-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Uso y edición de la fuente de datos de Marca/organización Tracker
Acerca del uso y la edición de la fuente de datos de Marca/organización Tracker
Programas BX recopilar datos sobre su marca/organización , además de las marcas competitivas y el mercado más amplio, lo que hace que el conjunto de datos sea más complejo que los proyectos estándar. Los programas BX utilizan un conjunto de datos apilados (Marca/organización Tracker Data Source o BTDS) para identificar información en sus datos con mayor facilidad.
Comprensión de la fuente de datos BX
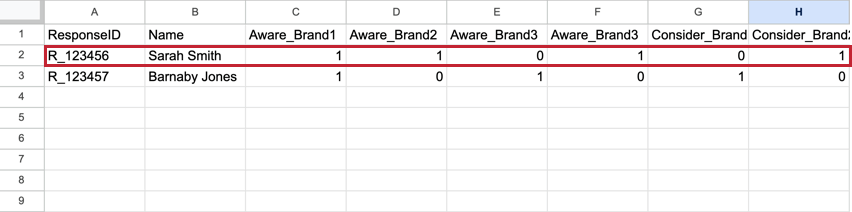
El BTDS varía de lo que verías en un conjunto de datos estándar. En un conjunto de datos estándar, cada encuestado tiene una fila que contiene todas las respuestas a sus respuestas, con la métrica de cada marca como su propia columna. Estos conjuntos de datos tienden a ser muy amplios, con cientos de columnas.
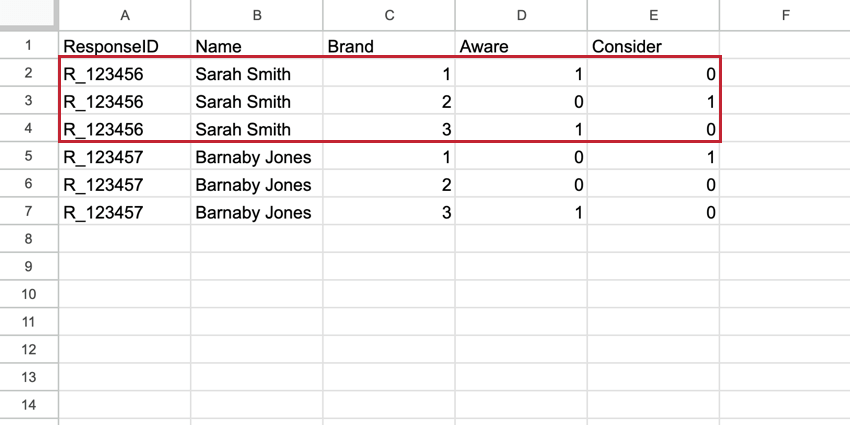
En el BTDS, Marca/organización se convierte en una columna de primera clase en el conjunto de datos y cada encuestado tiene una fila para Cada marca/organización. La fila de la marca contiene todos los datos de esa única marca/organización. Estos conjuntos de datos tienen más filas que el conjunto de datos estándar, pero tienen muchas menos columnas, lo que los hace más fáciles de leer.
RESPONSEID
El ResponseID El campo nos ayuda a identificar qué filas pertenecen al mismo encuestado. Este valor proviene de la encuesta original enviada y se repite para cada fila pertenencia a ese encuestado.
