, también puede cargar un archivo de datos específico que desea que Predict iQ evalúe.
{kind=link}
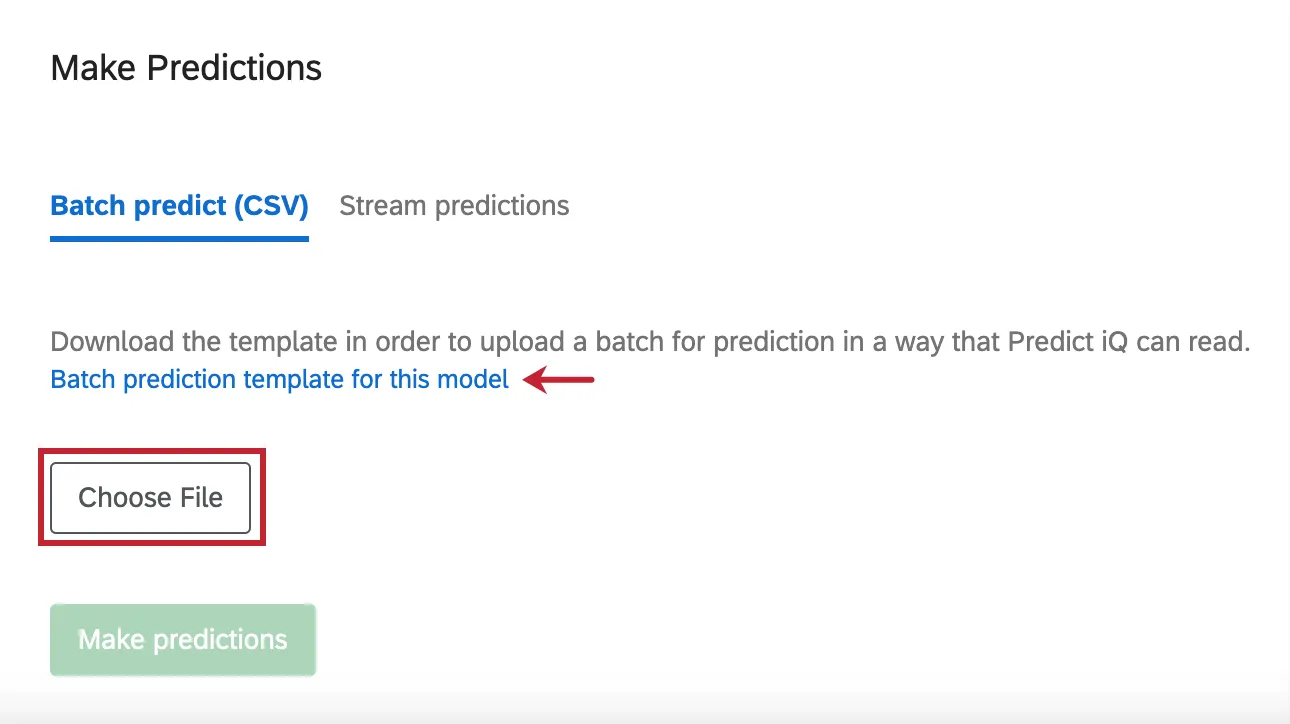
Para obtener un archivo de plantilla, haga clic en Plantilla de predicción por lotes para este modelo .
Cuando haya terminado de editar su archivo en Excel y esté listo para volver a cargarlo, haga clic en Seleccione Archivo para seleccionar el archivo. Luego haga clic Hacer predicciones para iniciar el análisis.
Consejo Q: ¿Tiene problemas con su archivo de plantilla? Ver el Problemas con la carga de CSV/ TSV página.
Predicciones de transmisión
Las predicciones de transmisión se actualizan a medida que llegan datos a la encuesta. En esta sección, puedes decidir cuándo se realizarán estas actualizaciones de predicciones.
{kind=link}
Cree una predicción cada vez que un nuevo encuestado complete esta encuesta: Esta configuración permite realizar predicciones en tiempo real. Tendrás dos columnas más en tus datos: Probabilidad de abandono, la probabilidad de abandono en formato decimal; y Predicción de abandono, una variable Sí/No. La predicción de abandono se basa en la límite configurado.
Consejo Q: Si sus datos incluyen datos embebidos extraídos de una fuente que no es una encuesta, es posible que los datos no lleguen a Qualtrics inmediatamente después de que se complete la encuesta . Si esos datos son importantes para las predicciones, es posible que quieras esperar hasta que se hayan cargado para poder incluirlos.
