-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Twitter-Eingangskonnektor
Informationen zum eingehenden Twitter-Konnektor
Sie können den eingehenden Twitter-Konnektor verwenden, um öffentliche Tweets und Erwähnungen von Twitter in XM Discover zu laden.
Twitter-Eingangsjob einrichten
Tipp: Die App „Jobs verwalten“ Berechtigung ist erforderlich, um diese Funktion verwenden zu können.
- Klicken Sie auf der Seite Jobs auf Neuer Job.
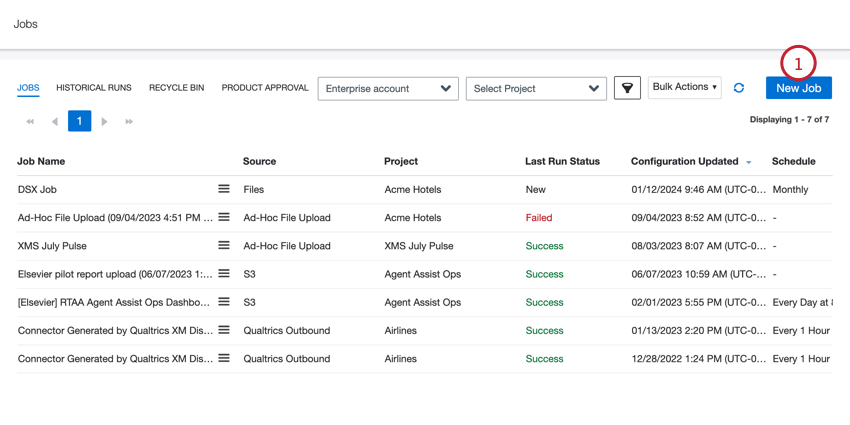
- Auswählen Twitter.

- Geben Sie Ihrem Job einen Namen, damit Sie ihn identifizieren können.
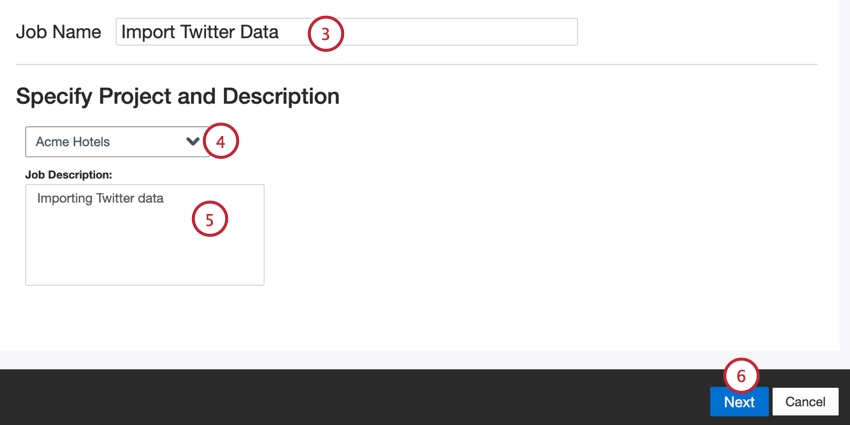
- Wählen Sie das Projekt aus, in das die Daten geladen werden sollen.
- Geben Sie Ihrer Stelle eine Beschreibung, damit Sie ihren Zweck kennen.
- Klicken Sie auf Weiter.
- Geben Sie eine Twitter-Abfrage ein, die mithilfe von erstellt werden kann. Erweiterte Suchanfragen von Twitter. XM Discover ruft öffentliche Tweets und Erwähnungen ab, die Ihren Suchkriterien entsprechen.
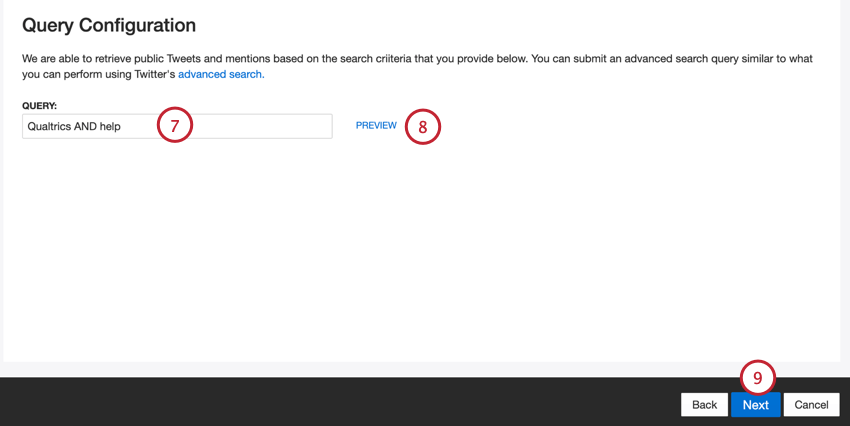
- Klicken Sie auf Vorschau um Ihre Abfrage zu testen. Dadurch werden die Ergebnisse in einer neuen Registerkarte in Ihrem Browser geöffnet.
