Análisis de correspondencia (BX)
Contenidos de la página
Acerca del análisis de correspondencia
El análisis de correspondencia revela las relaciones relativas entre y dentro de dos grupos de variables, basándose en datos proporcionados en una tabla de contingencia. Para la percepción de marca/organización , estos dos grupos son:
Por ejemplo, supongamos que una empresa quiere saber qué atributos asocian los consumidores con diferentes marcas de bebidas. El análisis de correspondencia ayuda a medir las similitudes entre las marcas y la fortaleza de las marcas en términos de sus relaciones con diferentes atributos. Comprender las relaciones relativas permite a los propietarios de marca/organización identificar los efectos de acciones anteriores sobre diferentes atributos relacionados con la marca/organización y decidir los siguiente pasos a seguir.
El análisis de correspondencia es valioso en las percepciones de la marca/organización por un par de razones. Al intentar mirar relativo Relaciones entre marcas y atributos: el tamaño de la marca/organización puede tener un efecto engañoso; el análisis de correspondencias elimina este efecto. El análisis de correspondencia también proporciona una vista rápida intuitiva de las relaciones de los atributo de la marca/organización (según la proximidad y la distancia desde el origen) que no ofrecen muchos otros gráficos.
Consejo Q: Esta página trata sobre la teoría del análisis de correspondencias; para el widget específico, consulte Widget de análisis de correspondencia.
En esta página, repasaremos un ejemplo de cómo aplicar el análisis de correspondencia a un caso de uso para diferentes marcas (ficticias) de productos de gaseosas.
Comencemos con el formato de datos de entrada: una tabla de contingencia.
Tablas de contingencia
Una tabla de contingencia es una tabla bidimensional con grupos de variables en las filas y columnas. Si nuestros grupos, como se describe arriba, fueran marcas y sus atributos asociados, realizaríamos encuestas y obtendríamos diferentes recuentos de respuestas que asociarían diferentes marcas con los atributos dados. Cada celda de la tabla representa el número de respuestas o recuentos que asocian ese atributo con esa marca/organización. Esta “asociación” se mostraría a través de una pregunta de encuesta como “Elija marcas de la siguiente lista que crea que muestran el atributo___”.
Aquí los dos grupos son “marcas” (filas) y “atributos” (columnas). La celda en la esquina inferior derecha representa el recuento de respuestas para la marca/organización “Brawndo” y el atributo”Económico”.
| Sabroso | Estético | Económico | |
|---|---|---|---|
| Cerveza de mantequilla | 5 | 7 | 2 |
| Squishy | 18 | 46 | 20 |
| ronroneo | 19 | 29 | 39 |
| Bebida gaseosa estimulante | 12 | 40 | 49 |
| Brawndo | 3 | 7 | 16 |
Residuos (R)
En el análisis de correspondencia, queremos observar los residuos de cada celda. Un residuo cuantifica la diferencia entre los datos observados y los datos que esperaríamos, asumiendo que no hay relación entre las categorías de fila y columna (aquí, serían marca/organización y atributo). Un residuo positivo nos muestra que el recuento para ese par de atributo de marca/organización es mucho mayor de lo esperado, lo que sugiere una relación fuerte; en consecuencia, un residuo negativo muestra un valor menor de lo esperado, lo que sugiere una relación más débil. Veamos cómo calcular estos residuos.
Un residuo (R) es igual a: R = P – E, donde P son las proporciones observadas y E son las proporciones esperadas para cada celda. ¡Desglosemos estas proporciones observadas y esperadas!
Proporciones observadas (P)
Una proporción observada (P) es igual al valor de una celda dividido por la suma total de todos los valores de la tabla. Entonces, para nuestra tabla de contingencia anterior, la suma total sería: 5 + 7 + 2 + 18 … + 16 = 312. Dividiendo cada valor de celda por los resultados totales en la siguiente tabla para obtener las proporciones observadas (P).
