-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Datenlader (Designer)
Informationen zum Datenlader
Der Datenlader wird verwendet, um Daten über einen API in Ihre Projekte in XM Discover zu importieren. Um auf den Datenlader zuzugreifen, gehen Sie zu Admin wählen Sie Ihr Projekt aus, und wechseln Sie dann zur Datenlader Registerkarte.
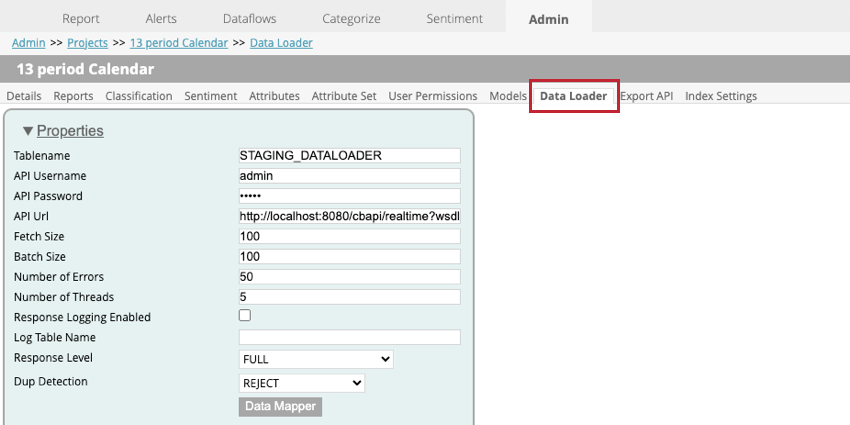
Datenlader-Einstellungen
Die folgenden Einstellungen stehen beim Einrichten des Datenladers innerhalb eines Projekts zur Verfügung:
- Tabellenname: Geben Sie den Namen der Staging-Tabelle ein, die die in XM Discover zu importierenden Daten enthält.
- API: Geben Sie den Benutzernamen für den API ein, der den API ausführen kann.
- API. Geben Sie den Benutzernamen für den API ein.
API : Geben Sie die URL für den API ein, der zum Abrufen der Daten verwendet wird.- Abrufgröße: Geben Sie die Anzahl der Zeilen an, die importiert werden sollen.
- Batch-Größe: Geben Sie die Anzahl der Zeilen an, die in einem Batch importiert werden sollen. Wenn Ihre Batch-Größe größer als Ihre Abrufgröße ist, werden mehrere Aufrufe ausgeführt, bis alle Daten importiert wurden.
- Anzahl Fehler: Wenn Ihr Import aufgrund von Fehlern fehlschlägt, können Sie angeben, wie oft der Aufruf wiederholt wird.
- Anzahl der Threads: Geben Sie die maximale Anzahl der Threads ein, die auf einer einzelnen Transformatorinstanz ausgeführt werden sollen.
- Antwortprotokollierung aktiviert: Wenn diese Option aktiviert ist, können Sie ein Protokoll der Ergebnisse anlegen.
- Protokolltabellenname: Wenn Sie Ihre Ergebnisse protokollieren, wird eine neue Tabelle für Sie angelegt. Geben Sie in diesem Feld einen Namen für die Tabelle ein.
Tipp: Sie müssen für dieses Feld nur dann etwas angeben, wenn Antwortprotokollierung aktiviert ist ausgewählt.
- Ebene: Diese Option sollte auf gesetzt werden NUR SICHERN.
- Auffälligkeitserkennung: Wählen Sie aus, wie Duplikate behandelt werden. Folgende Optionen sind verfügbar:
- KEINE: Duplikate werden importiert.
- ABLEHNEN: Duplikate werden abgelehnt.
- ATTRIBUTE AKTUALISIEREN: Bei Duplikaten werden nur strukturierte Attribute aktualisiert.
- Daten-Mapper: Der Datenmapper wird verwendet, um auszuwählen, welche Felder aus der Staging-Tabelle extrahiert werden, die in XM Discover verwendet werden sollen. Weitere Informationen finden Sie unten im Unterabschnitt Daten-Mapper.
