-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Anonimato (EX)
Acerca del anonimato
Hay dos niveles de anonimato: básico y mejorado. El anonimato básico está habilitado de forma predeterminada en cada Tablero, mientras que el anonimato mejorado se puede activar para obtener capas adicionales de protección. Para obtener más información, consulte Básico vs. Anonimato mejorado.
Cualquier cambio que realice en la configuración de anonimato se aplicará inmediatamente en su Tablero.
Básico vs. Anonimato mejorado
Anonimato básico
Los umbrales de anonimato básicos determinan cuántas respuestas deben incluirse para un punto de datos determinado antes de que pueda aparecer en su Tablero. Esta es una excelente manera de proteger la privacidad de las respuestas de los empleados. El umbral de anonimato se aplica a cada punto de datos para las métricas (puntaje de favorabilidad, promedio, etc.) pero no para los recuentos de datos (número de respuestas).
El anonimato básico es una forma sencilla de proteger las respuestas de los empleado y al mismo tiempo permitir flexibilidad en el análisis de datos.
Al agregar filtros a una página, puede seleccionar valores por debajo del umbral, pero no verá ningún dato hasta que el valor total de todos los datos seleccionados en los filtros alcance su umbral de anonimato. Ver Paneles de filtrado Para más información.
Al desglosar los datos en un solo campo, todas las métricas que estén por debajo del umbral de anonimato se ocultarán y se mostrarán los recuentos. Al desglosar los datos en varios campos, se ocultarán tanto las métricas como los recuentos que se encuentren por debajo del umbral de anonimato .
Widgets de tasas de respuesta Mostrará recuentos por debajo del umbral de anonimato.
Anonimato mejorado
Además de las características cubiertas por el anonimato básico, el anonimato mejorado agrega capas adicionales a los filtros y desgloses de widget que pueden mejorar el anonimato en ciertos casos de uso. Con un anonimato mejorado, el umbral de anonimato se aplica a todos los puntos de datos (métricas y recuentos) para campos sensibles, pero no a ningún punto de datos para campos no sensibles.
El anonimato mejorado proporciona protección avanzada para las respuestas de los empleado y, como resultado, hay menos flexibilidad en el análisis de datos.
Umbrales de anonimato
El umbral de anonimato determina cuántas respuestas se deben incluir para un punto de datos o comentario determinado antes de que pueda aparecer en su Tablero. Los puntos de datos pueden ser tan amplios como un widget o tan específicos como una barra dentro de un gráfico.
El umbral de anonimato predeterminado se establece en 5 tanto para los puntos de datos como para los comentarios.
Para ver y modificar los umbrales de anonimato, siga estos pasos:
- Mientras visualiza su Tablero, haga clic en Ajustes.
- Ir a la Anonimato pestaña.
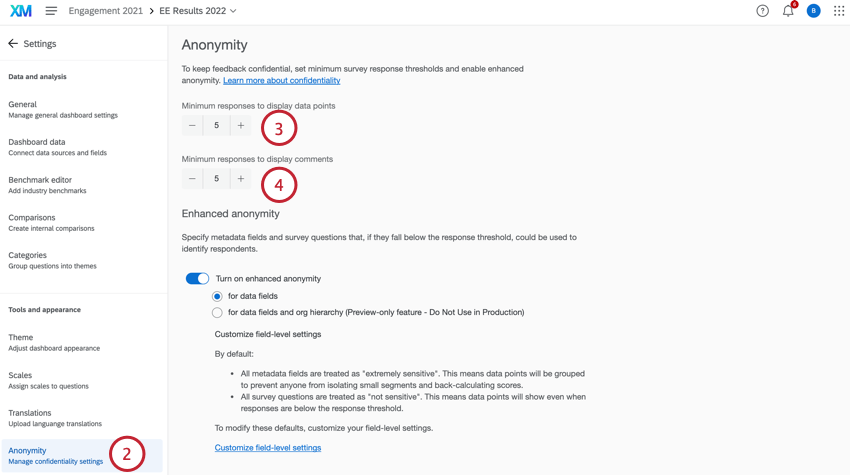
- Bajo respuestas mínimas para mostrar puntos de datos, Decide cuántas respuestas deben recopilarse antes de que los datos aparezcan en los widgets. Este límite se aplica a todos los desgloses de datos en todos los widgets.
