-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Guía de fácil uso para la regresión logística
¿Qué es la regresión logística?
La regresión logística estima una fórmula matemática que relaciona una o más variables de entrada con una variable de salida.
Por ejemplo, supongamos que usted tiene un puesto de limonada y le interesa saber qué tipos de clientes tienden a volver. Sus datos incluyen una entrada para cada cliente, su primera compra y si regresó durante el mes siguiente para comprar más limonada. Sus datos podrían verse así:
| Devolver | Edad del cliente | Sexo | Temp. en la primera compra | Color limonada | Largo del pantalón |
|---|---|---|---|---|---|
| No | 21 | Masculino | 24 | Rosa | Bermudas |
| Devuelto | 34 | Femenino | 20 | Amarillo | Bermudas |
| Devuelto | 13 | Femenino | 25 | Rosa | Pantalones |
| No | 25 | Femenino | 27 | Amarillo | Vestido |
| etc. | etc. | etc. | etc. | etc. | etc. |
¿Crees que la “Edad del cliente” (una entrada o variable explicativa) podría afectar el “Retorno” (una salida o variable de respuesta). La regresión logística podría arrojar este resultado:
A los 12 años (la edad más baja), la probabilidad de que el retorno sea “Devuelto” es del 10%.
Por cada año adicional de edad, “Retorno” es 1,1 veces más para ser “Retornado”.
Este conocimiento es útil por dos razones.
En primer lugar, permite comprender una relación: los clientes mayores tienen más probabilidades de regresar. Este Insight puede llevarlo a orientar su publicidad hacia clientes mayores, ya que tendrán más probabilidades de convertirse en clientes habituales.
En segundo lugar, y de manera relacionada, también puede ayudarle a realizar predicciones específicas. Si un cliente de 24 años pasa por allí, se podría estimar que si comprara limonada, hay un 26% de posibilidades de que más adelante se convierta en cliente habitual.
Comprender la multiplicación de probabilidades
Tenga en cuenta que si dijéramos que “Regresó” era “1,5 veces más probable” en una situación que en otra, estamos haciendo lo siguiente:
Las probabilidades eran 1:9, también escrito 1/(1+9) = 10%.
Las “probabilidades a favor” (el 1) se multiplican por 1,5.
Ahora 1,5:9, también escrito 1,5/(1,5+9) = 14%.
Otro ejemplo, esta vez de pasar de una probabilidad del 50% a algo 3 veces más probable:
Las probabilidades eran 1:1, también escrito 1/(1+1) = 50%.
Las “probabilidades a favor” (el 1 del lado izquierdo) se multiplican por 3.
Ahora 3:1, también escrito 3/(3+1) = 75%.
Ahora repasaremos el proceso de creación de este modelo de regresión.
Preparación para la creación de un modelo de regresión
1. Piense en la teoría de su regresión.
Una vez que haya elegido una variable de respuesta, “Ingresos , “ Plantear la hipótesis de cómo las distintas entradas pueden estar relacionadas con él. Por ejemplo, si piensa que una “temperatura más alta en la primera compra” generará una mayor probabilidad de “devolución”, es posible que no esté seguro de cómo la “antigüedad” afectará la “devolución”. , “ Y es posible que creas que “Pantalones” (vs. shorts) se ve afectado por la “Temperatura”, pero no tiene ningún impacto en tu puesto de limonada.
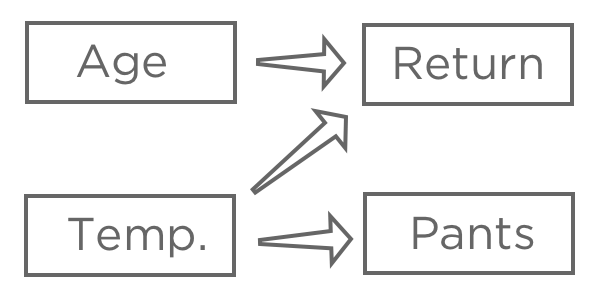
El objetivo de la regresión es típicamente entender la relación entre varias entradas y una salida, por lo que en este caso probablemente decidirías crear un modelo que explique “Retorno” con “Temperatura”. y “Edad” (también dicho como “predecir”) Devolver de Temperatura y Edad, “ incluso si estás más interesado en la explicación que en la predicción real).