Datenmapper
Der Datenmapper wird verwendet, um Daten aus Ihrer Staging-Tabelle für die Verwendung in XM Discover zu extrahieren. Der Datenmapper enthält nur Felder, die sich in Ihrer Staging-Tabelle befinden.
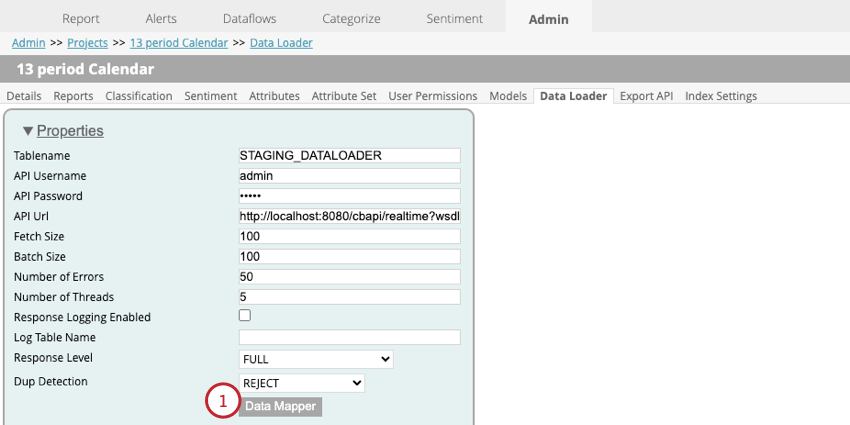
- Klicken Sie in Ihren Datenlader-Einstellungen auf Daten-Mapper.
- Wählen Sie das Feld aus, das die Datenquelle angibt.
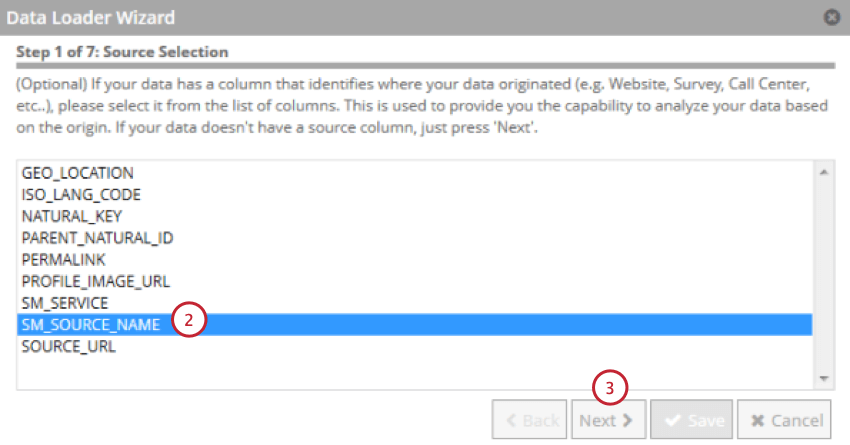
- Klicken Sie auf Weiter.
- Wählen Sie das Feld aus, das als natürlicher Schlüssel verwendet werden soll, und klicken Sie dann auf den Pfeil nach rechts ( > ). Sie können mehrere Felder auswählen, und der natürliche Schlüssel ist eine Verkettung der Felder in der Reihenfolge, in der Sie sie ausgewählt haben.
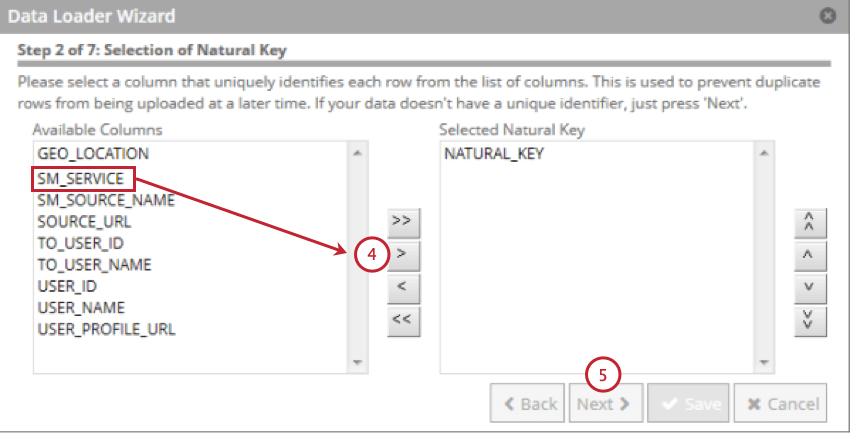 Tipp: Felder, die länger als 256 Zeichen sind, werden ausgeschlossen. Natürliche Schlüssel werden auf 256 Zeichen gekürzt.