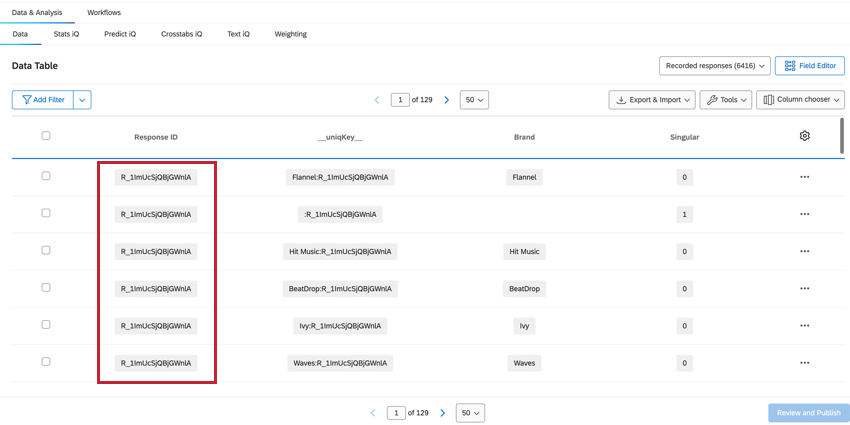
SINGULAR
El recuento de Respuestas registradas en el Datos y análisis La pestaña nos dará el recuento total de todas las filas, que será mayor que el número total de encuestados únicos. Para determinar los encuestados únicos, podemos filtro Para el campo Singular.
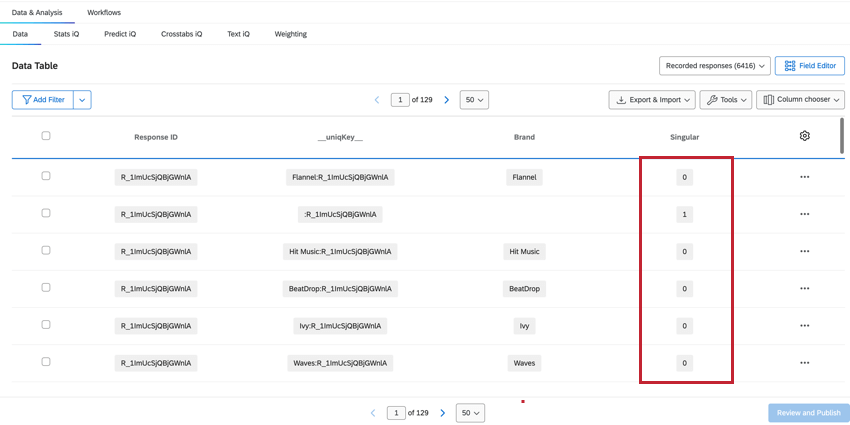
- Cuando Singular = 1, se nos muestran filas de encuestados únicos sin información de marca/organización . Hay una fila de encuestado única por respuesta.
Consejo Q:Creando una filtro para Singular = 1 se mostrará el número de encuestados individuales.
- Cuando Singular = 0, la fila contiene datos de marca/organización . Hay varias filas de datos de marca/organización para cada encuestado.
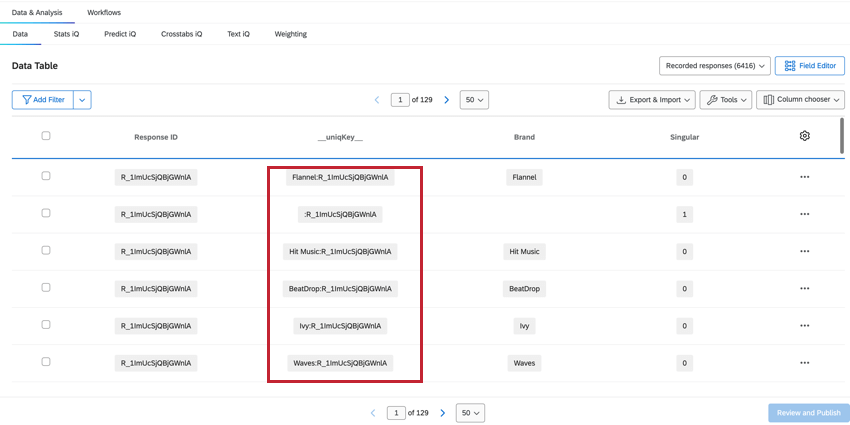
CLAVE UNIQ
El __claveuniq__ El campo combina el ResponseID y el nombre de la marca/organización , que se muestra como Marca: ResponseID. Para la fila de encuestado único sin información de marca/organización , la misma fila donde Singular = 1, se utilizará __uniqKey__. : ResponseID. Esto es útil para delimitar la respuesta exacta de la cual provienen estos datos, así como la marca/organización específica sobre la cual brindan opinión .
