Daten gruppieren (Studio)
Was finden Sie hier?
Informationen zum Gruppieren von Daten in Studio
Beim Erstellen eines Dashboard in Studio können Sie angeben, welche Daten Sie in das Dashboard aufnehmen möchten. Sie können die Daten in einem Bericht einschränken, indem Sie sie gruppieren, sortieren oder Filtern Ihre Daten.
Es gibt eine Vielzahl von Gruppierungen, die Sie für Ihre Daten verwenden können. Auf dieser Seite erfahren Sie, wie Sie Ihre Daten nach diesen verschiedenen Gruppierungen gruppieren.
Gruppieren von Daten in einem Widget
Tipp: Sie können Daten nicht in Metrik- oder Feedback gruppieren.
Sie können Daten in unterstützten Widget gruppieren. So gruppieren Sie die Daten in Ihrem Widget:
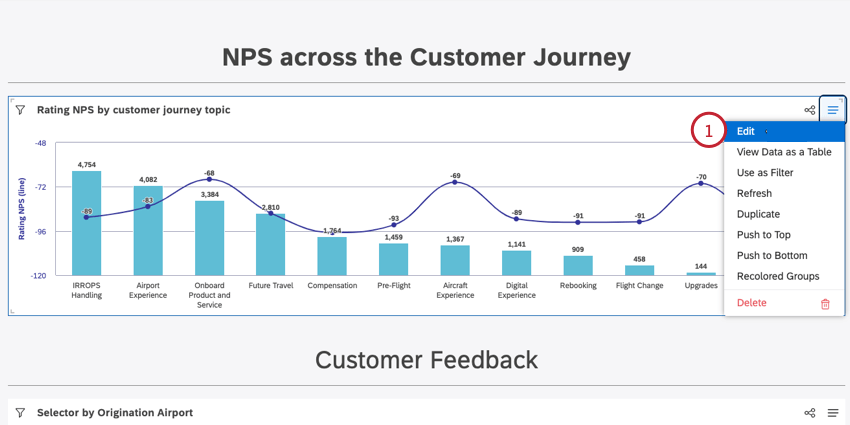
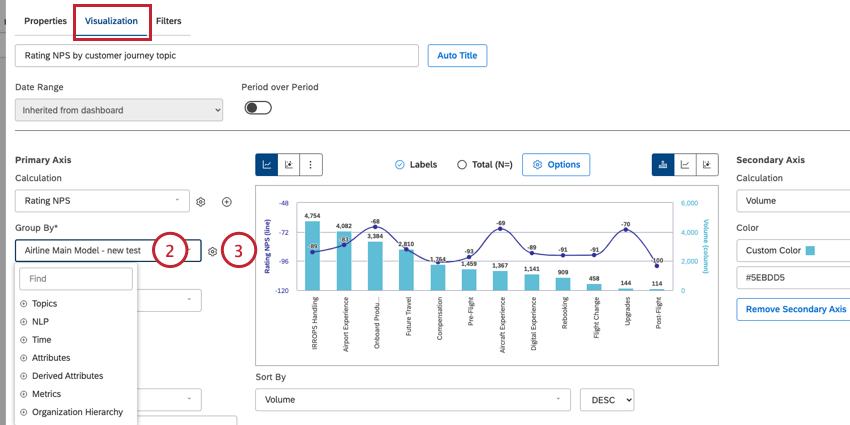
Tipp: Bei Verwendung eines Tabelle Widget, dann heißt diese Option stattdessen „Gruppierungen“. Bei Verwendung eines Heatmap Widget, dann heißt diese Option stattdessen „Boxen“. Bei Verwendung eines Netzwerk Widget, dann heißt diese Option stattdessen „Knoten“.
Themen
Auswahl Themen Mit können Sie Daten nach den Kategorien gruppieren, die aus Feedback abgeleitet wurden. Auf diese Weise erhalten Sie einen Überblick darüber, worüber Ihre Kunden sprechen.
Nachdem Sie Ihr Kategoriemodell ausgewählt haben, öffnen Sie die Gruppierungseinstellungen, um auszuwählen, welche Themen im Widget enthalten sind. Siehe Customizing Kategorienmodellgruppierungen für weitere Informationen.
