-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Anonymität (EX)
Informationen zur Anonymität
Es gibt 2 Ebenen der Anonymität: grundlegende und erweiterte. Die grundlegende Anonymität ist in jedem Dashboard standardmäßig aktiviert, während die erweiterte Anonymität für zusätzliche Schutzschichten aktiviert werden kann. Weitere Informationen finden Sie unter Basis vs. Verbesserte Anonymität.
Alle Änderungen, die Sie in den Anonymitätseinstellungen vornehmen, werden sofort auf Ihr Dashboard angewendet.
Basis vs. Verbesserte Anonymität
Grundlegende Anonymität
Grundlegende Anonymitätsschwellenwerte legen fest, wie viele Antworten für einen bestimmten Datenpunkt eingeschlossen werden müssen, bevor sie in Ihrem Dashboard angezeigt werden können. Dies ist eine großartige Möglichkeit, die Privatsphäre der Antworten der Mitarbeiter zu schützen. Die Anonymitätsschwelle gilt für jeden Datenpunkt für Metriken (Günstigkeits-Score, Durchschnitt usw.), jedoch nicht für die Anzahl der Daten (Anzahl der Antworten).
Grundlegende Anonymität ist eine einfache Möglichkeit, Mitarbeitende zu schützen und gleichzeitig Flexibilität bei der Datenanalyse zu ermöglichen.
Beim Hinzufügen von Filtern zu einer Seite können Sie Werte unterhalb des Schwellenwerts auswählen, aber Sie sehen erst dann Daten, wenn der Gesamtwert aller in den Filtern ausgewählten Daten Ihre Anonymitätsschwelle erreicht. Siehe Filtern von Dashboards für weitere Informationen.
Wenn Sie Daten in einem einzelnen Feld herausbrechen, werden alle Metriken unterhalb der Anonymitätsschwelle ausgeblendet, und die Anzahl wird angezeigt. Wenn Sie Daten in mehreren Feldern herausbrechen, werden sowohl die Metriken als auch die Anzahl unterhalb der Anonymitätsschwelle ausgeblendet.
Antwortraten -Widgets zeigt die Anzahl unterhalb der Anonymitätsschwelle an.
Verbesserte Anonymität
Zusätzlich zu den Funktionen, die von der grundlegenden Anonymität abgedeckt werden, fügt die erweiterte Anonymität zusätzliche Schichten zu Filtern und Widget hinzu, die die Anonymität in bestimmten Anwendungsfällen verbessern können. Mit der erweiterten Anonymität gilt die Anonymitätsschwelle für alle Datenpunkte (Metriken und Zählungen) für sensible Felder, aber nicht für Datenpunkte für nicht sensible Felder.
Die verbesserte Anonymität bietet erweiterten Schutz für Mitarbeitende und bietet dadurch weniger Flexibilität bei der Datenanalyse.
Anonymitätsschwellenwerte
Die Anonymitätsschwelle bestimmt, wie viele Antworten für einen bestimmten Datenpunkt oder Kommentar eingeschlossen werden müssen, bevor sie in Ihrem Dashboard angezeigt werden können. Datenpunkte können so breit wie ein Widget oder spezifisch wie ein Balken innerhalb eines Diagramms sein.
Die Anonymitätsschwelle ist sowohl für Datenpunkte als auch für Kommentare auf 5 gesetzt.
Um Anonymitätsschwellenwerte anzuzeigen und zu ändern, führen Sie die folgenden Schritte aus:
- Klicken Sie beim Anzeigen Ihres Dashboard auf Einstellungen.
- Wechseln Sie zum Anonymität Registerkarte.
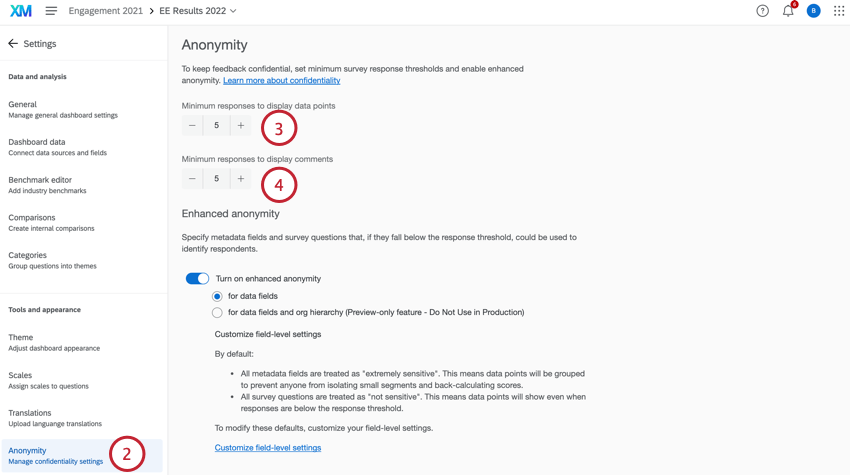
- Unter Minimale Antworten zum Anzeigen von Datenpunkten, Legen Sie fest, wie viele Antworten gesammelt werden müssen, bevor Daten in den Widgets angezeigt werden. Dieser Grenzwert wird auf alle Datenaufschlüsselungen in allen Widgets angewendet.