Por ejemplo, en la celda inferior derecha, tomamos nuestro valor de celda inicial de 16/312 = 0,051. Esto nos indica la proporción de nuestro gráfico completo que representa la combinación de Brawndo y Economic según nuestros datos recopilados.
| Sabroso | Estético | Económico | |
|---|---|---|---|
| Cerveza de mantequilla | 0,016 | 0,022 | 0.006 |
| Squishy | 0,058 | 0,147 | 0.064 |
| ronroneo | 0,061 | 0,093 | 0.125 |
| Bebida gaseosa estimulante | 0,038 | 0,128 | 0.157 |
| Brawndo | 0,01 | 0,022 | 0.051 |
Masas de filas y columnas
Algo que podemos calcular fácilmente a partir de nuestras proporciones observadas, y que se usará mucho más adelante, son las sumas de las filas y columnas de nuestra tabla de proporciones, que se conocen como masas de filas y columnas. Una masa de fila o columna es la proporción de valores para esa fila/columna. La masa de la fila para “Butterbeer”, mirando nuestro gráfico anterior, sería 0,016 + 0,022 + 0,006, lo que nos da 0,044.
Haciendo cálculos similares llegamos a:
| Sabroso | Estético | Económico | Masas de fila | |
|---|---|---|---|---|
| Cerveza de mantequilla | 0,016 | 0,022 | 0,006 | 0.044 |
| Squishy | 0,058 | 0,147 | 0,064 | 0.269 |
| ronroneo | 0,061 | 0,093 | 0,125 | 0.279 |
| Bebida gaseosa estimulante | 0,038 | 0,128 | 0,157 | 0.324 |
| Brawndo | 0,01 | 0,022 | 0,051 | 0.083 |
| Masas de columnas | 0.182 | 0.413 | 0.404 |
Proporciones esperadas (E)
Las proporciones esperadas (E) serían las que esperamos ver en la proporción de cada celda, asumiendo que no hay relación entre filas y columnas. Nuestro valor esperado para una celda sería la masa de la fila de esa celda multiplicada por la masa de la columna de esa celda.
Vea en la celda superior izquierda la masa de la fila de Butterbeer multiplicada por la masa de la columna de Tasty, 0,044 * 0,182 = 0,008.
| Sabroso | Estético | Económico | |
|---|---|---|---|
| Cerveza de mantequilla | 0.008 | 0.019 | 0.018 |
| Squishy | 0.049 | 0.111 | 0.109 |
| ronroneo | 0,051 | 0.115 | 0.113 |
| Bebida gaseosa estimulante | 0.059 | 0.134 | 0.131 |
| Brawndo | 0.015 | 0.034 | 0,034 |
Ahora podemos calcular nuestra tabla de residuos (R), donde R = P – E. Los residuos cuantifican la diferencia entre nuestras proporciones de datos observadas y nuestras proporciones de datos esperadas, si asumimos que no hay relación entre las filas y las columnas.
Tomando nuestro valor más negativo de -0,045 para Squishee y Económico, lo que interpretaríamos aquí es que hay una asociación negativa entre Squishee y Económico; es mucho menos probable que Squishee sea visto como “Económico” que nuestras otras marcas de bebidas.
| Sabroso | Estético | Económico | |
|---|---|---|---|
| Cerveza de mantequilla | 0,008 | 0.004 | -0.012 |
| Squishy | 0.009 | 0.036 | -0.045 |
| ronroneo | 0,01 | -0,022 | 0,012 |
| Bebida gaseosa estimulante | -0.021 | -0,006 | 0.026 |
| Brawndo | -0,006 | -0,012 | 0,018 |
Residuos indexados (I)
Sin embargo, la simple lectura de los residuos plantea algunos problemas.
Mirando la fila superior de nuestra tabla de cálculo de residuos anterior, vemos que todos estos números están muy cerca de cero. No deberíamos sacar de esto la conclusión obvia de que la cerveza de mantequilla no está relacionada con nuestros atributos, ya que esta suposición es incorrecta. La explicación real sería que las proporciones observadas (P) y las proporciones esperadas (E) son pequeñas porque, como nos dice nuestra masa de filas, solo el 4,4% de la muestra son cerveza de mantequilla.
