Vorgefertigte R-Skripte
Was finden Sie hier?
Achtung: Sie lesen eine Funktion, auf die nicht alle Stats iQ Zugriff haben. Wenn Sie an dieser Funktion interessiert sind, Kontakt Ihren Benutzerkonto um zu sehen, ob Sie sich qualifizieren.
Informationen zu vordefinierten R-Skripten
R ist eine statistische Programmiersprache, die für flexible und leistungsstarke Analysen weit verbreitet ist. Bei Verwendung von R-Kodierung in Stats iQkönnen Sie aus mehreren Analyseskripten auswählen, um die Verwendung von R zu vereinfachen und effizienter zu gestalten.
Skript für R-Code auswählen
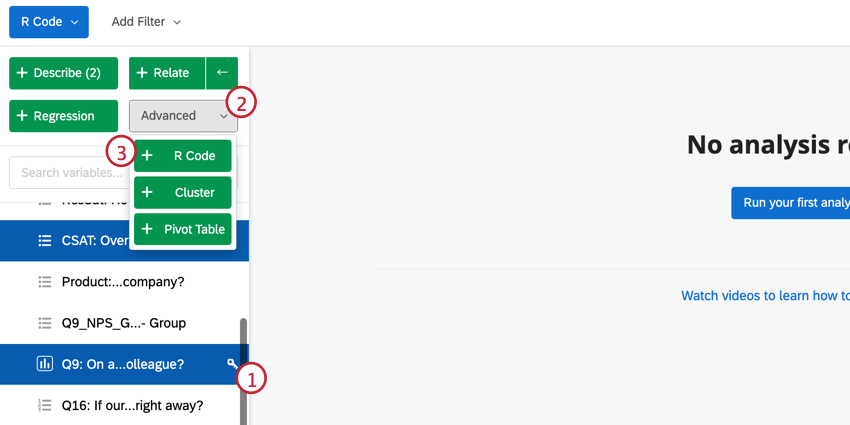
Tipp: Sie können Änderungen an den von Ihnen ausgewählten Variablen direkt in diesem Fenster vornehmen. Um die Umkodierungswerte zu bearbeiten, klicken Sie auf Bearbeiten. Wenn Sie die Variable löschen möchten, klicken Sie auf das ( – ). Wenn Sie eine neue Variable hinzufügen möchten, wählen Sie Variable hinzufügen unten links.