Probablemente no incluirías “Pantalones” en tu regresión. Podría estar correlacionado con “Retorno” porque ambos están relacionados con “Temperatura”, pero no aparece antes de “Retorno” en la cadena causal, por lo que incluirlo confundiría su modelo.
2. “Describe” todas las variables que podrían ser útiles para tu modelo.
Empezar por describiendo la variable de respuesta, en este caso “Ingresos”, y obtener una buena idea de ella. Haga lo mismo para sus variables explicativas.
Nota que tiene una forma como ésta…
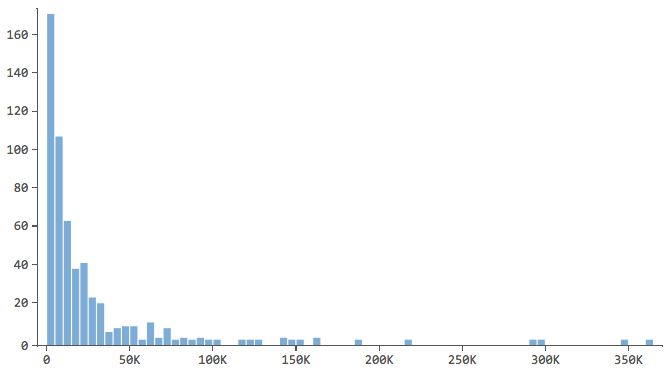
…donde la mayoría de los datos están en los primeros contenedores del histograma. Esas variables requerirán atención especial más adelante.
3. “Relacionar” todas las posibles variables explicativas con la variable respuesta.
Stats iQ lo hará Ordenar los resultados según la fuerza de la relación estadística . Eche un vistazo y tenga una idea de los resultados, observando qué variables están relacionadas con los “Ingresos” y cómo.
4. Comience a construir la regresión.
Construyendo una regresión El modelo es un proceso iterativo.Recorrerás las siguientes tres etapas tantas veces como sea necesario.
Las tres etapas de la construcción de un modelo de regresión
Etapa 1: Agregar o restar una variable.
Una por una, comience a agregar variables que sus análisis anteriores indicaron que estaban relacionadas con “Ingresos”. (o agregue variables que tenga una razón teórica para agregar). Ir uno por uno no es estrictamente necesario, pero hace que sea más fácil identificar y solucionar problemas a medida que avanza y le ayuda a tener una idea del modelo.
Digamos que comienzas prediciendo “Ingresos” con “Temperatura”. Encuentras una relación fuerte, evalúas el modelo y lo encuentras satisfactorio (más detalles en un minuto).
Retorno <– Temperatura
Luego agrega “color limonada” y ahora su modelo de regresión tiene dos términos, ambos son predictores estadísticamente significativos. Como esto:
Ingresos <– Temperatura y color de la limonada
Luego agrega “Sexo” y los resultados del modelo ahora muestran que “Sexo” es estadísticamente significativo en el modelo, pero “Color limonada” ya no lo es. Lo normal sería eliminar el “color limonada” del modelo. Ahora tenemos:
Ingresos <– Temperatura y sexo
Es decir, si conoces el sexo del cliente, saber qué color de limonada pidió no te da más información sobre si volverá a ser cliente.
Podrías investigar y discover que las mujeres tienden a recoger limonada amarilla más que los hombres y que es más probable que regresen. Entonces, inicialmente parecía que elegir el amarillo hacía que un cliente tuviera más probabilidades de regresar, pero, de hecho, el “color limonada” solo se relaciona con “regreso” a través de “sexo”. .” Entonces, cuando se incluye “Sexo” en la regresión, el “color limonada” desaparece de la regresión.
Interpretar los resultados de una regresión requiere mucho criterio, y el hecho de que una variable sea estadísticamente significativa no significa que sea realmente causal. Pero al sumar y restar variables con cuidado, notar cómo cambia el modelo y pensar siempre en la teoría detrás de su modelo, puede descubrir relaciones interesantes en sus datos.