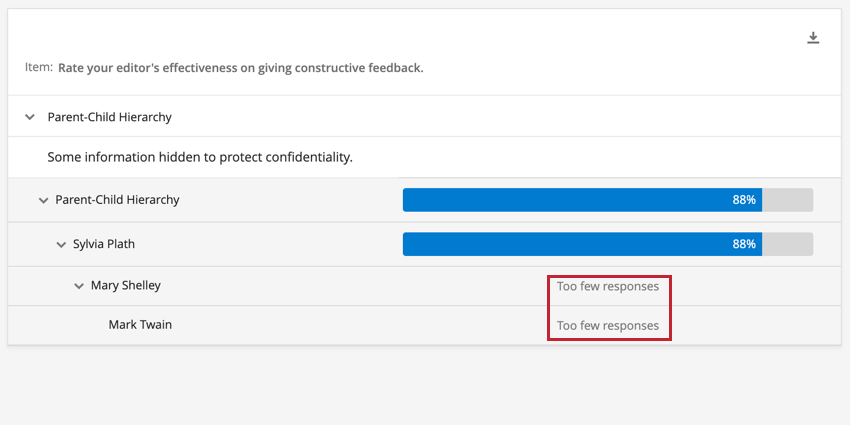
Beispiel: Die folgende Bild zeigt eineVergleich die von der aktiven Hierarchie aufgeschlüsselt wird. Wenn die Anzahl der Antworten unter dem Anonymitätsschwellenwert liegt, werden für diese Einheiten keine Daten im Widget angezeigt. Einheiten mit einer Antwortanzahl oberhalb des Anonymitätsschwellenwerts zeigen Daten wie gewohnt an. Da die Anzahl der Antworten für die Einheiten Mary Shelley und Mark Twain unter den Anonymitätsschwellenwert fällt, zeigt das Widget die Meldung „Zu wenige Antworten“ für diese Einheiten an.
- Unter
Minimale Antworten zum Anzeigen von Kommentaren, Legen Sie fest, wie viele Antworten gesammelt werden müssen, bevor freier Text in den Widgets angezeigt werden.
Aktivieren der erweiterten Anonymität
Die verbesserte Anonymität kann auf Ebene ein- und ausgeschaltet werden, um die Anonymität zu verbessern.
Angenommen, das Team von Barnaby hat 15 Personen. Wenn wir uns die Engagement-Ergebnisse für sein Team ansehen, wissen wir nicht wirklich, wie jedes Teammitglied auf Fragen zur Effektivität seines Manager:in geantwortet hat. Angenommen, es gibt nur 2 Frauen in seinem Team. Regelmäßige Anonymitätsschwellen werden sicherstellen, dass wir die Antworten der Frauen nicht direkt sehen können. Wenn wir jedoch einen Geschlechtsfilter hinzufügen, können wir ziemlich gut erraten, was jede Frau in seinem Team zu sagen hatte. Eine verbesserte Anonymität spürt solche Disparitäten. Dadurch wird sichergestellt, dass Daten aus Gruppen, die die Anonymitätsschwelle nicht erfüllen, mit der weiter Gruppe kombiniert werden, um ihre Antworten beim Aufschlüsseln von Daten oder Verwenden von Filtern auszublenden.
- Klicken Sie beim Anzeigen Ihres Dashboard auf Einstellungen.
- Wechseln Sie zum Anonymität Registerkarte.
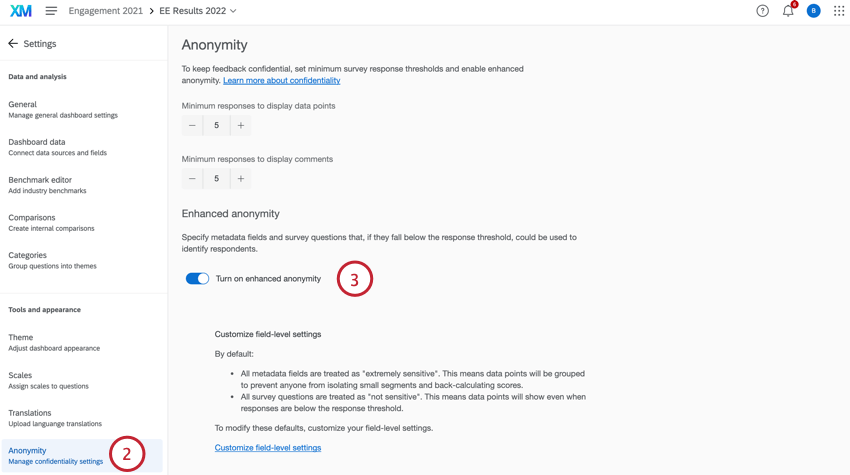
- Aktivieren Erweiterte Anonymität aktivieren.