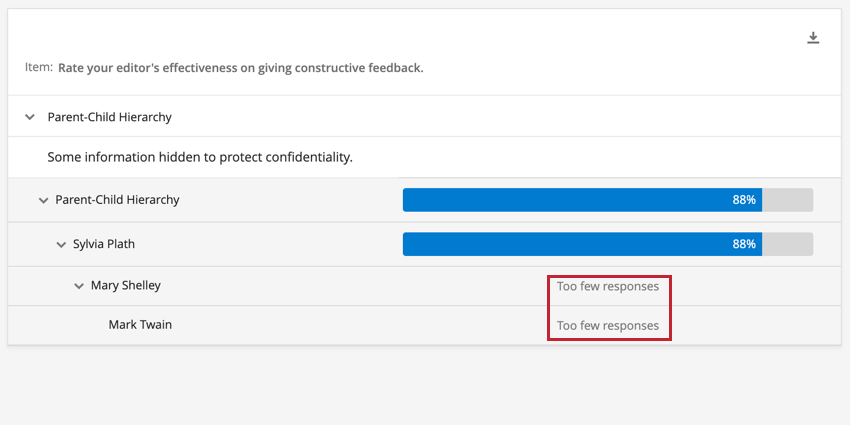
Ejemplo: La imagen de abajo muestra una widget de Comparación que se desglosa según la Jerarquía de organización activa. Si las unidades tienen recuentos de respuestas por debajo del umbral de anonimato, entonces esas unidades no mostrarán datos en el widget. Las unidades con un recuento de respuestas superior al umbral de anonimato mostrarán los datos de manera normal. Dado que el número de respuestas para las unidades de Mary Shelley y Mark Twain cae por debajo del umbral de anonimato, el widget muestra el mensaje “Muy pocas respuestas” para estas unidades.
- Bajo respuestas mínimas para mostrar comentarios, decide cuántas respuestas deben recopilarse antes de que las respuestas de texto libre aparezcan en los widgets.
Habilitación de un anonimato mejorado
El anonimato mejorado se puede activar y desactivar en el nivel del Tablero para mejorar el anonimato.
Por ejemplo, digamos que el equipo de Barnaby tiene 15 personas. Cuando analizamos los puntajes de compromiso de su equipo, no sabemos realmente cómo respondió cada miembro del equipo a las preguntas sobre la efectividad de su gerente. Sin embargo, supongamos que sólo hay dos mujeres en su equipo. Los umbrales de anonimato regulares garantizarán que no podamos ver las respuestas de las mujeres directamente, sin embargo, si agregamos un filtro de género, podemos hacer una estimación bastante precisa de lo que cada una de las mujeres de su equipo tenía para decir. Un mayor anonimato detecta disparidades de este tipo. Garantiza que los datos de los grupos que no cumplen el umbral de anonimato se combinen con el siguiente grupo más pequeño para ocultar sus respuestas al desglosar los datos o usar filtros.
- Mientras visualiza su Tablero, haga clic en Ajustes.
- Ir a la Anonimato pestaña.
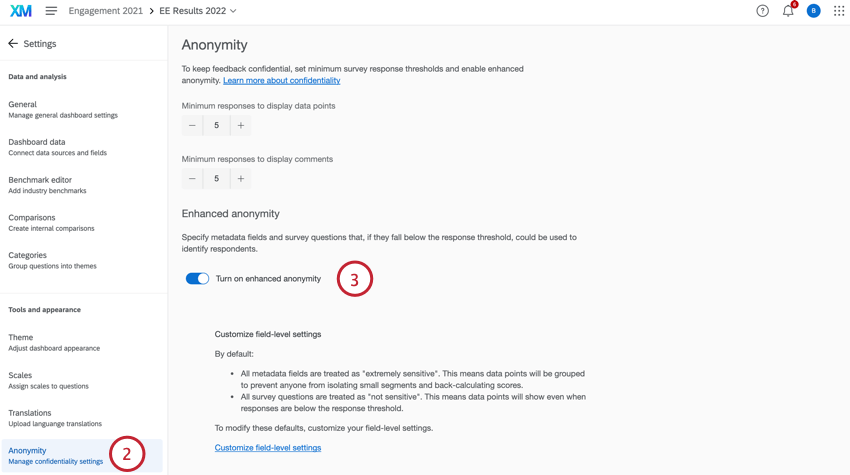
- Permitir Activar el anonimato mejorado.
