-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Attribute – Allgemeine Übersicht
Informationen zu Attributen – Allgemeine Übersicht
An Attribut ist eine Eigenschaft eines Dokuments, das es in irgendeiner Weise charakterisiert. Typische Beispiele für Attribute sind der Name des Autors und Erstellungsdatum.
Sie können benutzerdefinierte Attribute für Ihre Projekte. Es gibt auch eine Vielzahl von Systemattribute die Sie verwenden können. Sie können auch intelligente Entitäten einrichten, die Attribute basierend auf dem Text des Dokuments automatisch ermitteln (z.B. wenn eine Instanz oder ein Produkt im Feedback eines Kunden erwähnt wird).
Nachdem Sie Attribute hinzugefügt haben, können Sie zusätzliche abgeleitete Attribute um Ihre Daten besser zu verstehen. Sie können Ihre Attribute auch in Attribut organisieren, was die Berichterstellung für diese Attribute erleichtert.
Attribut
Folgende Feldtypen werden für Attribute unterstützt:
- Text
- Zahl
- Datum
Zugriff auf Attribute
Attribute werden auf Ebene verwaltet. So greifen Sie auf die Attribute für ein Projekt zu:
- Navigieren Sie im Designer zu Admin und suchen Sie das Projekt, an dem Sie interessiert sind.
- Klicken Sie auf das Symbol Attribute in der Spalte Aktionen.
Dadurch wird die Attributtabelle geöffnet, die die folgenden Informationen zu jedem Attribut im Projekt enthält: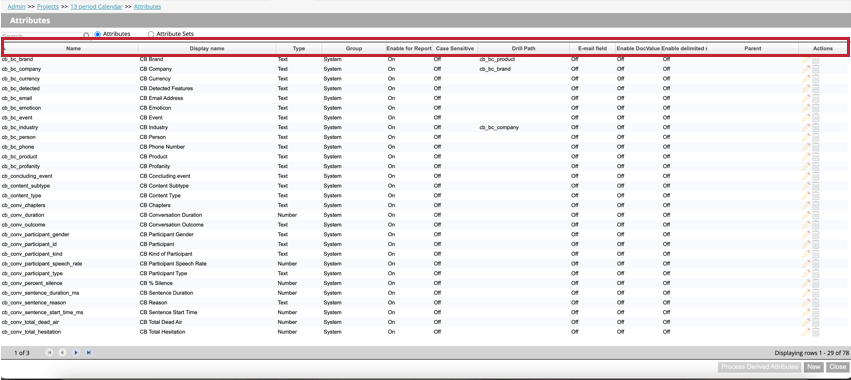
- Bezeichnung: Der Systemname des Attribut. Siehe Attribut für Namensanforderungen.
- Anzeigename: Der Anzeigename des Attribut, der in Berichten, Filtern usw. angezeigt wird. Siehe Attribut für Namensanforderungen.
- Typ: Typ des Attribut. Für Standardattribute können die Werte Text, Zahl oder Datum sein. Für abgeleitete Attribute können die Werte Dimensionaler Lookup, Bereichs-Rollup, Zufriedenheitswert oder Aus Kategorie abgeleitet sein.
- Gruppe: Die Gruppe des Attribut, die seinen Ursprung und Verwendungszweck darstellt. Es gibt folgende Werte:
- Kategorie abgeleitet: Attribute, die aus Modellen oder Kategorien abgeleitet wurden.
- System: Systemattribute.
- Kundendefiniert: Alle benutzerdefinierten Attribute, die aus der Datenquelle Ihrer Antwortmöglichkeit verfügbar sind (einschließlich dimensionaler Lookups, Bereichs-Rollups und Zufriedenheits-Scores).
- Punktekarte: Attribute, die im intelligenten Punktewertung verwendet werden.
- Für Reporting aktivieren: Zeigt an, ob ein Attribut für die Berichterstellung aktiviert ist (Ein) oder nicht (Aus).
- Groß-/Kleinschreibung beachten: Zeigt an, ob bei Attribut Anzeige von Werten im Dokument-Explorer, im Quellen-Highlighter, im benutzerdefinierten Export und beim Export der Satzvorschau die Groß-/Kleinschreibung berücksichtigt wird.
- Drill-Pfad: Zeigt den benutzerdefinierten Drill-Pfad an, wenn er definiert wurde. Wenn kein benutzerdefinierter Drill-Pfad vorhanden ist, ist dieses Feld leer.
- E-Mail-Feld: Zeigt an, ob ein Attribut eine E-Mail-Adresse enthält.
- DocValue aktivieren: Zeigt an, ob doc für dieses Attribut verwendet werden.
- Begrenzte Mehrfachwerte aktivieren: Zeigt an, ob für dieses Attribut mehrere Werte aktiviert sind.
- Übergeordnet: Wenn das Attribut ein abgeleitetes Attribut ist, zeigt dieses Feld „übergeordnetes Attribut“ an. Dieses Feld ist für benutzerdefinierte Attribute und Standardattribute leer.
- Aktionen: Führen Sie die folgenden Aktionen für das Attribut:
- Attribut bearbeiten
- Abgeleitetes Attribut anlegen
- Attribut löschen
Attribut verwalten
Verwenden Sie die Attribut Schalten Sie oben auf der Seite um, um Ihre Attribut anzuzeigen. Auf diese Weise können Sie neue Attribut anlegen und vorhandene Attributgruppen löschen. Auswählen Attribute um Ihre individuellen Attribute anzuzeigen. 