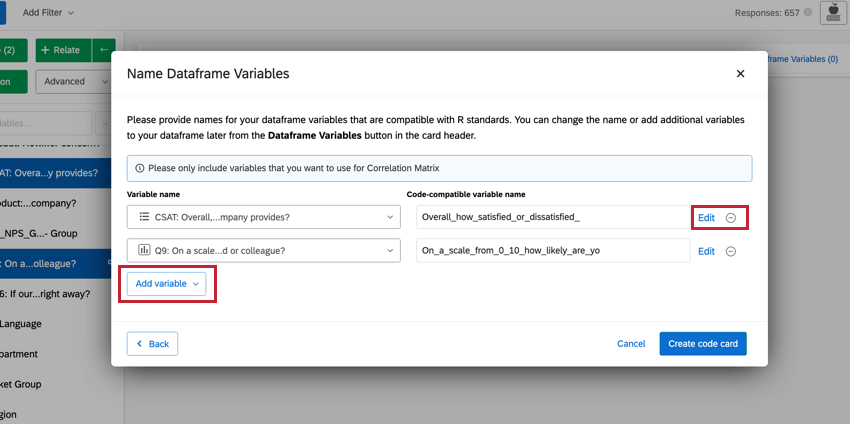
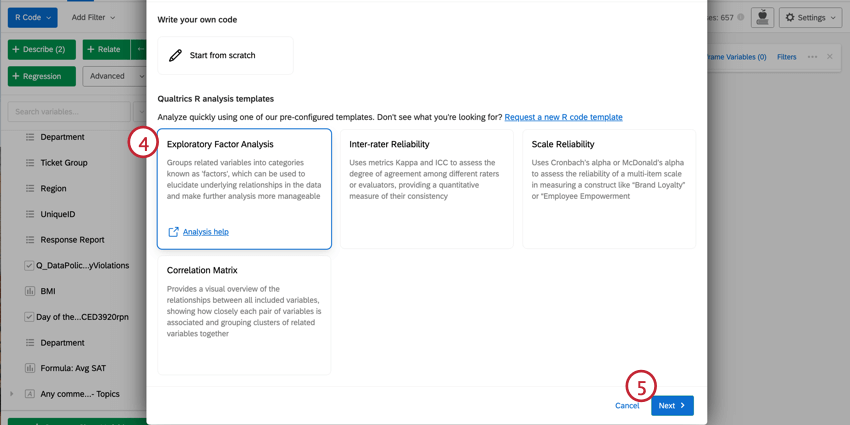
Navigieren in vorgefertigten R-Code-Skripten
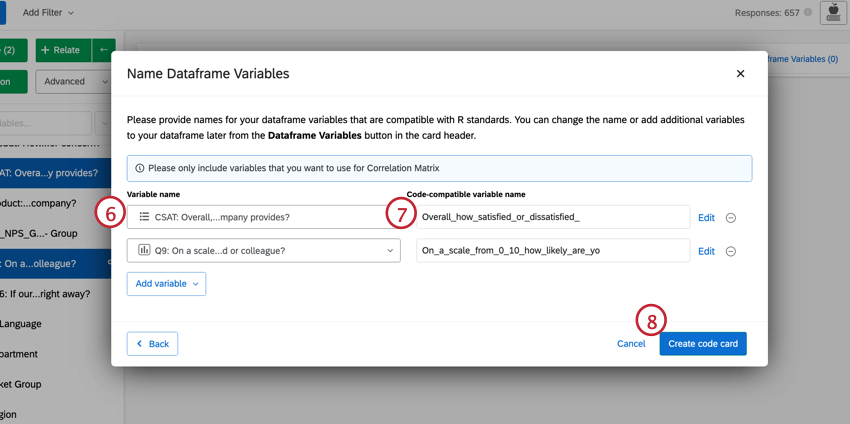
Ihr Skript wird in den Codeabschnitt der R-Code-Karte eingefügt. Dieser Code enthält Ratschläge sowie die Befehle zum Generieren der von Ihnen ausgewählten Analyse. Um Ihre Analyse auszuführen, wählen Sie Alle ausführen. Die Ergebnisse werden im Ausgabefeld auf der rechten Seite angezeigt.
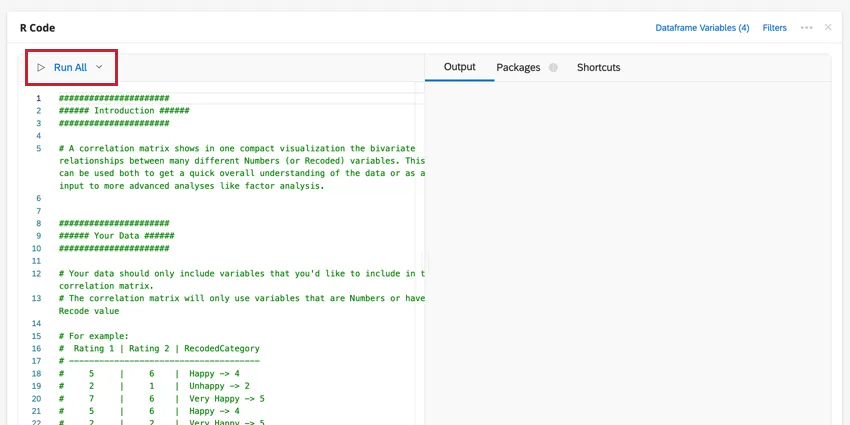
Sie können Ihre Dataframe-Variablen bearbeiten oder eine Filter zur Analyse hinzu, indem Sie oben rechts auf die Optionen klicken. Klicken Sie auf das Drei-Punkt-Menü, um Ihrer Codekarte Notizen hinzuzufügen, die Analyse zu kopieren oder die Karte im Vollbild zu öffnen.