Tipp: Felder, die länger als 256 Zeichen sind, werden ausgeschlossen. Natürliche Schlüssel werden auf 256 Zeichen gekürzt. - Klicken Sie auf Weiter.
- Wählen Sie das Feld aus, das Kundenberichte enthält, und klicken Sie dann auf den nach rechts zeigenden Pfeil ( > ).
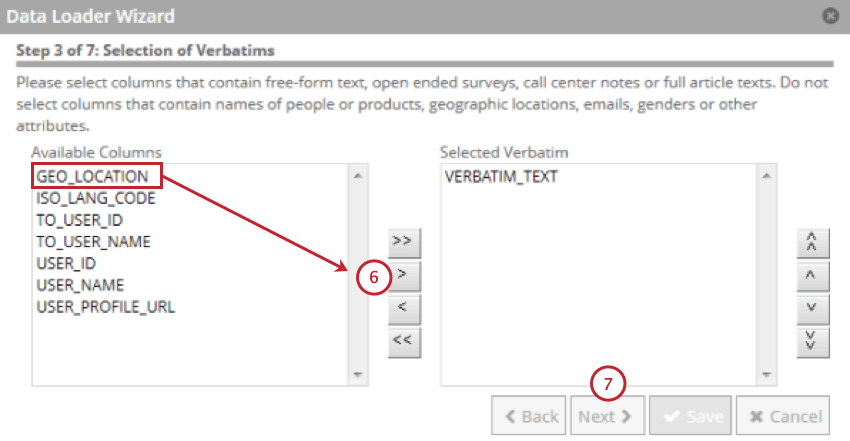
- Klicken Sie auf Weiter.
- Wählen Sie die Felder aus, die Ihre strukturierten Attribute enthalten, und klicken Sie dann auf den nach rechts zeigenden Pfeil ( > ). Sie können bis zu 500 strukturierte Attribute auswählen.
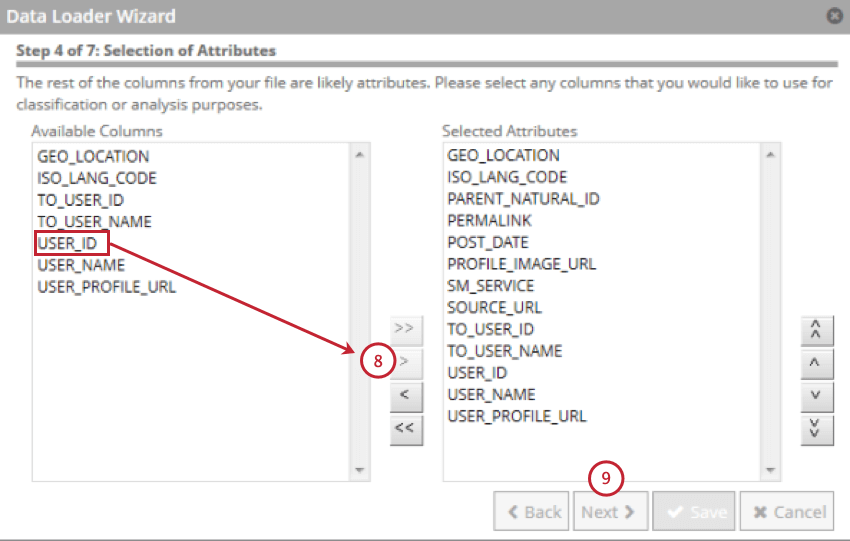
- Klicken Sie auf Weiter.