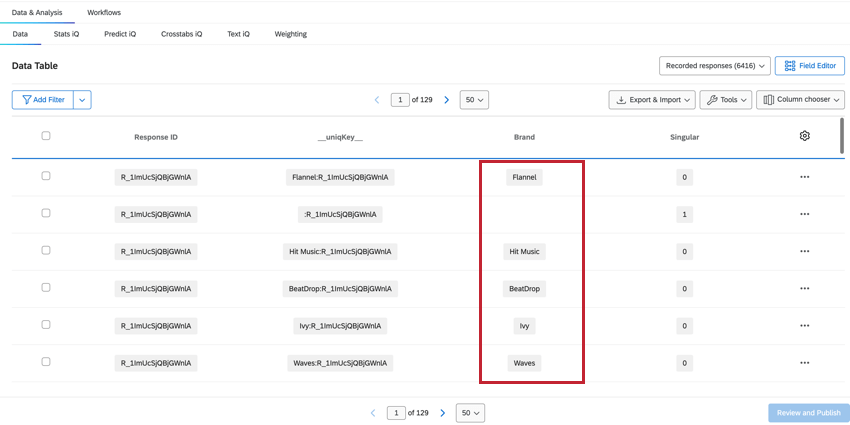
MARCA/ORGANIZACIÓN
El Marca/organización El campo muestra a qué marca/organización se refieren los datos de esa columna, lo que le permite ver y filtro para datos de marca/organización .
ATRIBUTO- LED MULTI-SELECCIÓN DE DATOS
Las preguntas basadas en atributos contienen las marcas como opciones de respuesta. Estos son típicamente tipos de preguntas de selección múltiple, y hay varias columnas con datos correspondientes a esa pregunta.
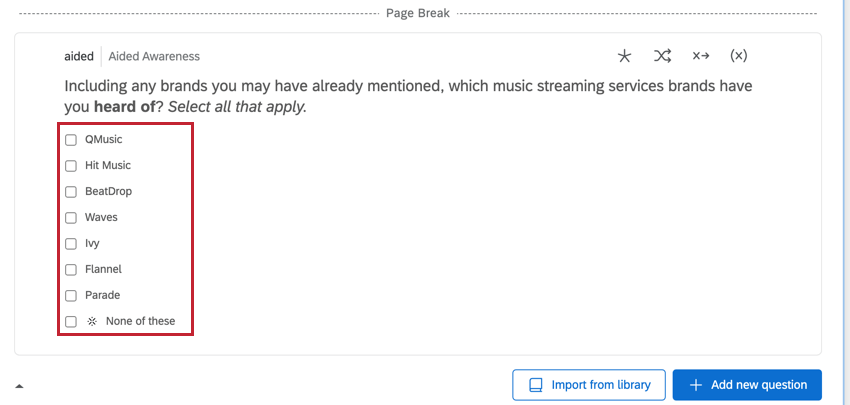
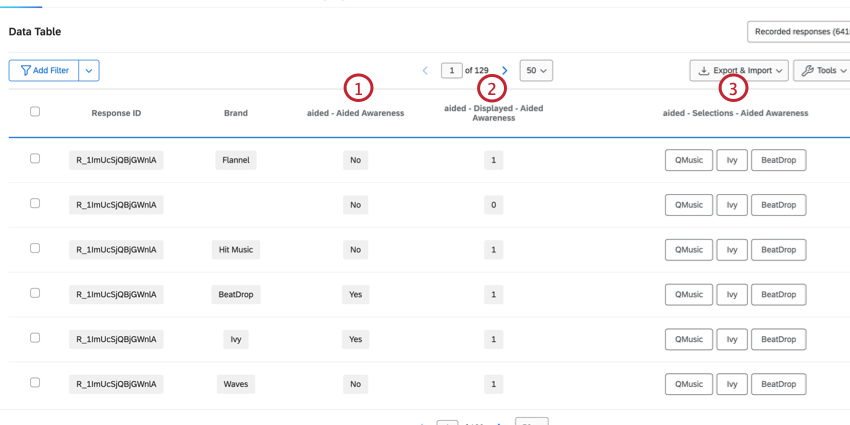
- Pregunta:Determina si la marca/organización fue seleccionada para esa pregunta. Los datos serán un 1 (“Sí”) o un 0 (“No”).