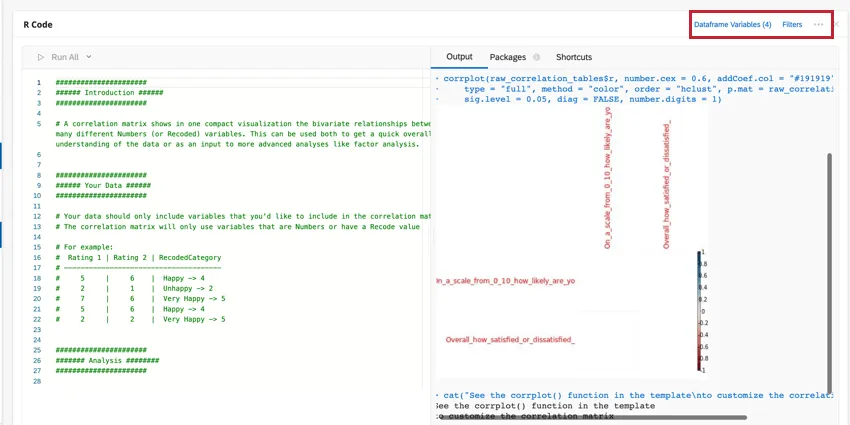
SHORTCUTS
Tastaturbefehle können verwendet werden, um effizienter durch die R-Code-Karte zu navigieren. Klicken Sie auf Tastaturbefehle eine Liste der möglichen Aktionen.
PACKAGES
R-Coding in Stats iQ wird mit Hunderten der beliebtesten R-Pakete vorinstalliert, die für die Analyse verwendet werden. Klicken Sie auf die Registerkarte Pakete in der rechten Hälfte der Karte, um die Liste der verfügbaren Pakete anzuzeigen. Weitere Informationen zur Verwendung von Paketen finden Sie unter. R-Kodierung in Stats iQ.
Zuverlässigkeit der Skala
Die Skalenzuverlässigkeit bewertet, inwieweit Positionen in einer Mehrpositionswaage ein Konstrukt zuverlässig messen können. Mit anderen Worten, wenn dasselbe mit denselben Fragen gemessen wird, gibt es verlässlich ähnliche Ergebnisse? Wenn dies der Fall ist, besteht die Zuversicht, dass alle Veränderungen, die wir in der Zukunft sehen, auf Veränderungen in der befragten Bevölkerung oder auf Interventionen zurückzuführen sind, die zur Verbesserung der Punktzahl vorgenommen wurden.
INTERPRETING RELIABILITÄTSMASSNAHMEN
Die Messgrößen der Skalenzuverlässigkeit fallen zwischen 0 und 1 und stellen im Wesentlichen eine aggregierte Korrelation zwischen allen Positionen in der Skala dar.
Cronbachs Alpha, ein weit verbreitetes Zuverlässigkeitsmaß, unterschätzt die Zuverlässigkeit oft aufgrund bestimmter Annahmen. McDonald’s Omega, eine empfohlene Alternative, vermeidet diese Mängel. Wir verwenden standardmäßig McDonald’s Omega, aber Cronbachs Alpha wird immer noch weithin akzeptiert.
Es gibt keine einzige korrekte Methode, um die resultierende Zahl zu interpretieren, aber unsere bevorzugte Faustregel für beide Omega ist unten beschrieben:
| Weniger als 0,65 | Inakzeptabel |
| 0,65 | Akzeptabel |
| 0,8 | Sehr gut |
Wenn Ihre zuverlässige Skala nicht akzeptabel ist, gibt es einige Möglichkeiten, Ihren Datensatz zu beheben:
- Entferne alle Gegenstände, die das Omega oder Alpha senken.
- Es ist möglich, dass zwei verschiedene Konstrukte gemessen werden. Wenn dies der Fall ist, würden die Variablen in zwei Gruppen unterteilt werden und das Ausführen dieser Analyse für jede Gruppe zu Zuverlässigkeitswerten führen, die höher sind als die der ersten Analyse. Sie können dies untersuchen, indem Sie die Matrix in der Ausgabe überprüfen oder die Exploratorische Faktoranalyse Skript, um zu sehen, welche Gruppierungen natürlich aus den Daten herausfallen.
