-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Regresión e importancia relativa
Acerca de la regresión y la importancia relativa
La regresión muestra cómo varias variables de entrada juntas impactan una variable de salida. Por ejemplo, si ambas entradas “Años como cliente” y “Tamaño de la empresa” están correlacionadas con la salida “Satisfacción” y entre sí, puede usar la regresión para determinar cuál de las dos entradas fue más importante para crear “Satisfacción”.
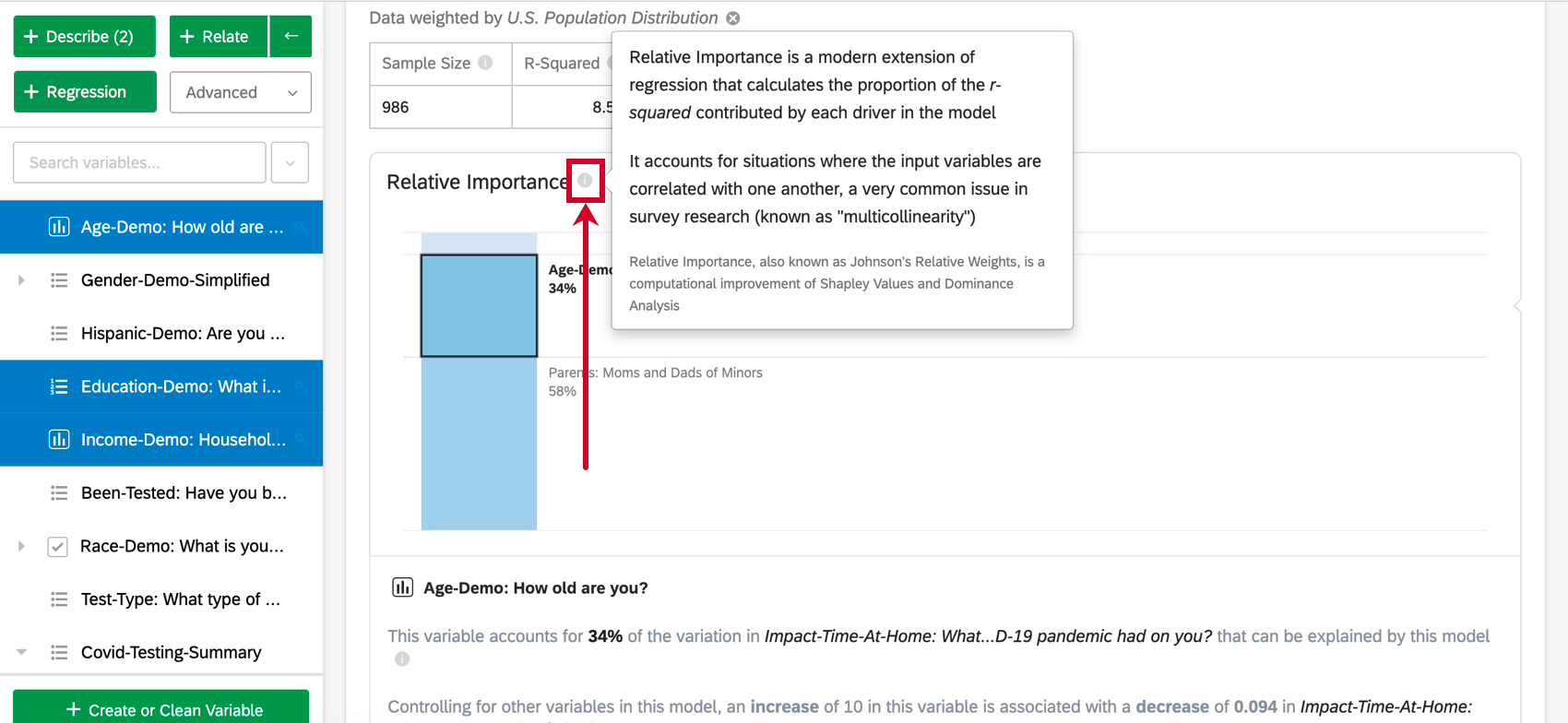
Análisis de importancia relativa es el método de mejores prácticas para la regresión de datos de encuesta y la salida predeterminada de las regresiones realizadas en Stats iQ. La importancia relativa es una extensión moderna de la regresión que tiene en cuenta situaciones en las que las variables de entrada están correlacionadas entre sí, un problema muy común en las investigaciones encuesta (conocido como “multicolinealidad”). La importancia relativa, también conocida como pesos relativos de Johnson, es una variación del análisis de Shapley y está estrechamente relacionada con el análisis de dominancia.
A continuación encontrará instrucciones sobre cómo configurar una regresión en Stats iQ. Para obtener más orientación sobre cómo pensar en las partes analíticas del análisis de regresión, consulte las siguientes páginas:
- Guía fácil de usar para la regresión lineal
- Interpretación de gráficos residuales para mejorar la regresión lineal
- Guía de fácil uso para la regresión logística
- La Matriz de confusión y el equilibrio entre precisión y recuperación en la regresión logística
Para la regresión lineal, la importancia relativa en Stats iQ sigue las técnicas descritas en Lipovetsky, Stan y Conklin, Michael. (2001). Análisis de regresión en el enfoque de teoría de juegos. Modelos estocásticos aplicados en los negocios y la industria. 17. 319 – 330. 10.1002/asmb.446.
Para la regresión logística, la importancia relativa en Stats iQ sigue las técnicas descritas en Tonidandel, Scott & LeBreton, James. (2009). Determinación de la importancia relativa de los predictores en la regresión logística: una extensión del análisis de peso relativo. Métodos de Investigación Organizacional – MÉTODOS ORGAN RES. 12. 10.1177/1094428109341993.
Selección de variables para tarjetas de regresión
La creación de una tarjeta de regresión le permitirá comprender cómo el valor de una variable en su conjunto de datos se ve afectado por los valores de otras.
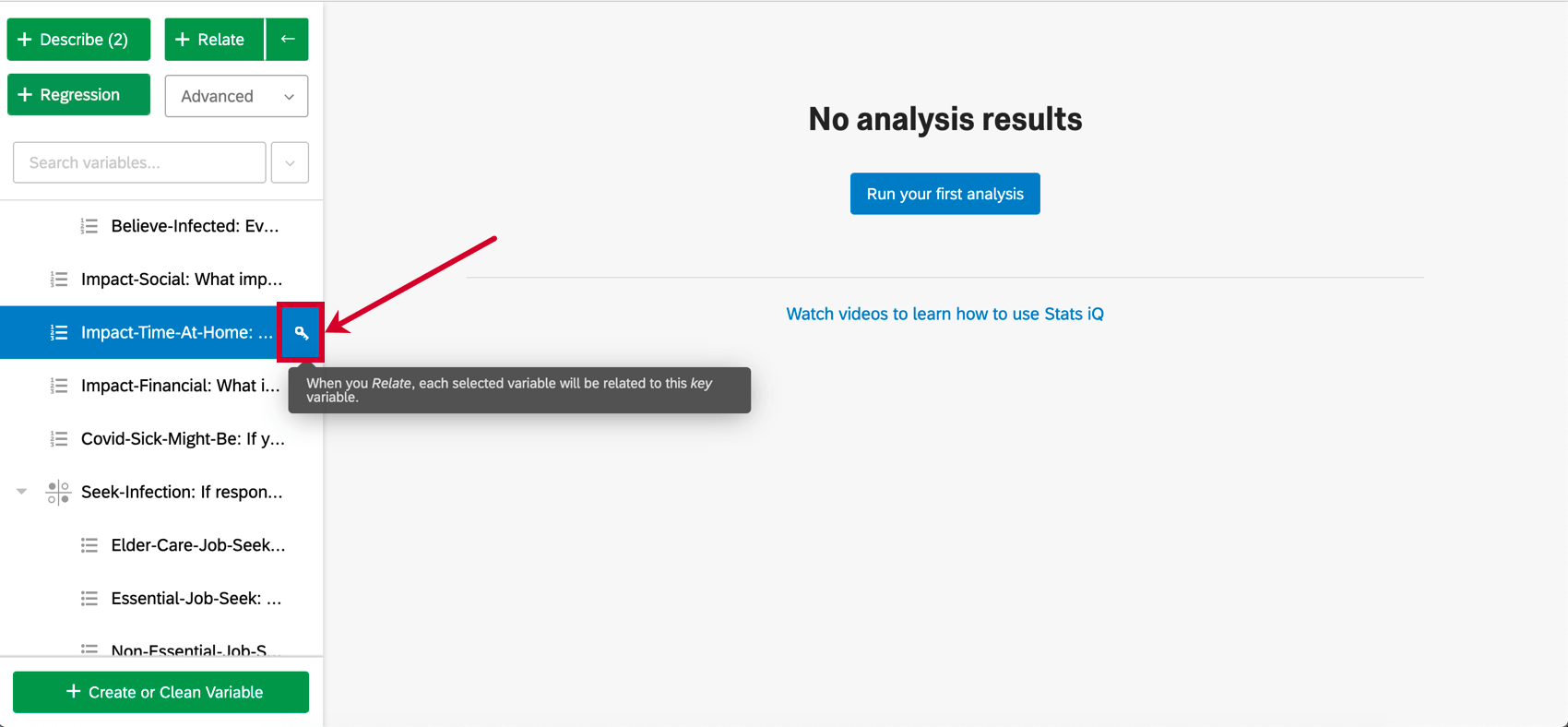
Al seleccionar variables, cada variable tendrá una clave junto a ella. Para la regresión, la variable clave será la variable de salida. Cada otra variable seleccionada después de la variable clave será una variable de entrada. En otras palabras, estamos tratando de explicar cómo el valor de la variable de salida depende de las variables de entrada.
