Benutzerfreundlicher Leitfaden für die lineare Regression
Was finden Sie hier?
Was ist Regression?
Regression schätzt eine mathematische Formel, die eine oder mehrere Eingabevariablen mit einer Ausgabevariablen verknüpft.
Nehmen wir zum Beispiel an, Sie führen einen Limonadenstand und Sie interessieren sich dafür, was den Umsatz steigert. Zu Ihren Daten gehören der „Umsatz“, die hohe „Temperatur“, die „Anzahl der Kinder, die vorbeigegangen sind“, „Anzahl der Erwachsenen, die vorbeigegangen sind“, die „Beschilderung“, die Sie an diesem Tag verwendet haben, und ein nahegelegener „Umsatz des Wettbewerbers“.
| Umsatz | Temperatur (Celsius) | Minuten der Pausenzeit | Anzahl der Kinder, die vorbeigegangen sind | Anzahl der Erwachsenen, die vorbeigegangen sind | Beschilderung | Umsatz des Wettbewerbers |
|---|---|---|---|---|---|---|
| 44 USD | 28,2 | 30 | 43 | 380 | Handbemalt | 20 EUR |
| 23 EUR | 21,4 | 42 | 28 | 207 | LED | 30 EUR |
| 43 USD | 32,9 | 14 | 43 | 364 | Handbemalt | 34 USD |
| 30 EUR | 24,0 | 24 | 18 | 103 | LED | 15 USD |
| usw. | usw. | usw. | usw. | usw. | usw. | usw. |
Sie denken, dass “Temperatur” (ein Input oder erklärende Variable) kann sich auf “Umsatz” (eine Ausgabe oder Antwortvariable). Wenn Sie die Regression verwenden, um diese Beziehung zu analysieren, kann dies zu folgender Formel führen:
Umsatz = 2,71 * Temperatur – 35
Diese Formel ist aus zwei Gründen sinnvoll.
Erstens ermöglicht es Ihnen, eine Beziehung zu verstehen: Heißere Tage führen zu mehr “Umsatz”. Insbesondere die 2,71 vor “Temperatur” (der sogenannte Koeffizient) bedeutet, dass für jeden Grad “Temperatur” höher geht, im Durchschnitt werden 2,71 US-Dollar mehr “Umsatz” sein. Diese Erkenntnis könnte dazu führen, dass Sie entscheiden, Limonade an kalten Tagen nicht zu verkaufen.
Zweitens, und damit verbunden, kann es Ihnen auch helfen, bestimmte Prognosen zu erstellen. Wenn die “Temperatur” 24 ist, könnte man schätzen, dass seit…
Umsatz = 2,71 * Temperatur – 35
Erlös = 2,71 * 24 – 35
Erlös = 30
… Sie haben rund 30 US-Dollar im “Umsatz”. Das können nützliche Informationen sein, um zu wissen, ob Sie an diesem Tag eine Zahlung vornehmen können, vorausgesetzt, Sie sind sicher, dass Ihr Modell korrekt ist.
Nun gehen wir durch den Prozess der Erstellung dieser Regressionsgleichung.
Anlegen eines Regressionsmodells vorbereiten
1. Denken Sie durch die Theorie Ihrer Regression
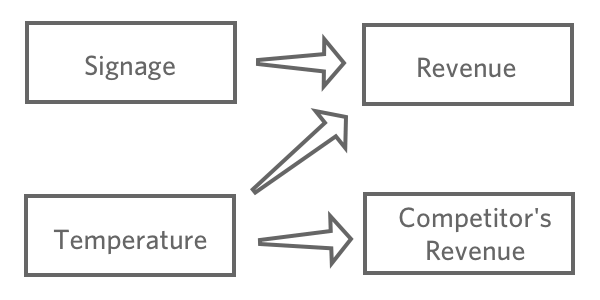
Nachdem Sie eine Antwortvariable ausgewählt haben,,” Hypothese, wie verschiedene Eingaben damit verbunden sein können. Beispiel: Sie denken, dass eine höhere “Temperatur” zu einem höheren “Umsatz” führt. Sie sind sich möglicherweise nicht sicher, wie sich verschiedene Beschriftungen auf den Umsatz auswirken.,” und Sie glauben vielleicht, dass “Mitbewerberverkäufe” von “Temperatur” betroffen sind, aber keine Auswirkungen auf Ihren Limonadenstand haben.