- Letztendlich kann es erforderlich sein, die Umfrage zu ändern und erneut auszuführen. Positionen, die eine geringe Korrelation mit den anderen haben, müssen möglicherweise geklärt oder überarbeitet werden, oder andere Positionen müssen hinzugefügt werden.
Sehr hohe Ergebnisse (z. B. 0,95) können auch auf ein Problem mit der Skala hinweisen, in der Regel, dass Sie immer noch eine Skala haben können, die sehr zuverlässig ist, ohne so viele Elemente zu haben. In diesem Fall empfehlen wir, die am wenigsten nützlichen Positionen aus der Skala zu entfernen und die Analyse erneut auszuführen.
INTERPRETING VON ITEM-LEVEL-STATISTIKEN
Das Skript führt zuerst eine allgemeine Zuverlässigkeitskennzahl und dann eine Iteration für jede Variable aus. Ziel der Analyse der Zuverlässigkeit pro Position ist es, zu verstehen, welche Elemente für den Aufbau der Waage am nützlichsten sind. Stats iQ gibt eine Tabelle aus, die wie folgt aussieht:
Insgesamt McDonald’s Omega: 0,71
| N | Mittelwert | Positions-Gesamt-Korrelation | McDonald’s Omega, wenn entfernt | |
| A1 | 2784 | 4.59 | 0.31 | 0.72 |
| A2 | 2773 | 4.80 | 0.56 | 0.69 |
| A3 | 2774 | 4.60 | 0.59 | 0.61 |
| … | … | … | … | … |
- Das allgemeine Ziel ist es, ein höheres McDonald’s Omega mit einer geringeren Anzahl von Gegenständen zu haben. Wenn also ein Forscher eine neue Skala erstellt, würde er wahrscheinlich A1 entfernen wollen, da die Omega ohne sie tatsächlich höher ist.
- Die rest Elemente, die die Zuverlässigkeit verringern würden, wenn sie entfernt würden, müssen vom Forscher ermittelt werden. Wenn sich ein Forscher beispielsweise mit Umfrage befasst, kann er bei der Entscheidung, eine Variable zu entfernen, eine größere Verlässlichkeit ermöglichen.
- Die Element-Gesamt-Korrelation ist die Korrelation zwischen dieser Position und dem Durchschnitt aller anderen Elemente. Niedrige Element-Gesamt-Korrelation deutet darauf hin, dass die Variable nicht repräsentativ genug für das zugrunde liegende Konstrukt ist. Die häufigste Faustregel ist, verdächtig zu sein mit einer Item-Total Correlation von 0,3 oder niedriger, besonders wenn Sie viele Elemente haben, die die Zuverlässigkeitsmetrik künstlich aufbläht.
Wenn Sie eine Position entfernen möchten, sollten Sie alle anderen Statistiken erneut ausführen, bevor Sie entscheiden, ob eine andere Position entfernt werden soll. In Stats iQ bedeutet dies, dass die Variable nur von der gesamten Karte entfernt wird. rest wird automatisch ausgeführt.
MATRIX INTERPOSITION
Die Matrix zeigt die Korrelation zwischen jeder Variablen in der Analyse und jeder anderen Variablen an. Wenn beispielsweise eine Variable sehr stark mit einer anderen korreliert (z. B. 0,9), können diese Fragen redundant sein, und das Entfernen dieser Fragen wirkt sich nur geringfügig auf Ihre Zuverlässigkeit aus.
Die durchschnittliche Interpostenkorrelation ist der Durchschnitt der Zahlen in der Matrix. Höhere Zahlen deuten darauf hin, dass einige Elemente möglicherweise redundant sind und entfernt werden könnten. Im Allgemeinen sollten Variablen im Bereich von 0,2 bis 0,4 liegen.