Aspectos a tener en cuenta al seleccionar variables para la regresión:
- Puede cambiar la variable clave haciendo clic en el ícono de llave siguiente a cualquier variable en el panel de variables.
- Si se seleccionan más variables que el número de respuestas que tiene, la regresión no se ejecutará.
- Puede seleccionar hasta 25 variables de entrada. Sin embargo, debe intentar seleccionar entre 1 y 10 variables de entrada o sus resultados podrían volverse muy complicados.
Si tiene una gran cantidad de variables que desea incluir en un análisis, considere los siguientes enfoques:
- Ejecute algunas regresiones iniciales y excluya las variables que tienen muy poca importancia en el modelo.
- Combine varias variables, por ejemplo, promediándolas.
- Si la estructura de sus datos lo permite, puede utilizar un proceso de importancia relativa de dos pasos, como se describe en la página 341 aquí.
Ejemplo: Por ejemplo, imagina que tienes diez medidas de Autonomía del empleado satisfacción y diez medidas de satisfacción de los empleado con la compensación.
- Promedia esos grupos en dos variables de resumen diferentes: una para autonomía y uno para compensación.
- Ejecute un análisis de importancia relativa con Satisfacción general como salida y las dos variables de resumen como entrada para ver qué grupo es más importante.
- A continuación, ejecute un análisis de importancia relativa con Satisfacción general como la salida y solo los diez autonomía variables como entradas para ver cuáles son las más importantes dentro de ese grupo.
- Ejecute un análisis de importancia relativa con Satisfacción general como la salida y solo los diez compensación variables como entradas para ver cuáles son las más importantes dentro de ese grupo.
Una vez que haya seleccionado sus variables, haga clic en Regresión para ejecutar una regresión.
Consejo Q: En la parte superior de la tarjeta de regresión habrá una línea verde (y a veces roja). Si hace clic en él, verá la cantidad de respuestas marcadas como “Incluidas” o “Faltantes” para esa tarjeta específica.
- Incluido:Encuestados que respondieron la pregunta para cada una de las preguntas o puntos de datos utilizados en el análisis de regresión, o cuyos datos para las variables de entrada faltantes fueron imputados. Estos datos se utilizarán en el análisis de regresión.
- Desaparecido:Encuestados a quienes les falta un valor para la variable dependiente del resultado. Estos datos no se utilizarán en el análisis de regresión.
Tipos de regresión
Hay dos tipos principales de ejecución de regresión en Stats iQ. Si la variable de salida es una variable numérica, Stats iQ ejecutará una regresión lineal. Si la variable de salida es una variable de categorías, Stats iQ ejecutará una regresión logística.
Más específicamente, los tipos de regresión que ejecutará Stats iQ son los siguientes:
Regresión lineal
La importancia relativa se combina con los mínimos cuadrados ordinarios (MCO). El resultado proviene de una combinación de los dos análisis:
- Importancia relativa:Todo en esta sección proviene de Importancia Relativa excepto el r-cuadrado, que proviene de la regresión MCO.
- Explora el modelo en detalle:Todo en esta sección proviene de Importancia Relativa excepto las distribuciones, que se extraen de los datos mismos.
- Analice los diagnósticos y residuos de regresión OLS para mejorar su modelo:Todo lo que aparece en esta sección proviene de la regresión OLS.
Regresión logística
La regresión logística es un método de clasificación binaria que se utiliza para comprender los impulsores de un resultado binario (por ejemplo, Sí o No) dado un conjunto de variables de entrada. Si ejecuta una regresión en una variable de salida con más de dos grupos, Stats iQ seleccionará un grupo y agrupará los demás para convertirla en una regresión binaria (puede cambiar qué grupo se está analizando después de ejecutar la regresión).
Importancia relativa
Las variables de entrada en los datos de una encuesta suelen estar altamente correlacionadas entre sí; este es un problema llamado “multicolinealidad”. Esto puede generar una salida de regresión que aumenta artificialmente la importancia de una variable y disminuye la importancia de otra variable correlacionada. La importancia relativa se reconoce como el mejor método práctico para tener esto en cuenta .
La importancia relativa (específicamente los pesos relativos de Johnson) no sufre este problema y equilibrará adecuadamente la importancia de las variables de entrada, independientemente del tipo de regresión que se esté ejecutando. También calcula el peso relativo de cada variable (o importancia relativa), la proporción de variación explicable en el resultado debido a esa variable. Esto se muestra como una serie de porcentajes que suman 100%.
Devuelve resultados similares a la ejecución de una serie de regresiones, una para cada variación de las variables de entrada. Por ejemplo, si tuviera dos variables, haría el equivalente a ejecutar tres regresiones: una con la variable A, una con la variable B y una con ambas. Esto le permite cuantificar la importancia de cada variable y aplicar esa cuantificación al resultado de la regresión.
Salida de regresión
Cuando se ejecuta una regresión en Stats iQ, los resultados del análisis contienen las siguientes secciones:
Resumen numérico
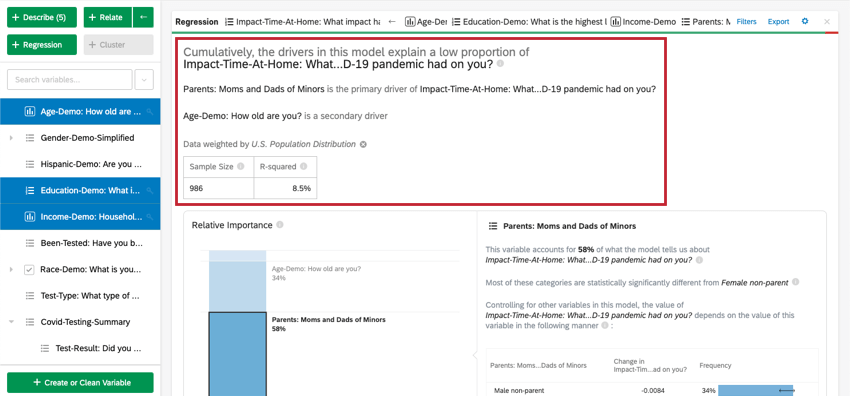
En la parte superior de la tarjeta hay un resumen del análisis de regresión. Al observar las variables elegidas, este resumen escrito explica cuáles son los impulsores primarios y secundarios, así como los impulsores que tuvieron un impacto acumulativo bajo. La tabla de datos incluye el tamaño de la Muestra y el valor R-cuadrado.
Importancia relativa
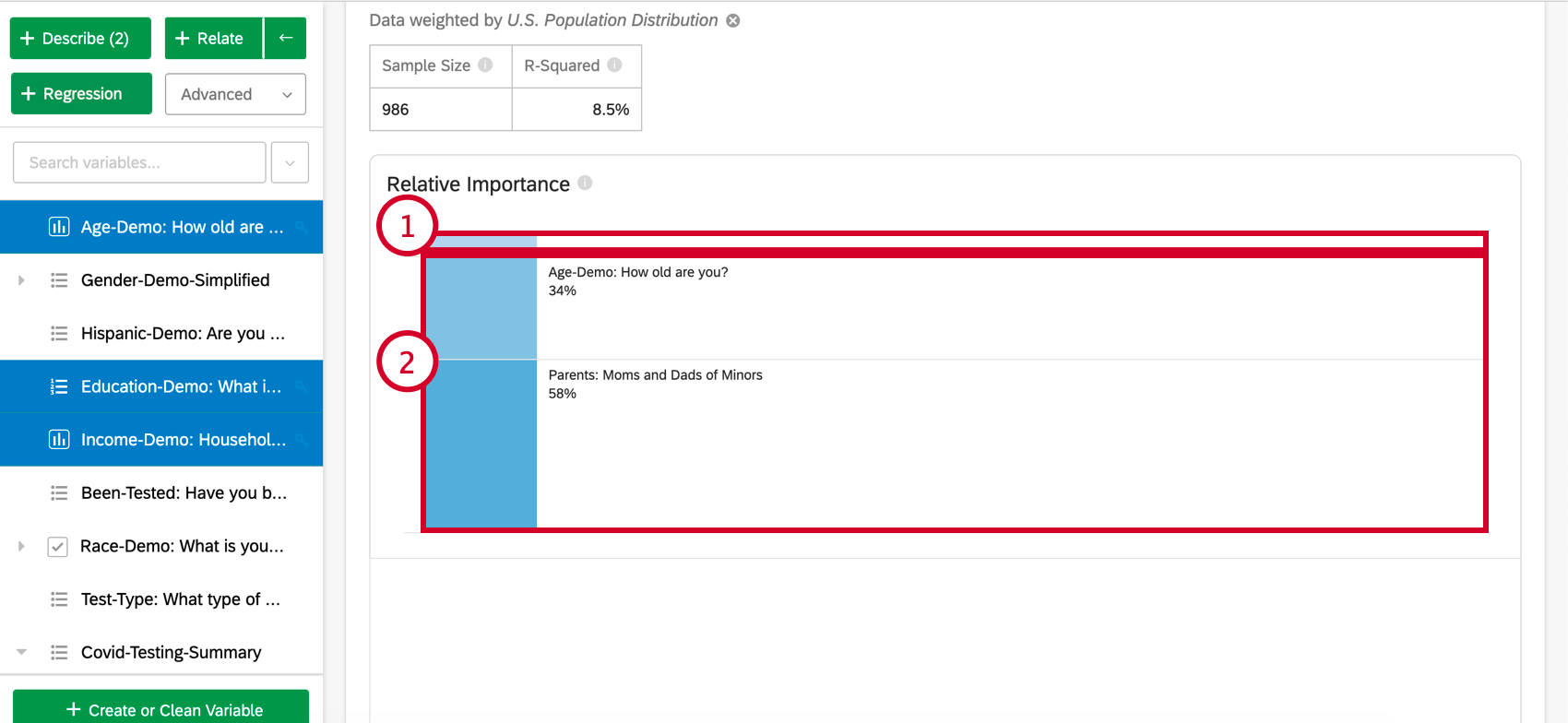
- Variables de bajo impacto:Las variables que individualmente tengan una importancia relativa del 10% o menos se agruparán. Cuando se selecciona, habrá una sección que explica la importancia relativa y la significancia estadística de cada variable de bajo impacto.