Esto plantea un gran problema a la hora de analizar los residuos, ya que debido a que no tenemos en cuenta el número real de registros en las filas y columnas, nuestros resultados están sesgados hacia las filas/columnas con masas mayores. Podemos solucionar esto dividiendo nuestros residuos por nuestras proporciones esperadas (E), lo que nos dará una tabla de nuestros Residuos indexados (I, I = R / E):
| Sabroso | Estético | Económico | |
|---|---|---|---|
| Cerveza de mantequilla | 0.95 | 0,21 | -0.65 |
| Squishy | 0,17 | 0,32 | -0,41 |
| ronroneo | 0,2 | -0,19 | 0,11 |
| Bebida gaseosa estimulante | -0,35 | -0,04 | 0,2 |
| Brawndo | -0,37 | -0,35 | 0.52 |
Los residuos indexados son fáciles de interpretar: cuanto más alejado esté el valor de la tabla, mayor será la proporción observada en relación con la proporción esperada.
Por ejemplo, tomando el valor superior izquierdo, la cerveza de mantequilla tiene un 95% más de probabilidades de ser vista como “sabrosa” de lo que esperaríamos si no hubiera relación entre estas marcas y atributos. Mientras que en el valor superior derecho, la cerveza de mantequilla tiene un 65% menos de probabilidades de ser vista como “económica” de lo que esperaríamos, dada la falta de relación entre nuestras marcas y atributos.
| Sabroso | Estético | Económico | |
|---|---|---|---|
| Cerveza de mantequilla | 0,95 | 0,21 | -0,65 |
| Squishy | 0,17 | 0,32 | -0,41 |
| ronroneo | 0,2 | -0,19 | 0,11 |
| Bebida gaseosa estimulante | -0,35 | -0,04 | 0,2 |
| Brawndo | -0,37 | -0,35 | 0,52 |
Dados nuestros residuos indexados (I), nuestras proporciones esperadas (E), nuestras proporciones observadas (P) y nuestras masas de filas y columnas, ¡vamos a calcular nuestros valores de análisis de correspondencia para nuestro gráfico!
Cálculo de coordenadas para el análisis de correspondencia
Descomposición en valores singulares (SVD)
Nuestro primer paso es calcular la descomposición en valores singulares, o SVD. La SVD nos proporciona valores para calcular la varianza y graficar nuestras filas y columnas (marcas y atributos).
Calculamos la SVD en el residuo estandarizado (Z), donde Z = I * sqrt(E), donde I es nuestro residuo indexado y E son nuestras proporciones esperadas. Al multiplicar por E, nuestro SVD se pondera, de modo que las celdas con un valor esperado más alto reciben un peso mayor, y viceversa, lo que significa que, como los valores esperados a menudo están relacionados con el tamaño de la muestra , las celdas “más pequeñas” de la tabla, donde el error de muestreo habría sido mayor, se ponderan de manera descendente. Por lo tanto, el análisis de correspondencia mediante una tabla de contingencia es relativamente robusto ante valores atípicos causados por errores de muestreo.
Volviendo a nuestra SVD, tenemos: SVD = svd(Z). Una descomposición en valores singulares genera tres resultados:
Un vector, d, que contiene la valores singulares
| Primera dimensión | 2da dimensión | 3ra dimensión |
|---|---|---|
| 2.65E-01 | 1.14E-01 | 4.21E-17 |
Una matriz, u, que contiene la vectores singulares de izquierda (marcas).
| Primera dimensión | 2da dimensión | 3ra dimensión | |
|---|---|---|---|
| Cerveza de mantequilla | -0.439 | -0.424 | -0.084 |
| Squishy | -0.652 | 0.355 | -0.626 |
| ronroneo | 0.16 | -0.0672 | -0,424 |
| Bebida gaseosa estimulante | 0.371 | 0.488 | -0.274 |
| Brawndo | 0.469 | -0.06 | -0.588 |
Una matriz, v, que contiene la vectores singulares correctos (atributos).
| Primera dimensión | 2da dimensión | 3ra dimensión | |
|---|---|---|---|
| Sabroso | -0,41 | -0.81 | -0.427 |
| Estético | -0.489 | >0.59 | -0.643 |
| Económico | 0.77 | -0.055 | -0.635 |
Los vectores singulares de la izquierda corresponden a las categorías en las filas de la tabla, y los vectores singulares de la derecha corresponden a las columnas. Cada uno de los valores singulares, para calcular la varianza, y los vectores correspondientes (es decir, columnas de u y v), para representar las posiciones, corresponden a una dimensión. Las coordenadas utilizadas para trazar categorías de filas y columnas para nuestro gráfico de análisis de correspondencia se derivan de las dos primeras dimensiones.