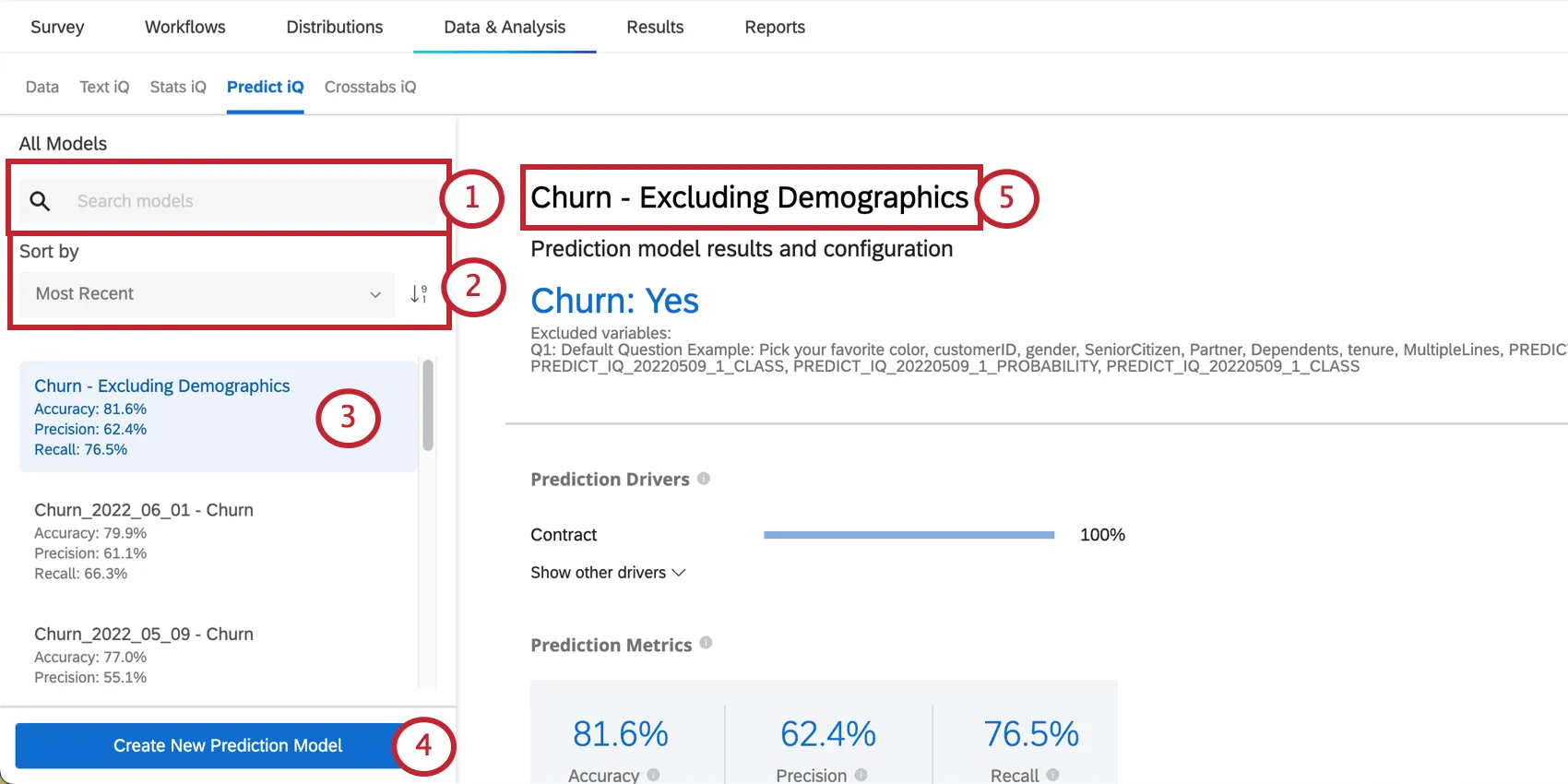
Gestión de modelos
A la izquierda de la página, verás un menú donde puedes desplazarte y seleccionar modelos de predicción que hayas creado en el pasado.
{kind=link}
Datos de abandono
En la sección Datos de la pestaña Datos y análisis, puede exportar sus datos como una conveniente hoja de cálculo. Una vez cargado el modelo de predicción, tendrá columnas adicionales para datos de abandono en esta página.
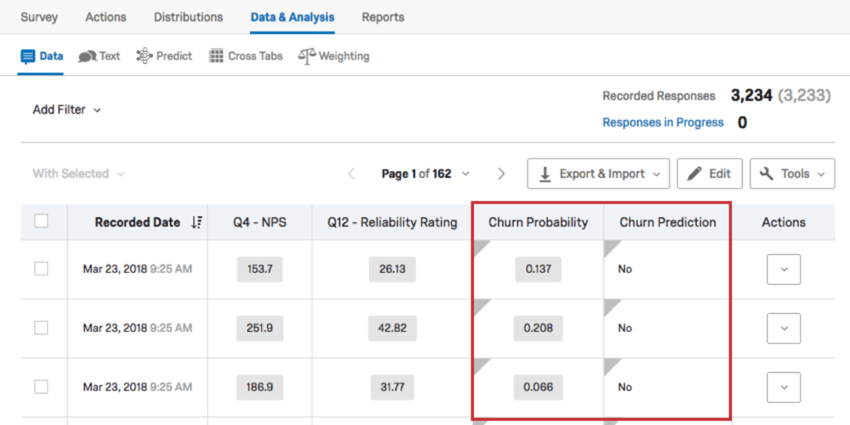{kind=link}
- Probabilidad de abandono: La probabilidad de rotación en formato decimal. Aparece cuando predicción de flujo Se ha habilitado y se basa en el umbral establecido. Si no ve la columna Probabilidad de abandono, también puede buscar una columna de datos llamada “[campo de abandono seleccionado]_PROBABILITY_PREDICT_IQ”.
