Cluster-Analyse
Was finden Sie hier?
Informationen zur Cluster-Analyse
Bei der Analyse unserer Daten beschäftigen wir uns häufig mit verschiedenen demografischen Gruppen und werden die Befragten nach Einkommen, Region, Alter und mehr segmentieren. Aber manchmal können diese Labels reduktiv sein – schließlich sagt Ihnen das Wissen, dass Sie viele männliche Umfrageteilnehmer haben, nicht, welche Art von Werbekampagne sie sehen möchten. Ist Ihr Publikum in erster Linie Millenials? Fußballväter? Beides? Wie fügen Sie persönliche Merkmale in Begriffe ein, die für Marketingzwecke aufgeschlüsselt werden können?
Die Cluster-Analyse ist ein Mittel, um die Gruppen zu ermitteln, die natürlich im Datensatz Ihrer Umfrage vorkommen. Dazu wird analysiert, welche demografischen, verhaltensbezogenen und/oder glaubwürdigen Qualitäten am stärksten korrelieren.
{kind=link}

Tipp: Möglicherweise haben Sie bis zu 750 Karten in Ihrem Arbeitsbereich. Wenn Sie dieses Limit erreichen, wird ein Fehler angezeigt, wenn Sie versuchen, eine neue Karte anzulegen, und warnt Sie, dass Ihre ältesten Karten gelöscht werden.
Vorbereiten einer Umfrage für die Cluster-Analyse
Um eine Cluster-Analyse durchzuführen, müssen Sie die richtigen Daten in Ihrer Umfrage erfassen.
- Stellen Sie die richtigen Fragen:
- Demografie: Fragen Sie nach grundlegenden beschreibenden Informationen wie Alter, Einkommensklasse, Rasse oder Geschlecht.
- Verhalten: Fragen Sie, wie Kunden mit Ihrer Instanz und Ihren Produkten interagieren oder nach Verhaltensweisen, die sich auf ihr Kaufverhalten beziehen können. Sie können beispielsweise fragen, wie oft der Kunde einkaufen geht.
- Operativ Daten: Dies sind Informationen wie die auf Ihrer Website aufgewendete Zeit oder die Beschäftigungsdauer eines Mitarbeitende in Ihrem Unternehmen. Tipp: Sind Sie daran interessiert, die auf einer Seite aufgewendete Zeit zu verfolgen? Dann könnten Sie daran interessiert sein, unsere Feedback Funktion. Kontakt Ihren Benutzerkonto wenn Sie mehr erfahren möchten.

- Einstellungen und Überzeugungen: Umfrage Sie Ihre Umfrageteilnehmer zu ihren Kernwerten, ihren Einstellungen und Überzeugungen. Dazu können religiöse oder politische Überzeugungen gehören, aber Sie können auch nach Überzeugungen fragen, die direkt für die Funktionsweise Ihres Unternehmens relevant sind. Sie können sie beispielsweise bitten, zu bewerten, wie wichtig es ist, dass Support-Interaktionen persönlich sind.
- Fragenformate: Formatieren Sie Fragen zu Verhaltensweisen und Überzeugungen wie folgt: Staffeln. Der Bereich auf einer Skala kann uns dabei helfen zu verstehen, welche Skalenwerte korreliert sind und daher ungefähr im selben Cluster liegen. Ja/Nein und Fragen mit Einfachauswahl sind für die Cluster-Analyse nicht so nützlich. Beispiel: Wenn du fragst: „Was für ein Käufer bist du?“ und die Optionen „Einkauf in Einkaufszentren bevorzugen“, „Online-Shopping bevorzugen“ und „Einkaufen in Boutiquen bevorzugen“ anbieten, möchte der Clustering-Algorithmus die Teilnehmer in drei Gruppen einteilen, eine für jede Antwort. Wenn Sie diese stattdessen als eine Reihe von Fragen gestellt haben (z. B. „Mögen Sie in Einkaufszentren einkaufen?“) Mit Antworten 1 bis 7 wird der Clustering-Algorithmus eine bessere Arbeit leisten, um herauszufinden, was verschiedene Käufer voneinander trennt.
 Tipp: Multiple Antwortmöglichkeit Fragen sind die besten für das Sammeln skalarer Daten.