- Überprüfen Sie Ihre Attribute, und nehmen Sie bei Bedarf Änderungen vor. Sie können den Anzeigename, den Typ und die Reporting-Verfügbarkeit des Attribut ändern und angeben, ob es sich bei dem Feld um eine E-Mail handelt.
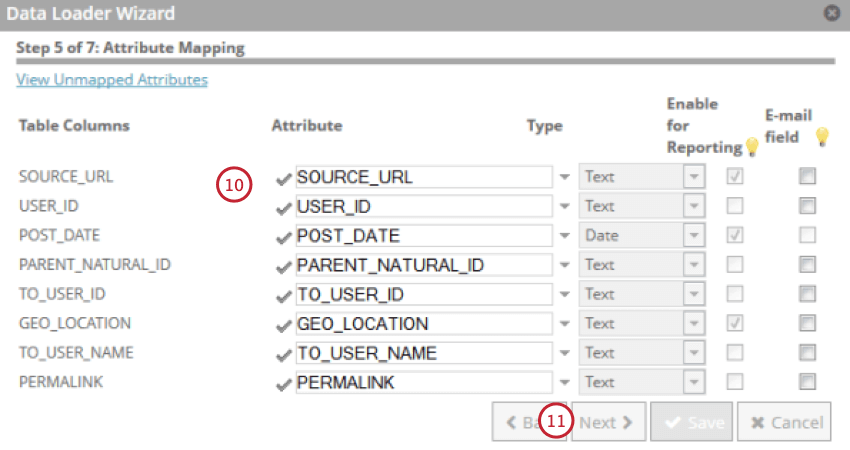
- Klicken Sie auf Weiter.
- Wählen Sie das Feld aus, das das Datum enthält, an dem der Beleg angelegt wurde. Dies wird als Aufzeichnungsdatum in XM Discover verwendet.
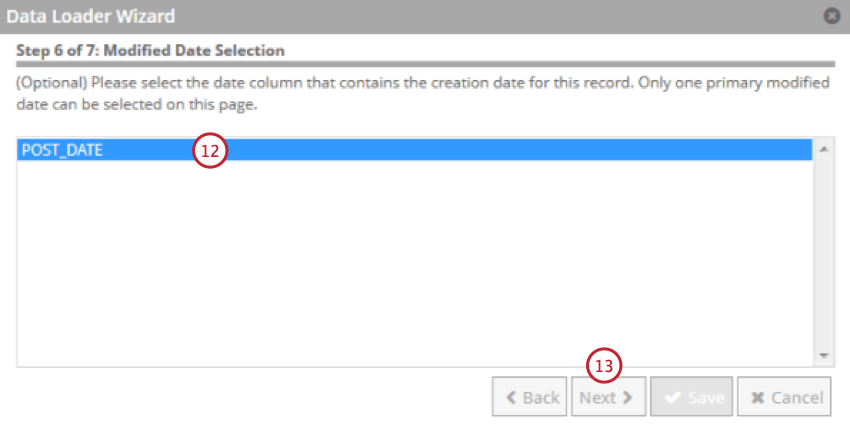
- Klicken Sie auf Weiter.
- Wählen Sie das Feld aus, das die Sprache des Dokuments enthält.
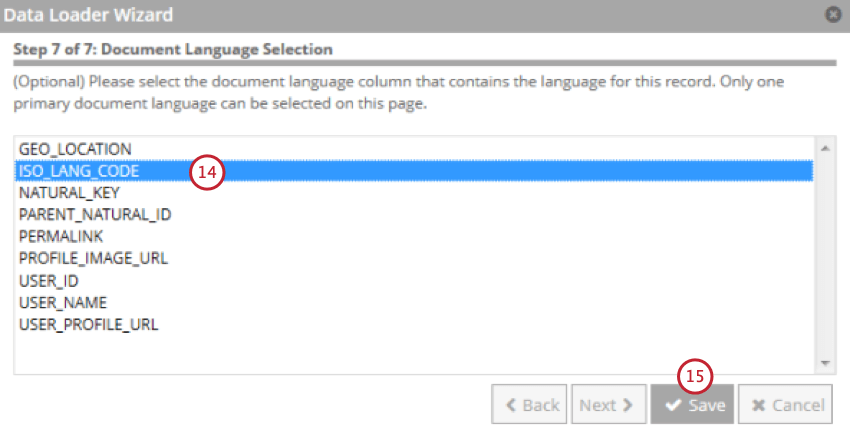
- Klicken Sie auf Speichern.
