-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Comprender su conjunto de datos
Acerca de su conjunto de datos de respuesta
Para realizar análisis adicionales fuera de Qualtrics, puede Descargar un conjunto de datos archivo para cualquier encuesta. Este conjunto de datos incluye los datos de respuestas sin procesar de su encuesta, entre ellos, la información de envío del archivo del encuestado, las respuestas a las preguntas, hasta los metadatos adicionales, como la duración y las fechas, hasta los datos embebidos, etc.
En esta página, haremos lo siguiente:
- Explicar las diferentes columnas de información que puede ver en su archivo de datos.
- Explicar cómo se pueden dar formato a las respuestas en este archivo de datos, según la columna.
- Indicar otros recursos que le permitirán comprender o personalizar la descarga de datos.
Sin embargo, en esta página no trataremos el análisis estadístico, ni le indicaremos cómo interpretar los resultados de sus datos, más allá de lo literal (por ejemplo, este encuestado marcó que estaba muy satisfecho). Hay tantas variables y proyectos diferentes que van a la investigación, y aunque nos encantaría decir que lo sabemos todo, realmente depende de los detalles de su estudio y de cómo lo configure.
Tipos de conjuntos de datos de respuesta que se tratan en esta página
Esta página puede ayudarle a comprender los datos sin procesar que exporta desde los siguientes tipos de proyectos :
Hay algunos otros tipos de proyectos en los que puedes exportar datos de respuesta. Sin embargo, hay diferencias importantes que debemos tener en cuenta:
- Para proyectos 360 , ver Comprender su conjunto de datos de respuesta ( 360) .
- Para todos los demás proyectos de Employee Experience , ver Comprender su conjunto de datos de respuesta ( EX) .
Técnicamente, Asociado y MaxDiff Los conjuntos de datos también se formatean como se describe en esta página cuando se exportan desde Datos y análisis. Sin embargo, esta exportación de datos excluye Asociado- y Datos específicos de MaxDiff .
Aspectos básicos del formato de archivo
Cada fila del archivo es una respuesta de encuesta diferente (aunque no necesariamente diferentes encuestados, si permite que las personas respondan varias veces). Cada columna es un tipo de datos de encuesta.
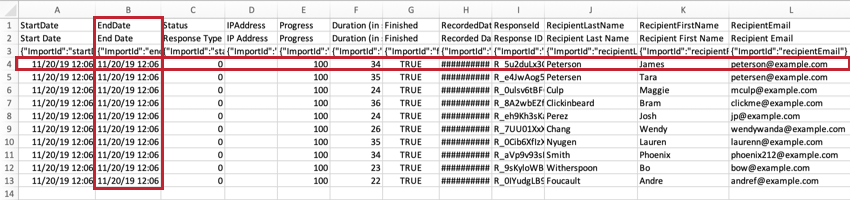
Los archivos CSV y TSV vienen con 3 filas de encabezados. El primer encabezado es el ID interno de Qualtrics del campo (por ejemplo, EndDate, Q1, Q2, etc.). El segundo es el nombre o el texto del campo (por ejemplo, Fecha de fin o ¿Cuál es su nivel de satisfacción con Qualtrics?). El tercero son ID de importación. Se incluyen estos tres encabezados porque son necesarios para Subir los datos a una encuesta . A partir de la cuarta dila del archivo se encuentran los datos del encuestado.
Información del encuestado
Las primeras columnas de un conjunto de datos incluyen información sobre cada encuestado y su respuesta, como su nombre, dirección IP, fechas de envío de respuestas, etc. Aquí enumeraremos cada una de esas columnas y cómo comprender su contenido.
Fecha de inicio
Estos valores de fecha y hora indican cuándo los encuestados hicieron clic por primera vez en el enlace de encuesta.
Fecha de finalización
Estos valores de fecha y hora indican cuándo el encuestado envió su encuesta. Si la entrada es una respuesta incompleta, esta fecha indicará la última vez que el encuestado interactuó con la encuesta.
Estado/Tipo de respuesta
El valor de la columna Estado indica el tipo de respuesta recopilada. Estos son los estados posibles, presentados en ambos valor y etiqueta formato:
- 0 / Dirección del IP: Una respuesta normal
- 1 / Vista previa de la Encuesta : A vista previa de respuesta
- 2 / Prueba de encuesta: una respuesta a la prueba
- 4 / Importado: Un respuesta importada
- 16 / Fuera de línea: A Aplicación sin conexión de Qualtrics respuesta
- 17 / Vista previa sin conexión: Vistas previas enviadas a través deAplicación sin conexión de Qualtrics. Esta función ha quedado obsoleta en las versiones más recientes de las aplicación
- 256 / Sintético: A respuesta del panel sintético.