Etapa 2: Evaluar el modelo.
Cada vez que agrega o resta una variable, debe evaluar la precisión del modelo observando su r cuadrado (R 2 ), AICc y cualquier alerta de Stats iQ. Cada vez que cambie el modelo, compare los nuevos gráficos de R-cuadrado, AICc y de diagnóstico con los antiguos para determinar si el modelo ha mejorado o no.
R-cuadrado (R 2 )
La métrica numérica para cuantificar la precisión de predicción del modelo se conoce como r-cuadrado, que está entre cero y uno. Un cero significa que el modelo no tiene valor predictivo y un uno significa que el modelo predice todo perfectamente.
Por ejemplo, los datos representados a la izquierda conducirán a un modelo mucho menos preciso que los datos de la derecha. Imagínese intentar dibujar una línea a través del diagrama de dispersión; podría separar casi por completo el azul (“Devuelto”) del rojo (“No”) en el lado derecho, pero en el lado izquierdo sería difícil hacerlo.
Es decir, el lado derecho tiene un r cuadrado alto; si conoces “Temperatura” y “Antigüedad”, puedes determinar “Devuelto” vs. “No lo hice” con mucha facilidad. El lado izquierdo tiene un r cuadrado bajo a medio; si conoces “Temperatura” y “Edad”, tienes una idea bastante buena de si será “Devuelto” o “No”. “No lo hice”, pero habrá muchos errores.
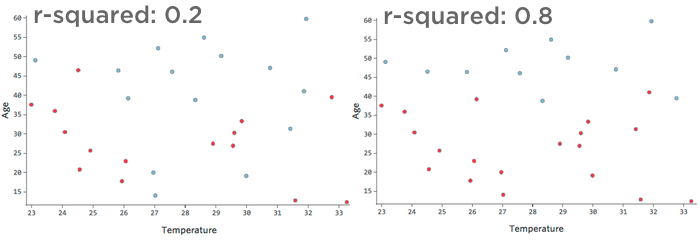
No existe una definición fija de un r-cuadrado “bueno”. En algunos entornos puede ser interesante ver algún efecto, mientras que en otros el modelo puede ser inútil a menos que sea muy preciso.
Cada vez que se agrega una variable, el r cuadrado aumentará, por lo que el objetivo no es lograr el r cuadrado más alto posible; más bien, se desea equilibrar la precisión del modelo (r cuadrado) con su complejidad (generalmente, la cantidad de variables que contiene).
AICc
AICc es una métrica que equilibra la precisión con la complejidad: una mayor precisión conduce a mejores puntuaciones y una mayor complejidad (más variables) conduce a peores puntuaciones. El modelo con el AICc más bajo es mejor.
Tenga en cuenta que la métrica AICc solo es útil para comparar AICc de modelos que tienen la misma cantidad de filas de datos. y la misma variable de salida.
Alertas
De vez en cuando, Stats iQ sugerirá formas de mejorar su modelo. Por ejemplo, Stats iQ puede sugerir que tome el logaritmo de una variable ( detalles de lo que eso significa ).
Matriz de confusión y curva de precisión-recuperación
La matriz de confusión y la curva de precisión-recuperación también son herramientas útiles para comprender qué tan preciso es su modelo. Y si desea hacer predicciones basadas en su modelo, estas herramientas le ayudarán a hacerlo.No son estrictamente necesarios para comprender bien lo que le dice su modelo, por lo que los colocamos en una sección diferente. La matriz de confusión y la curva de precisión-recuperación
Etapa 3: Modificar el modelo según corresponda.
Si su valoración del modelo resultó satisfactoria, ya está o puede volver a la Etapa 1 e ingresar más variables.
Si su valoración detecta que el modelo tiene deficiencias, utilizará las alertas de Stats iQ para solucionar los problemas.
A medida que modifica el modelo, observe continuamente los cambios en el R cuadrado, el AICR y los diagnósticos residuales, y decida si los cambios que está realizando ayudan o perjudican a su modelo.