Beim Gruppieren von Daten nach Themen können Sie Berichte auf verschiedenen Ebenen in Ihrem Kategoriemodell erstellen. Um einen allgemeinen Überblick darüber zu erhalten, worüber Ihre Kunden sprechen, gruppieren Sie die Daten nach Ebene 1 Themen. Um spezifischere Themen im Feedback zu überwachen, gruppieren Sie die Daten nach Ebene 2 Themen oder niedriger (abhängig von Ihrem Modell). Für den detailliertesten Bericht auf allen Ebenen gruppieren Sie die Daten mithilfe der Blatt Option, mit der Sie sich auf Themenblätter oder Kategorien konzentrieren können, die keine Unterkategorien haben.
NLP
Auswahl NLP Mit können Sie Daten nach Kriterien gruppieren, die automatisch von XM Discover erstellt werden. Diese Kriterien werden aus unstrukturiertem Feedback erstellt, das von XM Discover verarbeitet wird. Es stehen mehrere Untergruppierungen zur Auswahl:
Wörter
Die Wörter Mit NLP-Gruppierungen können Sie Daten nach Wörtern oder bestimmten Arten von Wörtern gruppieren, die im Feedback erwähnt werden. Folgende Gruppierungen stehen zur Verfügung:
- Alle Wörter: Daten nach regulären Wörtern gruppieren. Auf diese Weise erhalten Sie eine Vorstellung von den gängigsten Begriffen, die Kunden verwenden, wenn sie über Ihr Produkt oder Ihre Dienstleistung sprechen.
- Instanz: Daten nach Instanz gruppieren.
- CB-Unternehmen: Daten nach Erwähnungen der Gesellschaft gruppieren.
- CB-E-Mail-Adresse: Gruppieren Sie Daten nach E-Mail-Adressen, die im Feedback erwähnt werden.
- CB Emoticon: Gruppieren Sie Daten nach Emojis und Emoticons, die im Feedback verwendet werden.
- Ereignis: Gruppendaten über Standardferien (wie Neujahr oder Halloween), Lebensereignisse (wie Hochzeit oder Abschluss) und allgemeine kulturelle Veranstaltungen (wie der Super Bowl), die im Feedback erwähnt werden.
- Branche Zentralbank: Daten nach zugehöriger Branche gruppieren.
- CB Person: Gruppieren Sie Daten nach Namen von Personen, die im Feedback erwähnt werden.
- CB-Telefonnummer: Gruppieren Sie Daten nach Telefonnummern, die im Feedback genannt werden.
- CB-Produkt: Daten nach Produkterwähnungen gruppieren.
- CB Obszönität: Gruppieren Sie Daten nach profanen Wörtern aus einer vorgegebenen Menge.
Assoziierte Wörter
Die Assoziierte Wörter Mit der Gruppierung können Sie Daten nach Wortpaaren gruppieren, die im Feedback miteinander in Verbindung stehen. Auf diese Weise können Sie unabhängig von der Themenkategorisierung die häufigsten Themen und Themen im Feedback sehen.
Zugehörige Wörter werden im folgenden Format dargestellt: Wort 1 → Wort 2.
Beispiel: Wenn das Feedback eines Kunden „The store was dirty“ lautete und Sie nach zugehörigen Wörtern gruppieren, sehen Sie in Ihrem Widget „store → dirty“.
Hashtags
Die Hashtags Mit der Gruppierung können Sie Daten nach Hashtag-Sätzen (Wörter oder Phrasen mit dem Präfix # Symbol). Hashtags werden in der Regel in Social-Media-Beiträgen verwendet, um den Gegenstand des Beitrags zu identifizieren und zu kategorisieren.
Anreicherung
Die Anreicherung Mit Gruppierungen können Sie Daten nach den Arten von Inhalten gruppieren, die in Feedback enthalten sind. Folgende Gruppierungen stehen zur Verfügung:
- CB-Kapitel: Daten gruppieren nach dialogorientiert Kapitel, die semantisch zusammengehörige Segmente der Konversation darstellen (z.B. Eröffnung, Bedarf, Verifizierung, Lösungsschritt und Abschluss).