Tipp: Die durchschnittliche Korrelation zwischen Positionen kann nützliche Informationen zu den allgemeinen Zuverlässigkeitswerten liefern. Wenn Sie beispielsweise mit einer kleineren Anzahl von Elementen arbeiten (z. B. 3) und einen niedrigen Zuverlässigkeitswert und eine hohe durchschnittliche Korrelation zwischen Positionen haben, kann dies darauf hindeuten, dass es an fehlenden Elementen und nicht an einer fehlenden Korrelation zwischen ihnen liegt.
MEHR RESSOURCEN
- Die Zuverlässigkeitsanalyse in Stats iQ wird von der Funktion compRelSem() aus dem Paket semTools R ausgeführt. Eine Vielzahl von erweiterten Einstellungen sind: in der Dokumentation beschrieben.. Es ist nicht erforderlich, diese Einstellungen zu verwenden oder zu verstehen, um eine Zuverlässigkeitsanalyse durchzuführen.
- Die Matrix wird von der Funktion corrplot() aus dem Paket corrplot R ausgeführt. Eine Vielzahl von erweiterten Einstellungen und Anpassungen sind: in der Dokumentation beschrieben. und in diesem Begehung.
Zuverlässigkeit zwischen Bewertern
Die Inter-Rater-Zuverlässigkeit (IRR) wird verwendet, um zu beurteilen, inwieweit sich zwei oder mehr Bewerter in ihrer Bewertung einig sind. Beispielsweise können drei verschiedene Kodierer einen Textkommentar als positiv, neutral oder negativ Stimmung; der IRR beschreibt, wie viel sie miteinander abgestimmt haben.
MASSNAHMEN DER INTER-RATER-RELIABILITÄT
Der IRR wird anhand leicht unterschiedlicher Kennzahlen basierend auf der Struktur der Daten bewertet. Eine Analyse der Interzuverlässigkeit von zwei Bewertern verwendet beispielsweise eine etwas andere Metrik als die Interzuverlässigkeit von 3 Ratern.
Stats iQ wählt automatisch die entsprechende Metrik für Ihre Daten aus.
ERGEBNISSE
Die Kappa- oder ICC-Metrik ist die Primärausbeute zwischen 0 und 1 und gibt an, wie gut die Bewerter korreliert sind. Wir empfehlen die folgenden Bereiche für die Interpretation der Kappa:
| 0,75 bis 1 | Ausgezeichnet |
| 0,6 bis 0,75 | Gut |
| 0,4 bis 0,6 | Akzeptabel |
| 0,4 oder niedriger | Unzureichend |
MEHR RESSOURCEN
- Diese Zuverlässigkeitsanalyse wird von den Funktionen aus dem Paket IRR R ausgeführt. Eine Vielzahl von erweiterten Einstellungen sind: in der Dokumentation beschrieben.. Es ist nicht erforderlich, diese Einstellungen zu verwenden oder zu verstehen, um diese Analyse auszuführen.
Explorative Faktorenanalyse
Die explorative Faktoranalyse (EFA) ist eine statistische Technik, mit der Sie eine große Anzahl von Variablen in einen kleineren, überschaubareren Satz zusammenfassender „Faktoren“ reduzieren können. Dies erleichtert ihnen die Interpretation, Kommunikation und Ausführung weiterer Analysen (z.B. Regressionsanalyse). Die EFA folgt in der Regel diesen Schritten:
Das Ergebnis ist eine Reihe benannter Faktoren und deren Umfrage. Diese Faktoren können als konzeptioneller Rahmen für weitere Analysen dienen oder wieder auf die Daten angewendet werden.
Beispiel: Wenn die Artikel „Mein Zimmer war sauber“, „Der rest des Hotels war sauber“, und „Mein Zimmer hatte alles, was ich brauchte“ im selben Faktor liegen, könnten Sie diese Elemente im Durchschnitt anzeigen und über das zusammenfassende Maß von „Zimmerqualität“ berichten.