Dirección IP
Esta columna incluye la dirección IP del encuestado. Estos datos no estarán disponibles si se han recibido respuestas. completamente anónimo.
Duración
El número de segundos que tardó el encuestado en completar la encuesta. Esta es la duración completa de la respuesta; si un encuestado se detiene a mitad de la encuesta, cierra el navegador y vuelve a acceder otro día, ese tiempo se tiene en cuenta.
Terminado y Progreso
El Finalizado La columna detalla si la respuesta fue enviada o cerrada. Un “1” o “Verdadero” indica que el encuestado llegó a un punto final en su encuesta (presionó el último botón Siguiente/Enviar, fue excluido con Lógica de Ramificación, etc.). Un “0” o “Falso” indica que el encuestado abandonó la encuesta antes de llegar a un punto final y, en cambio, la respuesta se cerró. a mano o debido a expiración de la sesión.
El Progreso La columna muestra el progreso que logró un encuestado en la encuesta antes de finalizarla. Para aquellos marcados como “1” o “Verdadero” en la columna Terminado, el Progreso está marcado como 100. Para aquellos cuyas respuestas estén marcadas como “0” o “Falso”, obtendrá un porcentaje exacto de lo lejos que llegaron en la encuesta en función de la pregunta en la que dejaron.
Consejo Q: El porcentaje de progreso se calcula en función de todos los elementos de la encuesta, incluidos los elementos del flujo de la encuesta. Si su encuesta contiene muchos elementos, el porcentaje de progreso puede ser inferior al 1% incluso cuando se respondan las preguntas. El progreso menor al 1% se redondea al 0%.
Fecha de grabación
Esta columna indica cuándo se registró una encuesta en Qualtrics. En el caso de los usuarios que realizan la encuesta online, este valor de fecha y hora será similar a la End Date. No obstante, en el caso de las respuestas importadas o cargadas mediante la Aplicación offline, la RecordedDate será distinta a la EndDate, lo que refleja que los resultados se cargaron de forma manual, no cuando el encuestado terminó de responder.
Consejo Q: ¿Encuentra una diferencia de varios minutos entre la EndDate y la RecordedDate? Una conexión a Internet lenta puede crear un retraso entre la hora en la que el encuestado envía los datos de la encuesta y la hora en la que Qualtrics los almacena oficialmente en el sitio web.
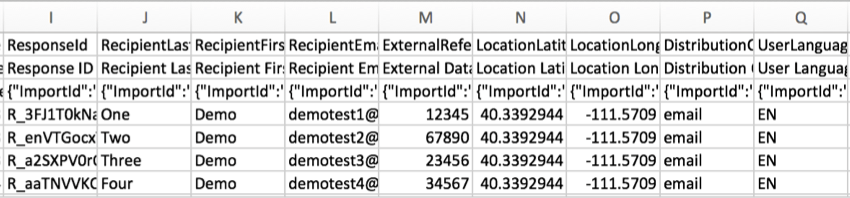
ResponseID
ResponseID es el ID que Qualtrics utiliza para identificar cada respuesta en la base de datos. Este identificador exclusivo se proporciona como referencia y no suele ser útil para analizar de datos.
Apellido del destinatario, Nombre del destinatario y Correo electrónico del destinatario
Los nombres y direcciones de correo electrónico de los encuestados se mostrarán en estas columnas si su encuesta se distribuyó mediante un lista de contactos . Algunas de las distribuciones comunes que utilizan listas de contactos incluyen:
- Enviar correos electrónicos a los encuestados de Qualtrics
- Enlaces individuales
- Autenticadores
- SMS (texto)
Para todas las demás respuestas, como las recogidas con un enlace anónimo o con cierta Opciones de Encuesta habilitadas , estas columnas estarán en blanco. Tenga en cuenta que cualquier distribución se puede anonimizar, independientemente del método de distribución.
Referencia de datos externos
Se utiliza con frecuencia al cargar un lista de contactos a Qualtrics para su uso en un autenticador y ocasionalmente en uncorreo electrónico distribución, se puede incluir una referencia a datos externos para cada participante. Este es un campo genérico que puede almacenar cualquier información que desee (y que se usa más a menudo con identificadores exclusivos como los ID de empleado o estudiante). Si se cargan datos de referencia externos para los encuestados, se mostrarán en esta columna. Si no ha optado por utilizar este campo, la columna estará en blanco.