- Pregunta – Mostrada:Determina si la marca/organización se mostró para esa pregunta. Los datos serán 1 (mostrados) o 0 (no mostrados).
- Pregunta – Selecciones:Contiene todas las marcas que fueron seleccionadas para esa pregunta. Habrá varios valores en esta columna y la lista de valores será la misma para todas las filas de ese encuestado.
PREGUNTAS SOBRE BUCLE Y FUSIÓN DE DATOS
También hay varias columnas para preguntas que tubo en el nombre de la marca/organización utilizando bucle y fusión.
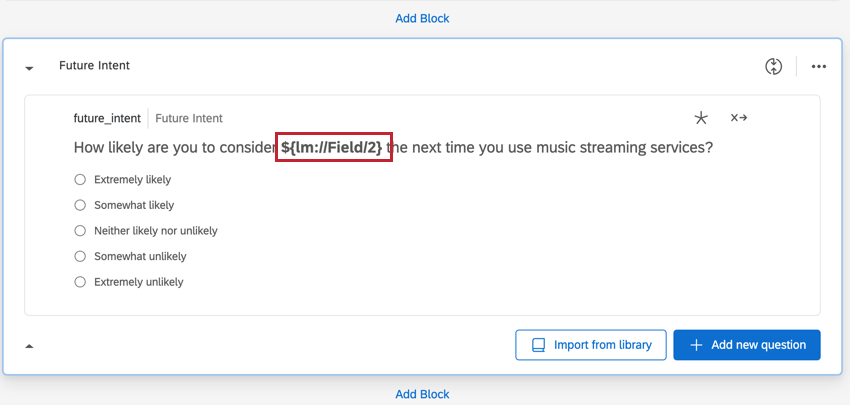
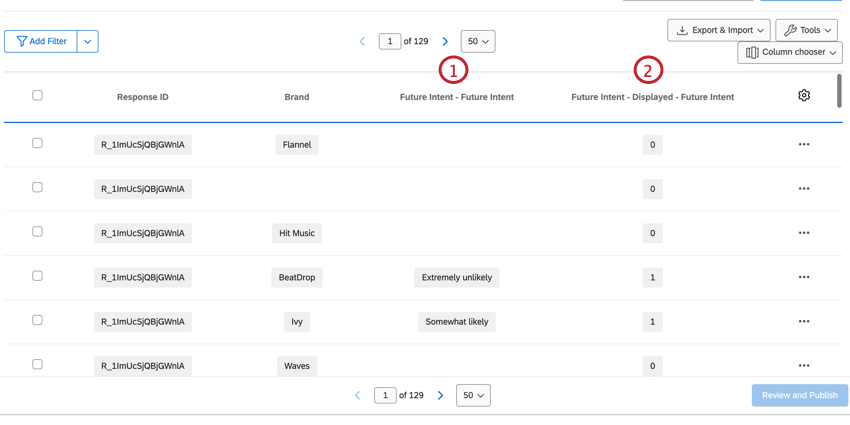
- Pregunta:Muestra qué opción de respuesta fue seleccionada para la pregunta.
- Pregunta – Mostrada:Determina si la marca/organización se mostró para esa pregunta. Los datos serán 1 (mostrados) o 0 (no mostrados).