DIAGNOSTIK
Das Skript führt zunächst eine Reihe von Diagnosen aus, um sicherzustellen, dass die Daten für EFA geeignet sind:
- Stichprobe: In der Regel wird ein Verhältnis von 10:1 von Antworten zu Positionen vorgeschlagen. Wenn Sie beispielsweise 10 Fragen haben, sollten Sie mindestens 100 Umfrageteilnehmer haben.
- Bartlett’s Test of Sphericity: Dieser Test wertet aus, ob die Positionen so korreliert sind, dass sie sinnvoll in Faktoren gruppiert werden können. Wenn dies fehlschlägt, gibt es wahrscheinlich mehrere Positionen, die nicht ausreichend mit den anderen korrelieren. Sie können Elemente aus Ihrer Analyse verwerfen, die nicht mit anderen korrelieren, oder weitere verwandte Elemente zur Umfrage hinzufügen.
- Determinant: Die Determinante wertet aus, ob die Positionen zu stark korreliert sind, um sinnvoll in Faktoren gruppiert zu werden. Wenn diese Diagnose fehlschlägt, gibt es wahrscheinlich Elemente, die einander zu ähnlich sind, um sie in Faktoren zu trennen. Erwägen Sie, Umfrage zu bearbeiten, um differenzierter zu sein.
- Kaiser-Meyer-Olkin (KMO) Maßnahme: Diese Kennzahl prüft, ob Ihre Umfrage ausreichend gemeinsam sind, um sie in aussagekräftige Faktoren zu gruppieren. Das Bestehen dieser Diagnose bedeutet, dass die Antworten in Ihrer Umfrage viel gemeinsam sind und gut gruppiert werden können. Andernfalls werden die Elemente nicht in Kategorien zusammengefasst. Wenn diese Diagnose fehlschlägt, können Sie Ihre Umfrage überarbeiten, um weitere ähnliche Designvorlagen zu erfassen und Elemente zu entfernen, die keine klare Beziehung zu anderen zeigen.
WÄHRUNGSFAKTOREN
Der Zweck der EFA besteht darin, viele Variablen in eine relativ kleine Zahl zu kochen, die für die Analyse nützlich sind. Daher müssen Sie die Faktoranalyse möglicherweise mehrmals mit einer unterschiedlichen Anzahl von Faktoren ausführen, um eine Gruppierung zu finden, die für Sie geeignet ist. Das EFA-Skript schlägt die Anzahl der Faktoren anhand ihrer Eigenwerte vor.
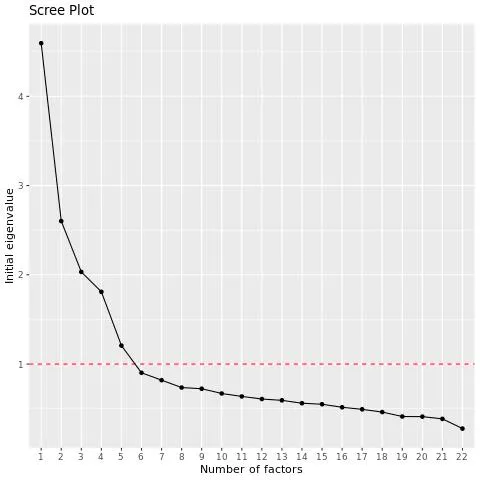
Tipp: Eigenwerte messen das Ausmaß, in dem ein Faktor mit den ursprünglichen Variablen korreliert, aus denen er erstellt wurde, indem die R-Quadrat-Werte zwischen dem Faktor und den Variablen addiert werden. Wenn beispielsweise das R-Quadrat zwischen dem Faktor und Q1 0,8 und das des Faktors und Q2 0,5 ist, ist der Eigenwert 1,3. In der Regel sollten Faktoren mit einem Eigenwert über 1 verwendet werden. Das EFA-Skript verwendet diesen Benchmark, um die Anzahl der Faktoren vorzuschlagen.
Das EFA-Skript gibt ein Screenshot aus, das die Eigenwerte der Variablen in absteigender Reihenfolge anzeigt. Sie können das Diagramm untersuchen, um zu sehen, wie viele Faktoren vor dem „Ellbogen“ im Diagramm auftreten. Danach ist das Hinzufügen weiterer Faktoren weniger nützlich.