Einstellungen auf Feldebene
Wenn Sie die erweiterte Anonymität aktiviert haben, können Sie die Ebene für jedes Feld in Ihrem Dashboard anpassen, indem Sie Felder als Äußerst empfindlich, Etwas sensibel, oder Nicht sensibel. Dies ändert die Art und Weise, wie Aufschlüsselungen in Widgets behandelt und angezeigt werden, und ermöglicht es Ihnen, Datenpunkte unterhalb des Antwortschwellenwerts in einigen Feldern zu gruppieren, während Sie Datenpunkte unterhalb des Antwortschwellenwerts für andere Felder ausblenden.
Es gibt möglicherweise einige Dashboard, die Teilnehmer durch identifiziert werden können, die als sensibel gelten und als äußerst sensibel oder etwas sensibel gekennzeichnet werden sollten, während Felder, die nicht sensibel sind, als nicht sensibel gekennzeichnet werden sollten. Beispielsweise können die Beschäftigungsdauer, das Geschlecht und das Team, zu dem jemand gehört, verwendet werden, um herauszufinden, wer er ist. Fragen, die in einer Employee Experience gestellt werden, sind jedoch fast immer nicht sensibel, mit Ausnahme demografischer Fragen wie Sprache, Bürostandort und Alter.
Wenn Felder als äußerst sensibel gekennzeichnet sind, werden die Daten von Gruppen, die die Anonymitätsschwelle nicht erfüllen, mit der weiter Gruppe kombiniert, um die Identitäten der Umfrageteilnehmer zu schützen. Wenn Felder als etwas sensibel gekennzeichnet sind, werden ihre Daten aus Gruppen, die die Anonymitätsschwelle nicht erfüllen, nicht angezeigt. Wenn Felder als nicht sensibel gekennzeichnet sind, erfolgt keine Gruppierung, es sei denn, Sie filtern oder brechen sie durch ein sensibles Feld aus.
Um zu bearbeiten, welche Felder sensibel sind und welche nicht, gehen Sie wie folgt vor:
- Gehe zu Einstellungen.
- Auswählen Anonymität.
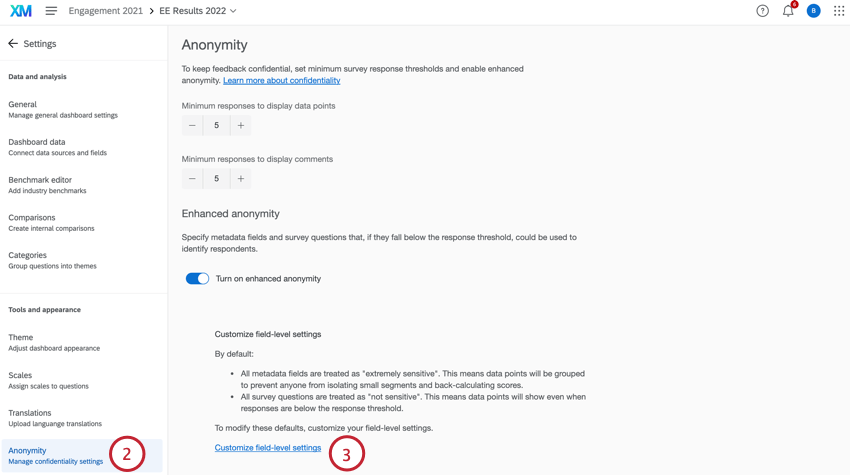
- Auswählen Einstellungen auf Feldebene anpassen.
