Datensätze ohne Text (Discover)
Was finden Sie hier?
Informationen zu Datensätzen ohne Text (Discover)
Feedback, insbesondere Umfrage, kann häufig Datensätze ohne Text enthalten (auch leere ausführliche Felder genannt). Sie können wählen, ob leere Datensätze in XM Discover einbezogen werden sollen.
Dieses Datenset enthält beispielsweise einige leere Zellen:
| Datensatz-ID | Standort | Positives Feedback | Negatives Feedback |
|---|---|---|---|
| 1 | Provo | Das Hotel war überraschend ruhig. (Stimmung = 3) | Das Zimmer war sehr klein und riechte moldy. (Stimmung = –2,25) |
| 2 | Provo | ||
| 3 | Dublin | Das Hotel ist sehr schön eingerichtet und geräumig. (Stimmung = 2,5) |
Leere Versionen herausfiltern
Sie können einfach filtern, um Ergebnisse ohne Text und andere Inhalte mit geringem Wert auszuschließen, z.B. extrem kurze Antworten und Antworten, die Anzeigen und anderen Spam enthalten.
Nach bestimmten Versionen filtern
Um Dokumente herauszufiltern, bei denen nur das spezifische Wort leer ist, legen Sie einen Filter mit der spezifischen ausführlichen Bedingung und dem Operator „hat einen beliebigen Wert“ an.
Beispiel: Wir möchten jede Antwort sehen, bei der die Überprüfen Attribut wurde ausgefüllt.

Nach „N/A“ und anderen derartigen Antworten
Anstatt einen Datensatz leer zu lassen, hinterlassen die Umfrageteilnehmer manchmal Feedback wie „Keine Antwort“, „Nicht zutreffend“, „Nichts“ usw. Um diese Dokumente herauszufiltern, wählen Sie Ihre spezifische ausführliche Beschreibung aus, verwenden Sie den Operator „ist nicht“, und geben Sie dann den spezifischen Inhalt ein, den Sie ausschließen möchten.

Nach Wortanzahl filtern
Sie können Dokumente unterhalb einer bestimmten Wortanzahl ausschließen. Verwenden Sie die CB-Dokument – Word-Anzahl Attribut setzen Sie es auf „größer oder gleich“ die von Ihnen gewählte Mindestwortanzahl.

Nach Inhaltstyp filtern
Die CB-Inhaltstyp Filter erkennt verbatim, die weniger nützliche Informationen enthalten, wie Anzeigen, Coupons und Artikel-Links. Setzen Sie den Operator auf „ist nicht“ und den Wert auf „inhaltlich“.