- Variables de alto impacto:Cada variable de alto impacto será independiente y se podrá hacer clic en ella. Una vez seleccionada una variable, debajo del gráfico de barras, podrá ver la variación tomada en cuenta y lo que sucedería si se controlaran otras variables en el modelo.
Detalles adicionales del modelo
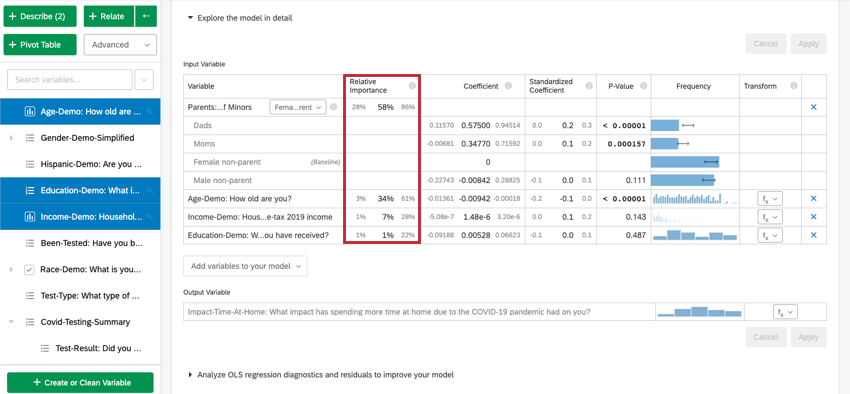
Cuando seleccionas Explora el modelo en detalleVerá sus variables de entrada y sus variables de salida enumeradas. Sus variables de entrada vendrán con la siguiente información:
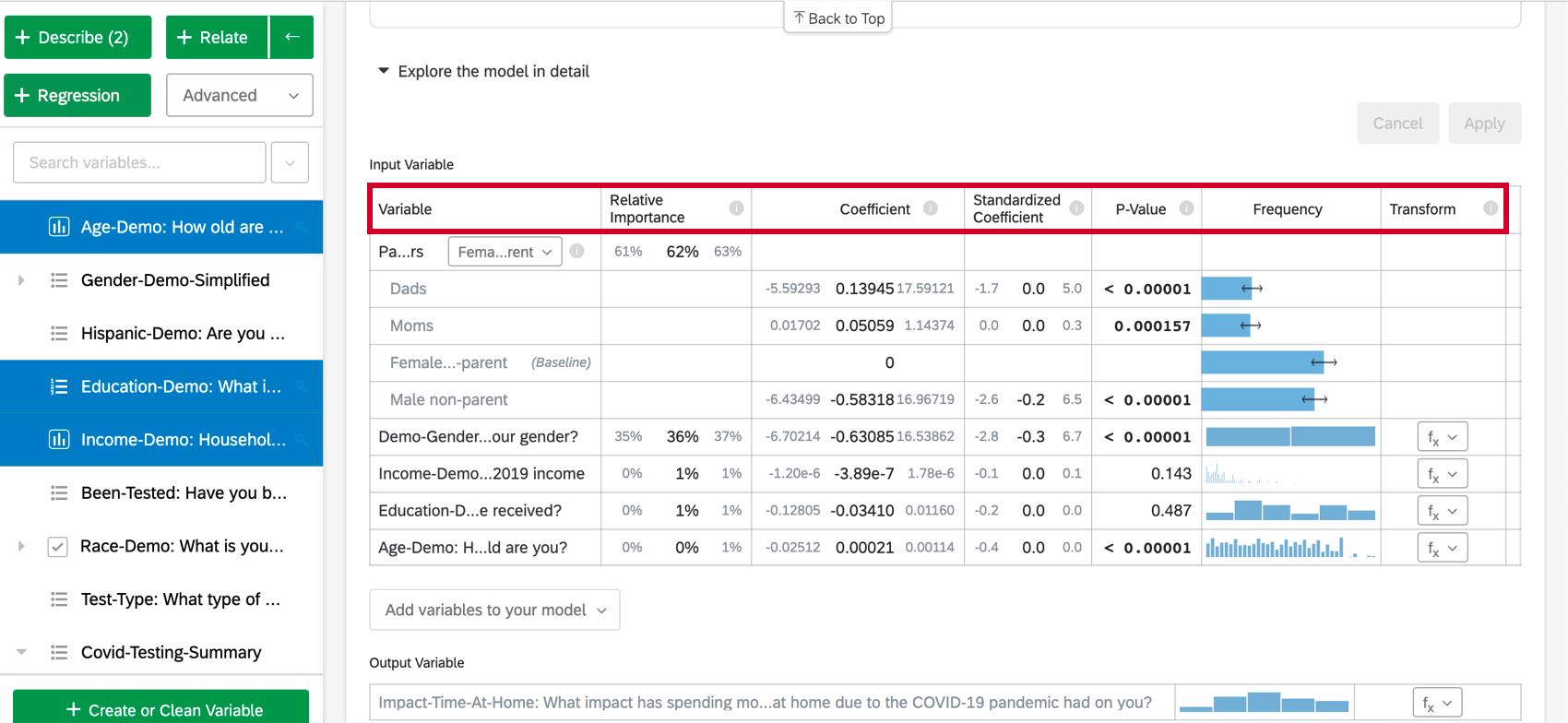
- Importancia relativa: La proporción del r-cuadrado que aporta una variable individual. El r-cuadrado es la proporción de la variación de la variable de resultado que puede explicarse por las variables de entrada en este modelo. Ver Importancia relativa Para más detalles.
- Razón de probabilidades: Sólo relevante para regresión logística. La razón de probabilidades para una variable de entrada dada indica el factor por el cual las probabilidades cambian por cada aumento de unidad en la variable explicativa.
Ejemplo: Por ejemplo, si la razón de probabilidades para Satisfacción con el Gerente es 1.1 y los grupos de la variable de salida son Satisfecho y No satisfecho, entonces para cada instancia en la que Satisfacción con el Gerente es 1 más alto, las probabilidades de la variable de salida de ser Satisfecho son 1,1 más altos (10% más altos). Si la fila de datos es una categoría, como color[azul], el coeficiente representa el cambio en las probabilidades de la variable de respuesta si la variable Categorías es esa categoría particular (azul) en lugar del grupo “base” (rojo, verde, etc.).
- Coeficiente: Cada aumento de 1 unidad en una variable de entrada está asociado con un aumento del coeficiente en la variable de salida. Estos coeficientes se construyen con base en los resultados del análisis de importancia relativa y, por lo tanto, se ajustan a la multicolinealidad y no coinciden con los coeficientes que resultarían de una regresión de mínimos cuadrados ordinarios estándar.
- Coeficiente estandarizado: El coeficiente estandarizado es el coeficiente dividido por la varianza de la variable de entrada. Esto coloca cada variable en la misma escala para que sus coeficientes puedan compararse más directamente.
- Valor P: El valor p es la medida de significancia estadística. Los valores más bajos se asocian con menores probabilidades de que la relación sea una coincidencia. Para las variables categóricas, el valor p indica la significancia estadística de la diferencia entre un grupo y el grupo “base” en la variable.
- Transformar: Ver Transformación de variables.
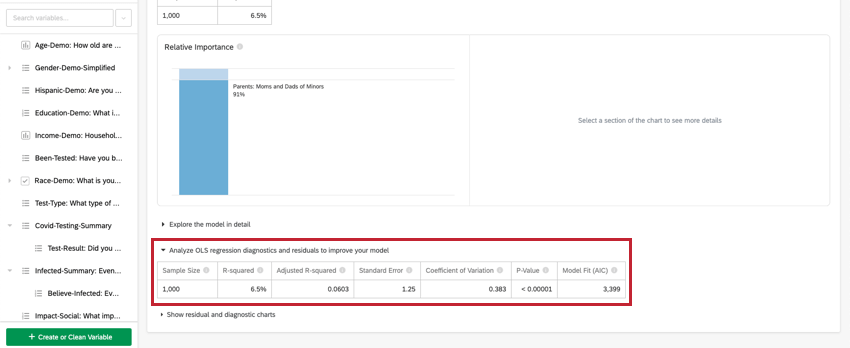
Análisis de regresión MCO
Para la regresión lineal, haga clic en Analice los diagnósticos y residuos de regresión OLS para mejorar su modelo debajo de la variable clave/salida para ver los gráficos de Predicho vs. Real y Residuos. Ver Interpretación de gráficos residuales para mejorar la regresión Para más información.