Configuración a nivel de campo
Cuando haya habilitado el anonimato mejorado, puede personalizar el nivel de anonimato para cada campo en su Tablero marcando los campos como Extremadamente sensible, Un poco sensible, o No sensible. Esto cambia la forma en que se tratan y se muestran los desgloses en los widgets, y le permite agrupar puntos de datos por debajo del umbral de respuesta en algunos campos mientras oculta puntos de datos por debajo del umbral de respuesta en otros.
Es posible que haya algunos campos del Tablero por los cuales se pueda identificar a los participantes, que deberían considerarse sensibles y marcarse como extremadamente sensibles o algo sensibles, mientras que los campos que no son sensibles deberían marcarse como no sensibles. Por ejemplo, la experiencia, el género y el equipo al que pertenece una persona pueden utilizarse para determinar quién es. Sin embargo, las preguntas realizadas en una encuesta Employee Experience casi siempre no son sensibles, con la excepción de preguntas demográficas como el idioma, la ubicación de la oficina y la edad.
Cuando los campos están marcados como extremadamente sensibles, los datos de los grupos que no cumplen el umbral de anonimato se combinarán con el siguiente grupo más pequeño para proteger la identidad de los encuestados. Cuando los campos están marcados como algo sensibles, no se mostrarán los datos de los grupos que no cumplan con el umbral de anonimato . Cuando los campos están marcados como no sensibles, la agrupación no se realizará a menos que filtro o desglose por un campo sensible.
Para editar qué campos son sensibles y cuáles no, deberá hacer lo siguiente:
- Ir a Ajustes.
- Seleccionar Anonimato.
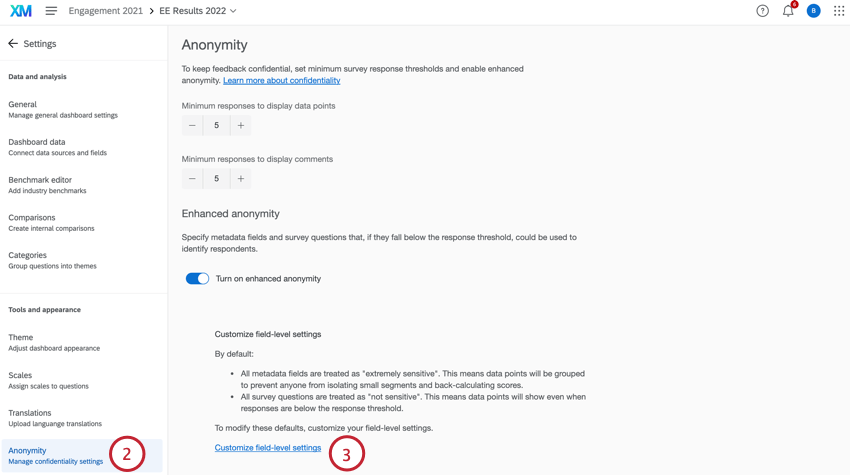
- Seleccionar Personalizar la configuración a nivel de campo.
- Utilice el menú desplegable siguiente a cada campo para seleccionar qué tan sensible es. Puede elegir entre las siguientes opciones:
- Extremadamente sensible: Estos campos contienen información que identificará a los participantes. Cuando un punto de datos cae por debajo del umbral de respuesta, aplicar configuraciones de anonimato mejoradas y los datos se agruparán con los siguiente puntos de datos más pequeños. Estos campos anteriormente se llamaban campos identificables.
Consejo Q: Todos los campos de metadatos están marcados como extremadamente sensibles de forma predeterminada.
- Un poco sensible: Estos campos contienen información que puede identificar a los participantes. Los puntos de datos que estén por debajo del umbral de respuesta no se mostrarán, al igual que ocurre con el anonimato básico. Esta opción es útil para campos como fechas o períodos de tiempo.
Consejo Q: Con esta opción aún es posible determinar qué participante proporcionó una determinada respuesta; para mayor sensibilidad, los campos deben marcarse como extremadamente sensibles.