{kind=link}

Das Ziel der Regression besteht in der Regel darin, die Beziehung zwischen mehreren Eingaben und einer Ausgabe zu verstehen. Daher würden Sie in diesem Fall wahrscheinlich ein Modell anlegen, das “Umsatz” mit “Temperatur” erläutert. und “Signage” (auch als „Vorhersage Erlös von Temperatur und Beschilderung“, selbst wenn Sie mehr an einer Erklärung als an einer tatsächlichen Vorhersage interessiert sind).
Wahrscheinlich würden Sie “Mitbewerberumsätze” nicht in Ihre Regression einbeziehen. Es ist wahrscheinlich mit „Umsatz“ korreliert, aber es kommt in der Kausalkette nicht davor, sodass es Ihr Modell verwirren würde.
2. „Beschreiben“ Sie alle Variablen, die für Ihr Modell nützlich sein könnten.
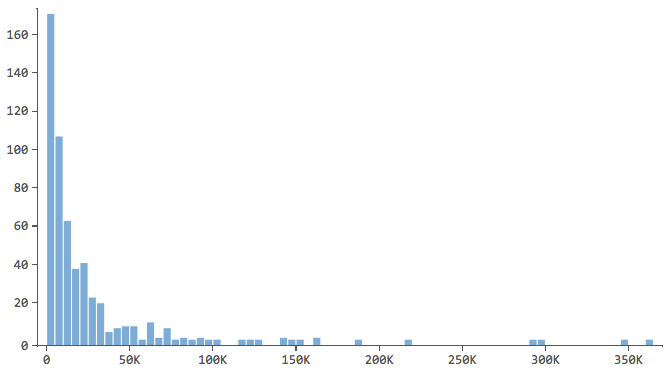
Beginnt von beschreibende die Antwortvariable, in diesem Fall „Umsatz“, und ein gutes Gefühl dafür zu bekommen. Gehen Sie für Ihre erklärenden Variablen genauso vor.
Hinweis, die eine Form wie diese haben…
{kind=link}
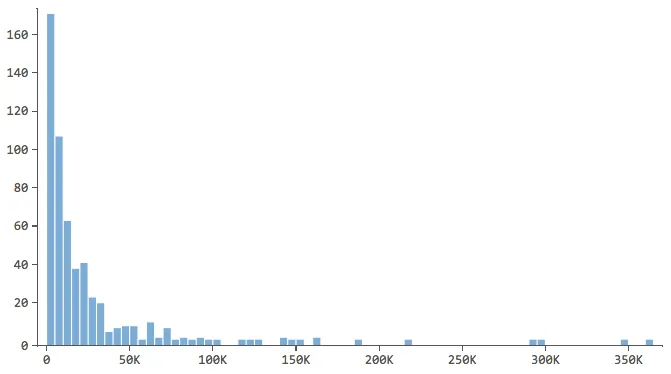
… wo sich der Großteil der Daten in den ersten Bins des Histogramms befindet. Diese Variablen erfordern später besondere Aufmerksamkeit.
3. „Verknüpfen“ aller möglichen erklärenden Variablen mit der Antwortvariablen
Stats iQ wird die Ergebnisse nach der Stärke der statistischen Beziehung. Sehen Sie sich die Ergebnisse an, und notieren Sie, welche Variablen sich auf „Umsatz“ beziehen und wie.
Wenn Sie bereits eine gute Vorstellung davon haben, welche Variablen theoretisch die Ausgabe steuern sollen (z.B. aus vorherigen akademischen Arbeiten), sollten Sie diesen Schritt überspringen. Wenn Ihre Analyse jedoch etwas explorativer ist (z.B. eine Umfrage), ist dies ein nützlicher und wichtiger Schritt.
4. Mit dem Aufbau der Regression beginnen
Erstellen einer Regression -Modell ist ein iterativer Prozess. Sie durchlaufen die folgenden drei Phasen so oft wie nötig.
Die drei Phasen des Aufbaus eines Regressionsmodells
Stufe 1: Variable addieren oder subtrahieren
Beginnen Sie nacheinander mit dem Hinzufügen von Variablen, die Ihre vorherigen Analysen angegeben haben, die sich auf „Umsatz“ bezogen haben (oder fügen Sie Variablen hinzu, die Sie theoretisch hinzufügen sollten). Eins nach dem anderen zu gehen ist nicht unbedingt notwendig, aber es macht es einfacher, Probleme zu erkennen und zu beheben, während Sie weitergehen, und hilft Ihnen, ein Gefühl für das Modell zu bekommen.