Variable incluida
A lo largo del encabezado superior de la tarjeta de regresión, verá las variables utilizadas en la regresión.
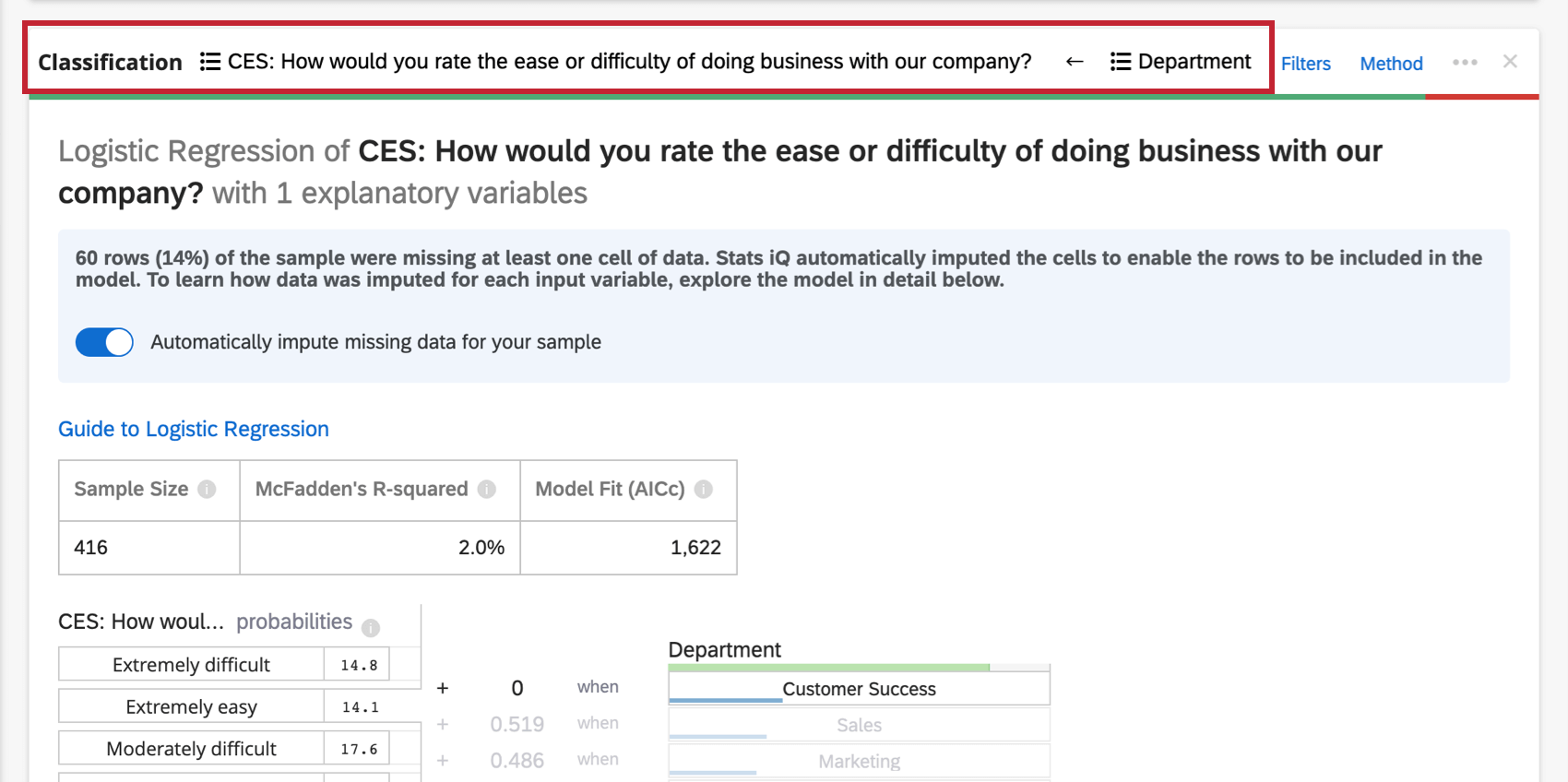
Haga clic en el nombre de una variable para abrir una nueva ventana donde podrá recodificar o balde valores. Haga clic en las flechas para cambiar cuáles son las variables de entrada y cuáles son las variables de salida en el análisis.
Si hay demasiadas variables involucradas para mostrar en el encabezado, habrá un Variables explicativas menú desplegable donde puede elegir entre las variables que desea recodificar.
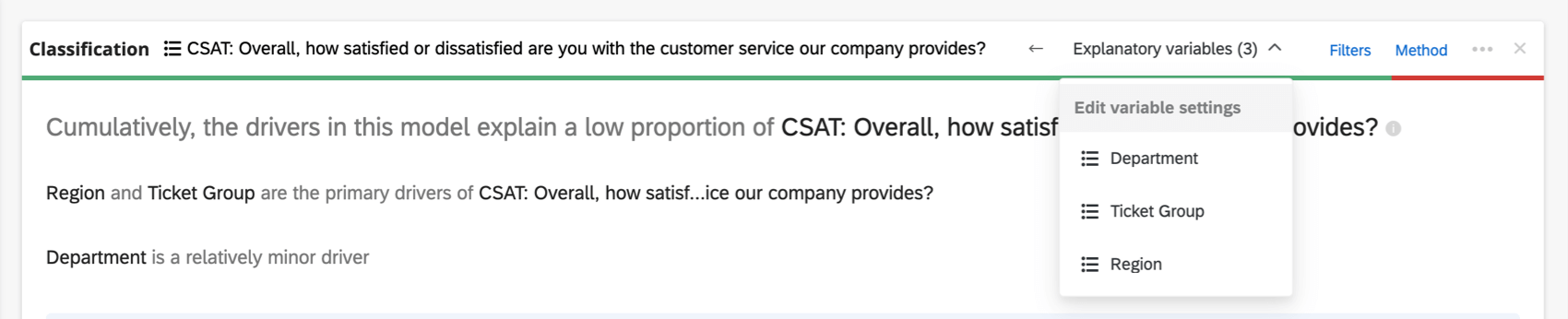
Agregar y eliminar variables
Una vez que haya creado una tarjeta de regresión, puede agregar variables adicionales al análisis siguiendo los pasos a continuación:
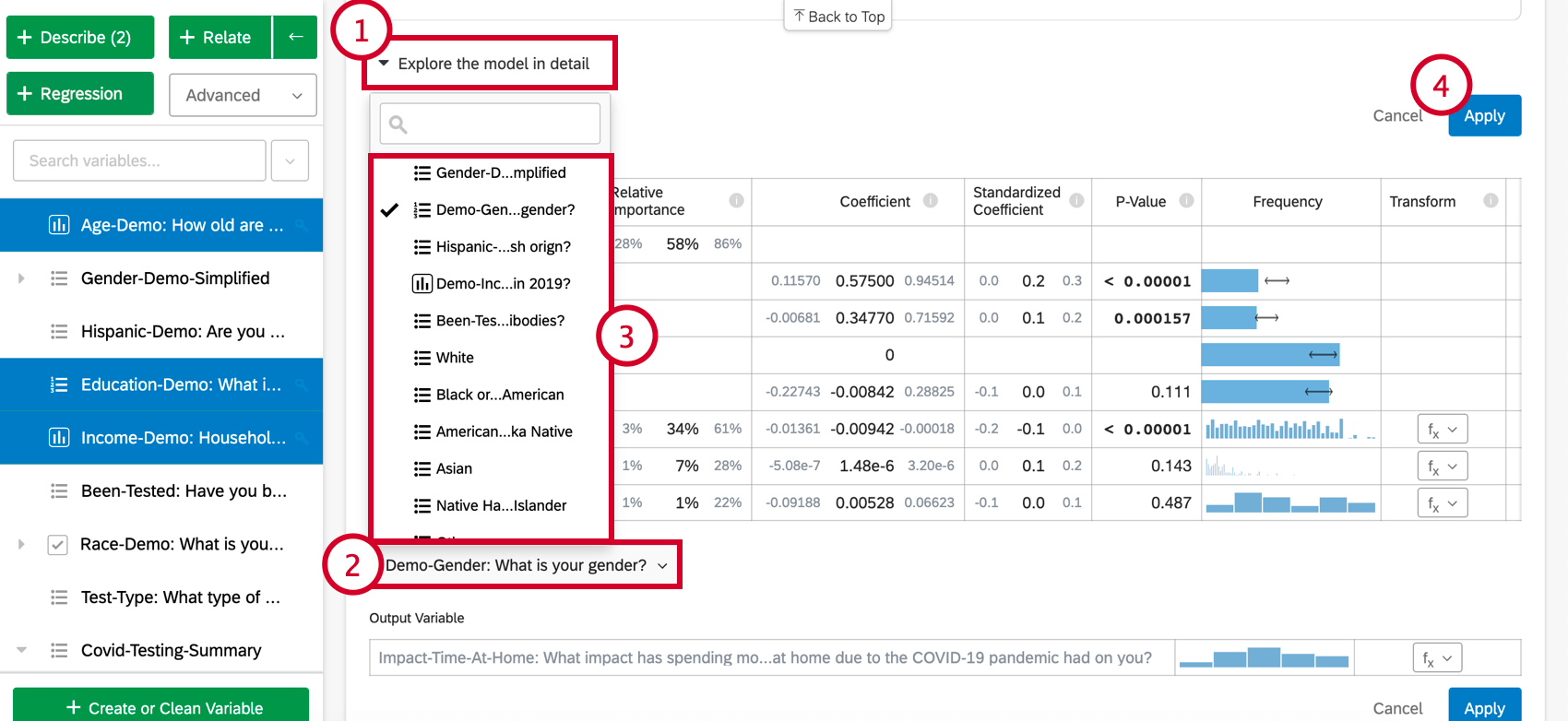
- Hacer clic Explora el modelo en detalle.