Varianza expresada por nuestras dimensiones
Los valores singulares al cuadrado se conocen como valores propios (d^2). Los valores propios en nuestro ejemplo son 0,0704, 0,0129 y 0,0000. Expresar cada valor propio como una proporción de la suma total nos indica la cantidad de diferencia capturado en cada dimensión de nuestro análisis de correspondencia, basado en el valor singular de cada dimensión; obtenemos el 84,5% de la varianza expresada por nuestra primera dimensión y el 15,5% en nuestra segunda dimensión (nuestra tercera dimensión explica el 0% de la varianza).
Análisis de correspondencia estándar
Ahora estamos equipados con los recurso para calcular la forma básica del análisis de correspondencia, utilizando lo que se conoce como coordenadas estándar, calculado a partir de nuestros vectores singulares izquierdo y derecho. Anteriormente, ponderamos los residuos indexados antes de realizar la SVD. Para obtener coordenadas que representen nuestros residuos indexados, ahora necesitamos desponderar las salidas del SVD, dividiendo cada fila de los vectores singulares de la izquierda por la raíz cuadrada de las masas de las filas, y dividiendo cada columna de los vectores singulares de la derecha por la raíz cuadrada de las masas de las columnas, lo que nos da las coordenadas estándar de las filas y columnas para graficar.
Coordenadas estándar de la Marca/organización :
| Primera dimensión | 2da dimensión | 3ra dimensión | |
|---|---|---|---|
| Cerveza de mantequilla | -2.07 | -2 | -0,4 |
| Squishy | -1.27 | 0.68 | -1.21 |
| ronroneo | 0.3 | -1,27 | -0,8 |
| Bebida gaseosa estimulante | 0,65 | 0.86 | -0.48 |
| Brawndo | 1.62 | -0,21 | -2.04 |
Coordenadas estándar del Atributo :
| Primera dimensión | 2da dimensión | 3ra dimensión | |
|---|---|---|---|
| Sabroso | -0.96 | -1.89 | -1 |
| Estético | -0.76 | 0.92 | >-1 |
| Económico | 1.21 | -0.09 | -1 |
Utilizamos las dos dimensiones con la mayor varianza capturada para trazar el gráfico, la primera dimensión en el eje X y la segunda dimensión en el eje Y, generando nuestro gráfico de análisis de correspondencia estándar.
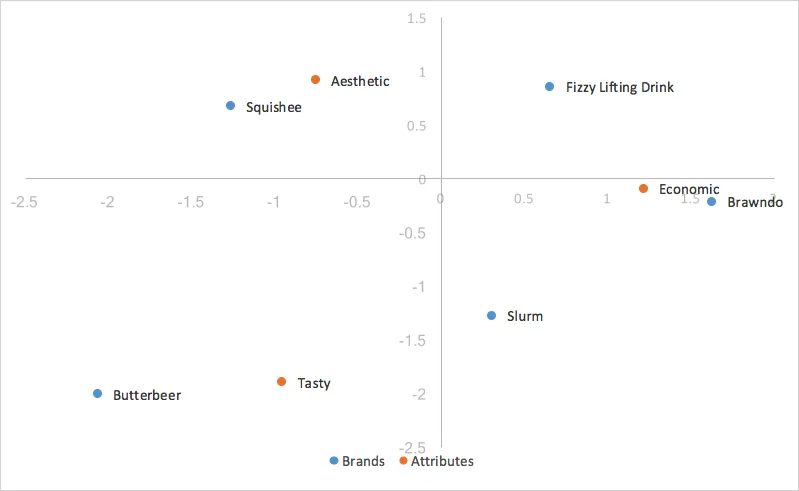
Hemos sentado las bases de los cálculos que necesitamos para el análisis de correspondencia estándar. En la siguiente sección exploraremos los pros y los contras de los diferentes estilos de análisis de correspondencia y cuál se adapta mejor a nuestros propósitos de ayudar en el análisis de las percepciones de la marca/organización .