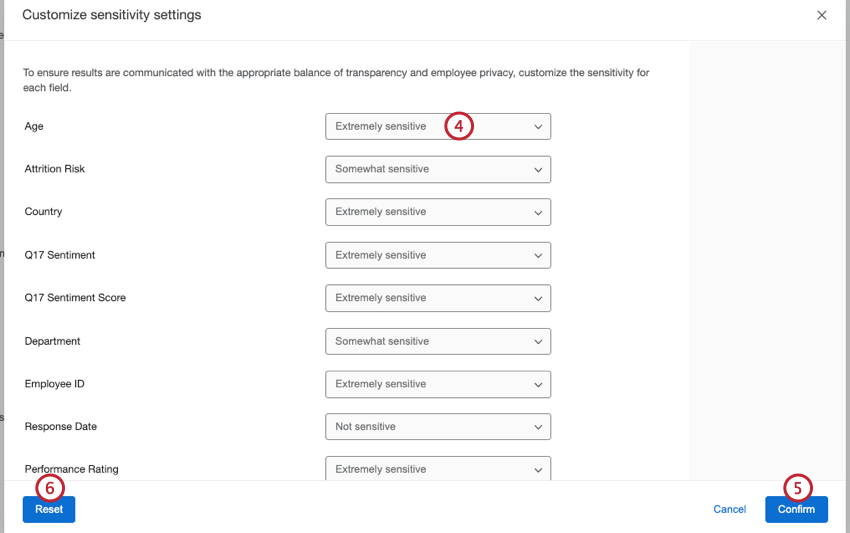
- Verwenden Sie die Dropdown-Liste weiter jedem Feld, um auszuwählen, wie sensibel es ist. Sie können zwischen folgenden Optionen wählen:
- Äußerst empfindlich: Diese Felder enthalten Informationen, die Teilnehmer identifizieren. Wenn ein Datenpunkt die Antwortschwelle unterschreitet, übernehmen erweiterte Anonymitätseinstellungen, und die Daten werden mit den weiter Datenpunkten gruppiert. Diese Felder wurden bisher als identifizierbare Felder bezeichnet.
Tipp: Alle Metadaten sind standardmäßig als äußerst sensibel gekennzeichnet.
- Etwas sensibel: Diese Felder enthalten Informationen, die Teilnehmer identifizieren können. Datenpunkte, die unter die Antwortschwelle fallen, werden nicht angezeigt, wie bei der grundlegenden Anonymität. Diese Option ist für Felder wie Datumsangaben oder Zeiträume nützlich.
Tipp: Mit dieser Option ist es weiterhin möglich, herauszufinden, welcher Teilnehmer:in eine bestimmte Antwort gegeben hat. Für mehr Sensibilität sollten Felder als äußerst sensibel gekennzeichnet werden.
- Nicht sensibel: Diese Felder enthalten keine Informationen, die Teilnehmer identifizieren können. Alle Datenpunkte werden auch dann angezeigt, wenn Antworten unter den Antwortschwellenwert fallen. Diese Felder wurden bisher als nicht identifizierbare Felder bezeichnet.
Tipp: Alle Fragefelder sind standardmäßig als nicht sensibel gekennzeichnet.
- Äußerst empfindlich: Diese Felder enthalten Informationen, die Teilnehmer identifizieren. Wenn ein Datenpunkt die Antwortschwelle unterschreitet, übernehmen erweiterte Anonymitätseinstellungen, und die Daten werden mit den weiter Datenpunkten gruppiert. Diese Felder wurden bisher als identifizierbare Felder bezeichnet.
- Klicken Sie auf Bestätigen.
- Um zur ursprünglichen Konfiguration zurückzukehren und alle Änderungen zu entfernen, wählen Sie Zurücksetzen.
Beispiel: In unserem Dashboard haben wir Verpflichtungsfragen nicht als identifizierbar gekennzeichnet, da sie nicht demografisch sind und nicht verwendet werden können, um ihre Umfrageteilnehmer in irgendeiner Weise zu identifizieren.

Angenommen, der Schwellenwert des Dashboard ist 5. Wenn wir eine Tabelle erstellt haben, die anzeigt, wie Mitarbeiter auf ein nicht identifizierbares Feld reagiert haben, wie „Ich bin stolz darauf, den Menschen zu sagen, wo ich arbeite“, werden die Antworten nicht gruppiert. Sehen Sie unten, wie „Stimme überhaupt nicht zu“ angezeigt wird, obwohl es nur eine Antwort hat.
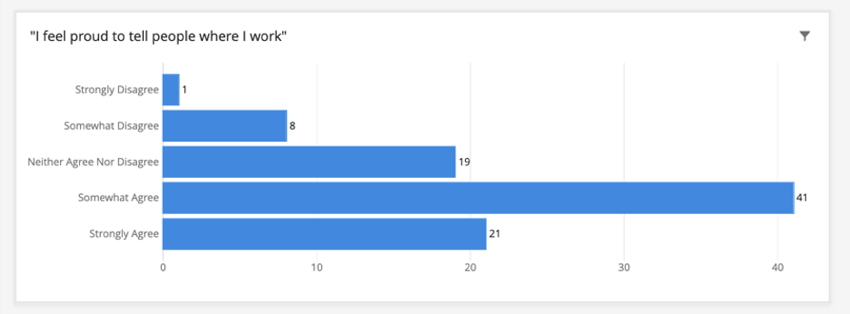
Beachten Sie, dass die Gesamtzahl der Antworten im Widget weiterhin den Schwellenwert erfüllen muss. Dieses Diagramm hat insgesamt 90 Antworten. Wenn es weniger als 5 hätte, wäre das Diagramm leer, da das Standardverhalten der Anonymitätsschwelle darin besteht, Daten aus Widgets auszublenden, die den Schwellenwert nicht erfüllen.