DATOS NO APILADOS
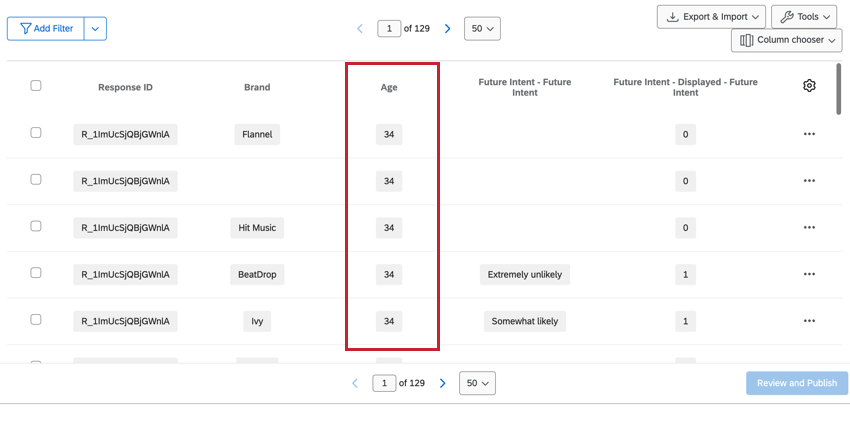
Los datos no apilados no están relacionados con la marca/organización, como las preguntas estándar (por ejemplo, datos demográficos) y los datos no apilados. campos de datos embebidos. Estos campos son repetido por marca/organización, lo que mantiene los datos disponibles ya sea que esté mirando una marca/organización específica o todas las marcas.
Generando el BTDS
Si crea un programa BX desde cero, la fuente de datos de Marca/organización Tracker no se genera automáticamente y debe generarse antes de la recopilación de datos. Cualquier dato recopilado antes de que se genere el BTDS no se acumulará.
- Crear un Programa BX.
- Navega hasta tu encuesta BX.
- Entrar en el flujo de la encuesta.
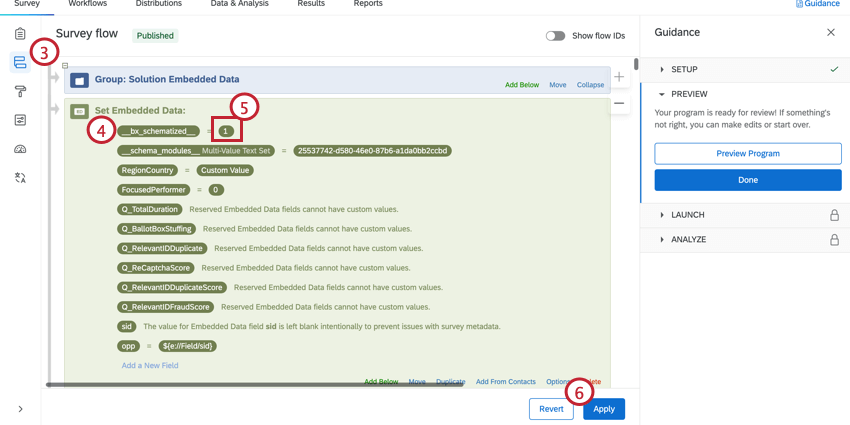
- Encuentra el __bx_esquematizado__. Debe ser el primer campo de datos embebidos en el flujo de la encuesta.
- Cambiar el valor a 1.
- Haga clic en Aplicar.
- Regrese al editor de encuesta y haga clic en Publicar a publicar tu encuesta.
Compatibilidad de conjuntos de datos apilados
Los conjuntos de datos apilados tienen limitaciones en cuanto a qué tipos de campo y tipos de preguntas Funciona mejor para el procesamiento de datos. Al crear su programa BX, es importante asegurarse de que la estructura de la encuesta sea compatible con el BTDS que se generará.
El BTDS es compatible con los siguientes tipos de preguntas:
- Opción múltiple (selección simple y múltiple)
- Entrada de texto, Matriz
- Texto descriptivo
- Suma constante
- Slider
- Orden de preferencia
- Meta info
Filtrado y exportación de BTDS
Filtrar y exportar el BTDS funciona de la misma manera que filtrar y exportar desde la pestaña Datos y análisis. Estas operaciones pueden ser útiles para comprender mejor la información del Tablero , limitar el tamaño del conjunto de datos o ver subsecciones específicas del conjunto de datos apilados.