- CB-Content-Subtyp: Weitere Gruppe nicht inhaltlich Daten nach ihren Subtypen (z.B. Anzeigen, Coupons, Artikelverknüpfungen oder “undefinierte” Typen). Beachten Sie, dass für inhaltliche Datensätze auch der Subtyp immer inhaltlich ist.
- CB-Inhaltstyp: Daten nach gruppieren inhaltlich oder nicht inhaltlich wie von XM Discover automatisch identifiziert.
- Ermittelte CB-Funktionen: Gruppieren Sie Daten nach Typen von erkannten NLP-Funktionen (z.B. Daten, die Branchen- oder Instanz enthalten).
- CB Emotion: Daten gruppieren nach Emotion Typen, die von der NLP-Engine erkannt wurden (wie Anger, Verwirrung, Enttäuschung, Peinlichkeit, Angst, Frustration, Eifersucht, Freude, Liebe, Traurigkeit, Überraschung, Dankbarkeit, Vertrauen oder Sonstiges).
- CB Medizinischer Bedingung: Gruppieren Sie Daten nach im Text genannten Erkrankungen (z.B. “covid” oder “meningitis”).
- CB Medizinisches Verfahren: Gruppieren Sie Daten nach im Text genannten medizinischen Prozeduren (z.B. “Mammogramm” oder “Rückenoperation”).
- Teilnehmer:in: Gesprächsdaten dahingehend gruppieren, ob Vertreter Empathie in ihren Interaktionen mit Kunden gezeigt haben oder nicht. 0 bedeutet, dass der Vertreter keine Empathie gezeigt hat, während 1 bedeutet, dass der Vertreter Empathie gezeigt hat.
- SR-Grund: Gruppieren Sie Daten nach Gründen für ein bestimmtes Ereignis (z.B. Grund für Kontakt oder Grund für Empathie).
- CB Rx: Gruppieren Sie Daten nach im Text genannten Arzneimittelnamen (z.B. “Acetaminophen” oder “Tylenol”).
- Satzart VB: Gruppieren Sie Daten nach der Art des Satzes oder der Absicht (z.B. „Hilfeaufruf“ oder „Vorschlag“).
Sprache
Die Sprache Mit Gruppierungen können Sie Daten nach der Sprache gruppieren, in der das Feedback hinterlassen wurde. Folgende Gruppierungen stehen zur Verfügung:
- CB Automatisch erkannte Sprache: Daten nach Sprachen gruppieren, die automatisch ermittelt wurden (wenn die automatische Spracherkennung für ein Projekt aktiviert ist).
- CB Bearbeitete Sprache: Gruppieren Sie Daten nach Sprachen, in denen Feedback tatsächlich verarbeitet wurde. Sprachen, die von XM Discover nicht unterstützt werden, sind als „andere“ gekennzeichnet.
Konversation
Die Konversation Mit Gruppierungen können Sie Daten nach verschiedenen dialogorientierten Anreicherungen gruppieren. Beachten Sie, dass diese Gruppierungen nur für dialogorientierte Daten (Anrufe und Chats, die mit Qualtrics Konversationsformat). Folgende Gruppierungen stehen zur Verfügung:
- CB % Stille: Gruppieren Sie Daten nach dem Prozentsatz der Stille in einem Anruf.
- CB-Gesprächsdauer: Gruppieren Sie Daten nach der Dauer einer Konversation in Millisekunden. Bei Aufrufen ist dies die Zeitspanne zwischen dem Beginn des ersten Satzes und dem Ende des letzten Satzes. Führendes und nachfolgendes Schweigen wird nicht gezählt. Bei Chats ist dies die Zeitspanne zwischen dem ersten Satz und dem letzten Satz.
- CB-Art des Teilnehmer:in: Gruppieren Sie Daten nach der Art des Teilnehmer:in. Mögliche Werte sind:
- Chatbot ist ein Chatbot.
- IVR ist ein Interactive Voice Response-Bot.
- Mensch ist eine Person.