Tipos de análisis de correspondencia
Análisis de correspondencia principal entre filas y columnas
El análisis de correspondencia estándar es fácil de calcular y se pueden extraer resultados sólidos de él. Sin embargo, la correspondencia estándar es una mala opción para nuestras necesidades; las distancias entre las coordenadas de filas y columnas son exageradas y no existe una interpretación sencilla de las relaciones entre las categorías de filas y columnas. Lo que queremos para interpretar las relaciones entre las coordenadas de fila (marca/organización) y las relaciones entre las categorías de fila y columna es normalización principal de filas (o, si nuestras marcas estuvieran en nuestras columnas, normalización principal de columna).
Para la normalización principal de filas, desea utilizar las coordenadas estándar calculadas anteriormente para los valores de su columna (atributo), pero desea calcular las coordenadas principales para los valores de su fila (marca/organización). Calcular las coordenadas principales es tan simple como tomar las coordenadas estándar y multiplicarlas por sus valores singulares correspondientes (d). Entonces, para nuestras filas, solo queremos multiplicar nuestras coordenadas de fila estándar por nuestros valores singulares (d), que se muestran en la siguiente tabla. Para la normalización principal de columnas, simplemente multiplicaríamos nuestras columnas en lugar de nuestras filas por nuestros valores singulares (d).
| Primera dimensión | 2da dimensión | 3ra dimensión | |
|---|---|---|---|
| Cerveza de mantequilla | -0.55 | -0.23 | 0 |
| Squishy | -0.33 | 0.08 | 0 |
| ronroneo | 0,08 | -0.14 | 0 |
| Bebida gaseosa estimulante | 0,17 | 0,1 | 0 |
| Brawndo | 0.43 | -0.02 | 0 |
Sustituyendo nuestras coordenadas principales por nuestras filas (marcas), obtenemos:
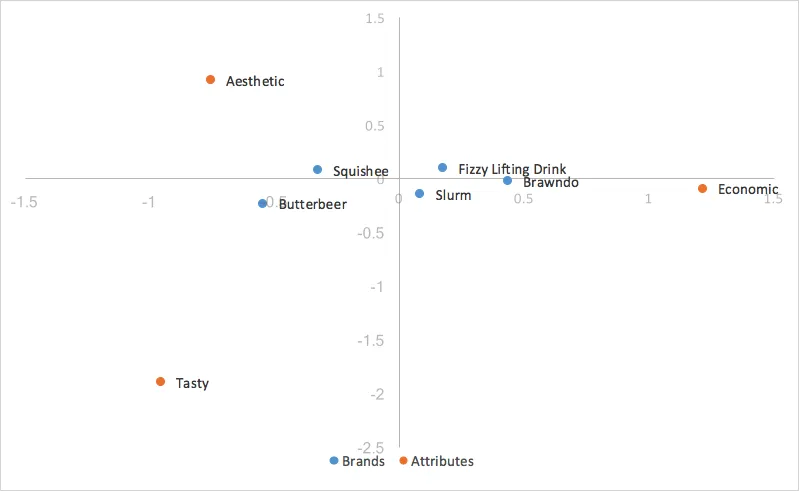
Debido a que escalamos por nuestros valores singulares, nuestras coordenadas principales para nuestras filas representan la distancia entre los perfiles de filas de nuestra tabla original; uno puede interpretar las relaciones entre nuestras coordenadas de filas en nuestro gráfico de análisis de correspondencia por su proximidad entre sí.
La distancia entre las coordenadas de nuestras columnas, dado que se basan en coordenadas estándar, es aún exagerada. Además, nuestra escala por nuestros valores singulares en solo una de las dos categorías (filas/columnas) nos ha dado una forma de interpretar las relaciones entre las categorías de filas y columnas. Dado un valor de fila y un valor de columna, por ejemplo, Butterbeer (fila) y Tasty (columna), cuanto mayor sea su distancia al origen, más fuerte será su asociación con otros puntos del mapa. Además, cuanto menor sea el ángulo entre los dos puntos (Butterbeer y Tasty), mayor será la correlación entre ambos.