Datensätze ohne ausführlichen Text filtern
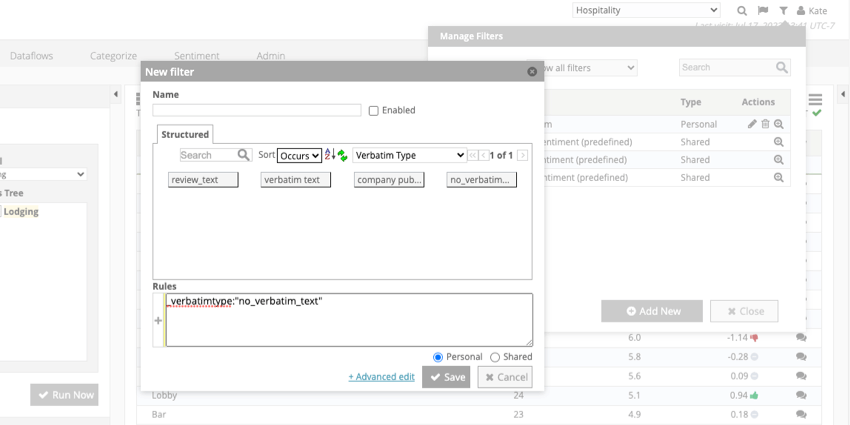
Datensätze, bei denen jede einzelne Spalte leer ist, werden mit dem ausführlichen Typ “no_verbatim_text” gekennzeichnet.
Beispiel: Betrachtet man unsere obige Tabelle, würde nur Satz 2 mit „no_verbatim_text“ gekennzeichnet.
In beiden Studio und Designerkönnen Sie filtern, um nur leere Datensätze einzuschließen oder um alle leeren Datensätze auszuschließen. Wählen Sie dazu Ausführlicher Typ und setzen Sie ihn auf “no_verbatim_text”.
Beispiel: So sieht dieser Filter in Studio aus:
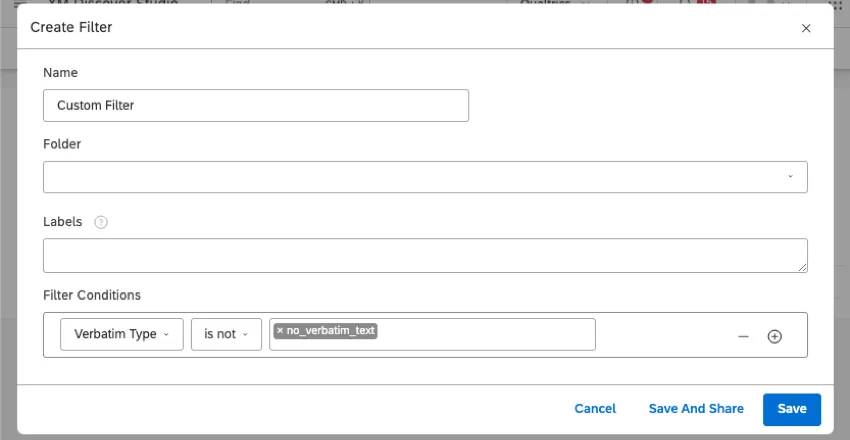
So sieht dieser Filter im Designer aus:
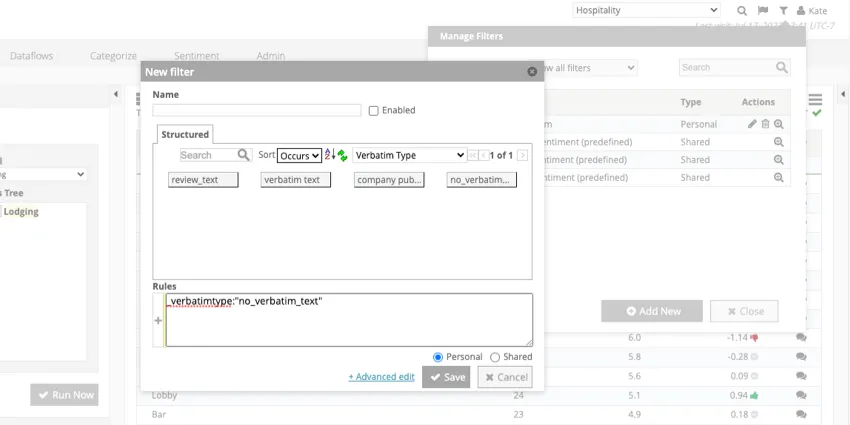
Achtung: Ausführliche Filter entfernen die gesamte Interaktion aus Ihren Ergebnisse.
Platzhaltertext für leere Sätze
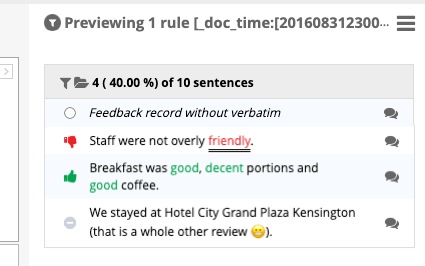
Wann Anzeigen einer Vorschau von Sätzen in Designer Datensätze mit leerem Wortlaut werden mit dem folgenden Text angezeigt: “Feedback ohne ausführliche Angabe”.