- No sensible: Estos campos no contienen información que pueda identificar a los participantes. Se muestran todos los puntos de datos incluso cuando las respuestas caen por debajo del umbral de respuesta. Estos campos anteriormente se llamaban campos no identificables.
Consejo Q: Todos los campos de preguntas están marcados como no sensibles de forma predeterminada.
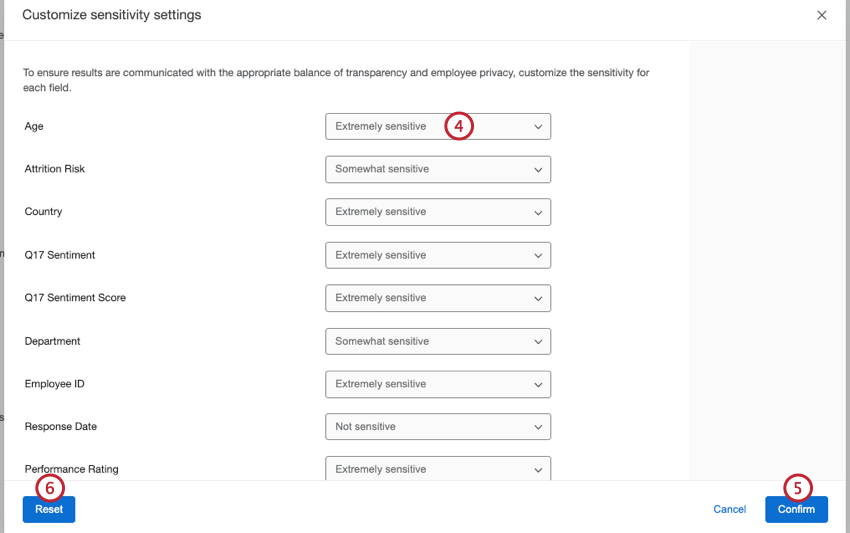
- Extremadamente sensible: Estos campos contienen información que identificará a los participantes. Cuando un punto de datos cae por debajo del umbral de respuesta, aplicar configuraciones de anonimato mejoradas y los datos se agruparán con los siguiente puntos de datos más pequeños. Estos campos anteriormente se llamaban campos identificables.
- Hacer clic Confirmar.
- Para volver a la configuración original y eliminar todos los cambios, haga clic en Reiniciar.
Ejemplo: En nuestro Tablero, no marcamos las preguntas de participación como identificables, porque no son demográficas y no pueden usarse para identificar a sus encuestados de ninguna manera.

Digamos que el umbral del panel es 5. Si creamos una tabla que muestre cómo respondieron los empleados a un campo no identificable como “Me siento orgulloso de decirle a la gente dónde trabajo”, las respuestas no se agruparán. Vea a continuación cómo aparece “Totalmente en desacuerdo”, aunque solo tiene 1 respuesta.
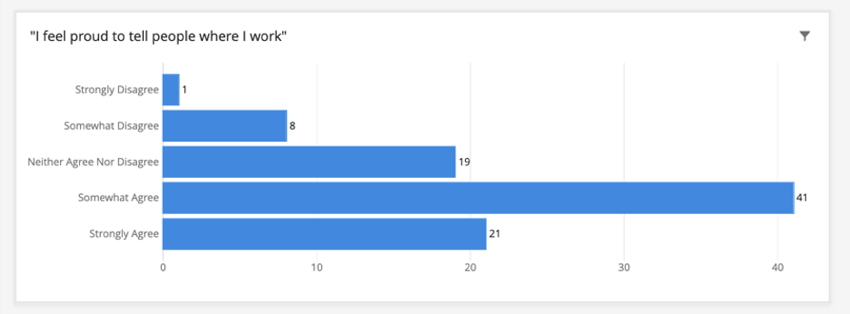
Tenga en cuenta que el número total de respuestas en el widget aún debe cumplir con el umbral. Este gráfico tiene un total de 90 respuestas. Si tuviera menos de 5, el gráfico estaría en blanco porque el comportamiento predeterminado del umbral de anonimato es ocultar los datos de los widgets que no cumplen con el umbral.
Interacciones de campo
Si está utilizando una tabla o un gráfico para mostrar un campo extremadamente sensible o algo sensible con un campo no sensible, sus datos deben agruparse de la misma manera independientemente de cómo transponga los datos. La lógica de agrupación se aplica de forma consistente según la configuración del campo, sin importar qué campo esté configurado como fila o columna.