Angenommen, Sie beginnen mit der Prognose von „Umsatz“ mit „Temperatur“. Sie finden eine starke Beziehung, bewerten das Modell und finden es zufriedenstellend (weitere Details in einer Minute).
Umsatz = 2,71 * Temperatur – 35
Anschließend fügen Sie “Anzahl der Kinder, die durchgegangen sind” hinzu, und nun hat Ihr Regressionsmodell zwei Begriffe, von denen beide statistisch signifikante Prädiktoren sind. So:
Umsatz = 2,5 * Temperatur + 0,3 * NumberOfChildrenWhoWalkedBy – 12
Anschließend fügen Sie “Anzahl der Erwachsene wer vorbeiging” und die Ergebnisse zeigen nun, dass “Anzahl Erwachsene” im Modell statistisch signifikant ist, “Anzahl Kinder” aber nicht mehr. In der Regel würden Sie “Anzahl untergeordneter Elemente” aus dem Modell entfernen. Jetzt haben wir:
Erlös = 2,6 * Temperatur + 0,4 * AnzahlVonErwachseneWhoWalkedBy – 14
Das bedeutet, dass “Anzahl Erwachsene” der bessere Prädiktor für “Umsatz” ist. Wenn Sie also wissen, wie viele Erwachsene vorbeikommen, fügt das Wissen, wie viele Kinder vorbeikommen, keine neuen Informationen hinzu – es hilft Ihnen nicht, Verkäufe vorherzusagen.
Vielleicht denken Sie zurück und denken daran, dass Kinder nicht wirklich jemals Ihre Limonade kaufen, daher ist es sinnvoll, dass diese Variable nicht zum Modell gehört.
Warum war es im ersten Modell jedoch statistisch signifikant? Wahrscheinlich, weil “Anzahl Kinder” mit “Anzahl Erwachsene” korreliert ist,” und da “Anzahl Erwachsene” noch nicht im Modell war, “Anzahl Kinder” fungierte als grober Vertreter für „Anzahl Erwachsener“.
Die Interpretation von Ergebnisse erfordert viel Einschätzung, und nur weil eine Variable statistisch signifikant ist, bedeutet dies nicht, dass sie tatsächlich kausal ist. Aber indem Sie Variablen sorgfältig addieren und subtrahieren, notieren, wie sich das Modell ändert, und immer über die Theorie hinter Ihrem Modell nachdenken, können Sie interessante Beziehungen in Ihren Daten auseinanderreißen.
Phase 2: Modell bewerten
Jedes Mal, wenn Sie eine Variable addieren oder subtrahieren, sollten Sie die Genauigkeit des Modells bewerten, indem Sie das R-Quadrat (R2), AICR und deren Restplots. Jedes Mal, wenn Sie das Modell ändern, vergleichen Sie die neuen R-Quadrat-, AICR- und Residualdiagramme mit den alten, um zu ermitteln, ob sich das Modell verbessert hat oder nicht.
R-Quadrat (R)2)
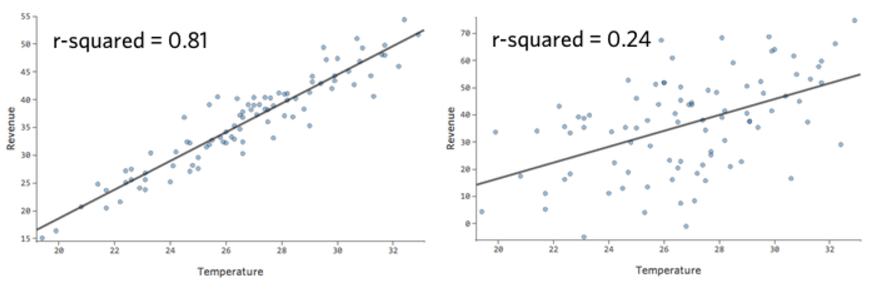
Die numerische Metrik zur Quantifizierung der Prognosegenauigkeit des Modells wird als R-Quadrat bezeichnet, das zwischen null und eins liegt. Eine Null bedeutet, dass das Modell keinen Prognosewert hat, und eine davon bedeutet, dass das Modell alles perfekt vorhersagt.