Feldinteraktionen
Wenn Sie eine Tabelle oder ein Diagramm verwenden, um ein extrem sensibles oder etwas sensibles Feld mit einem nicht sensiblen Feld anzuzeigen, sollten Ihre Daten auf die gleiche Weise gruppiert werden, wie Sie die Daten transponieren. Die Gruppierungslogik wird basierend auf den Feldeinstellungen konsistent angewendet, unabhängig davon, welches Feld als Zeile oder Spalte konfiguriert ist.
Dashboard(n)
Wenn Sie die erweiterte Anonymität verwenden, wenn Sie auch historische Quellen in Ihrem Dashboard ist es wichtig, Allgemeine Dashboard und beschränken Sie Seitenfilter nach den Daten des laufenden Jahres.
Andernfalls enthalten Dashboard mit Ausnahme des Hierarchie, der standardmäßig die primäre Datenquelle verwendet, Daten aus alle Datenquellen im Dashboard Daten. Das bedeutet, dass historische Daten in die Antwortanzahl einbezogen werden können und Anonymitätsgruppierungen verzerrt werden können. Wenn beispielsweise aktuelle und historische Ergebnisse für ein kleines Team und nicht nur für die Ergebnisse des laufenden Jahres gezählt werden, scheint das kleine Team größer zu sein, als es wirklich ist, und kann die Anonymitätsschwelle nicht unterschreiten. Das Einschränken der Filter auf die primäre Datenquelle (d.h. das aktuelle Projekt oder die Daten des aktuellen Jahres) behebt dieses Problem.
Filterverhalten
Sobald Sie Erweiterte Anonymität aktiviert und Ihrem Dashboard einen Filter hinzugefügt haben, bestimmen Ihre Anonymitätseinstellungen, wie sich Filter verhalten.
Das Verhalten des Seitenfilters hängt von der Einstellung auf Feldebene für jedes Feld:
- Nicht sensible Felder: In diesen Feldern können Sie einen beliebigen Wert auswählen, auch wenn er unter dem Schwellenwert liegt.
- Etwas sensible Felder: Mit diesen Feldern können Sie nur Werte auswählen, die den Schwellenwert erfüllen oder überschreiten.
- Äußerst sensible Felder: Diese Felder gruppieren alle Werte unterhalb des Schwellenwerts. Ergebnisse unterhalb des Schwellenwerts werden mit der weiter Option im Filter kombiniert, bevor eine Auswahl getroffen wird. Wenn Sie nur eine Gruppe haben, die unter den Schwellenwert fällt, wird diese mit der weiter Gruppe kombiniert, unabhängig davon, ob die weiter Gruppe den Schwellenwert erreicht oder nicht. Dadurch wird sichergestellt, dass ihre Daten auch dann geschützt werden, wenn nur eine Gruppe den Schwellenwert nicht einhält.
Da Filter hinzugefügt oder entfernt werden, Benutzerkonto die erweiterte Anonymität diese und ändert die Gruppierungen entsprechend.
Beispiel: Im Screenshot unten versuchen wir, nach Abteilung zu filtern. Dies ist ein kleines Unternehmen, daher haben Finanzen, Support und Ressourcen sehr kleine Teams, die unter der Anonymitätsschwelle liegen, die wir festgelegt haben.
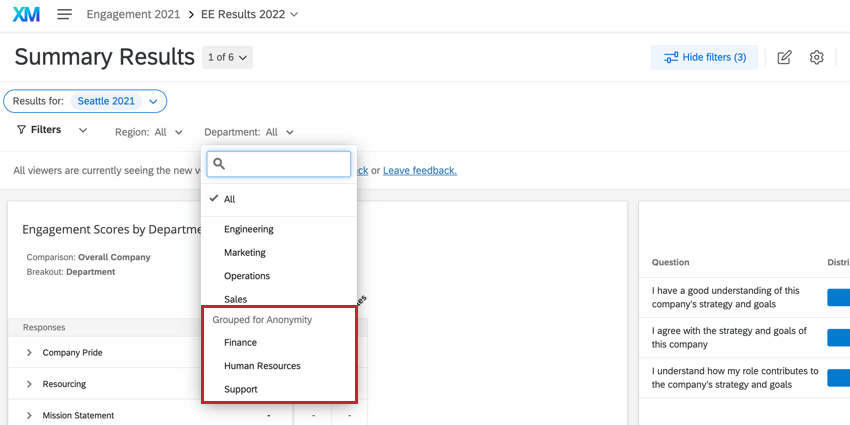
Sie sehen, dass sich Finanzen, Support und Ressourcen unter der Kopfzeile befinden. Gruppiert für Anonymität. Wenn ich versuche, nur eine auszuwählen, werden beide automatisch ausgewählt. Wenn ich versuche, eine zu entmarkieren, werden beide entmarkiert. Dadurch wird verhindert, dass Benutzer die Werte untergeordneter Schwellenwertgruppen ermitteln.