Configuración de las fuentes de datos del Tablero
Al utilizar el anonimato mejorado, si también está utilizando fuentes históricas En tu Tablero, es importante ir a configuración general del Tablero y limitar los filtros de página según los datos del año actual.
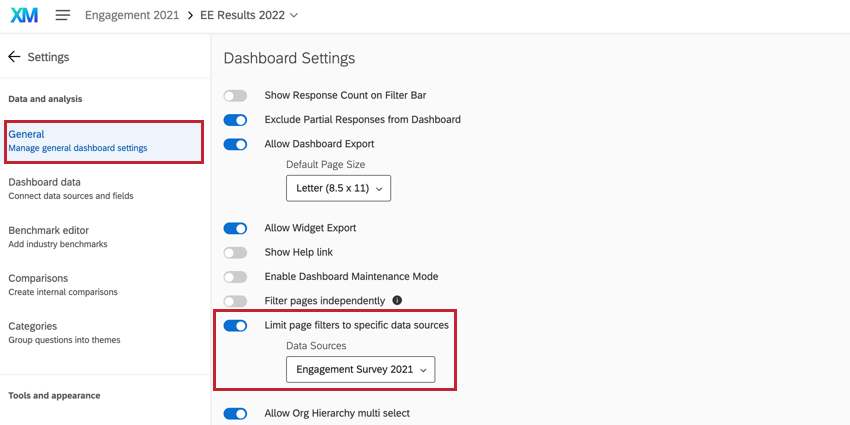
De lo contrario, los filtros del Tablero , excepto el filtro de Jerarquía de la organización, que tendrá como opción predeterminada la fuente de datos principal, incluirán datos de Todas las fuentes de datos en el Tablero datos. Esto significa que los datos históricos pueden incluirse en los recuentos de respuestas y pueden sesgar las agrupaciones de anonimato. Por ejemplo, si se cuentan los resultados actuales e históricos de un equipo pequeño en lugar de solo los resultados del año actual, el equipo pequeño parece más grande de lo que realmente es y puede no caer por debajo del umbral de anonimato. Limitar los filtros a la fuente de datos principal (es decir, el proyecto actual o los datos del año actual) resuelve este problema.
Comportamiento del Filtro
Una vez que hayas Habilitó el anonimato mejorado y agregó un filtro a su Tablero, su configuración de anonimato determinará cómo se comportan los filtros.
El comportamiento del filtro de página depende de configuración a nivel de campo Para cada campo:
- Campos no sensibles: Estos campos le permiten seleccionar cualquier valor, incluso si está por debajo del umbral.
- Campos algo sensibles: Estos campos solo le permiten seleccionar valores que cumplan o superen el umbral.
- Campos extremadamente sensibles: Estos campos agrupan cualquier valor por debajo del umbral. Los Resultados por debajo del umbral se combinarán con la siguiente opción más pequeña en el filtro antes de realizar cualquier selección. Si solo tiene 1 grupo que está por debajo del umbral, este se combinará con el siguiente grupo más pequeño, independientemente de si el siguiente grupo cumple con el umbral o no. Esto es para garantizar que incluso si solo un grupo no alcanza el umbral, sus datos estén protegidos.
A medida que se agreguen o eliminen filtros, el anonimato mejorado los tendrá en cuenta y cambiará las agrupaciones en consecuencia.
Ejemplo: En la captura de pantalla a continuación, estamos intentando filtro por departamento. Esta es una empresa pequeña, por lo que Finanzas, Soporte y Recurso Humanos tienen equipos muy pequeños, por debajo del umbral de anonimato que hemos establecido.