Tipp: Multiple Antwortmöglichkeit Fragen sind die besten für das Sammeln skalarer Daten. - Variablentypen: Wenn Sie bereit sind, in Stats iQ zu analysieren, stellen Sie sicher, dass Sie Ihre Variablen wie folgt formatieren: Kategorien oder Zahlen. Datumsangaben sind nicht mit der Cluster-Analyse kompatibel.
Tipp: Berücksichtigen Sie beim Anlegen Ihrer Variablen Variablen, von denen Sie bereits wissen, dass sie stark korreliert sind. Dies hilft Ihnen, bei der Cluster-Analyse an der Grenze von 10 Variablen zu bleiben.
Achtung: Die Cluster-Analyse hat eine maximale Stichprobe von 20.000 Antworten.
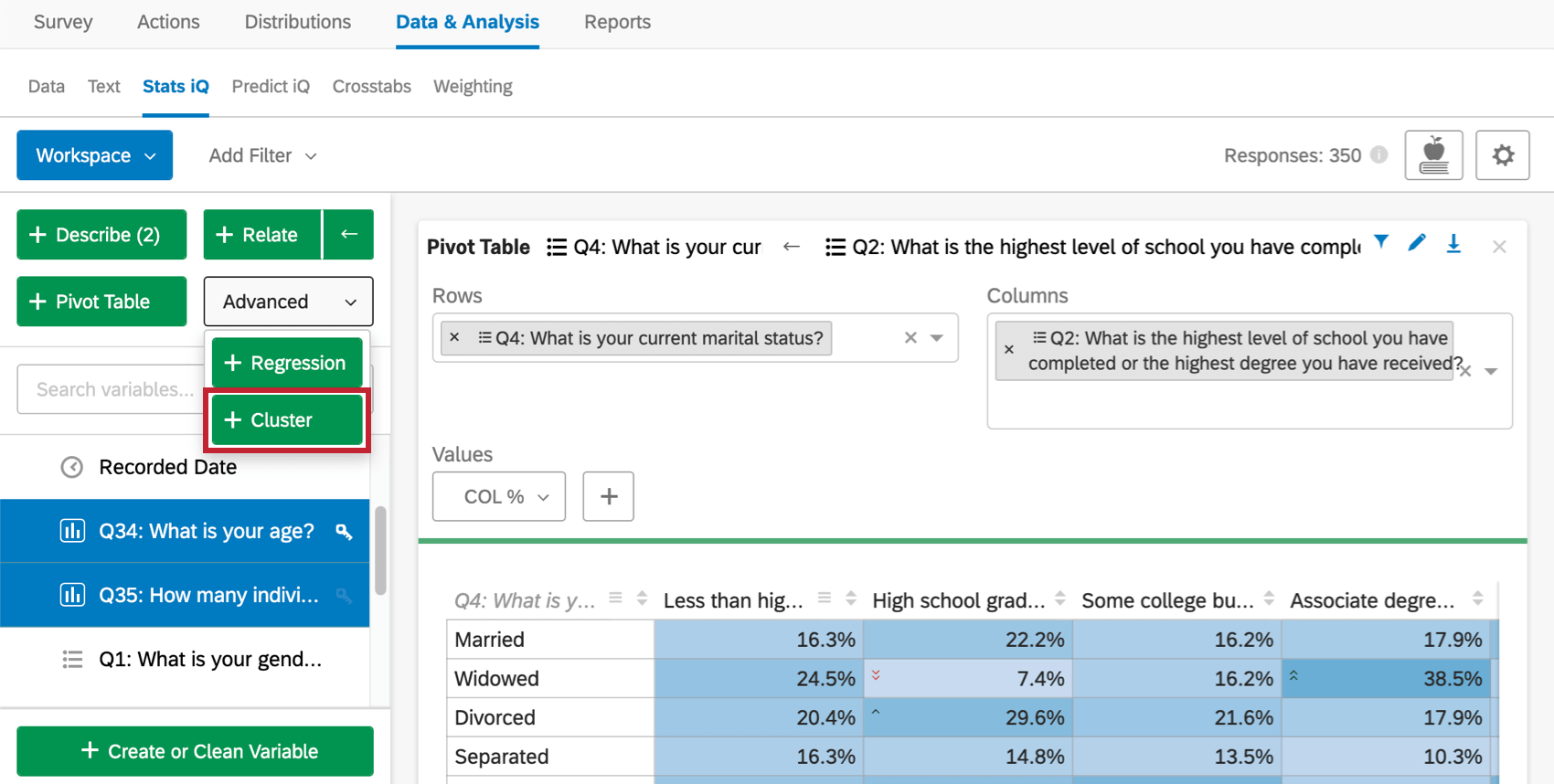
Cluster-Analyse durchführen
Tipp: Sie können eine Cluster-Analyse nur für 10 Variablen gleichzeitig durchführen. Wenn Sie mehr hinzufügen möchten, versuchen Sie, Variablen zu finden, die stark miteinander korrelieren, und erstellen Sie einen Durchschnitt davon mithilfe der Variable anlegen oder bereinigene.