Beispiel: In diesem Beispiel gibt es eine große Abladung nach der 4. Variable und dann eine weitere signifikante Abladung nach der 5. Variable. Standardmäßig verwendet das Skript hier 5 Faktoren, aber Sie können es auch mit 4 Faktoren ausführen und Ihre Ergebnisse vergleichen.
{kind=link}
{kind=link}
{kind=link}
NAMIEREN SIE IHRE FAKTOREN
Nach dem Ausführen von EFA wird jede Variable einem Faktor zugeordnet. Es ist hilfreich, jedem Faktor einen Namen zu geben, der Ihnen eine Kurzform gibt, um über sie zu sprechen, was Ihre Erkenntnisse leichter zugänglich macht. Ziel ist es, Ihre komplexen Daten in ein paar verständliche Themen zu vereinfachen.
Im Folgenden finden Sie einige Richtlinien für die Benennung Ihrer Faktoren:
- Beschreiben: Versuchen Sie, das gemeinsame Designvorlage zu erfassen, das die Variablen in der Gruppe zusammenfasst.
- Einfach halten: Ihre Faktornamen sollten leicht zu verstehen und zu kommunizieren sein. Vermeiden Sie Fachjargon oder zu komplexe Formulierungen.
- Betrachten Sie Ihre Zielgruppe: Faktornamen sollten für Personen sinnvoll sein, die Ihre Analyse verwenden. So wäre zum Beispiel „Sauberkeit“ sowohl für Hotelmanager als auch für Hotelgäste sinnvoll.
- Konsistenz: Wenn sich Ihre Umfrage oder Ihr Datensatz über verschiedene Domänen oder Feedbacknehmer erstreckt, stellen Sie sicher, dass Ihre Faktornamen konsistent sind.
ZUGEORDNETE MASSNAHMEN & MASSNAHMEN
Die Faktorlast-Tabelle ist eine der wichtigsten Ausgaben von EFA. Das Laden des Faktors für ein bestimmtes Paar variabler Faktoren ist die Korrelation zwischen dieser Variablen und dem Faktor. Wenn eine Variable einen hohen Faktor hat, der für einen bestimmten Faktor geladen wird, bedeutet dies, dass die Frage stark mit diesem Faktor verbunden ist.
Die Eindeutigkeit ist der Anteil der Varianz, der für die spezifische Variable eindeutig ist und nicht mit anderen Variablen geteilt wird. Eindeutigkeitswerte reichen von 0 bis 1, wobei höhere Werte angeben, dass die Variable eindeutig ist und in keinen der Faktoren gut passt. .
Generell wird empfohlen, Variablen zu entfernen, wenn ihre Faktorbelastungen über 0,3 liegen oder ihre Eindeutigkeit über 0,7 liegt.
NUTZEN IHRER ERGEBNISSE
Die Faktoranalyse ist ein iterativer Prozess. Daher müssen Sie ihn möglicherweise mehrmals mit einer unterschiedlichen Anzahl von Faktoren ausführen, um eine Gruppierung zu finden, die für Sie geeignet ist. Für die meisten Forscher liegt die wichtigste Erkenntnis darin, Gruppierungen von Faktoren zu finden, die einen neuen Erkenntnis in ihre Daten bieten können. Sie können diese Faktoren jedoch als neue Variablen in nachfolgenden Analysen verwenden, z.B.: Regression oder Clusteranalyse. Sie können beispielsweise eine neue Variable für jeden Faktor anlegen, der den Durchschnittswert aller Variablen verwendet, die darin gruppiert sind.