Mejoramiento
Los programas BX con grandes listas de marca/organización pueden crear conjuntos de datos más grandes de lo necesario. Con la optimización de la marca/organización , puede limitar sus datos únicamente a las marcas que son significativas.
- Navega hasta el proyecto BX Flujo de la Encuesta.
- En el bloque de datos embebidos , haga clic en Agregar un nuevo campo.
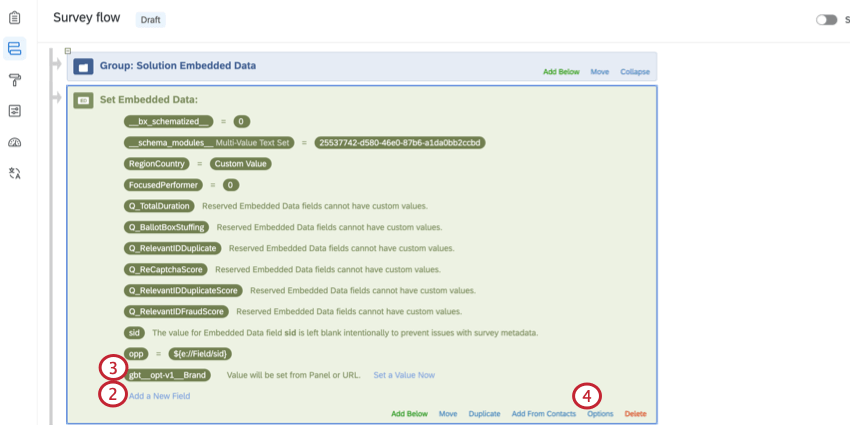
- Nombrar el campo
gbt__opt-v1__Marca. - Hacer clic Opciones.
- Para la variable creada en el paso 3, seleccione Conjunto de texto de múltiples valores como el tipo de variable.
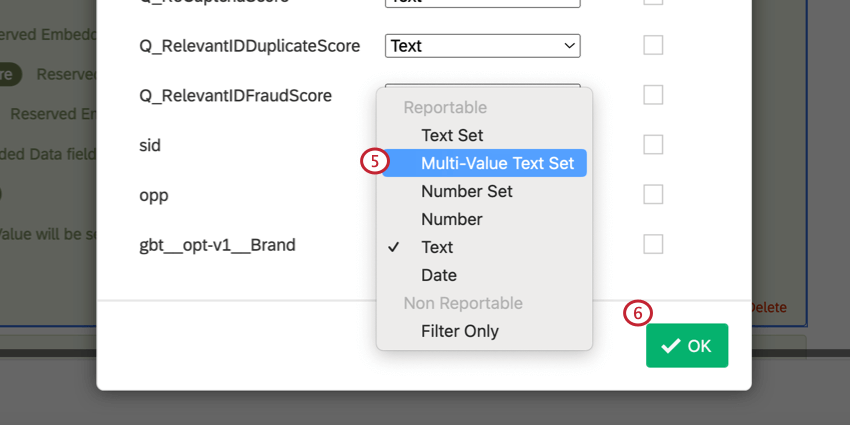
- Haga clic en Aceptar.
- Después de la pregunta que define la lista de marca/organización , añadir una rama. En el ejemplo anterior, esta rama estaría después de la pregunta sobre los países.
- Hacer clic Agregar una condición.
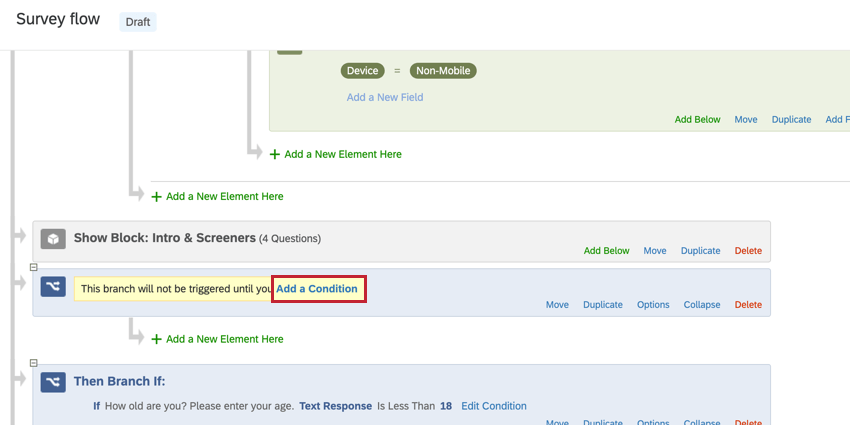
- Crea la condición que definirá tu lista de marca/organización . Para el ejemplo anterior, sería “Canadá”.