Ergebnisse der Cluster-Analyse
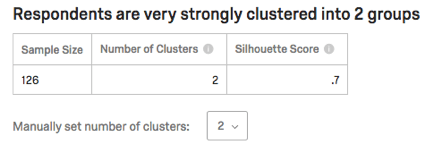
Stärke und Statiktabelle
Die Tabelle listet die Stichprobe (wie viele Teilnehmer Daten zu dieser Analyse beigetragen haben), die Anzahl der Cluster und den Silhouetten-Score auf. Der Silhouetten-Score wird in Phrasen wie „sehr stark“ im Satz oben interpretiert.
{kind=link}

Tipp: Weitere Informationen zum Silhouetten-Score, der in dieser Tabelle angezeigt wird, finden Sie im Abschnitt Interpretation der Cluster-Analyse.
Die Cluster-Analyse versucht, die entsprechende Anzahl von Clustern automatisch auszuwählen, indem die Dichtigkeit des Clusterings bei verschiedenen Zahlen bewertet wird, aber eine höhere Anzahl von Clustern bestraft wird, weil sie schwerer zu arbeiten ist. Die Wahl der richtigen Zahl ist mehr Kunst als Wissenschaft, und Sie sollten mit verschiedenen Zahlen experimentieren, um zu sehen, was am besten funktioniert.
In einigen Fällen kann der Algorithmus eine bestimmte Anzahl von Clustern nicht erzeugen und fällt auf eine kleinere Zahl zurück.
Cluster-Übersicht
Ihre Cluster werden im Abschnitt Cluster-Übersicht aufgeführt. Sie werden basierend auf den Fragen beschrieben, die Mitglieder des Clusters am ähnlichsten beantwortet haben.
{kind=link}

Beispiel: Cluster 1 in diesem Screenshot enthält Personen, die:
- Verheiratet
- Master-Abschlüsse haben
- Haben wenige Menschen (unmittelbare Familienmitglieder, Kinder) in ihrem Zuhause leben lassen
- Jung
Klicken Sie auf den Namen eines Clusters, um ihn umzubenennen.
Tipp: Die Umbenennung Ihrer Cluster ist wichtig, damit Ihre Ergebnisse in einem realen oder Marketingkontext sinnvoller sind.

{kind=link}
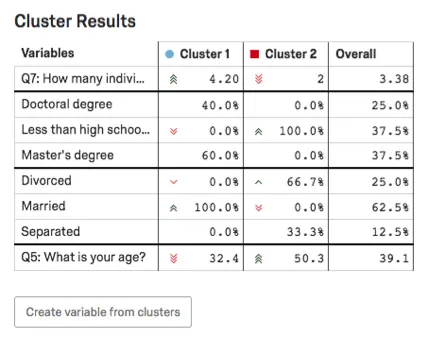
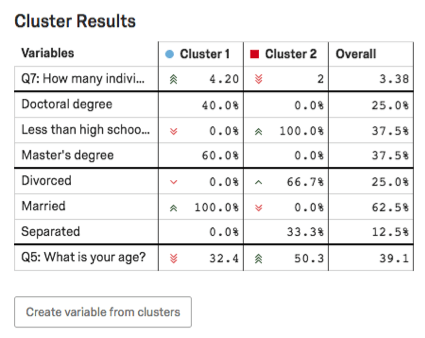
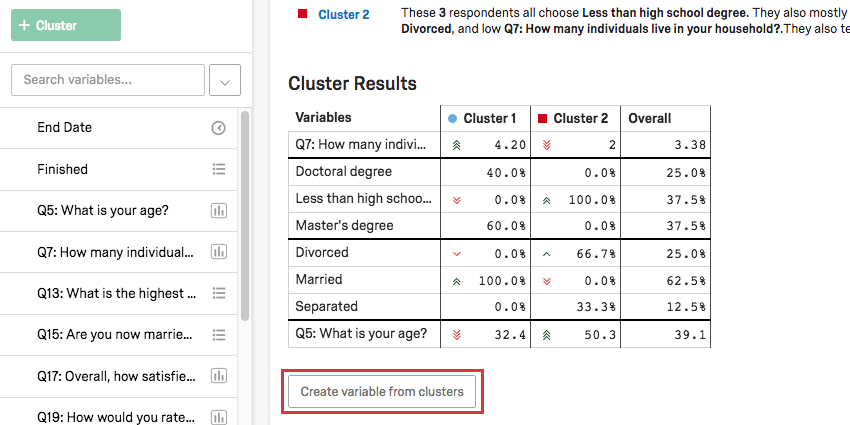
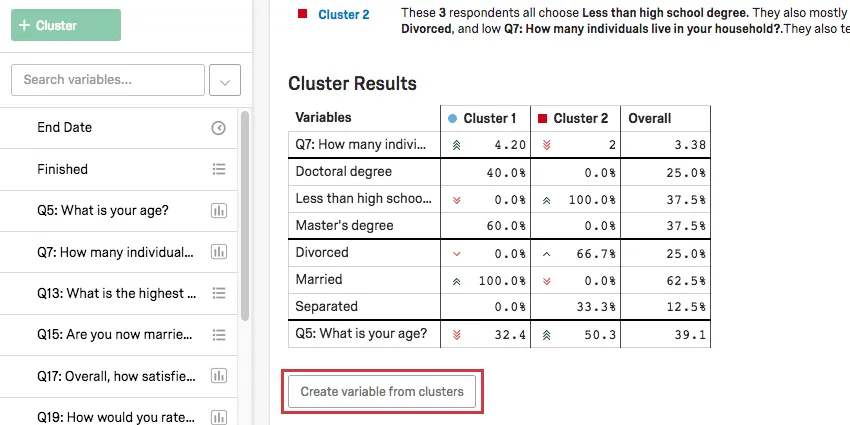
Ergebnisse