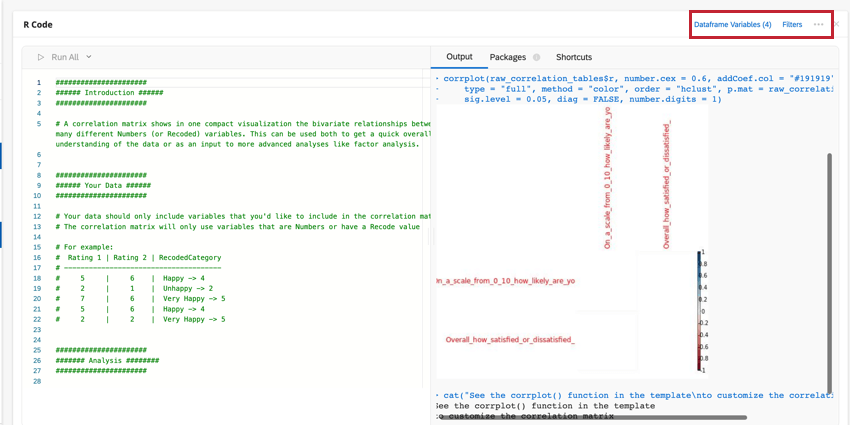
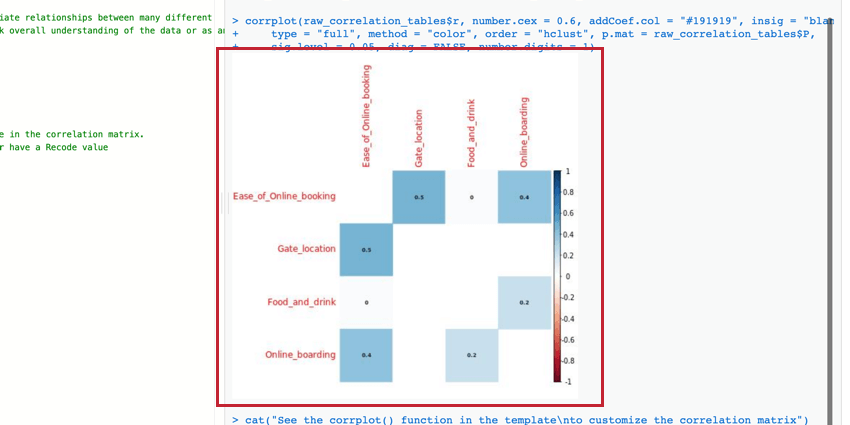
Korrelationsmatrix
Die Matrix ist eine Tabelle, die die Korrelation zwischen den einzelnen bereitgestellten Variablenpaaren anzeigt. Diese Tabelle verwendet standardmäßig Pearsons r, um die Korrelation zu messen, aber Sie können sie in Spearmans Rho ändern, wenn Sie möchten.
{kind=link}
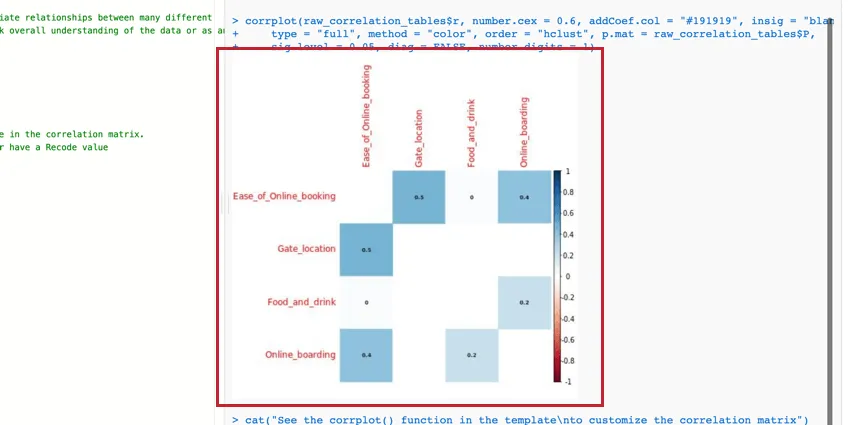
Sie können die Parameter der Funktion corrplot() bearbeiten, um die Tabelle zu ändern und lesbarer zu machen. Weitere Informationen finden Sie im offiziellen R Walkthrough und Dokumentation.
Großartig! Vielen Dank für die Rückmeldung!
Vielen Dank für die Rückmeldung!