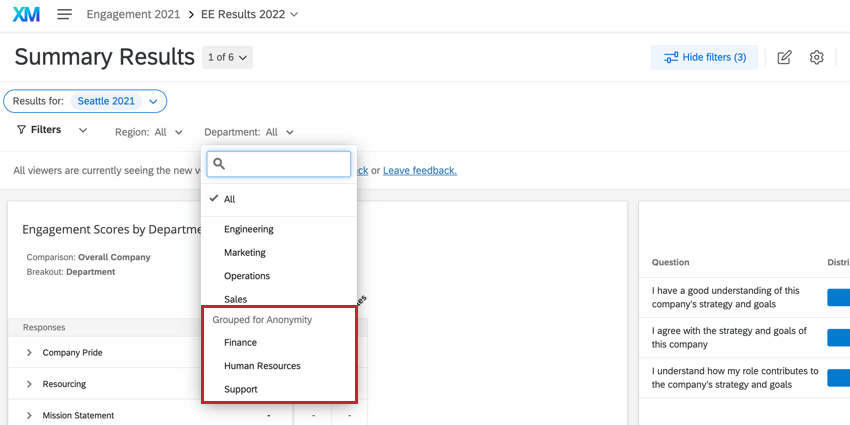
Verás que Finanzas, Soporte y Recurso Humanos están debajo del encabezado. Agrupados por el anonimato. Si intento seleccionar solo uno, ambos se seleccionarán automáticamente. Si intento deseleccionar uno, ambos quedan deseleccionados. Esto evita que los usuarios descubran los valores de los grupos por debajo del umbral.
Filtros de Jerarquía de la organización
Las unidades de Jerarquía de la organización que no cumplan con el umbral de anonimato aparecerán en gris y tendrán un ícono de candado siguiente a ellas. No podrás seleccionar ninguna unidad que no cumpla con el umbral de anonimato. Esto es para proteger el anonimato de los encuestados.
![]()
Comportamiento de Desglose
Cuando se habilita el anonimato mejorado, el configuraciones a nivel de campo para cada campo, determine cómo se mostrarán los datos en los widgets donde los datos se han dividido en ciertos grupos. Esto incluye widgets de línea donde se ha definido una dimensión de eje x, widgets con Comparaciones Además, se agregaron widgets de desglose demográfico , widgets de mapa de calor y cualquier otra configuración de widget que aísle grupos que puedan ser más pequeños que el umbral de anonimato.
- Campos no sensibles: Estos campos mostrarán todos los puntos de datos (métricas y recuentos), incluso si están por debajo del umbral.
- Campos algo sensibles: Estos campos solo mostrarán puntos de datos (métricas y recuentos) que cumplan o superen el umbral de respuesta.
- Campos extremadamente sensibles: Estos campos agruparán todos los puntos de datos (métricas y recuentos) que se encuentren por debajo del umbral.
Las excepciones a esta regla incluyen widgets desglosados por jerarquía de la organización. Algunos widgets (mapa de calor, desglose demográfico ) admiten un desglose de un Nivel por debajo que muestra datos de cada unidad secundaria de la unidad seleccionada actualmente en el filtro de jerarquía de la organización . Otros widgets (tasas de respuesta, comparación, gráfico de burbujas) admiten la exploración en profundidad de la jerarquía, mostrando datos de cada unidad y permitiendo al usuario seleccionarlos. Para cualquier widget desglosado por jerarquía de la organización, no se aplica el anonimato mejorado. Esto significa que ninguna unidad se agrupará para mantener el anonimato.
Si cambiara la métrica a un puntaje de participación promedio o un NPS, el anonimato mejorado le impediría averiguar los datos de la oficina más pequeña al no permitir que los usuarios del Tablero aíslen los datos de esa oficina. Esto es útil en casos en los que, por ejemplo, no queremos que las calificaciones de cada miembro de la oficina más pequeña se calculen fácilmente.
Ejemplo:
En el siguiente ejemplo, nuestro Tablero tiene un umbral de anonimato establecido para el campo “país” para ayudar a proteger las respuestas de los empleados en oficinas pequeñas. En el widget a continuación, hemos establecido la dimensión del eje y de un gráfico de barras para que sea el país donde se encuentra la oficina del empleado. Australia y México tienen oficinas muy pequeñas, por debajo del umbral de anonimato que hemos establecido. Como resultado, sus respuestas se han combinado.