- Seleccionar Añade variables a tu modelo En la parte inferior de la tarjeta. Esto mostrará una lista de variables que aún no se han utilizado para la regresión.
- Elija una variable de esta lista.
- Hacer clic Aplicar para ejecutar el análisis nuevamente con la nueva variable incluida.
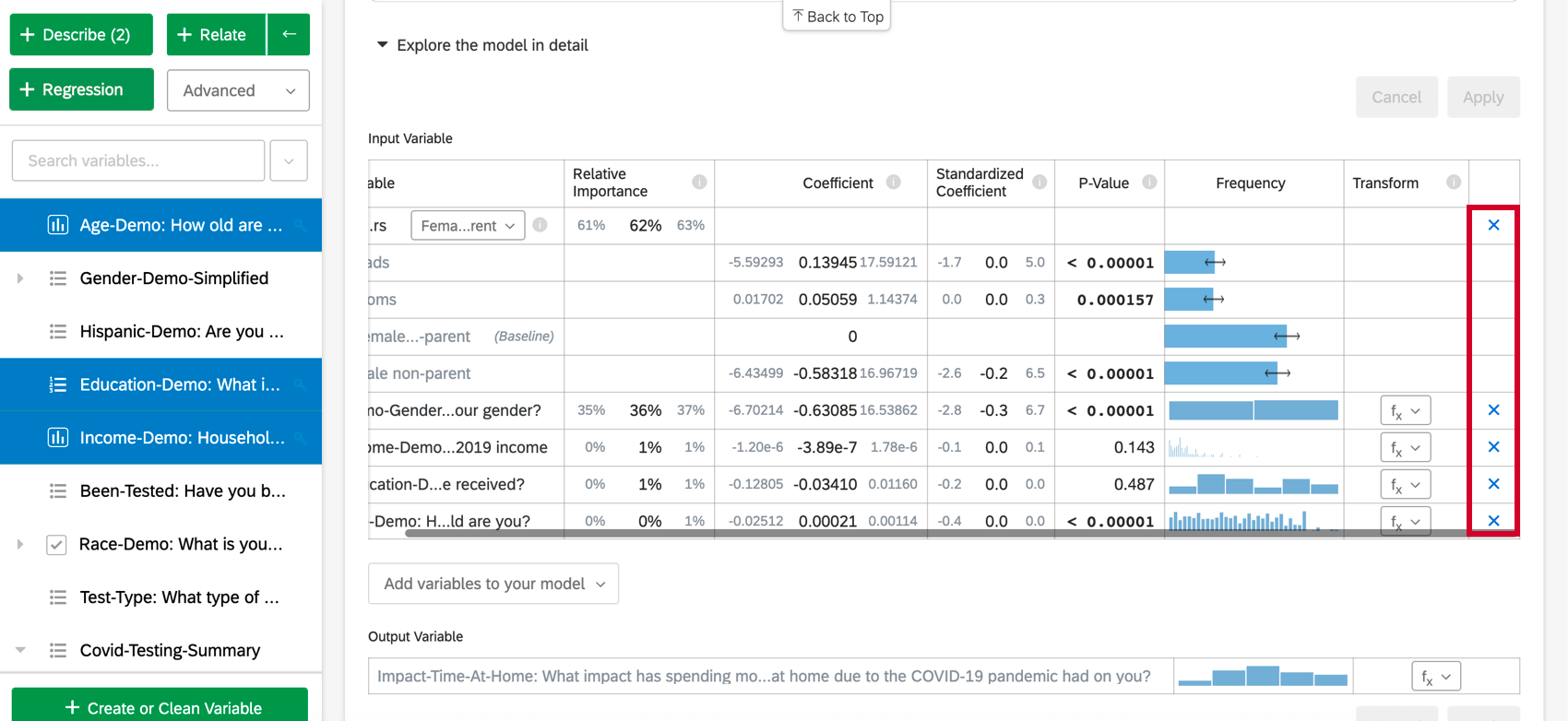
Para eliminar una variable de la regresión, pase el cursor sobre la variable deseada y haga clic en el botón azul. incógnita en el extremo derecho de la mesa. Después de elegir las variables que desea agregar o eliminar, asegúrese de seleccionar “Aplicar” para ejecutar el nuevo modelo.
Imputación de variables
La regresión solo considerará las filas donde todas las variables de entrada tengan datos. Sin embargo, a menudo faltan datos en la recopilación de datos de encuesta , lo que puede afectar negativamente el análisis y el modelo de regresión. Si solo incluye filas que no tienen datos faltantes en su regresión, los resultados de su análisis pueden estar sesgados porque su muestra no es representativa de todo su conjunto de datos.
Con la imputación, Stats iQ completará automáticamente los datos faltantes con valores estimados. Cuando se completan los datos faltantes, puede incluir más datos originales en el análisis de regresión, lo que da como resultado un modelo de regresión con menos sesgo que puede explicar mejor la variación en la variable de resultado deseada.
La imputación es automática, por lo que cuando ejecuta un análisis de regresión en un conjunto de datos con valores faltantes, su conjunto de datos se imputará antes de que se realice cualquier cálculo.
- Haga clic aquí para ver un conjunto de datos de ejemplo antes y después de la imputación de variables.
- Antes de la imputación:
Para esta regresión, “Uso de datos” es la variable de resultado y “Edad”, “Servicio de Internet” y “Minutos de tiempo frente a pantalla” son las variables de entrada.Identificación de fila Uso de datos Edad Servicio de Internet Tiempo de pantalla (minutos) 1 75 39 Satelital 503 2 19 41 Fibra óptica 52 3 87 434 4 54 23 Satelital 5 14 101 6 75 Satelital 7 81 57 DSL 329 Atención: Si ejecutara una regresión sin completar los valores faltantes, solo se incluirían las filas 1, 2 y 7.Después de la imputación:
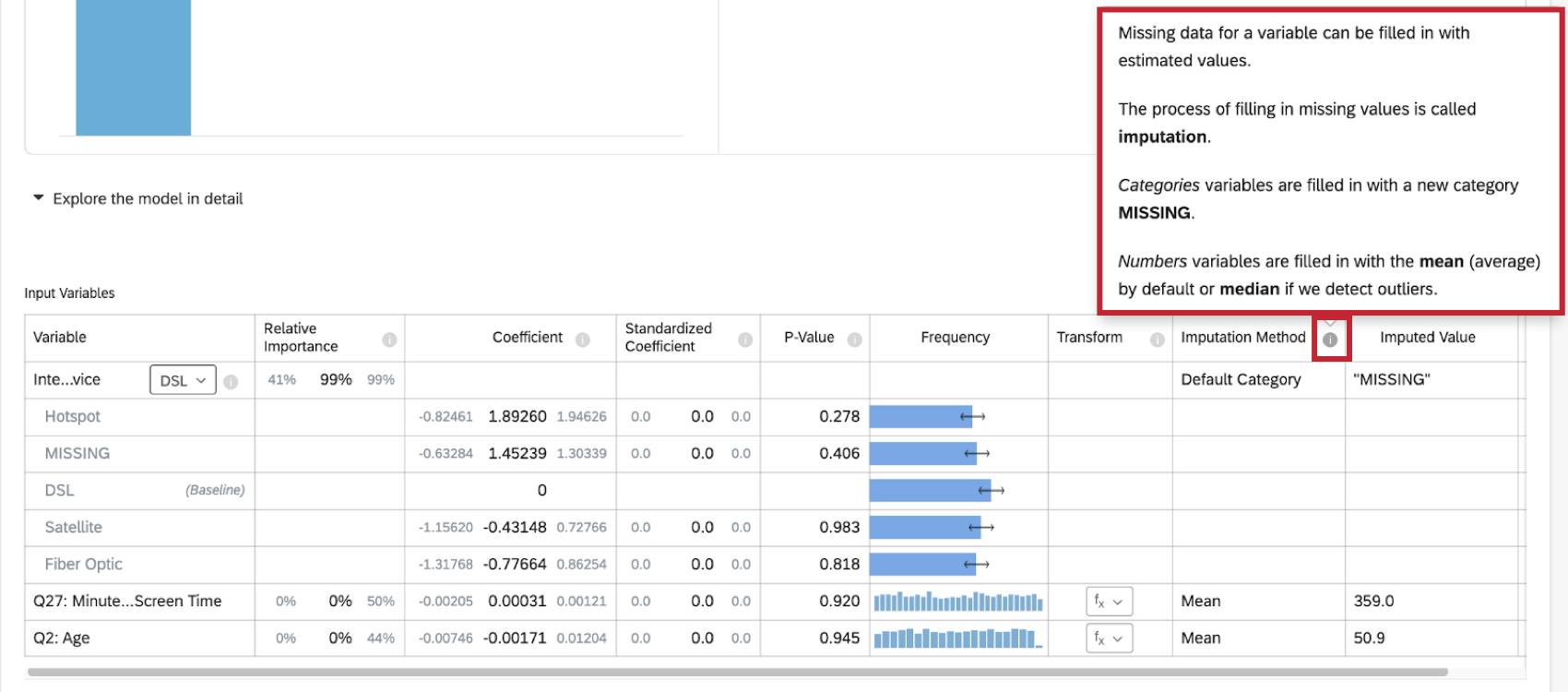
Identificación de fila Uso de datos Edad Servicio de Internet Tiempo de pantalla (minutos) 1 75 39 Satelital 503 2 19 41 Fibra óptica 52 3 87 50.9 FALTANTE 434 4 54 23 Satelital 359.0 5 14 50.9 FALTANTE 101 6 75 50.9 Satelital 359.0 7 81 57 DSL 329 Consejo Q: “Servicio de Internet” es una variable categórica, no numérica, por lo que el valor faltante se completa como “FALTANTE”.