Tipp: Wenn Sätze leer sind, haben sie kein Stimmung, wie oben gezeigt.
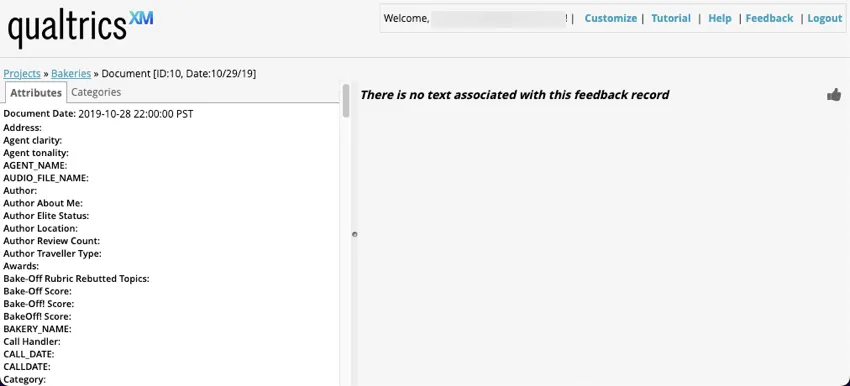
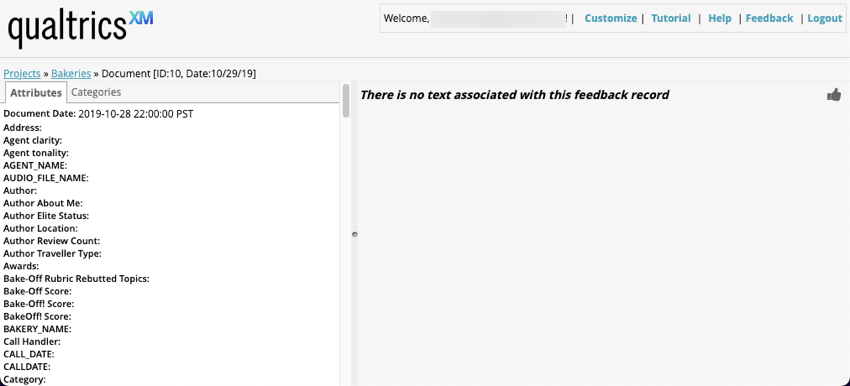
Beim Anzeigen leerer Datensätze in Hervorhebungszeichen für Quelle oder Dokument-Explorerlautet der Text: „Mit diesem Feedback ist kein Text verknüpft.“
Auswirkung auf Volumen
In Studio können Sie über das Volumen berichten, d. h. die Anzahl der Datensätze, die einer bestimmten Metrik oder einem bestimmten Filter entsprechen. Im Folgenden finden Sie einige Regeln, die in Bezug auf Volumen und leere Datensätze zu beachten sind:
- Das Volumen umfasst Datensätze mit leeren verbatim, außer wenn Sie Berichte zu Wörter und Assoziierte Wörter.
- Bei der Berichterstellung zu Attributen werden immer leere Begriffe berücksichtigt.
- Bei der Auswertung von Attributen und der Auflösung von Ergebnisse durch ein Kategorienmodell werden relevante leere Datensätze berücksichtigt, auch wenn dieses Kategoriemodell nicht so konfiguriert ist, dass Datensätze ohne Text enthalten sind.
Beispiel: In unserer Tabelle werden beide Datensätze 1 und 2 bei der Berechnung des Volumens für das Attribut berücksichtigt.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Auswirkung auf Stimmung
Die Stimmung enthält keine Datensätze mit leerer ausführlicher Angabe.
Beispiel: In unserer Tabelle wird bei der Berechnung der Stimmung für das Attribut Provo nur Datensatz 1 berücksichtigt. Datensatz 2 wird bei der Stimmung ignoriert.
Auswirkungen auf die Klassifizierung
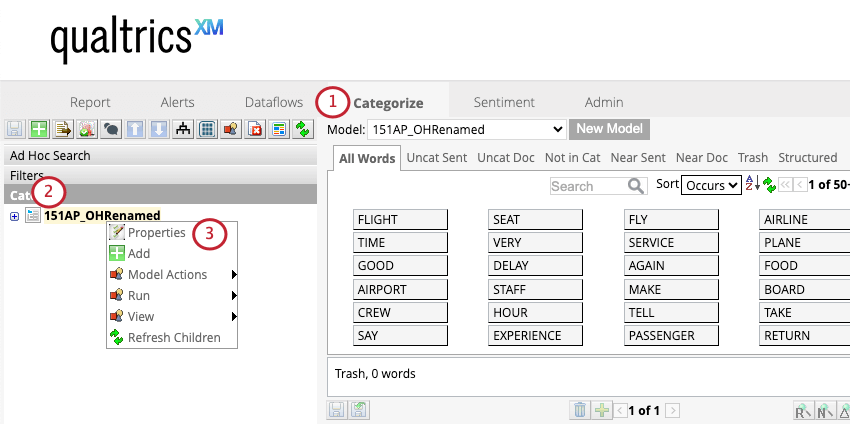
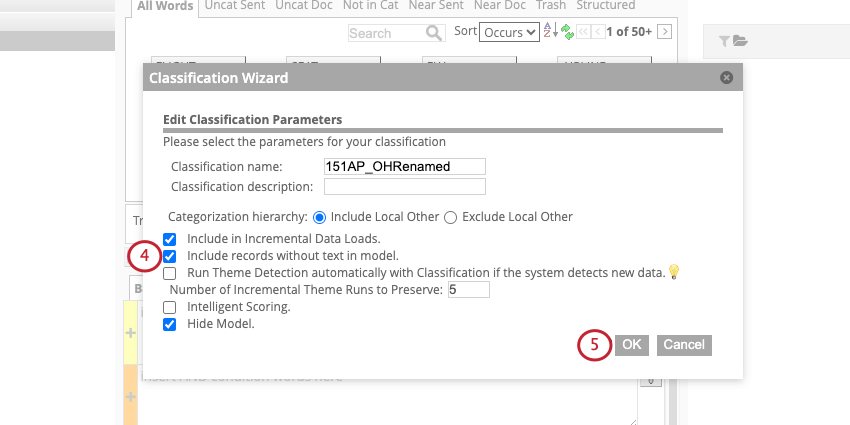
Wenn Sie laufende Klassifizierungkönnen Sie wählen, ob leere Datensätze in Ihr Kategoriemodell aufgenommen werden sollen.
So nehmen Sie leere Datensätze in eine Klassifizierung auf:
Auswirkungen auf die Projektstatistik
Im Designer werden Projektstatistiken zum Datenflüsse verhalten sich wie folgt:
- Dokumente: Anzahl umfasst alle Datensätze, einschließlich der mit leerem Verbalopfer.
- Verbatim: Anzahl tut nicht Datensätze mit leerem Wort einschließen.
- Sätze: Anzahl tut nicht Datensätze mit leerem Wort einschließen.
Großartig! Vielen Dank für die Rückmeldung!
Vielen Dank für die Rückmeldung!