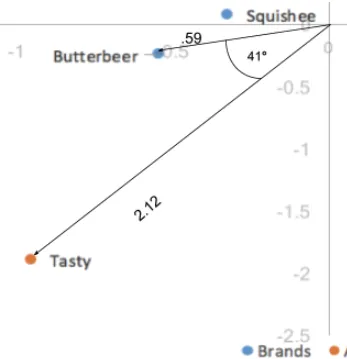
La distancia al origen combinada con el ángulo entre los dos puntos es el equivalente a tomar el producto escalar; el producto escalar entre un valor de fila y columna mide la fuerza de la asociación entre los dos. De hecho, cuando la primera y la segunda dimensión explican toda la varianza de los datos (suman 100%), el producto escalar es directamente igual al residuo indexado de las dos categorías. Aquí, el producto escalar sería la distancia al origen de los dos puntos multiplicada por el coseno del ángulo entre ellos; 0,59*2,12*cos(41) = 0,94. Teniendo en cuenta los errores de redondeo, es igual a nuestro valor residual indexado de 0,95. Así, los ángulos menores de 90 grados representan un residuo indexado positivo y, por lo tanto, una asociación positiva, y los ángulos mayores de 90 grados representan un residuo indexado negativo o una asociación negativa.
Análisis de correspondencias principales por filas escaladas
Al observar nuestro gráfico anterior para la normalización principal de filas, tenemos una observación fácil: los puntos para nuestras columnas (rasgos) están mucho más dispersos y nuestros puntos para nuestras filas (marcas) están agrupados alrededor del origen. Esto puede hacer que analizar nuestro gráfico a simple vista sea bastante difícil y poco intuitivo, y a veces imposible leer las categorías de filas si todas se superponen. Afortunadamente, hay una manera fácil de escalar nuestro gráfico para incluir nuestras columnas, mientras se mantiene la capacidad de utilizar el producto escalar (distancia desde el origen y ángulo entre puntos) para analizar las relaciones entre nuestros puntos de fila y columna, conocido como Normalización principal de fila escalada.
La normalización principal de filas escaladas toma la normalización principal de filas y escala las coordenadas de las columnas de la misma manera que escalamos el eje x de las coordenadas de las filas; en otras palabras, nuestras coordenadas de columnas se escalan por el primer valor de nuestros valores singulares (d). Nuestros valores de fila permanecen iguales que la normalización principal de fila, pero ahora nuestras coordenadas de columna se reducen mediante un factor constante.
| Primera dimensión | 2da dimensión | 3ra dimensión | |
|---|---|---|---|
| Sabroso | -0.2544 | -0.501 | -0.265 |
| Estético | -0.201 | 0.2438 | -0,265 |
| Económico | 0.321 | -0,02 | -0,265 |
Lo que esto significa para nosotros es que nuestras coordenadas de columna se escalan para ajustarse mucho mejor a nuestras coordenadas de fila, lo que hace mucho más fácil analizar tendencias. Debido a que escalamos todas las coordenadas de nuestras columnas con el mismo factor constante, contrajimos la dispersión de las coordenadas de nuestras columnas en el mapa, pero no hicimos ningún cambio en sus relatividades; todavía utilizamos el producto escalar para medir la fuerza de las asociaciones. El único cambio es que cuando nuestra primera y segunda dimensión cubren toda la varianza de los datos, en lugar de que el residuo indexado sea igual al producto escalar de las dos categorías, ahora es igual al escamoso producto escalar de las dos categorías, que es el producto escalar por un valor constante de nuestro primer valor singular (d). La interpretación del gráfico sigue siendo la misma que la normalización principal de filas.