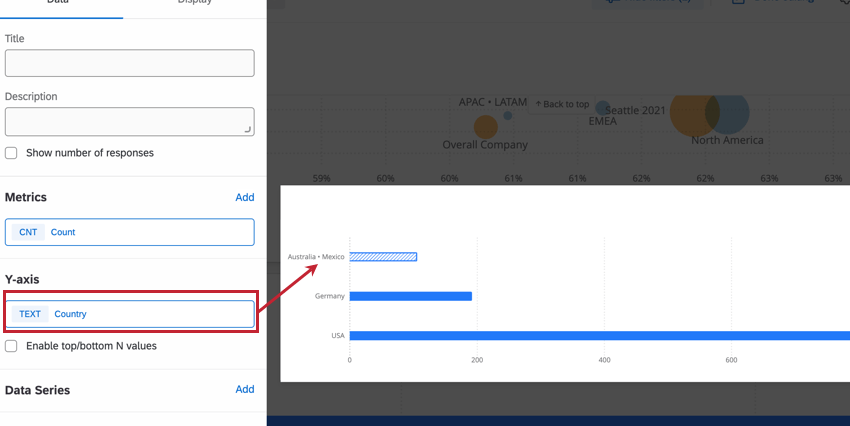
Si cambiara la métrica a un puntaje de participación promedio o un NPS, el anonimato mejorado le impediría averiguar los datos de la oficina más pequeña al no permitir que los usuarios del Tablero aíslen los datos de esa oficina. Esto es útil en casos en los que, por ejemplo, no queremos que las calificaciones de cada miembro de la oficina más pequeña se calculen fácilmente.
Múltiples rupturas
Algunos widgets se dividen en múltiples dimensiones, por ejemplo, Widgets de línea y barra le permite agregar tanto un valor del eje x como una serie de datos, y mesas Le permite agregar filas y columnas.
Cuanto más se desglosen los datos, más pequeña podrá ser cada categoría y más categorías podrán agruparse bajo anonimato. Y debido a que ahora hay dos dimensiones en la desglose, puede haber diferentes combinaciones de categorías que deben agruparse para mantener el anonimato. De esta manera, las categorías agrupadas para el anonimato se etiquetarán Agrupados por el anonimatoy puedes pasar el cursor sobre ellos para determinar qué categorías específicas se agruparon.
También notarás que en la leyenda, los grupos de anonimato están etiquetados como Agrupados por el anonimato, no es un nombre compuesto. Esto es para tener en cuenta cómo las agrupaciones pueden cambiar en función de cómo interactúan múltiples desgloses y para evitar etiquetas que sean demasiado largas.
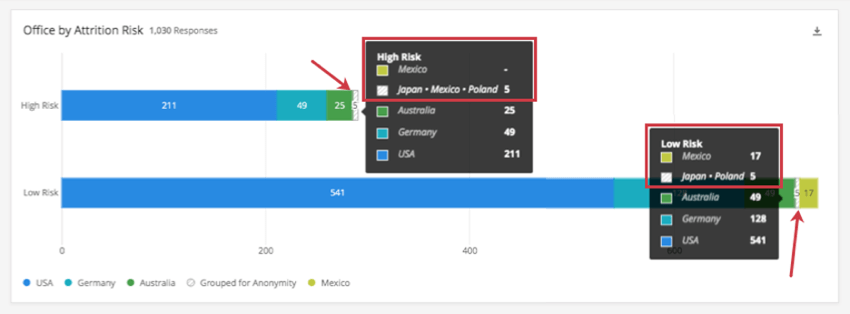
Ejemplo: Este Tablero tiene un umbral de 5. En el gráfico a continuación, desglosamos los países en los que trabajan nuestros empleados según el riesgo de deserción. Podemos ver un bloque verde claro para México en la barra de Bajo Riesgo, pero no en la barra de Alto Riesgo.
Cuando resaltado los bloques Agrupados por Anonimato para cada barra, discover que hay una diferencia: México fue agrupado con Japón y Polonia en la barra de Alto Riesgo, pero solo Japón y Polonia fueron agrupados en la barra de Bajo Riesgo.
Mira la captura de pantalla a continuación. En Alto riesgo, México no cuenta con datos individuales ( – ), pero Japón + México + Polonia muestran datos, ya que están agrupados para mantener el anonimato (5). Bajo Bajo riesgo, México cumple el umbral, por lo que no necesita agruparse, y muestra datos individuales (17), mientras que Japón + Polonia se agrupan (5).
Anonimato básico
Si está desglosando datos en 2 o más campos con anonimato básico, se considerará cada uno de los campos de desglose. por separado. Al desglosar los datos en varios campos, se ocultarán las métricas y los puntos de datos de recuento por debajo del umbral.