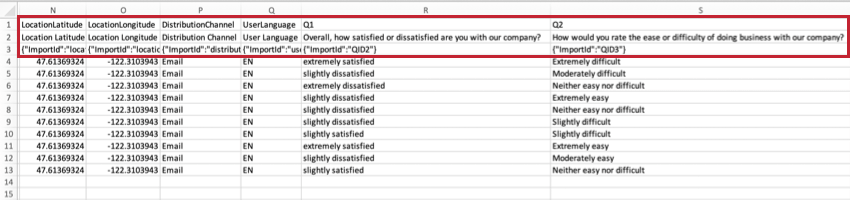
UbicaciónLatitud y UbicaciónLongitud
Si el encuestado completó la encuesta utilizando el Aplicación sin conexión de Qualtrics En un dispositivo con GPS, estos datos serán una representación precisa de la ubicación del encuestado.
En el caso de los demás encuestados, la ubicación es una aproximación determinada mediante la comparación de la dirección IP de un participante con la de una base de datos de ubicación. En los Estados Unidos, este dato suele indicar con exactitud la ciudad. Fuera de los Estados Unidos, este dato solo suele indicar con exactitud el país.
Estos datos no estarán disponibles si se han recibido respuestas. completamente anónimo .
Canal de distribución
Esta columna describe el método de distribución de la encuesta .
En el ejemplo anterior, la encuesta se envió por correo electrónico a los participantes.
Idioma del usuario
Si su encuesta tiene varios idiomas , del demandado código de idioma Se mostrará en esta columna.
Incluso si una encuesta solo tiene un idioma, cada respuesta debe tener datos en la columna UserLanguage, incluidas las vistas previas. La única excepción son las respuestas a la prueba, que tendrán una columna UserLanguage en blanco.
Respuestas a la pregunta
Las siguiente columnas del conjunto de datos muestran las respuestas proporcionadas para cada pregunta de la encuesta . Las columnas presentan como encabezado con los números de pregunta (por ejemplo, Q1) y, a continuación, las líneas iniciales del texto de la pregunta (por ejemplo, ¿Qué tan fácil fue comprender la asignación de lectura?).
Las preguntas simples (entrada de texto, opción múltiple – 1 respuesta, etc.) se incluirán en una columna, pero las preguntas más complejas con múltiples afirmaciones (tabla matriz , tabla combinada, etc.) se distribuirán en múltiples columnas.

De forma predeterminada, los datos se descargan en etiquetas (es decir, el texto exacto de las preguntas y respuestas). Sin embargo, también puede optar por exportarlo como valores (llamados “recodificar valores“) para cada opción de respuesta. Por ejemplo, en una escala de 5 puntos, “Totalmente de acuerdo” se mostrará como un “5”, lo que hará que resulte más sencillo encontrar la media o realizar otros análisis estadísticos.
Si la codificación numérica de tus opciones no coincide con tus expectativas, siempre puedes Regrese a la pestaña Encuesta para cambiarlas y luego exporte sus datos nuevamente. También puede Exporta tu encuesta a Word para recuperar un libro de códigos que describe cómo se codifica cada opción en el conjunto de datos.
Guía para tipos de preguntas específicas
A menudo, los datos exportados serán diferentes según los tipos de preguntas que elija incluir. Estas diferencias se explican en la página individual de la pregunta. A continuación exponemos enlaces a las secciones pertinentes.
- Opción múltiple (incluida la forma en que aparecen las exportaciones de respuestas múltiples)
- Tabla de matriz
- Entrada de texto
- Campo de formulario
- Slider
- Orden de preferencia
- Tabla combinada
- Suma constante
- Elige, agrupa y clasifica
- Punto caliente
- Mapa de calor
- Slider gráfico
- Desglose
- Net Promoter® Score
- Resaltado
- Firma
- Temporizador
- Meta info
- Carga de archivo
Preguntas sobre bloques de bucle y de combinación
Al visualizar sus datos, cada loop se trata como un conjunto separado de preguntas. Si tiene 5 posibles loops, verá las preguntas repetidas 5 veces en los datos. Incluso si un encuestado no se muestra en todos los loops, todos los loops posibles se representarán en los datos.
Resultados de puntuación
Para encuestas que utilizan Puntuación , la puntuación de cada categoría se incluye en el conjunto de datos. Cada categoría de puntuación obtiene su propia columna de datos. En el siguiente ejemplo, la encuesta solo tenía una categoría de puntuación, llamada “Legibilidad”.