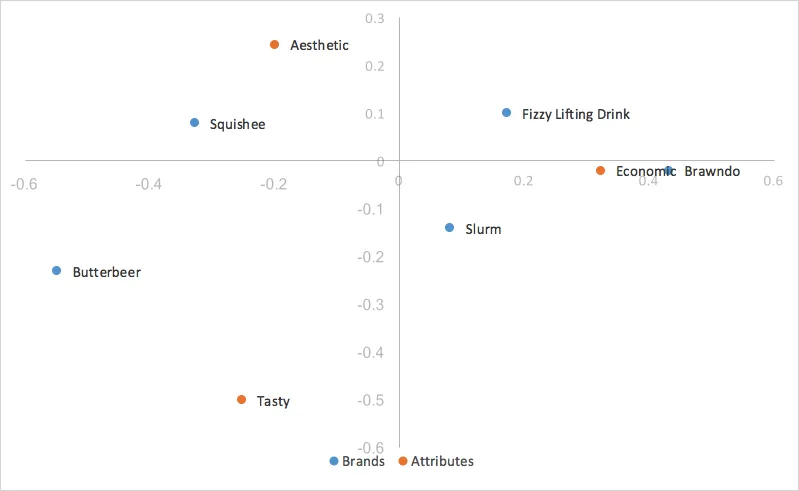
Análisis de correspondencia principal
Una última forma de análisis de correspondencia que mencionaremos es el análisis de correspondencia principal, también conocido como mapa simétrico, escala francesa o análisis de correspondencia canónica. En lugar de solo multiplicar las filas o columnas estándar por los valores singulares (d) como en el análisis de correspondencia principal fila/columna, multiplicamos ambas por los valores singulares. Por lo tanto, nuestros valores de columna estándar, multiplicados por los valores singulares, se convierten en:
| Primera dimensión | 2da dimensión | 3ra dimensión | |
|---|---|---|---|
| Sabroso | -0,2544 | -0.215 | 0 |
| Estético | -0,201 | 0.105 | 0 |
| Económico | 0,321 | -0,01 | 0 |
Al unir esto con nuestros valores de fila calculados en el análisis principal de fila, obtenemos:
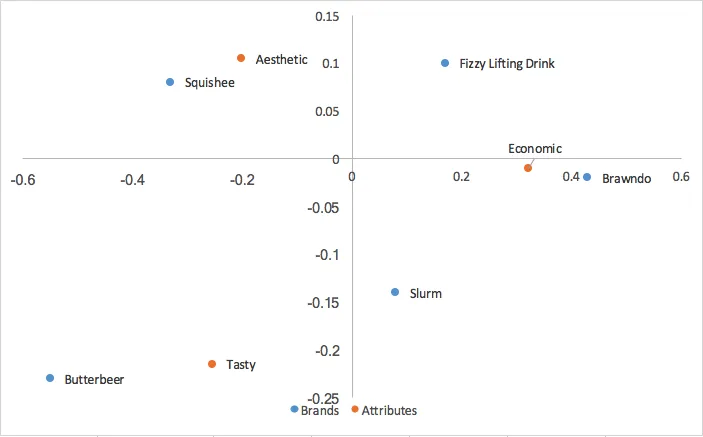
El análisis de correspondencia canónica escala las coordenadas de fila y columna mediante los valores singulares. Lo que esto significa es que podemos interpretar nuestras relaciones entre nuestras coordenadas de fila tal como lo hicimos en el análisis de correspondencia principal de fila (basado en la proximidad), Y podemos interpretar nuestras relaciones entre nuestras coordenadas de columna de manera similar al análisis de correspondencia principal de columna; podemos analizar las relaciones entre marcas y las relaciones entre atributos. También perdemos la agrupación de filas/columnas en el centro del mapa del análisis principal de filas/columnas. Sin embargo, lo que perdemos del análisis de correspondencia canónica es una forma de interpretar las relaciones entre nuestras marcas y atributos, algo muy útil en las percepciones de marca/organización .
Comparación lado a lado
Análisis de correspondencia estándar
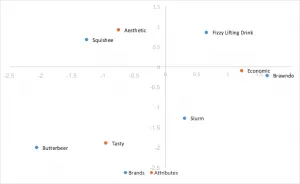
El estilo de análisis de correspondencia más fácil de calcular, utilizando vectores singulares izquierdo y derecho de SVD divididos por las masas de filas y columnas. Las distancias entre las coordenadas de filas y columnas están exageradas y no existe una interpretación sencilla de las relaciones entre las categorías de filas y columnas.