Métodos de imputación
Stats iQ utiliza actualmente los siguientes métodos de imputación:
- Categoría predeterminada: Stats iQ creará un nuevo valor de categoría “FALTANTE” para completar los datos faltantes. Este método se utiliza para variables categóricas.
- Significar:Si Stats iQ no detecta valores atípicos en la distribución de la variable numérica, entonces los datos faltantes para la variable se completan con el valor medio (promedio). Este método se utiliza para variables numéricas.
- Mediana:Si Stats iQ detecta valores atípicos en la distribución de la variable numérica, los datos faltantes para la variable se completan con el valor mediano. Este método se utiliza para variables numéricas.
Indicadores de imputación
Cuando realice un análisis de regresión en el conjunto de datos, verá un indicador de imputación en la parte superior de la tarjeta de regresión.
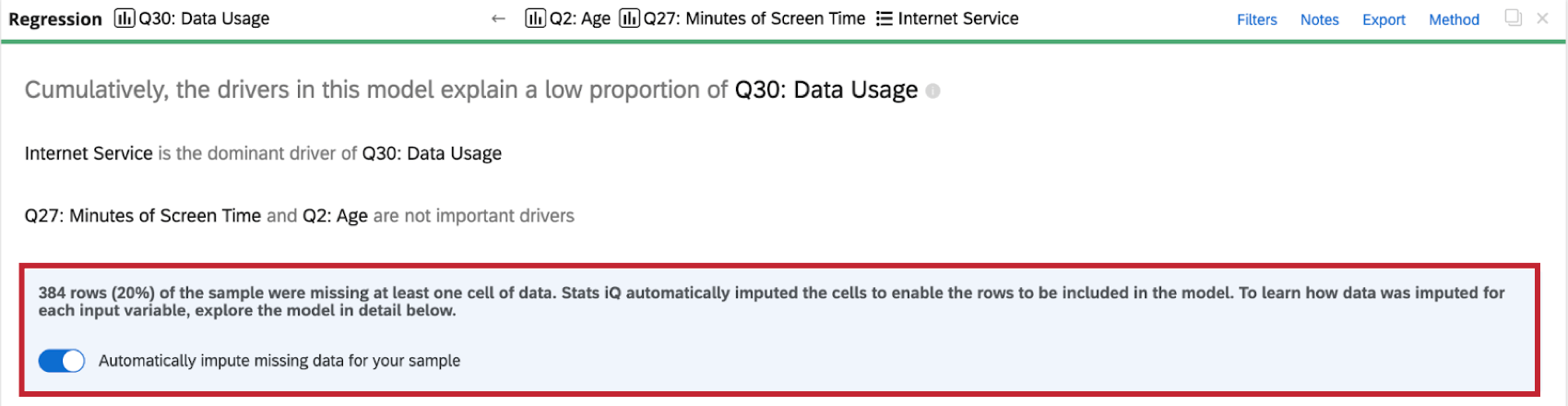
Puede obtener más información sobre la imputación haciendo clic en el símbolo de información ( i ) siguiente a Método de imputación.
Deshabilitar la imputación
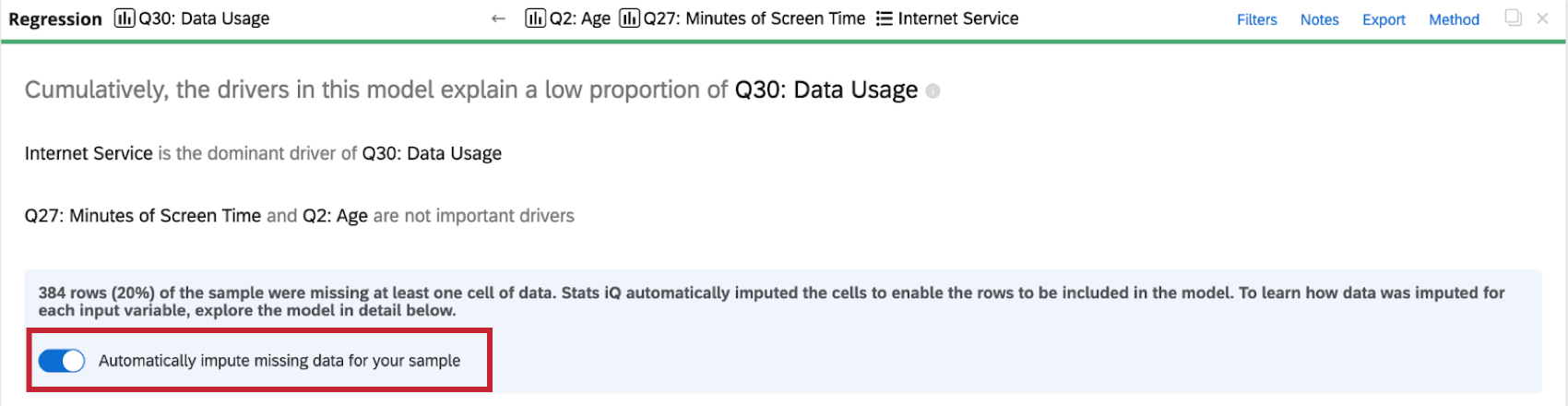
Stats iQ aplica automáticamente la imputación a todas las tarjetas de regresión. Para desactivar la imputación automática, haga clic en Imputa automáticamente los datos faltantes para tu muestra en la parte superior de la tarjeta de regresión.
Advertencias de imputación
- Si se imputan demasiados datos, el modelo de regresión se volverá sesgado y poco confiable. Cuando se haya completado más del 50% de su conjunto de datos, Stats iQ le advertirá acerca de sacar conclusiones de los resultados de su regresión.

- Cuando se detectan valores atípicos en cualquiera de las variables de entrada numéricas, Stats iQ imputará las variables utilizando el valor mediano en lugar de la media. En este escenario, Stats iQ le avisará cuando explore el modelo en detalle.

Transformación de variables
Al ejecutar un análisis de regresión en Stats iQ, es posible que descubra que necesita mejorar su modelo. La forma más común de mejorar un modelo es transformar una o más variables, generalmente utilizando un “logaritmo” u otra transformación funcional.
La transformación de una variable cambia la forma de su distribución. En general, los modelos de regresión funcionan mejor con distribuciones más simétricas y en forma de campana. Pruebe distintos tipos de transformaciones hasta encontrar una que le proporcione este tipo de distribución.