La puntuación es una suma de los puntos que el encuestado ha acumulado en cada categoría; no es una media.
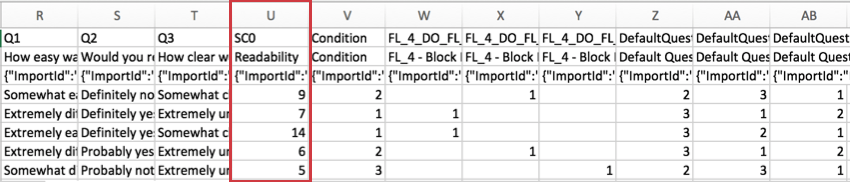
La “SC” en el encabezado significa “Categoría de puntuación”, y el número representa la categoría de número que es, contando desde cero. Debido a que la encuesta de ejemplo anterior tiene 1 categoría de puntuación, vemos SC0, pero si hubiera más, veríamos SC1, SC2, y así sucesivamente.
Datos embebidos
Para encuestas que utilizan datos embebidos La información de datos embebidos se incluye en las columnas que siguen a la información de puntuación .
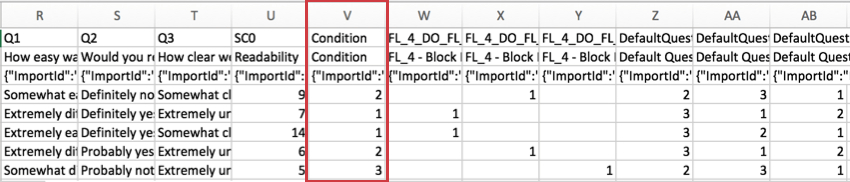
Solo los campos de Datos embebidos almacenados en el flujo de la encuesta se incluyen en el conjunto de datos descargado. Los campos de Datos embebidos con valores de una lista de contactos o una URL pueden guardarse en el flujo de la encuesta en cualquier momento anterior o posterior a la recopilación de datos.
Datos de aleatorización
Verá columnas de aleatorización después de los datos de respuesta. Habrá una columna para cada elemento aleatorizado de la encuesta. Por ejemplo, si aleatorizas un bloque con 5 preguntas, tendrás 5 columnas, una para cada pregunta. Si tuvieras una aleatorizador En su flujo de la encuesta con 7 elementos debajo, tendría 7 columnas, una para cada elemento que fue aleatorizado.
Si aleatoriza el orden de todos los elementos presentados, la columna mostrará el orden en el que se presentó el elemento, por ejemplo, 1, 2, 3, etc.
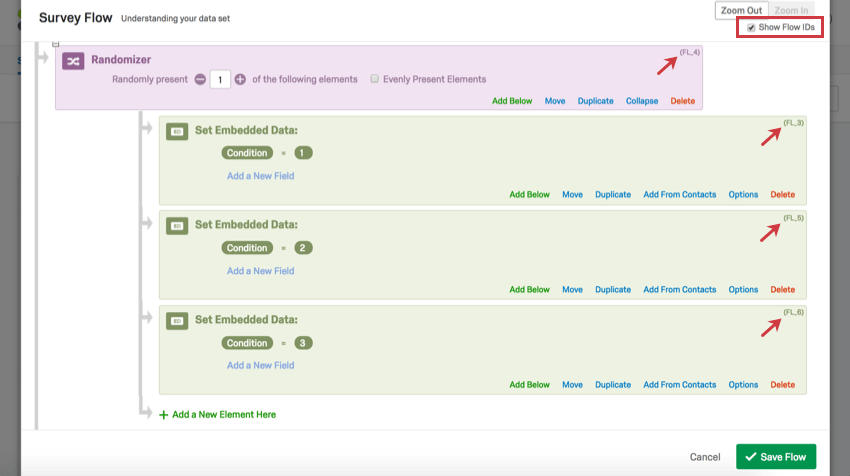
Ejemplo: En la siguiente captura de pantalla, el orden de las preguntas se aleatorizó y las columnas muestran el orden en el que aparece cada pregunta en la secuencia. Tenga en cuenta que los números de pregunta se encuentran en el encabezado.

Cuando se presenta aleatoriamente 1 elemento de una lista de varios, los elementos que se mostraron se marcarán como 1. Los elementos que no se mostraron al encuestado estarán en blanco.