- CB Teilnehmer:in: Gruppieren Sie Daten nach der Art des Teilnehmer:in. Mögliche Werte sind:
- Agent ist ein Unternehmensvertreter oder ein Chatbot.
- Mandant ist ein Kunde.
- type_unknown ist ein Teilnehmer:in, der nicht als Agent oder Mandant identifiziert wurde.
- VB Satzdauer: Daten nach der Dauer eines Satzes in einem Aufruf in Millisekunden gruppieren.
- VB Satzanfangszeit: Gruppieren Sie Daten nach dem Zeitstempel des Satzanfangs. Bei Anrufen ist dies die Zeit in Millisekunden seit dem hörbaren Anfang des ersten Wortes im ersten Satz. Bei Chats ist dies die Zeit in Millisekunden seit dem Senden der ersten Nachricht. Tipp: Die Startzeit der ersten Chat-Nachricht ist für dieses Attribut immer 0 ms.

- CB Total Dead Air: Daten in einem Aufruf in Millisekunden nach toter Luft gruppieren. Bei Anrufen ist tote Luft eine lange Pause zwischen den Lautsprechern.
- CB Total Hesitation: Gruppieren Sie Daten nach der Gesamtzahl der Zögerlichkeiten (Agent und Client) in einem Anruf in Millisekunden. Bei Anrufen ist Zögern eine lange Pause durch einen Redner.
- VB Summe Overtalk: Gruppieren Sie Daten nach der akkumulierten Länge überlappender Sätze in einem Aufruf in Millisekunden. In Anrufen ist Overtalk jede Zeit, wenn 2 oder mehr Sprecher gleichzeitig sprechen und sich die Zeitstempel ihrer Sätze überschneiden.
- CB Total Silence: Gruppieren Sie Daten nach der akkumulierten Länge aller Silences größer oder gleich 2 Sekunden zwischen Sätzen für alle Teilnehmer in einem Aufruf in Millisekunden.
Zeit
Auswahl Zeit Mit können Sie Daten nach Zeiträumen gruppieren. Sie können Attribut verwenden, um einen Trendbericht anzulegen, mit dem Sie anzeigen können, wie sich Ihre Berechnungen und Metriken im Laufe der Zeit ändern.
Attribute
Auswahl Attribute Mit können Sie Daten nach den Werten eines ausgewählten strukturierten Attribut gruppieren. Ein strukturiertes Attribut ist jedes numerische Feld oder String-Feld in einem Datensatz, bei dem es sich nicht um das tatsächliche textuelle Feedback handelt. Strukturierte Attribute enthalten in der Regel diskrete Daten mit einem hohen Organisation (z.B. Alter einer Person oder Name des Produkts, das sie verwenden). Die für die Gruppierung verfügbaren Attribute hängen von der Feedback ab und variieren in der Regel von Datenset zu Datenset.
Beispiel: Ich kann nach dem Attribut „Agent“ gruppieren, um Gruppierungen von Interaktionen der verschiedenen Agents anzuzeigen, die die Interaktion bearbeitet haben.
Kennzahlen
Auswahl Metriken Mit können Sie Daten nach diskreten Werten oder Bändern bestimmter Standardberechnungen und abgeleiteter Metriken gruppieren. Mit anderen Worten, Sie können Daten nach einer Metrik organisieren und nach einer anderen Metrik messen. Folgende Gruppierungen stehen zur Verfügung:
- Stimmung (3 Bands): Gruppieren Sie Daten nach 3 Stimmung (Negativ, Neutral, Positiv). Siehe Gruppierung nach Stimmung für weitere Informationen.
- Stimmung (5 Bands): Gruppieren Sie Daten nach 5 Stimmung (Stark negativ, Negativ, Neutral, Positiv, Stark positiv). Siehe Gruppierung nach Stimmung für weitere Informationen.
- Aufwand (3 Bänder): Gruppieren Sie Daten nach 3 Aufwandsbändern (Hart, Neutral, Einfach). Bei der Gruppierung nach Aufwand werden Nullwerte standardmäßig eingeschlossen.
- Aufwand (5 Bänder): Gruppieren Sie Daten nach 5 Aufwandsbändern (Sehr hart, Hart, Neutral, Einfach, Sehr einfach). Bei der Gruppierung nach Aufwand werden Nullwerte standardmäßig eingeschlossen.