Hierarchie
Organisationshierarchie, die die Anonymitätsschwelle nicht einhalten, werden ausgegraut und haben weiter ihnen ein Sperrsymbol. Sie können keine Einheiten auswählen, die die Anonymitätsschwelle nicht erfüllen. Damit soll die Anonymität der Befragten geschützt werden.
![]()
Aufschlüsselung
Wenn die erweiterte Anonymität aktiviert ist, Einstellungen auf Feldebene Legen Sie für jedes Feld fest, wie Daten in Widgets angezeigt werden, in denen Daten in bestimmte Gruppen aufgeteilt wurden. Dazu gehören Linien-Widgets, für die eine X-Achsendimension definiert wurde, Widgets mit Vergleiche hinzugefügt, demografische Aufschlüsselung, Heatmap und jede andere Widget, die Gruppen isoliert, die kleiner als der Anonymitätsschwellenwert sein können.
- Nicht sensible Felder: In diesen Feldern werden alle Datenpunkte (Metriken und Anzahl) angezeigt, auch wenn sie unter dem Schwellenwert liegen.
- Etwas sensible Felder: In diesen Feldern werden nur Datenpunkte (Metriken und Anzahl) angezeigt, die den Antwortschwellenwert erreichen oder überschreiten.
- Äußerst sensible Felder: Diese Felder gruppieren alle Datenpunkte (Metriken und Anzahl) unterhalb des Schwellenwerts.
Ausnahmen von dieser Regel sind Widgets, die nach Organisationshierarchie aufgeschlüsselt sind. Einige Widgets (Heatmap, demografische Aufschlüsselung) unterstützen eine Aufschlüsselung Ebene darunter, die Daten für jede untergeordnete Einheit der aktuell ausgewählten Einheit im Organisationshierarchie anzeigt. Andere Widgets (Antwortraten, Vergleich, Blasendiagramm) unterstützen Drilldowns in die Hierarchie und zeigen Daten für jede Einheit an, sodass der Benutzer sie auswählen kann. Für Widget, die nach Organisationshierarchie aufgeschlüsselt sind, wird die erweiterte Anonymität nicht angewendet. Das bedeutet, dass keine Einheiten für die Anonymität gruppiert werden.
Wenn Sie die Kennzahl in einen durchschnittlichen Interaktions-Score oder einen NPS ändern würden, würde eine verbesserte Anonymität Sie daran hindern, die Daten des kleinsten Büros zu ermitteln, da Dashboard die Daten dieses Büros nicht isolieren können. Dies ist beispielsweise dann sinnvoll, wenn wir nicht möchten, dass die Bewertungen jedes Mitglieds des kleinsten Büros leicht berechnet werden.
Beispiel:
Im folgenden Beispiel ist für unser Dashboard eine Anonymitätsschwelle für das Feld „Land“ festgelegt, um Antworten von Mitarbeitern in kleinen Büros zu schützen. Im Widget unten haben wir die Y-Achsendimension eines Balkendiagramm als das Land festgelegt, in dem sich das Büro des Mitarbeitende befindet. Australien und Mexiko haben sehr kleine Büros, unterhalb der Anonymitätsschwelle, die wir festgelegt haben. Infolgedessen wurden ihre Antworten kombiniert.
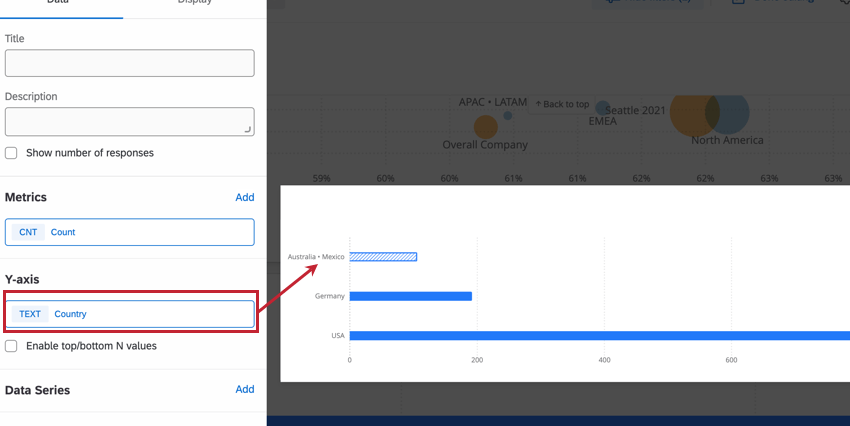
Wenn Sie die Kennzahl in einen durchschnittlichen Interaktions-Score oder einen NPS ändern würden, würde eine verbesserte Anonymität Sie daran hindern, die Daten des kleinsten Büros zu ermitteln, da Dashboard die Daten dieses Büros nicht isolieren können. Dies ist beispielsweise dann sinnvoll, wenn wir nicht möchten, dass die Bewertungen jedes Mitglieds des kleinsten Büros leicht berechnet werden.