El anonimato básico no contará las respuestas sin valor (vacías/nulas) al comparar el recuento de respuestas con el umbral de anonimato. Esto es para proteger los casos en los que un encuesta que podría no ser elegible para responder una pregunta (por ejemplo, la lógica de la encuesta dice que solo los gerentes pueden responder una pregunta) tiene sus respuestas contadas en relación con el umbral de anonimato.
Anonimato mejorado
El anonimato mejorado cuenta las respuestas sin valores (vacíos/nulos) al comparar el recuento de respuestas con el umbral de anonimato.
El comportamiento de desglose de múltiples campos depende de la configuraciones a nivel de campo para los 2 campos involucrados. Esta tabla muestra cómo se ocultarán los datos para los desgloses dobles entre diferentes tipos de campos.
| No sensible | Un poco sensible | Extremadamente sensible | |
| No sensible | Se mostrarán todos los puntos de datos (métricas y recuentos). | Los valores del campo algo sensible se ocultarán si están por debajo del umbral. | Los valores del campo extremadamente sensible se agruparán si están por debajo del umbral. |
| Un poco sensible | Los valores del campo algo sensible se ocultarán si están por debajo del umbral. | Se ocultarán todos los puntos de datos (métricas y recuentos) que se encuentren por debajo del umbral de respuesta. | Los valores del campo algo sensible se ocultarán si están por debajo del umbral y los valores del campo extremadamente sensible se agruparán si están por debajo del umbral. |
| Extremadamente sensible | Los valores del campo extremadamente sensible se agruparán si están por debajo del umbral. | Los valores del campo algo sensible se ocultarán si están por debajo del umbral y los valores del campo extremadamente sensible se agruparán si están por debajo del umbral. | Los puntos de datos que se encuentren por debajo del umbral de respuesta se agruparán. |
Comportamiento de las tasas de respuesta
Las tasas de respuesta muestran cuántas respuestas recibió y qué porcentaje de su lista de participante completó la encuesta. Este tipo de datos son reportados por resumen de participación y tasa de respuestas widgets.
De forma predeterminada, el Tablero considera que las tasas de respuesta son información confidencial. Esto significa que los datos de tasa de respuestas se pueden usar para identificar a los participantes y, por lo tanto, para protegerlos, las tasas de respuesta están sujeto a agruparse por anonimato.
Ejemplo: Cuando creas un widget de tasa de respuestas , puedes Agregue un campo para dividir el widget. A continuación, hemos desglosado nuestras tasas de respuesta por país, lo que ha dado como resultado que Australia, Alemania y México se agrupen para mantener el anonimato.
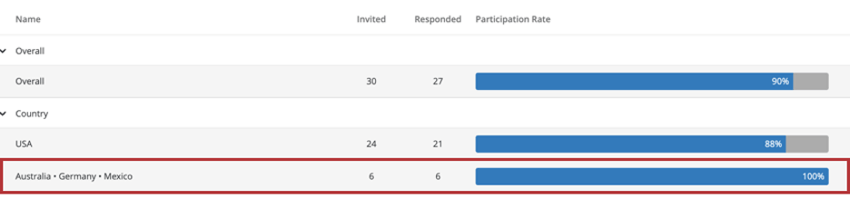
Por lo tanto, los widgets de tasa de respuestas muestran lo mismo comportamiento de desglose Otros widgets lo hacen. Si el recuento de respuestas está por debajo del umbral, no verá datos en el widget de resumen de participación .
Cuando se habilita el anonimato mejorado, el comportamiento de las tasas de respuesta depende de la configuración a nivel de campo Para cada campo:
- Campos no sensibles: Estos campos muestran todos los puntos de datos, incluso si están por debajo del umbral.
- Campos algo sensibles: Estos campos solo muestran puntos de datos que cumplen o superan el umbral de respuesta.
- Campos extremadamente sensibles: Estos campos agrupan todos los puntos de datos que se encuentran por debajo del umbral.
Configuración de anonimato para toda la Organización
Puede establecer el umbral de anonimato para toda su organización , garantizando que todos los proyectos EX cumplan con el mismo estándar de privacidad. Ver Respuestas anónimas (Administrador).