Importieren von Daten mit dem Datenlader
Nachdem Daten über den Datenlader in eine Staging-Tabelle geladen wurden, können Sie diese Daten zur Verwendung in XM Discover verarbeiten. In diesem Abschnitt wird erläutert, wie Sie einen automatisierten Datenladeprozess einrichten, damit Ihre Daten auf dem neuesten Stand gehalten werden.
- Wechseln Sie zum Datenflüsse Registerkarte.
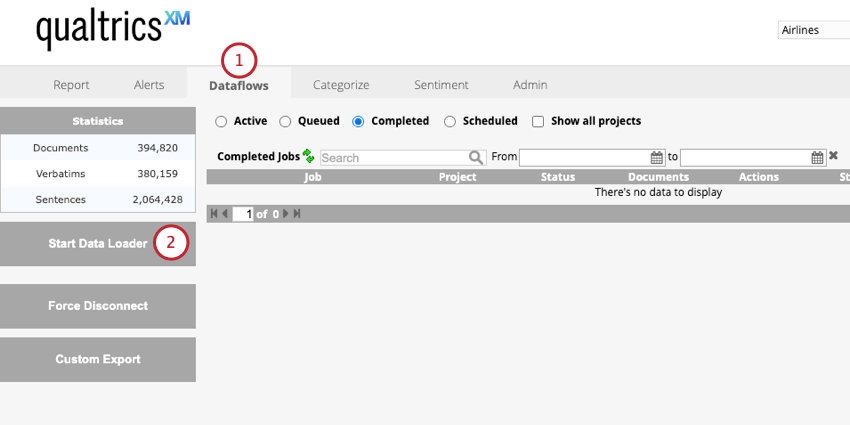
- Klicken Sie auf Datenlader starten.
- Navigieren Sie zum Eingeplant Abschnitt von Datenflüssen.
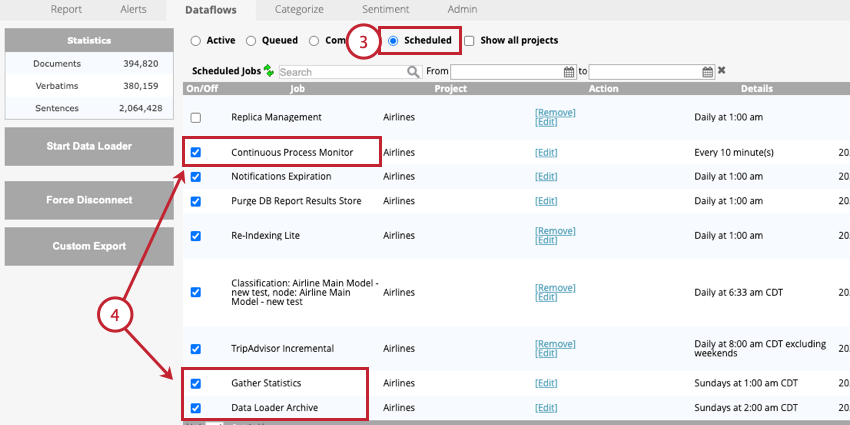
- Aktivieren Sie die folgenden Jobs:
- Kontinuierlicher Prozessmonitor: Dieser Job ist erforderlich. Dieser Datenfluss führt regelmäßig die Downstream-Echtzeit aus, um die Datenverarbeitung abzuschließen.
- Datenlader-Archiv: Dieser Job ist optional, wird jedoch dringend empfohlen. Dieser Datenfluss archiviert Datensätze, die vom Datenlader verarbeitet werden. Sie sollten die Häufigkeit dieses Jobs entsprechend Ihrer Datenladerhäufigkeit aktualisieren.