Mehrere Aufschlüsselungen
Einige Widgets werden bei mehreren Dimensionen aufgelöst, z.B. Linien- und Balken-Widgets Sie können sowohl einen X-Achsenwert als auch eine Datenreihe hinzufügen und Tabellen Hiermit können Sie sowohl Zeilen als auch Spalten hinzufügen.
Je mehr Sie Daten aufschlüsseln, desto kleiner kann jede Kategorie werden, und desto mehr Kategorien werden unter Anonymität gruppiert. Da es nun zwei Dimensionen für die Aufschlüsselung gibt, kann es verschiedene Kombinationen von Kategorien geben, die aus Gründen der Anonymität gruppiert werden müssen. Daher werden Kategorien, die für die Anonymität gruppiert sind, gekennzeichnet. Gruppiert für Anonymitätund Sie können den Mauszeiger darüber bewegen, um zu ermitteln, welche bestimmten Kategorien gruppiert wurden.
Sie werden auch feststellen, dass Anonymitätsgruppen in der Legende als Gruppiert für Anonymität, kein zusammengesetzter Name. Dabei soll Benutzerkonto werden, wie sich Gruppierungen ändern können, je nachdem, wie mehrere Aufschlüsselungen interagieren, und um zu lange Bezeichner zu verhindern.
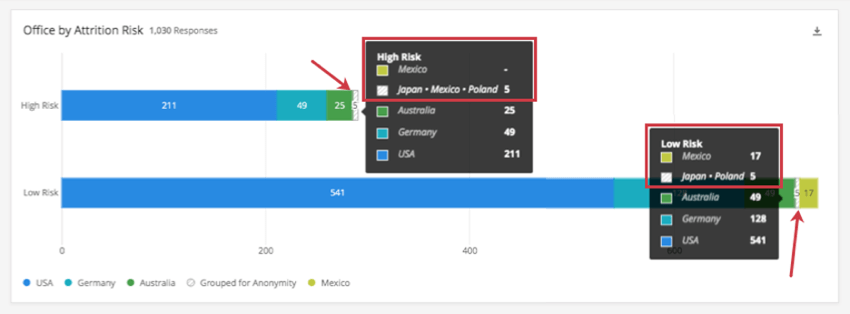
Beispiel: Dieses Dashboard hat einen Schwellenwert von 5. In der folgenden Grafik haben wir die Länder, in denen unsere Mitarbeiter arbeiten, durch Fluktuationsrisiken aufgelöst. Wir sehen einen hellgrünen Block für Mexiko in der Leiste Niedriges Risiko, aber nicht in der Leiste Hohes Risiko.
Wenn wir die Blöcke Gruppiert für Anonymität für jeden Balken Hervorhebung, stellen wir fest, dass es einen Unterschied gibt: Mexiko wurde mit Japan und Polen in der Leiste Hohes Risiko gruppiert, aber nur Japan und Polen wurden in der Leiste Niedriges Risiko gruppiert.
Sehen Sie sich den Screenshot unten an. In Hohes Risiko, Mexiko hat keine individuellen Daten ( – ), aber Japan + Mexiko + Polen zeigt Daten an, da diese aus Gründen der Anonymität gruppiert sind (5). Unter Geringes Risiko, Mexiko erfüllt den Schwellenwert, sodass er nicht gruppiert werden muss und einzelne Daten (17) anzeigt, während Japan + Polen gruppiert werden (5).
Grundlegende Anonymität
Wenn Sie Daten durch zwei oder mehr Felder mit grundlegender Anonymität aufschlüsseln, wird jedes der Aufschlüsselung berücksichtigt. separat. Beim Zerlegen von Daten in mehreren Feldern werden Metriken und Zähldatenpunkte unterhalb des Schwellenwerts ausgeblendet.