Systemattribute
Es gibt eine Reihe von Systemattributen, z.B. Dokumentdatum und Quell-ID, die automatisch auf jedes Dokument angewendet werden, das in XM Discover hochgeladen wird. Mit diesen Attributen können Sie Feedback in XM Discover verwalten und mit XM anreichern, die von der NLP-Engine abgeleitet werden.
Nachfolgend finden Sie eine Tabelle der verschiedenen Systemattribute, gruppiert nach den verschiedenen Kategorien von Attributen. Diese Tabelle enthält zu jedem Attribut folgende Informationen:
- Bezeichnung: Der Attribut, der in Berichten, Filtern usw. angezeigt wird.
- Systemname: Der Systemname des Attribut, den Sie zum Abfragen oder Filtern Ihrer Daten verwenden.
- Typ: Der Attribut.
- Beschreibung: Eine kurze Beschreibung der Bedeutung und des Zwecks des Attribut.
Granularität : Die Ebene verknüpfte Datengranularitätsebene. Beispielsweise ist die Satzwortanzahl nur auf Ebene relevant, während das Dokumentdatum sowohl für ein Dokument als auch für jeden Satz in diesem Dokument verfügbar ist.
IDs und Referenzen
| Name | Systemname | Typ | Beschreibung | Granularität |
| Dokument-ID | _id_document | Nummer | Die eindeutige System-ID des Dokuments. Im Gegensatz zur natürlichen ID wird die Dokument-ID automatisch von XM Discover generiert. | Dokument und Satz |
| Natürliche ID | natural_id | Text | Die eindeutige natürliche ID des Dokuments. Im Gegensatz zur Dokument-ID wird die natürliche ID aus den Feldern generiert, die beim Hochladen eines Dokuments angegeben wurden. Die natürliche ID wird von der duplizieren verwendet und kann auch nützlich sein, wenn das Dokument außerhalb von XM Discover auf seine Quelle verfolgt wird. | Dokument und Satz |
| Satz-ID | _id_Satz | Nummer | Die eindeutige ID des Satzes. Diese ID wird automatisch generiert.
|
Satz |
| Sitzungs-ID | _id_batch | Nummer | Die eindeutige ID der Upload-Sitzung, während der das Dokument in XM Discover geladen wurde. Diese ID wird automatisch generiert. | Dokument und Satz |
| Quell-ID | _id_source | Text | Der Name der Datenquelle. Abhängig von der Datenquelle kann sie entweder automatisch oder aus den Feldern generiert werden, die beim Hochladen des Dokuments angegeben wurden. | Dokument und Satz |
| Verbatim ID | _id_verbatim | Nummer | Die eindeutige ID des ausführlichen Begriffs. Diese ID wird automatisch generiert. | Wortlaut und Satz |
| Ausführlicher Typ | _verbatimtype | Text | Der Name des ausführlichen Feldes. Mit diesem Attribut können Sie Sätze nach verschiedenen ausführlichen Feldern in Ihren Daten unterscheiden. | Wortlaut und Satz |
Datum und Uhrzeit
| Name | Systemname | Typ | Beschreibung | Granularität |
| Erstellungsdatum VB | cb_date_created_utc | Datum, Epochenzeit in Millisekunden | Das Datum, an dem das Dokument zu XM Discover hinzugefügt wurde. Dieses Datum wird automatisch generiert. | Dokument und Satz |
| VB-Aktualisierungsdatum | cb_date_updated | Datum, Epochenzeit in Millisekunden | Das Datum, an dem das Dokument zuletzt aktualisiert wurde. Aktualisierungen enthalten keine Kategorisierungsänderungen. Dieses Datum wird automatisch generiert. | Dokument |
| Belegdatum | _doc_time | Datum, ISO 8601 in Sekunden | Das primäre Datum des Belegs. Das Belegdatum wird in Berichten, Trendberichten, Alerts usw. verwendet. Dieses Datum wird aus den beim Hochladen des Dokuments angegebenen Feldern generiert. | Dokument und Satz |
| Belegdatum ohne Uhrzeit | _doc_date | Datum, Format JJJJ-MM-TT | Das Datum des Belegs ohne Zeitstempel.
Dieses Datum wird aus den beim Hochladen des Dokuments angegebenen Feldern generiert. |
Dokument und Satz |
| Tageszeit | time_of_day | Text, Format hh:mm | Die Uhrzeit des Belegs, auf die Stunde heruntergerollt. Beispielsweise werden Kommentare, die um 9:09 und 9:59 Uhr veröffentlicht wurden, beide auf 9:00 Uhr hochsummiert. Dieses Attribut wird automatisch generiert. | Dokument und Satz |
Wortanzahl und -position
| Name | Systemname | Typ | Beschreibung | Granularität |
| CB-Dokument – Word-Anzahl | cb_document_word_count | Nummer | Die Anzahl der Wörter in einem Dokument. Die Dokumentwortanzahl ist eine Summe aller Satzwortanzahlen.
|
Dokument und Satz |
| CB Satzquartil | cb_sentence_quartile | Nummer | Der Teil des Wortlauts, in den ein Satz fällt. Dieses Attribut kann einen der folgenden Werte haben: 1, 2, 3 oder 4. Jeder Abschnitt entspricht 25 % der gesamten ausführlichen Länge. | Satz |
| CB Satzwortanzahl | cb_sentence_word_count | Nummer | Die Anzahl der Wörter in einem Satz. | Satz |