Para transformar una variable:
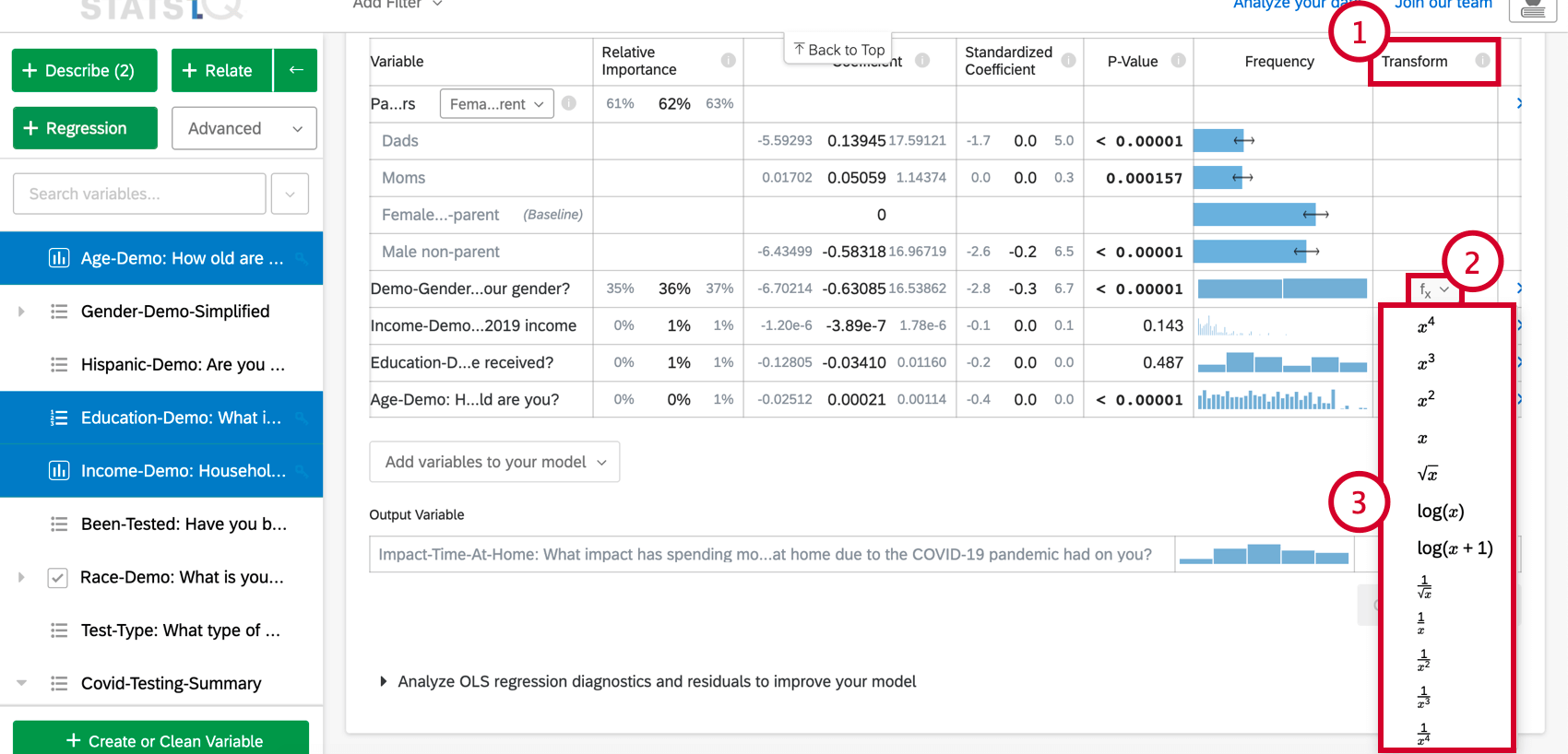
- Bajo el Explora el modelo en detalle opción, desplácese hasta la Transformar columna.
- Haga clic en la función (f(x)) correspondiente a la variable que desea transformar.
- De la lista, elija la función que desea aplicar y Stats iQ recalculará la tarjeta utilizando la nueva variable transformada.
Las siguientes transformaciones están disponibles en Stats iQ:
![]()
La transformación más común con diferencia es log(x). Transforma una distribución de “poder” (como el tamaño de la población de una ciudad) que tiene muchos valores más pequeños y una pequeña cantidad de valores más grandes en una “ distribución normal” en forma de campana (como la altura) donde la mayoría de los valores se agrupan hacia el medio.
Utilice log(x+1) si la variable que se está transformando tiene algunos valores de cero, ya que log(x) no se puede calcular cuando x es cero.
Para obtener más detalles sobre cuándo transformar sus variables, consulte Interpretación de gráficos residuales para mejorar la regresión lineal
Otras técnicas de regresión lineal disponibles en Stats iQ
La importancia relativa combinada con los mínimos cuadrados ordinarios es la salida predeterminada para una regresión lineal. Sin embargo, existen otras opciones disponibles.
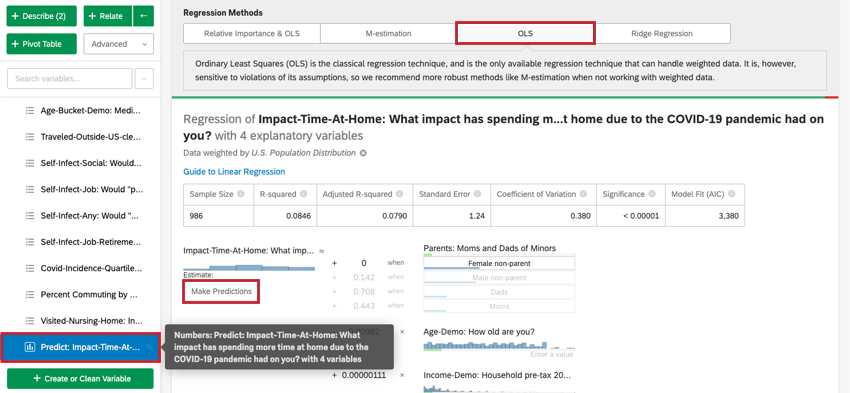
Para acceder a la estimación M, los mínimos cuadrados ordinarios y la regresión de cresta, haga clic en el engranaje de configuración en la esquina superior derecha de su tarjeta de regresión. Al hacer clic en el nombre de la técnica de regresión debajo Métodos de regresión Le permitirá cambiar la técnica de regresión utilizada para la tarjeta de regresión. Esto sólo se puede hacer para la regresión lineal.

- Estimación M:Diseñado para manejar valores atípicos en la variable de salida mejor que los mínimos cuadrados ordinarios (MCO).
- Mínimos cuadrados ordinarios:Los mínimos cuadrados ordinarios (MCO) son la técnica de regresión clásica. Es sensible a valores atípicos y otras violaciones de sus supuestos, por lo que recomendamos métodos más robustos como la estimación M. Dado que OLS se utiliza en la salida de importancia relativa predeterminada, solo debe seleccionar esta opción si está interesado en las características que aún no se han adaptado a la salida de importancia relativa: predecir resultados y agregar términos de interacción.
- Regresión de cresta:La regresión de cresta es una técnica similar a la regresión OLS estándar, pero con un parámetro de ajuste alfa. Este parámetro alfa ayuda a lidiar con la alta varianza y los datos que sufren multicolinealidad. Cuando se ajusta correctamente, la regresión de cresta generalmente produce mejores predicciones que MCO debido a un mejor compromiso entre sesgo y varianza. En Stats iQ, podrá elegir el parámetro alfa al utilizar la regresión de cresta.
Una vez que haya seleccionado Estimación M, Mínimos Cuadrados Ordinarios o Regresión de Ridge, podrá ver el resultado. La salida aparecerá debajo de la Métodos de regresión sección.
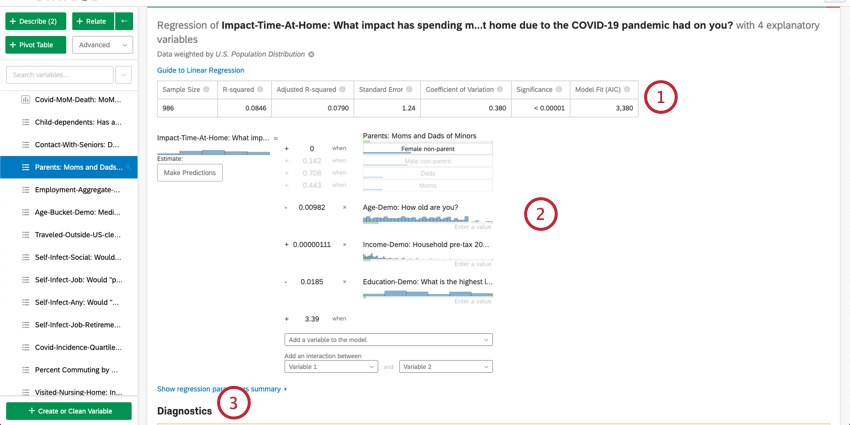
- Resumen numérico:En la parte superior de la tarjeta hay un resumen del análisis de regresión. Esto incluye el tamaño de la Muestra , los casos faltantes, el método, el valor R cuadrado, el error estándar, el coeficiente de variación y el ajuste del modelo.
- Detalles del coeficiente:Los resultados primarios de la regresión, la ecuación matemática, se encuentran en el resumen. La variable clave está a la izquierda de la ecuación. Las variables de entrada están en el lado derecho. Al pasar el cursor sobre una variable, se muestra una información sobre herramientas que explica en términos sencillos cómo esa variable contribuye a la variable de salida. Aquí también puede ingresar valores en la ecuación matemática para estimar valores para su variable de salida. Consulte la siguiente sección sobre la estimación de valores de variables de salida para obtener más información.
- Diagnóstico y residuos: Stats iQ proporciona diagnósticos para ayudarle a evaluar la precisión y validez de su modelo. Para obtener más información, consulte Interpretación de gráficos residuales para mejorar la regresión lineal o La Matriz de confusión y el equilibrio entre precisión y recuperación en regresión logística.
Estimación de valores de variables de salida
Una vez que haya ejecutado una regresión, podrá usar la ecuación matemática en la sección Detalles de coeficientes para estimar los valores de las variables de salida en función de los valores de entrada que seleccione. En el lado derecho de la ecuación, verás tus variables de entrada. Puede establecer valores para cada una de las variables de entrada. En el lado izquierdo de la ecuación está la variable de salida. Después de ingresar valores para las variables de entrada, la ecuación calculará una estimación para la variable de salida según el modelo de regresión.