Beispiel: Das Modell auf der linken Seite ist genauer als das Modell auf der rechten Seite. Das heißt, wenn Sie “Temperatur” kennen, haben Sie eine ziemlich gute Vermutung, was “Umsatz” auf der linken Seite, aber nicht wirklich auf der rechten Seite.
{kind=link}

Es gibt keine feste Definition eines „guten“ R-Quadrats. In einigen Einstellungen kann es interessant sein, irgendeinen Effekt zu sehen, während Ihr Modell in anderen unbrauchbar sein könnte, es sei denn, es ist sehr genau.
Jedes Mal, wenn Sie eine Variable hinzufügen, geht das R-Quadrat hoch, sodass das Erreichen des höchstmöglichen R-Quadrats nicht das Ziel ist. Stattdessen möchten Sie die Genauigkeit (R-Quadrat) des Modells mit seiner Komplexität (in der Regel die Anzahl der Variablen darin) ausgleichen.
AICR
AICR ist eine Metrik, die Genauigkeit mit Komplexität ausgleicht. Eine höhere Genauigkeit führt zu besseren Bewertungen, eine hinzugefügte Komplexität (mehr Variablen) führt zu schlechteren Bewertungen. Das Modell mit dem unteren AICR ist besser.
Beachten Sie, dass die Kennzahl AICR nur für den Vergleich von AIKR aus Modellen mit der gleiche Anzahl von Datenzeilen und dieselbe Ausgabevariable.
Prognoseintervalle
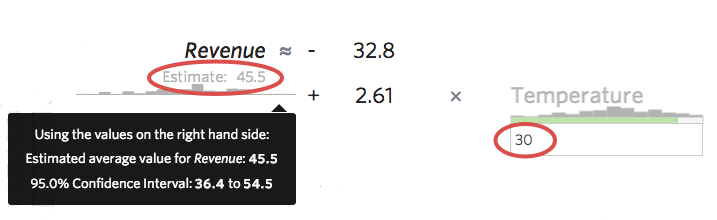
Eine weitere nützliche Möglichkeit, ein Gefühl für die Genauigkeit Ihres Modells zu erhalten, besteht darin, Stichprobe in Ihrer Formel zu speichern und das Prognoseintervall anzuzeigen, das Stats iQ berechnet. Wenn Sie beispielsweise die Zahl 30 in die Formel einfügen, teilt Stats iQ Ihnen mit, dass der vorhergesagte Wert 45,5 beträgt, das Konfidenzintervall von 95 % jedoch 36,4 bis 54,5 beträgt. Das bedeutet, dass Sie 95 % sicher sein könnten, dass Sie bei einem morgigen Ertrag von 30 Grad zwischen 36,40 USD und 54,50 USD in “Umsatz” erhalten würden. Sie könnten sich ein genaueres Modell vorstellen, bei dem das Prognoseintervall ein enges Band wie 44 bis 48 USD war, oder ein weniger genaues, bei dem das Intervall breit war, wie 20 bis 72 USD.
{kind=link}

Dieser Ansatz ist nur hilfreich, wenn Ihre Restflächen gesund aussehen (siehe unten), andernfalls sind sie ungenau.
Residuen
Residuen sind das primäre Diagnosewerkzeug zur Beurteilung und Verbesserung der Regression. Daher gibt es einen ganzen separaten Abschnitt über Interpretieren von Resten zur Verbesserung Ihres Modells. Sie erfahren oder aktualisieren Ihr Gedächtnis darüber, was Reste sind, wie Sie sie verwenden, um das Modell zu bewerten und zu verbessern, und wie Sie darüber nachdenken, wie genau Sie Ihr Modell sein müssen.
Wir empfehlen Ihnen, es vollständig zu lesen, da es alles andere abdeckt, was Sie benötigen, um ein tolles Modell zu produzieren. Aber man kann natürlich immer wieder darauf zurückkommen.
Phase 3: Modell entsprechend ändern
Wenn Ihre Bewertung des Modells ergibt, dass es zufriedenstellend ist, sind Sie entweder fertig, oder Sie können zu Stufe 1 zurückkehren und weitere Variablen eingeben.
Wenn Ihre Bewertung feststellt, dass das Modell fehlt, verwenden Sie Stats iQ und die residualer Diagnoseabschnitt um die Probleme zu beheben.