In der Ergebnistabelle werden die Hauptvariablen des Clusters hervorgehoben. Für kategorische Variablen werden die gängigste Option und der Prozentsatz der Teilnehmer im Cluster angegeben, die diese Antwort bereitgestellt haben. Für Zahlenvariablen wird eine durchschnittliche Antwort angezeigt.
Beispiel: In diesem Screenshot ist der Ebene kategorisch, daher sehen wir eine Aufschlüsselung der Prozentsätze der Befragten mit Doktorgrad vs. Weniger als die Ausbildung eines Gymnasiums vs. Masterabschlüsse.
Das Alter ist hier numerisch, sodass das Durchschnittsalter für jeden Cluster angezeigt wird (32,4 für Cluster 1, 50,3 für Cluster 2).
{kind=link}
mehr erfahren zum Anlegen von Variablen aus Clustern finden Sie im Abschnitt Variable aus Clustern anlegen.
Bedeutung der Variablen
Die Tabelle Variablenwichtigkeit zeigt die Stärke der Beziehung zwischen jeder Variablen und den Clustern an. Eine stärkere Beziehung zeigt an, dass die Variable beim Anlegen der Cluster wichtiger war.
Um dies zu berechnen, führen wir Regressionen für jede Variable aus. Beispielsweise würden wir das Alter im Vergleich zum Cluster-Ergebnis, die gearbeiteten Stunden im Vergleich zum Cluster-Ergebnis usw. ausführen.
Die aus diesen Regressionen resultierenden R-Quadrat-Werte werden dann so skaliert, dass das höchste R-Quadrat auf 1 gesetzt wird.
Beispiel: Angenommen, Q7 hatte ein R-Quadrat von 0,5, dem höchsten in der Gruppe. Wir müssen das verdoppeln, um es auf 1 zu setzen. Das bedeutet, wenn Q13 ein R-Quadrat von 0,4 hätte, würde es im Diagramm unten als 0,8 angezeigt werden.

{kind=link}
Neue Variablen aus Ergebnisse anlegen
Sobald Sie Cluster unter Ihren Umfrageteilnehmern ermittelt haben, können Sie diese Kategorien in neue Variablen umwandeln, die Sie in Stats iQ analysieren können.
Stellen Sie zunächst sicher, dass Benennen Sie Ihre Cluster um. indem Sie auf ihre Namen klicken.

Tipp: Der Umbenennungsschritt ist nicht erforderlich, macht Ihre Daten jedoch für Sie und Ihre Kollegen sauberer und verständlicher.