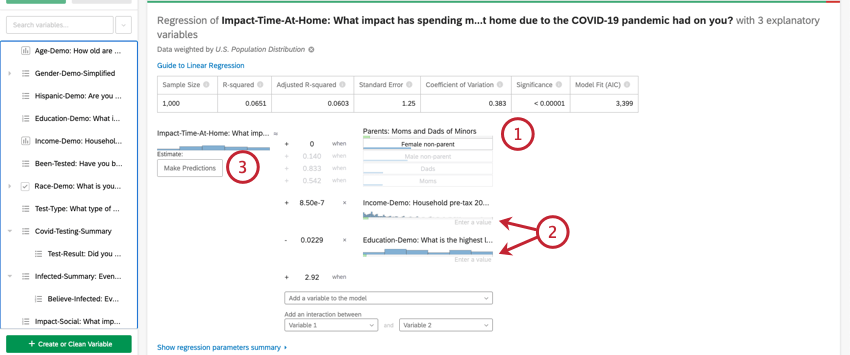
- Esta variable de entrada es una tipo de categoría variable. Para ingresar un valor para las variables de categoría, haga clic en el valor deseado en la lista de opciones.
- Estas variables de entrada son tipo de numero variables. Para ingresar un valor para las variables numéricas, haga clic en Introduzca un valor y escriba un número.
- Esta variable es la variable de salida de su ecuación de regresión. Después de seleccionar valores para sus variables de entrada, aparecerá un valor estimado para su variable de salida siguiente a donde dice Estimar.
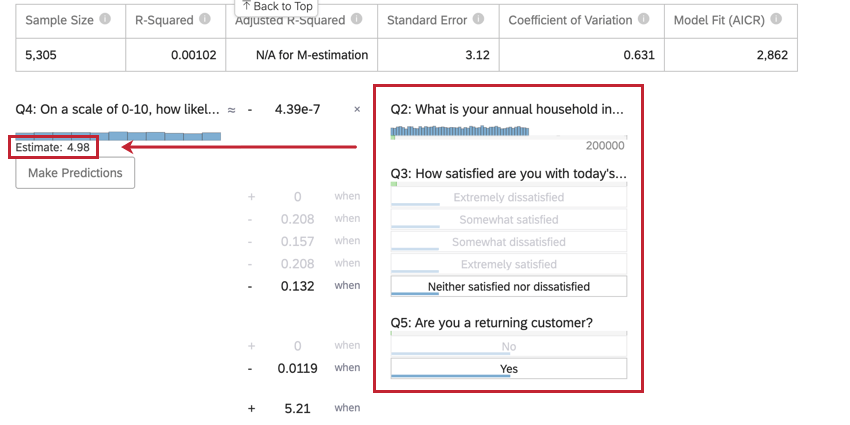
Predicción de resultados
Por lo general, utilizará el análisis de regresión en Stats iQ para comprender la relación entre las variables de entrada y las variables de salida. Sin embargo, una vez que se crea un modelo de regresión, también se puede utilizar para predecir el valor de salida de las filas de datos donde tiene valores para las entradas.
Términos de interacción y otras preocupaciones avanzadas
Agregar términos de interacción
Si desea mejorar su modelo de regresión, es posible que desee agregar términos de interacción además de las variables de entrada existentes. Se agregaría un término de interacción si sospecha que el valor de una de las variables de entrada cambia el modo en que una variable de entrada diferente afecta a la variable de salida.
Por ejemplo, quizás en el caso de las personas con niños presentes durante una estadía en un hotel, los más jóvenes están más satisfechos que las personas mayores, pero en el caso de las personas sin niños presentes, los más jóvenes están menos satisfechos. Eso significaría que hay una interacción entre “Niños presentes” y “Edad”.
Seleccionar dos variables bajo Añadir una interacción entre en la parte inferior de la lista de variables de entrada de la tarjeta se agregará un término de interacción a la regresión. Esta funcionalidad solo está disponible en mínimos cuadrados ordinarios, estimación M y regresión de cresta.
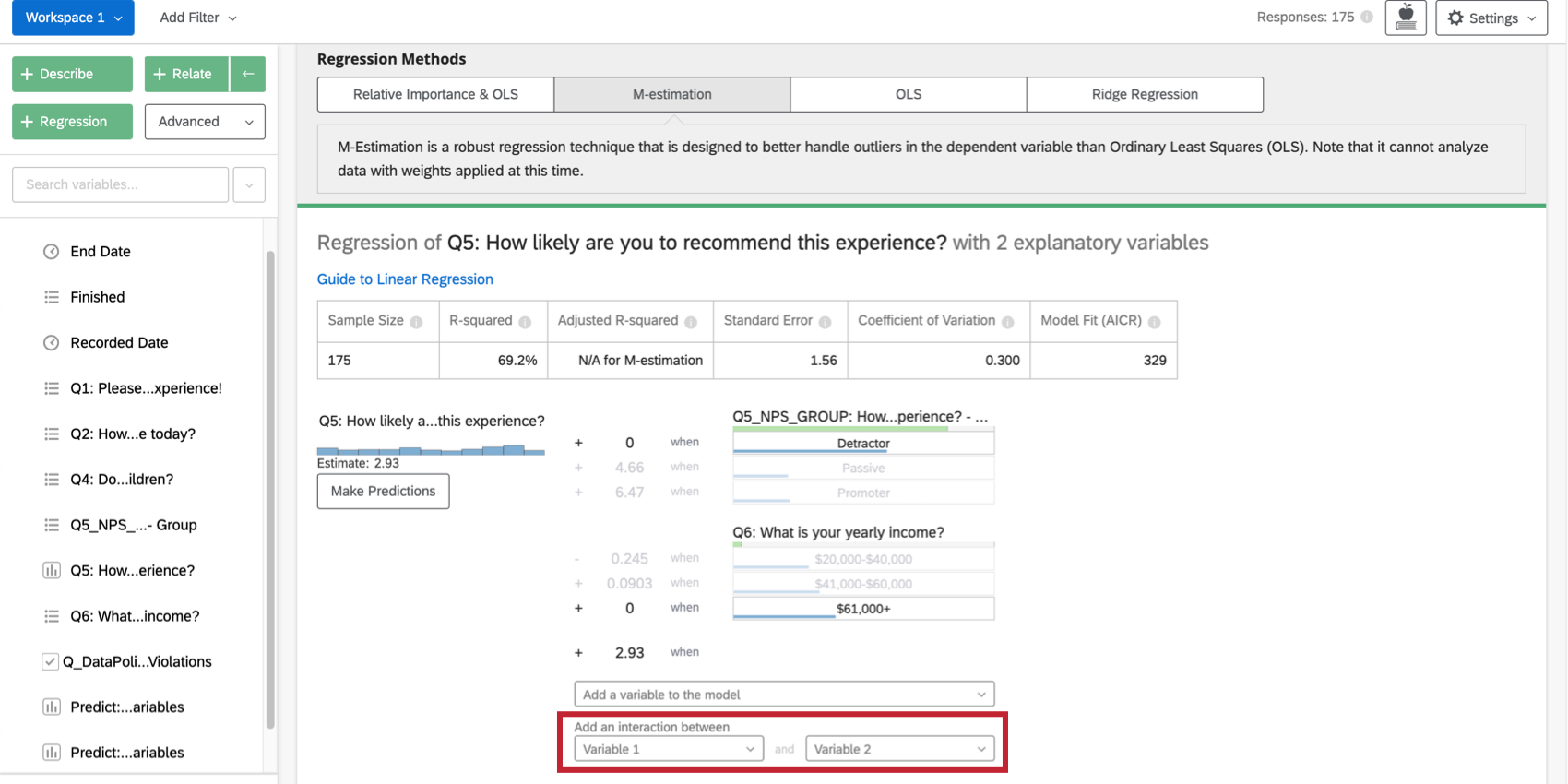
Puede lograr el mismo efecto para las variables categóricas en un análisis de importancia relativa mediante creando una nueva variable que combina los dos. Por ejemplo, podría combinar la variable Color (con rojo y verde grupos) con Tamaño (con grande y pequeño grupos) para crear una variable llamada ColorTamaño (con grupos Gran rojo, Gran verde, Pequeño rojo, y Pequeño Verde).
Multicolinealidad
La multicolinealidad ocurre en un contexto de regresión cuando dos o más de las variables de entrada están altamente correlacionadas entre sí.
Cuando dos variables están altamente correlacionadas, las matemáticas para la regresión generalmente colocan el mayor valor posible en una variable y no en la otra. Esto se manifiesta en un coeficiente mayor para esa variable. Pero si se modifica el modelo incluso una pequeña cantidad (agregando un filtro, por ejemplo), entonces la variable donde se colocó la mayor parte del valor puede cambiar. Esto significa que incluso un pequeño cambio puede tener un efecto drástico en el modelo de regresión.
El análisis de importancia relativa se ocupa de esta cuestión para que usted no tenga que preocuparse por ello. Si prefiere utilizar uno de los otros métodos y su modelo tiene este problema, la presencia de multicolinealidad (medida por el “Factor de inflación de varianza”) activador una advertencia y sugerirá que elimine una variable o combine variables promediándolas, por ejemplo.
Mensajes de advertencia
Stats iQ le avisará cuando haya posibles problemas con los resultados de su regresión. Entre ellas se incluyen las siguientes situaciones:
- Las variables de entrada en su regresión no son estadísticamente significativas.
- Su transformación Se eliminaron datos de la regresión.
- Dos o más variables están altamente correlacionadas entre sí y hacen que sus resultados sean inestables, es decir multicolinealidad.
- Los residuos tienen un patrón que sugiere que el modelo podría mejorarse.
- Se ha eliminado automáticamente una variable con un solo valor.
- El tamaño de la muestra es demasiado pequeño en relación con el número de variables de entrada en la regresión.
- Se ha agregado una variable de categorías con demasiadas opciones de respuesta.