- Klicken Sie auf Weiter.
- Passen Sie bei Bedarf Ihre Datenzuordnungen. Siehe Supportseite für die Datenzuordnung für detaillierte Informationen zu Zuordnungsfeldern in XM Discover. Die Abschnitt Standarddatenzuordnung enthält Informationen zu den für diesen Konnektor spezifischen Feldern.
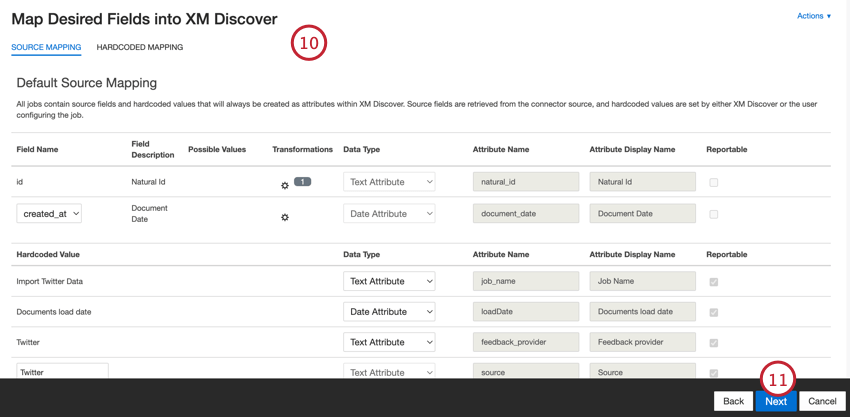
- Klicken Sie auf Weiter.
- Bei Bedarf können Sie Folgendes hinzufügen: Regeln für Datensubstitution und Unkenntlichmachung um sensible Daten auszublenden oder bestimmte Wörter und Phrasen in Feedback und -interaktionen automatisch zu ersetzen. Siehe Supportseite für Datenersetzung und Redaktion.
 Tipp: Klicken Sie auf Stichprobe herunterladen um eine Excel-Datei mit Stichprobe auf Ihren Computer herunterzuladen.
Tipp: Klicken Sie auf Stichprobe herunterladen um eine Excel-Datei mit Stichprobe auf Ihren Computer herunterzuladen. - Klicken Sie auf Weiter.
- Bei Bedarf können Sie eine Konnektorfilter um die eingehenden Daten zu filtern, um einzuschränken, welche Daten importiert werden.
- Sie können auch Anzahl der Datensätze begrenzen in einen einzelnen Job importiert, indem Sie eine Nummer in das Feld Datensatzlimit angeben Kasten. Geben Sie „Alle“ ein, wenn Sie alle Datensätze importieren möchten.
- Klicken Sie auf Weiter.
- Wählen Sie aus, wann Sie benachrichtigt werden möchten. Siehe Jobbenachrichtigungen für weitere Informationen.

- Klicken Sie auf Weiter.
- Legen Sie fest, wie duplizieren Belege behandelt werden. Siehe Handhabung Duplizieren für weitere Informationen.
- Auswählen Inkrementelle Läufe Plan wenn Sie möchten, dass Ihr Job periodisch nach einem Plan ausgeführt wird, oder Einmaligen Pull einrichten wenn Sie möchten, dass der Job nur einmal ausgeführt wird. Siehe Jobeinplanung für weitere Informationen.
- Klicken Sie auf Weiter.
- Überprüfen Sie Ihre Einrichtung. Wenn Sie eine bestimmte Einstellung ändern müssen, klicken Sie auf das Symbol Bearbeiten Drucktaste, die zu diesem Schritt in der Verbindungseinrichtung weitergeleitet werden soll.