Wenn Sie das Modell ändern, notieren Sie sich kontinuierlich die sich ändernden R-Quadrate, AICR und Residualdiagnosen und entscheiden Sie, ob die Änderungen, die Sie vornehmen, Ihr Modell unterstützen oder verletzen.
FAQs
Wie erstelle ich eine neue Stats iQ-Variable?
Wie erstelle ich eine neue Stats iQ-Variable?
Welche Optionen gibt es für die Analyse meiner Daten in Stats iQ?
Welche Optionen gibt es für die Analyse meiner Daten in Stats iQ?
- Beschreiben: Wenn Sie eine Variable aus der Liste auswählen und dann auf Beschreiben klicken, erhalten Sie eine Visualisierung der in dieser Variablen enthaltenen Daten. Verwenden Sie diese Option, wenn Sie sehen möchten, wie die Daten für eine bestimmte Variable verteilt werden.
- Verknüpfen: Wenn Sie zwei Variablen auswählen und dann auf Verknüpfen klicken, wird eine statistische Analyse der Beziehung zwischen den beiden Variablen ausgeführt. Verwenden Sie diese Option, wenn Sie wissen möchten, wie stark zwei Variablen korrelieren.
- Pivot-Tabelle: Wenn Sie zwei oder mehr Variablen auswählen und auf Pivot-Tabelle klicken, wird eine Tabelle erstellt, in der die Werte der Variablen als Zeilen und Spalten angezeigt werden. Die Zellen können so eingestellt werden, dass eine Vielzahl verschiedener Informationen angezeigt werden, einschließlich Spalten- und Zeilenprozentsatz, Summe und Abweichung. Verwenden Sie diese Option, wenn Sie die Überlappung bestimmter Werte eines Variablensatzes vergleichen möchten.
- Regression: Wenn Sie zwei Variablen auswählen und auf Regression klicken, wird die mathematische Beziehung zwischen den Variablen hergestellt. Verwenden Sie diese Option, wenn Sie Werte für eine Variable basierend auf den Werten einer anderen prognostizieren möchten.
- Cluster: Wenn Sie zwei bis zehn demografische Variablen auswählen und auf Cluster klicken, werden Gruppierungen von Merkmalen angezeigt, die am wahrscheinlichsten zusammen auftreten. Auf diese Weise werden die in Ihren Daten erfassten Populationssegmente angezeigt.
Ich weiß nicht, was dieser statistische Begriff bedeutet. Können Sie es mir sagen?
Ich weiß nicht, was dieser statistische Begriff bedeutet. Können Sie es mir sagen?
- Statistische Tests: ANOVA, T-Test und Chi-Quadrat sind alle statistischen Tests, die Stats iQ durchführt, um zu prüfen, ob die Beziehung zwischen zwei Variablen signifikant ist. Diese Tests werden verwendet, um einen P-Wert zu generieren.
- P-Wert: Dieser Wert gibt die Wahrscheinlichkeit an, dass die beobachteten Ergebnisse angezeigt werden, wenn keine Korrelation zwischen den Variablen vorhanden ist. Ein niedrigerer P-Wert bedeutet mehr korrelierte Daten.
- Effektgröße: Die Effektgröße ist ein Maß dafür, wie groß die Korrelation zwischen zwei Variablen ist. Dies wird je nach Art des durchgeführten statistischen Tests unterschiedlich gemessen. Beispiele sind Cohen’s d, Pearson’s r und Cramer’s v. Je größer der Wert der Effektgröße, desto korrelierender sind die Variablen.
Wie filtere ich die Daten, die in Stats iQ angezeigt werden?
Wie filtere ich die Daten, die in Stats iQ angezeigt werden?
Wie kann ich meine neuen Antworten in Stats iQ anzeigen?
Wie kann ich meine neuen Antworten in Stats iQ anzeigen?
Wie werden Analysekarten in meinem Stats iQ-Arbeitsbereich bestellt?
Wie werden Analysekarten in meinem Stats iQ-Arbeitsbereich bestellt?
Was ist Stats iQ? / Wo ist Statwing?
Was ist Stats iQ? / Wo ist Statwing?
Was mache ich, wenn meine Daten nicht ordnungsgemäß geladen werden?
Was mache ich, wenn meine Daten nicht ordnungsgemäß geladen werden?
Großartig! Vielen Dank für die Rückmeldung!
Vielen Dank für die Rückmeldung!