Ejemplo: En el siguiente ejemplo, se presentó 1 elemento al azar de una lista de 3. Las columnas indican qué elemento se mostró al encuestado colocando un 1 debajo de la columna etiquetada con el elemento presentado.
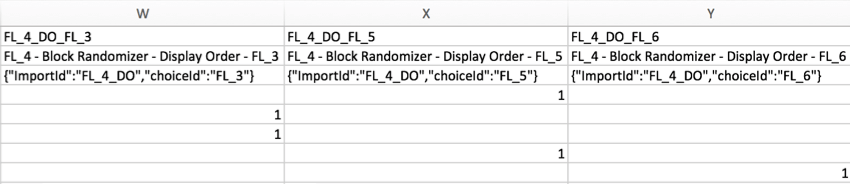
Consejo Q: ¿No sabe cómo leer los encabezados del segundo ejemplo? Como en este ejemplo se ha utilizado el aleatorizador del flujo de la encuesta, la columna muestra los ID del flujo en lugar de los ID de pregunta. Puede recuperar los ID del flujo si accede al flujo de la encuesta y selecciona Mostrar los ID del flujo de la encuesta en la esquina superior derecha. Los ID de flujo no se pueden editar.
Resolución de problemas de un archivo de datos
Esta sección tratará algunas preguntas y preocupaciones comunes que tienen muchos usuarios con respecto a su archivo de datos. También destacaremos algunas funciones útiles que puede utilizar para personalizar sus exportaciones de datos.
Guía para exportar datos y todas las opciones disponibles
Para obtener instrucciones sobre cómo exportar datos, consulte las siguientes páginas de soporte:
- Exportación de datos de respuesta: instrucciones y consejos paso a paso.
- Opciones de exportación de datos:Guía de opciones adicionales, como exportar datos aleatorios, etiquetar preguntas vistas pero sin respuesta, exportar en formato de valor vs. formato de etiqueta, etc.
- Formatos de exportación de datos: guía para diferentes tipos de archivo que puede exportar.
Personalización de las columnas incluidas en la exportación
Para personalizar las columnas en sus exportaciones:
- Seleccionar columnas desea exportar y deseleccione las columnas que no desea.
- Exporte sus datos con la opción Descargar todos los campos desmarcada.
Exportación de datos filtrados
Para exportar datos filtrados:
Funciones que no tienen datos para incluir en una exportación
Si ha incluido un texto descriptivo (como un párrafo de introducción sin pregunta adjunta) o una gráfico (como una imagen sin pregunta adjunta), estos campos no tendrán sus propias columnas en la exportación de datos, ya que no tienen respuestas para que el encuestado seleccione. Si se ha dado cuenta de que los números de preguntas se han “omitido” en la exportación de la encuesta, puede deberse a que tiene campos como este.
Sin embargo, si aleatorizó campos de texto o gráficos descriptivos a los encuestados, puede encontrarlos exportando datos aleatorios. Consulte Exportación de datos aleatorios para obtener instrucciones paso a paso y consulte Datos de aleatorización para obtener una guía sobre cómo leerlos.
Ciertas opciones de respuesta excluidas del archivo / Cómo excluir valores del análisis
Ver Excluir del análisis . Algunos valores, en función de cómo estén redactados, se excluyen de forma predeterminada. Estas respuestas se registran y se pueden volver a agregar a los datos en cualquier momento sin problemas.
Datos embebidos excluidos del archivo
Asegúrese de que el elemento de datos embebidos esté añadido al flujo de la encuesta y es tirando de todos los campos de contacto .
Para una solución de problemas más profunda con datos integrados, consulte las páginas de soporte enlazadas.
Otros campos excluidos del archivo
Asegúrate de tener Descargar todos los campos seleccionado Cuando exportas tus datos. Los datos aleatorios no se incluyen de forma predeterminada, pero se pueden añadir según estas instrucciones.
Ver más Opciones de exportación .
Personalizar numeración de preguntas
Ver Preguntas de numeración automática y Números de preguntas .
Personalizar la pregunta o la palabra de la respuesta en la exportación de datos, pero no en la encuesta
Puedes utilizar etiquetas de preguntas para cambiar la forma en que se formulan las preguntas en la exportación, sin afectar la forma en que las ven los encuesta . Puede utilizar nombres de variables para modificar el texto de las opciones de respuesta. Editar etiquetas de preguntas y nombres de variables en cualquier momento durante la recopilación de encuestas es un proceso seguro.
Las etiquetas de preguntas y los nombres de las variables también afectan la forma en que aparecen estos datos. resultados y informes .