Sobald Ihre Cluster Namen haben, die für Sie sinnvoll sind, klicken Sie auf Variable aus Clustern anlegen unter der Ergebnistabelle. Dadurch wird Ihrer Variablenliste auf der linken Seite automatisch eine kategorische Variable hinzugefügt.
{kind=link}
Tipp: Diese Variable ist nur in Stats iQ verfügbar. Sie wird an keiner anderen Stelle in Ihren Qualtrics angezeigt.
Technische Hinweise
Die Cluster-Analyse in Stats iQ verwendet die Latent Class Analysis (LCA), um vom Benutzer bereitgestellte Daten in die zugrunde liegenden Cluster zu partitionieren. Im Gegensatz zu anderen Clustering-Algorithmen ermöglicht der Stats iQ das Clustern gemischter Datentypen (numerisch, kategorisch und binär).
Latente Klassenanalyse mit gemischtem Typ
Latent Class Analysis (LCA) ist ein wahrscheinlichkeitsbasiertes Clustering-Modell. Jeder Cluster wird durch eine Sammlung von Wahrscheinlichkeitsdichtefunktionen definiert, die basierend auf dem Wert der Variablen eines Datenpunkts die Wahrscheinlichkeit zurückgibt, dass ein bestimmter Datenpunkt zu diesem Cluster gehört.
Beispiel: Ihre Familie kann in einige Generationen aufgeteilt werden, wie die aktuellen Kinder, die Eltern und die Großeltern. Ein LCA-Modell würde diese drei Cluster darstellen, wobei jeder Cluster durch eine einzelne Wahrscheinlichkeitsfunktion basierend auf dem Alter definiert wird:
Cluster Wahrscheinlichkeitsfunktion Mittelwert Wahrscheinlichkeitsfunktion Standardabweichung Aktuell 25 7 Eltern 48 5 Großeltern 75 3 Um eine Person mit dem Wert 30 einem Cluster zuzuordnen, verwenden Sie diese Wahrscheinlichkeitsdichtefunktionen, um zu berechnen, dass sie eine Wahrscheinlichkeit von 44 % in Aktuell, <1 % Wahrscheinlichkeit in übergeordneten Elementen und <1 % Wahrscheinlichkeit in Großeltern haben. Diese Person wird ihrem wahrscheinlichsten Cluster, Current, zugeordnet.
Ein LCA-Modell kann auf mehrere Variablen angewendet werden, indem die Wahrscheinlichkeit, dass ein Datenpunkt zu einem Cluster gehört, basierend auf jeder Variablen multipliziert wird. Das Modell kann auf verschiedene Variablentypen angewendet werden, indem verschiedene Wahrscheinlichkeitsdichtefunktionen verwendet werden:
| Typ | Transformation | Wahrscheinlichkeitsdichtefunktion |
|---|---|---|
| Kategorisch | Dummy-kodiert (N-1) | Bernoulli |
| Binär | Bernoulli | |
| Numerisch | Normal |
Anzahl der Klassen ermitteln
Um die optimale Anzahl von Klassen zu ermitteln, verwendet Stats iQ einen BIC-Score.
Modellanpassung auswerten
Um das Ziel „Güte“ eines Modells zu bewerten, verwendet Stats iQ einen wahrscheinlichkeitsbasierten Silhouetten-Score. Ein Silhouetten-Score ist ein Maß dafür, wie gut jeder Datenpunkt in seinem Cluster liegt. Ein Silhouetten-Score misst die Ähnlichkeit eines bestimmten Punkts mit allen anderen Punkten in seinem Cluster und vergleicht dies mit der Ähnlichkeit mit allen Punkten in seinem nächsten Nachbar-Cluster. Um die Ähnlichkeit zwischen zwei Datenpunkten zu messen, berechnet Stats iQ die Zieldistanz (eine Entfernungsmetrik, die für binäre, kategorische und numerische Daten funktioniert) zwischen den Punkten.
FAQs
Wie kann ich meine neuen Antworten in Stats iQ anzeigen?
Wie kann ich meine neuen Antworten in Stats iQ anzeigen?
Was mache ich, wenn meine Daten nicht ordnungsgemäß geladen werden?
Was mache ich, wenn meine Daten nicht ordnungsgemäß geladen werden?
Großartig! Vielen Dank für die Rückmeldung!
Vielen Dank für die Rückmeldung!