- Predicción de abandono: Una variable Sí/No que confirma o niega la pérdida de clientes en función del umbral establecido. Aparece cuando predicción de flujo Se ha habilitado. Si no ve la columna Predicción de abandono, también puede buscar una columna de datos llamada “[campo de abandono seleccionado]_CLASS_PREDICT_IQ”.
Ejemplo: Si el campo de abandono que seleccionó al crear su modelo de predicción de abandono se llama “CustomerChurnFlag”, las columnas de datos de abandono pueden verse como CustomerChurnFlag_CLASS_PREDICT_IQ y CustomerChurnFlag_PROBABILITY_PREDICT_IQ.
Los nombres de las columnas también incluirán la fecha en que se entrenó el modelo en formato MMDDAAAA. Por ejemplo, el 14 de enero de 2022 se representaría en el nombre de la columna como 01142022.
Tenga en cuenta que las probabilidades de abandono y las predicciones solo se aplican a los nuevos resultados de la encuesta . A las respuestas ya existentes no se les agregarán probabilidades de abandono ni predicciones.
Consejo Q: Una vez que haya creado estas variables, se pueden analizar utilizando Resultados-Informes o Informes avanzados , al igual que cualquier otra variable.
Limpieza automática de datos
Al capacitación el modelo, Predict iQ ignorará automáticamente ciertos tipos de variables que no serán útiles para las predicciones, mientras transforma automáticamente otras variables.
Variables de alta cardinalidad
Si una variable tiene más de 50 valores únicos o más del 20% de los valores registrados son únicos, se ignorará durante el capacitación del modelo. Las variables con demasiados valores únicos no son buenas columnas de función para las predicciones.
Ejemplo: Por ejemplo, si tienes una variable que es Condado – Estados Unidos , esta variable se ignoraría durante el capacitación del modelo porque hay más de 3000 condados en los Estados Unidos en los 50 estados.
Ejemplo: Como otro ejemplo, considere una variable como Sabor de helado favorito y supongamos que tienes 100 filas de datos para esta variable. Entre esas 100 filas, discover que hay 21 valores únicos para el sabor del helado. Esta variable se ignora durante el capacitación del modelo porque más del 20% de sus valores registrados son únicos.
Valores faltantes en columnas numéricas
Para las variables numéricas que se incluyen en el modelo, los valores faltantes siempre se imputan como 0 (cero).
Codificación One-Hot de categóricos
Las variables categóricas serán codificado one-hot Si la variable no es recodificado o la variable no tiene una relación ordinal para sus categorías.
Consejo Q: Predict iQ se traslada al mismo tiempo configuraciones variables utilizadas en Stats iQ .
Variables invariantes
Cualquier variable que no tenga variación en sus valores registrados será ignorada para el capacitación del modelo. Esto significa que si tienes una variable que solo tiene un valor único, no será parte del modelo. Las variables que son útiles para la predicción lograrán un buen equilibrio entre tener muy pocos valores únicos y tener demasiados valores únicos. Consulte “Variables de alta cardinalidad” más arriba.
Si se excluyen variables invariantes durante la limpieza de datos, se incluirán en la lista. Sección de resultados y configuración del modelo de predicción .
Proyectos en los que puedes utilizar Predict iQ
Predict iQ no está incluido con todas las licencias. Sin embargo, si tiene esta función, puede acceder a ella de varias formas diferentes. tipos de proyectos :
- Proyectos de encuesta
- Proyectos de datos importados
- Soluciones XM
- Investigación de la experiencia del empleado ad hoc
Predict iQ también puede aparecer en Compromiso y Ciclo vital proyectos, pero en función de la naturaleza de los datos que suelen recopilar estos tipos de proyectos, el conjunto de datos no sería necesariamente el mejor para Predict iQ.
Mientras que Predict iQ aparece en Asociado y MaxDiff , lo hacemos no Recomiendo usarlos juntos. El contenido específico de Conjoint y MaxDiff no es compatible con Predict iQ, por lo que solo puede analizar datos demográficos.
No se admiten otros tipos de proyectos.
Consejo Q: Los proyectos enumerados en esta sección no están disponibles en todas las licencias.
Preguntas frequentes
¡No tengo la pestaña descrita en esta página! ¿Qué hago?
¡No tengo la pestaña descrita en esta página! ¿Qué hago?
¡Genial! ¡Gracias por tus comentarios!
¡Gracias por tus comentarios!