Análisis de correspondencia de normalización de filas principales
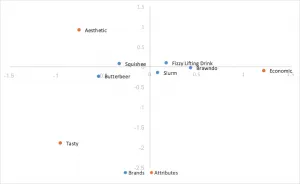
Utiliza las coordenadas estándar de arriba, pero multiplica las coordenadas de la fila por los valores singulares para normalizar. Las relaciones entre filas (marcas) se basan en la distancia entre ellas. Las distancias de las columnas (atributo) aún se exageran. Las relaciones entre filas y columnas se pueden interpretar mediante el producto escalar. Las filas (marcas) tienden a estar agrupadas en el centro.
Análisis de correspondencia de normalización principal de filas escaladas
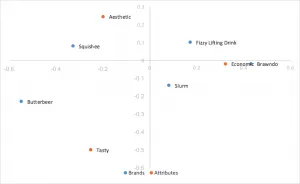
Toma la normalización principal de fila y escala las coordenadas de columna mediante una constante del primer valor singular. Se extraen las mismas interpretaciones que la normalización principal de filas, reemplazando el producto escalar por el producto escalar. Ayuda a eliminar las aglomeraciones en las filas del centro. Este es el estilo de análisis de correspondencia que preferimos.
Análisis de correspondencias de normalización principal (simétrico, mapa francés, canónico)
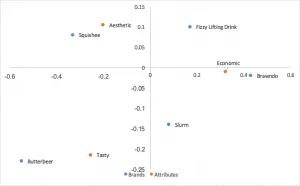
Otra forma popular de análisis de correspondencia utiliza coordenadas principales normalizadas tanto en filas como en columnas. Las relaciones entre filas (marcas) se pueden interpretar por la distancia entre ellas; lo mismo puede decirse de las columnas (atributos). No se puede extraer ninguna interpretación de las relaciones entre filas y columnas.
Terminando
En conclusión, el análisis de correspondencias se utiliza para analizar las relaciones relativas entre y dentro de dos grupos; en nuestro caso, estos grupos serían marcas y atributos.
El análisis de correspondencia elimina un sesgo en los resultados de diferentes masas entre grupos mediante el uso de residuos indexados. Para las percepciones de marca/organización para el análisis de correspondencia, utilizamos la normalización principal de filas (o principal de columnas si las marcas se colocan en las columnas), ya que esto nos permite analizar las relaciones entre diferentes marcas por su proximidad entre sí, y también nos permite analizar las relaciones entre marcas y atributos por su distancia desde el origen combinado con el ángulo entre ellos y el origen (el producto escalar), con el sacrificio de tergiversar la relación entre atributos con distancias exageradas (lo que no nos importa ya que no nos preocupamos por las relaciones entre atributos). Utilizamos la normalización principal de filas/columnas escaladas para facilitar el análisis de nuestro gráfico sin costo. Queremos asegurarnos de tener en cuenta que sumamos la varianza explicada a partir de las etiquetas de los ejes X e Y (la primera y la segunda dimensión) para ver la varianza total capturada en el mapa; cuanto menor sea este número, mayor será la varianza inexplicada en los datos y más engañoso será el gráfico.
Una última cosa para recordar es que el análisis de correspondencia solo muestra Relatividades Dado que eliminamos el factor de masa de nuestros datos, nuestro gráfico no nos dirá nada sobre qué marcas tienen las puntuaciones “más altas” en los atributos. Una vez que comprende cómo crear y analizar los gráficos, el análisis de correspondencias es una herramienta poderosa que ignora los efectos del tamaño de la marca/organización para brindar información poderosa y fácil de interpretar sobre las relaciones entre las marcas y dentro de ellas y sus atributos aplicables.
Preguntas frequentes
¿Cómo interactúan los filtros de métrica personalizados con los filtros de página en los dashboards BX?
¿Cómo interactúan los filtros de métrica personalizados con los filtros de página en los dashboards BX?
¡Genial! ¡Gracias por tus comentarios!
¡Gracias por tus comentarios!