- Statistiken sammeln: Dieser Job ist optional. Wir empfehlen, diesen Job einmal pro Woche auszuführen. Dieser Datenfluss aktualisiert die folgenden Projektstatistiken:
- Die Gesamtanzahl der Dokumente, Verfassungen und Sätze, die auf der Registerkarte Datenflüsse angezeigt werden.
- Die Gesamtzahl der Vorkommen von Wörtern, die auf der Registerkarte Stimmung angezeigt werden.
Datenlader-Optionen
Nachdem der Datenlader gestartet wurde, können Sie den Job mit den folgenden Optionen verwalten: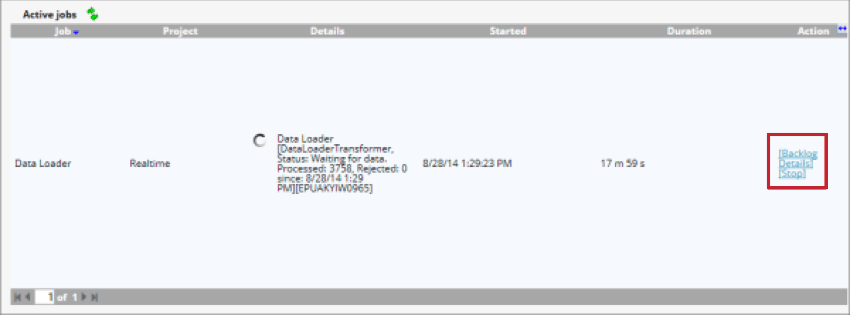
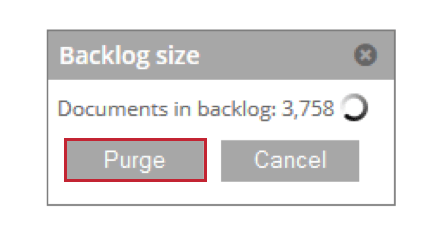
- Rückstand: Zeigt die Anzahl der Belege an, die auf die Verarbeitung warten. Sie können auf Bereinigen um diese Belege aus der Staging-Tabelle zu entfernen.
- Details: Zeigen Sie Details zu Dokumenten an, die aufgrund von Duplizierungseinstellungen übersprungen wurden.
- Stopp: Stoppen Sie die Verarbeitung von Daten mit dem Datenlader.
Projektdaten löschen
Sie können die Daten in Ihrem Projekt löschen. Dazu gehören verbatim und strukturierte Attribut. Beim Löschen von Projektdaten können Sie alle Daten löschen, die während einer bestimmten Sitzung hochgeladen wurden, oder alle Daten im Projekt löschen.
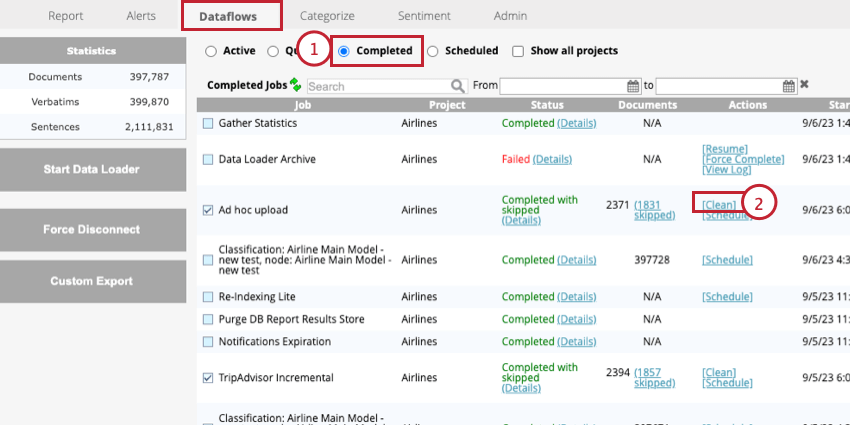
- Wechseln Sie zum Abgeschlossen Abschnitt des Datenflüsse Registerkarte.
- Klicken Sie auf Bereinigen weiter dem Ad-hoc-Upload Job.
Dadurch werden alle Daten gelöscht, die während des ausgewählten Uploads hinzugefügt wurden.