- Klicken Sie auf Fertigstellen , um den Job zu sichern.
Standarddatenzuordnung
Dieser Abschnitt enthält Informationen zu den Standardfeldern für Twitter-Eingangsjobs.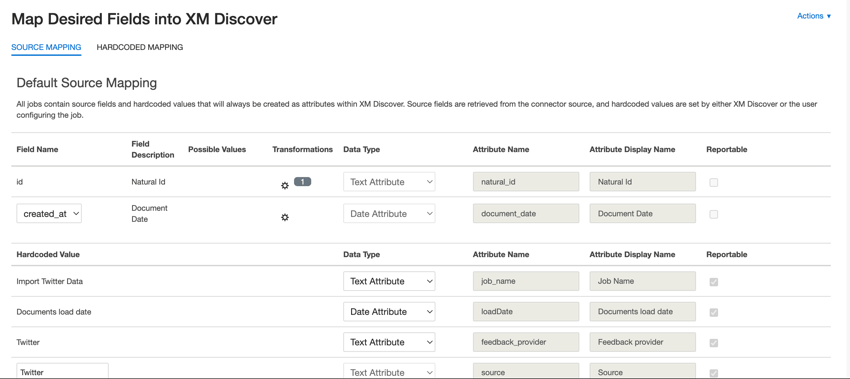
- natural_id: Eine eindeutige ID eines Dokuments. Es wird dringend empfohlen, eine eindeutige ID für jedes Dokument zu haben, um Duplikate korrekt zu verarbeiten. Für Natürliche ID können Sie einen beliebigen Text oder ein numerisches Feld aus Ihren Daten auswählen. Alternativ können Sie IDs automatisch generieren indem Sie ein benutzerdefiniertes Feld hinzufügen.
- tweet_id: Ein eindeutiger Identifikator für einen Tweet innerhalb des Twitter-Dienstes. Diese IDs können verwendet werden, um den ursprünglichen Tweet für eine Vielzahl von Zwecken zu verfolgen, einschließlich der Möglichkeit, auf Erwähnungen Ihrer Organisation über zu antworten. Qualtrics Social Connect.
- document_date: Das primäre Datumsfeld, das mit einem Dokument verknüpft ist. Dieses Datum wird in XM Discover, Trends, Warnungen usw. verwendet. Standardmäßig wird dies dem Datum zugeordnet, an dem der Tweet erstellt wurde. Sie können eine der folgenden Optionen wählen:
- created_at (Standard): Datum und Uhrzeit der Erstellung des Tweets.
- created_at: Datum und Uhrzeit der Erstellung des Benutzerkonto auf Twitter.
- Sie können auch ein bestimmtes Belegdatum festlegen.
- feedback_provider: Identifiziert Daten, die von einem bestimmten Anbieter abgerufen wurden. Bei Tweets ist der Wert dieses Attribut auf „Twitter“ gesetzt und kann nicht geändert werden.
- source_value: Identifiziert Daten, die aus einer bestimmten Quelle abgerufen wurden. Dabei kann es sich um alles handeln, was die Herkunft der Daten beschreibt, z.B. der Name einer Umfrage oder einer mobilen Marketingkampagne. Standardmäßig ist der Wert dieses Attribut auf „Twitter“ gesetzt. Verwendung benutzerdefinierte Transformationen um einen benutzerdefinierten Wert festzulegen, einen Ausdruck zu definieren oder ihn einem anderen Feld zuzuordnen.
- feedback_type: Identifiziert Daten basierend auf ihrem Typ. Dies ist nützlich für das Reporting, wenn Ihr Projekt verschiedene Arten von Daten enthält (z.B. Umfragen und Feedback). Standardmäßig ist der Wert dieses Attribut auf „Sozial“ gesetzt. Verwendung benutzerdefinierte Transformationen um einen benutzerdefinierten Wert festzulegen, einen Ausdruck zu definieren oder ihn einem anderen Feld zuzuordnen.
- Jobname: Identifiziert Daten basierend auf dem Namen des Jobs, der zum Hochladen verwendet wurde. Sie können den Wert dieses Attribut während der Einrichtung über das Jobname Feld, das während der Einrichtung oben auf jeder Seite angezeigt wird.
- loadDate: Gibt an, wann ein Dokument in XM Discover hochgeladen wurde. Dieses Feld wird automatisch gesetzt und kann nicht geändert werden.