El texto de las preguntas/respuestas difiere del editor de la encuesta
Si la redacción de las preguntas es diferente a la que ve en el editor de encuesta , verifique que no haya errores. etiquetas de preguntas agregado. Si el texto de sus respuestas difiere de lo que ve en el editor de encuestas, compruebe los nombres de sus variables en las opciones recodificadas. Si creó su encuesta a partir de una copia de una versión anterior, estas configuraciones se pueden transferir. Editar etiquetas de preguntas y nombres de variables en cualquier momento durante la recopilación de encuestas es un proceso seguro.
Problemas de exportación de CSV
Si su exportación CSV no se ve bien (por ejemplo, tiene símbolos en lugar del texto esperado o tiene columnas superpuestas), exporte los datos en TSV formato en su lugar. TSV es especialmente útil para datos que contienen caracteres especiales.
Para obtener más información sobre solución de problemas, consulte Problemas con los archivos CSV descargados .
Archivos de respuesta de Proyectos 360, Compromiso de los empleados, Ciclo de vida del empleado e Investigación ad hoc para empleados
Para 360, consulte Comprender su conjunto de datos de respuesta (360) .
Para todos los demás proyectos EX , consulte Comprender su conjunto de datos de respuesta ( EX) .
Diferencias de formato de fichero
Aunque todos los tipos de archivo descargan los mismos campos de datos ya mencionados, cada uno tiene un diseño que puede ser ligeramente diferente.
Programa estadístico SPSS
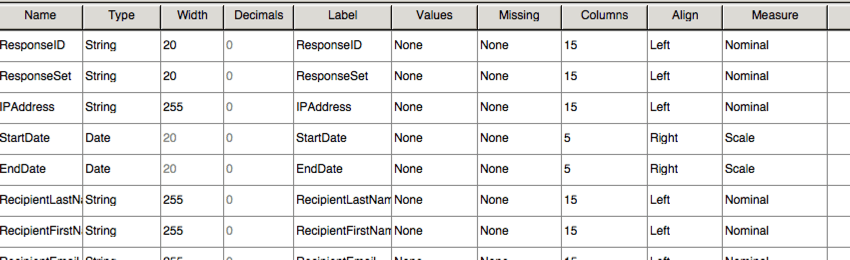
La vista de datos en SPSS incluye exactamente el mismo diseño que el archivo CSV , con menos encabezados.
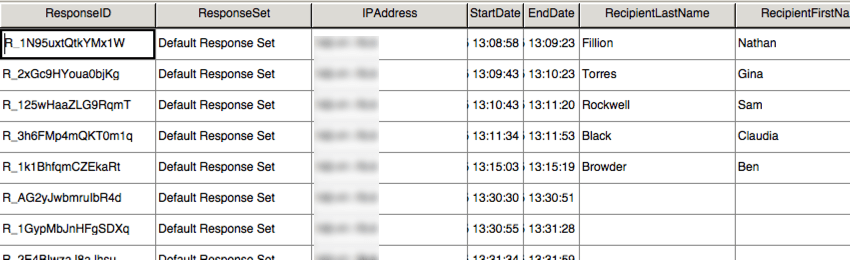
SPSS incluye otra vista, llamada Vista de variable. Esta vista muestra todas las variables del conjunto de datos con información sobre cada una, como el tipo de variable y los valores posibles.
XML
El tipo de archivo XML se utiliza a menudo al integrar datos de Qualtrics con una base de datos de terceros. Este tipo de archivo pueden analizarlo fácilmente el software de base de datos común.
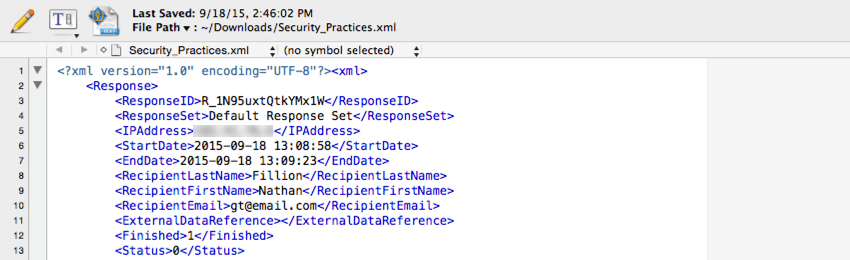
Se proporciona un elemento XML para cada respuesta, con un elemento secundario para cada pieza de datos almacenada en esa respuesta.