- Emotionale Intensität: Gruppieren Sie Daten nach 3 emotionalen Intensitätsbändern (Niedrig, Mittel, Hoch).
- CB-Dokument – Word-Anzahl: Gruppieren Sie Daten nach der Anzahl der Wörter in einem Dokument.
- CB-Loyalty-Beschäftigungsdauer: Gruppieren Sie Daten nach der Länge der Kundentreue (in Jahren).
- CB Satzquartil: Gruppieren Sie Daten nach dem Quartal des Wortlauts, in das ein Satz fällt (1, 2, 3 oder 4). Dies kann Ihnen dabei helfen zu verstehen, welche Themen an welchen Stellen im Gespräch besprochen werden.
- CB Satzwortanzahl: Daten nach der Anzahl der Wörter in einem Satz gruppieren.
Darüber hinaus können Sie eigene Top-Box, Bottom-Box und Zufriedenheitskennzahlen nach denen Sie Daten gruppieren können. Auf diese Weise können Sie ermitteln, ob Feedback von einem Promotor, Detraktor oder neutralen Kunden stammt. Folgende Gruppierungen stehen zur Verfügung:
- Oberes Feld: Gruppieren Sie Daten nach Top-Box-Bändern (Promotoren und andere).
- Unteres Feld: Daten nach Bottom-Box-Bändern (Kritiker und andere) gruppieren.
- Zufriedenheit: Gruppendaten nach Zufriedenheitsbändern (Kritiker, Neutrale, Promotoren).
Treiber
Tipp: Sie können Treiber nur in verwenden. Streudiagramm.
Auswahl Treiber ermöglicht das Gruppieren von Daten nach Treiber Sie in Ihrem Benutzerkonto erstellen. Sie können diese Treiber verwenden, um Attribute und Themen zu finden, die zu einem bestimmten Ergebnis führen.
Organisationshierarchie
Gruppierungskosten
Wenn Sie Berichte mit mehreren Gruppierungen ausführen, erhalten Sie unter Umständen die folgende Fehlermeldung:
„Hoppla! Wir übernehmen für jede Gruppierung geschätzte Kosten an, und die Summe der Kosten darf das Leitplanbudget von [10,5] nicht überschreiten. (Gruppierungen mit hoher Kardinalität kosten mehr.) Entfernen Sie verschiedene Gruppierungen basierend auf den unten aufgeführten Kosten, oder wählen Sie sie aus, um sicherzustellen, dass das Widget über Gesamtkosten im Budget verfügt: [Liste der Gruppierungen und ihre Kosten] Aktuelle Gesamtkosten: [Summe aller Kosten]“
Die Kosten jeder Gruppierung hängen von der Anzahl der eindeutigen Werte in der Gruppe ab (diese Kennzahl wird als Kardinalität bezeichnet). Standardmäßig geben die meisten Widgets die Top-10-Artikel nach Volumen zurück. Wenn insgesamt 100 Positionen vorhanden sind, ist diese Berechnung in der Regel sehr schnell. Wenn 1.000.000 Positionen vorhanden sind, dauert es länger, zu berechnen, welche davon die Top 10 sind. Im Allgemeinen Ergebnisse die Verwendung eindeutigerer Elemente zu einer kostspieligeren Berechnung in Bezug auf die leistung. Diese Kosten können sich bei Widgets, die mehrere Datenebenen zurückgeben, schnell vervielfachen und dazu führen, dass die oben genannte Fehlermeldung angezeigt wird.
Wenn Sie bei der Verwendung von Gruppierungen in einem Bericht den oben genannten Fehler erhalten, müssen Sie eine oder mehrere der aufgeführten Gruppierungen entfernen, damit deren Gesamtkosten das Budget nicht überschreiten. Die Fehlermeldung zeigt die geschätzten Kosten für jede Gruppierung an, damit Sie entscheiden können, welche Gruppierung entfernt werden soll.
Großartig! Vielen Dank für die Rückmeldung!
Vielen Dank für die Rückmeldung!