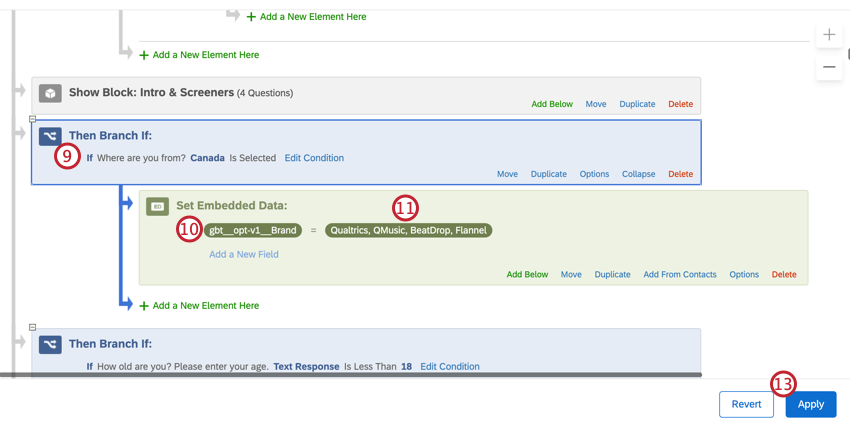
- Agregue la variable que creó en el paso 3.
- Introduzca las marcas sobre las que desea informar. Para el ejemplo anterior, estas serían las 4 marcas que le interesan a Canadá.
- Repita los pasos 7 a 9 para las demás listas de marca/organización que desee optimizar.
- Haga clic en Aplicar.
- Publicar tu encuesta.
Con la variable de optimización definida, el BTDS procesado eliminará las filas que no estén incluidas en la lista para esa variable.
Solución de problemas con BTDS
Los problemas comunes con el BTDS incluyen:
- El recuento de respuestas es diferente entre el BTDS y los Datos y Análisis de la encuesta.
- Las preguntas o campos de la marca/organización son No apilar o apilar incorrectamente después de generar el BTDS.
CONTEO DE RESPUESTAS
Para comparar los recuentos de respuestas entre el conjunto de datos de la encuesta y el BTDS, filtro el BTDS para Singular = 1. Compare este recuento con el recuento total en el conjunto de datos de la encuesta . Si los datos fluyen correctamente, estos dos números deberían coincidir.
Si estos números no coinciden, podría haber componentes incompatibles en la encuesta. Revisar Mejores prácticas de los programas BX. Si todos los componentes parecen correctos, por favor contacto con el Soporte técnico de Qualtrics con una lista de ID de respuestas afectadas.
NO APILAR O APILAR DE FORMA INCORRECTA
- Consulte la lista de Opción reutilizables y todas las preguntas relacionadas con la marca. Los nombres de las marca/organización deben coincidir exactamente a la lista de Opción reutilizables.
- Asegúrese de que no haya subcadenas dentro de la lista de marca/organización (por ejemplo, una marca/organización “Qualtrics” y otra marca/organización “Qualtrics Employee Experience”).
- Asegúrese de que el texto de la pregunta coincida exactamente con cada pregunta que se va a acumular. Los diferentes campos de texto dinámico en cada pregunta (por ejemplo, texto dinámico para diferentes logotipos por marca/organización) evitarán que las preguntas se apilen, lo que es especialmente común en las preguntas de Matriz .
- Consulte los resultados de Revisión de expertos > Apilamiento de datos para ver si hay algún problema marcado.