Die einfache Anonymität zählt Antworten ohne Wert (leer/null) nicht, wenn die Antwortanzahl mit der Anonymitätsschwelle verglichen wird. Dies dient dem Schutz von Fällen, in denen Umfrage, die möglicherweise nicht berechtigt sind, eine Frage zu beantworten (z. B. lautet Umfrage, dass nur Vorgesetzte eine Frage beantworten können), ihre Antworten auf die Anonymitätsschwelle angerechnet haben.
Verbesserte Anonymität
Die erweiterte Anonymität zählt Antworten ohne Werte (leer/null) beim Vergleich der Antwortanzahl mit der Anonymitätsschwelle.
Das Verhalten bei der Aufschlüsselung Felder hängt von der Einstellungen auf Feldebene für die beiden beteiligten Felder. Diese Tabelle zeigt, wie Daten für doppelte Aufschlüsselungen zwischen verschiedenen Feldtypen ausgeblendet werden.
| Nicht sensibel | Etwas sensibel | Äußerst sensibel | |
| Nicht sensibel | Alle Datenpunkte (Metriken und Anzahl) werden angezeigt. | Werte aus dem etwas sensiblen Feld werden ausgeblendet, wenn sie unter dem Schwellenwert liegen. | Werte aus dem extrem sensiblen Feld werden gruppiert, wenn sie unter dem Schwellenwert liegen. |
| Etwas sensibel | Werte aus dem etwas sensiblen Feld werden ausgeblendet, wenn sie unter dem Schwellenwert liegen. | Alle Datenpunkte (Metriken und Anzahl) unterhalb des Antwortschwellenwerts werden ausgeblendet. | Werte aus dem etwas sensiblen Feld werden ausgeblendet, wenn sie unter dem Schwellenwert liegen, und Werte aus dem extrem sensiblen Feld werden gruppiert, wenn sie unter dem Schwellenwert liegen. |
| Äußerst sensibel | Werte aus dem extrem sensiblen Feld werden gruppiert, wenn sie unter dem Schwellenwert liegen. | Werte aus dem etwas sensiblen Feld werden ausgeblendet, wenn sie unter dem Schwellenwert liegen, und Werte aus dem extrem sensiblen Feld werden gruppiert, wenn sie unter dem Schwellenwert liegen. | Datenpunkte unterhalb des Antwortschwellenwerts werden gruppiert. |
Verhalten der Rücklaufquoten
Die Antwortraten zeigen an, wie viele Antworten Sie erhalten haben und wie viel Prozent Ihrer Teilnehmer:in die Umfrage abgeschlossen hat. Diese Art von Daten wird von Teilnahmezusammenfassung und Antwortrate Widgets.
Standardmäßig betrachtet das Dashboard Antwortraten als vertrauliche Informationen. Das bedeutet, dass Antwortrate verwendet werden können, um Teilnehmer zu identifizieren, und um Ihre Teilnehmer zu schützen, müssen die Antwortraten nach Anonymität gruppiert werden.
Im Folgenden haben wir unsere Rücklaufquoten nach Ländern aufgeschlüsselt, was dazu geführt hat, dass Australien, Deutschland und Mexiko nach Anonymität gruppiert wurden.
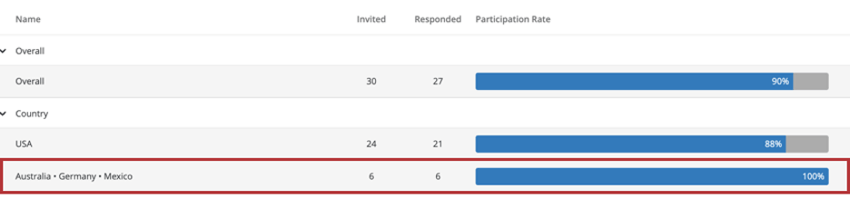
Daher zeigen Antwortrate dasselbe an. Aufschlüsselung andere Widgets. Wenn die Anzahl der Antworten unter dem Schwellenwert liegt, werden im Widget keine Daten angezeigt.
Wenn die erweiterte Anonymität aktiviert ist, hängt das Verhalten der Antwortraten von der Einstellung auf Feldebene für jedes Feld:
- Nicht sensible Felder: Diese Felder zeigen alle Datenpunkte an, auch wenn sie unter dem Schwellenwert liegen.
- Etwas sensible Felder: Diese Felder zeigen nur Datenpunkte an, die den Antwortschwellenwert erreichen oder überschreiten.
- Äußerst sensible Felder: Diese Felder gruppieren alle Datenpunkte unterhalb des Schwellenwerts.
Anonymitätseinstellungen für die gesamte Organisation
Sie können die Anonymitätsschwelle für Ihre gesamte Organisation festlegen, um sicherzustellen, dass alle EX denselben Datenschutzstandard erfüllen. Siehe Anonyme Antworten (Admin).