-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Conjoint-Clustering
Conjoint-Clustering im Überblick
Innerhalb der Umfrage sind Gruppen gleichgesinnter Personen. Diese Gruppen oder „Cluster“ können dadurch bestimmt werden, wie ähnlich das optimale Paket jedes Befragte:r ist. Indem wir jeden Befragte:r basierend auf seinem individuellen Nutzen für jedes Attribut gruppieren, können wir Teilpopulationen ermitteln und bestimmen, aus welchen demografischen Daten diese Teilpopulationen bestehen.
Vorbereiten einer Umfrage für das Clustering
Bevor Sie das Conjoint-Clustering verwenden können, müssen Sie sicherstellen, dass die Umfrage Ihres Conjoint-Projekt die richtigen Fragen stellt. Das bedeutet, dass Sie bestimmte Funktionen einrichten müssen, vor sammeln Sie Daten.
In der Reiter Umfrage“stellen Sie sicher, dass Sie hat Fragen hinzugefügt zu einem Nicht-Conjoint-Block. Im Beispiel unten enthält der Block „Demografie“ eine Frage zum Alter, zur Anzahl der Personen im Haushalt des Befragte:r usw.
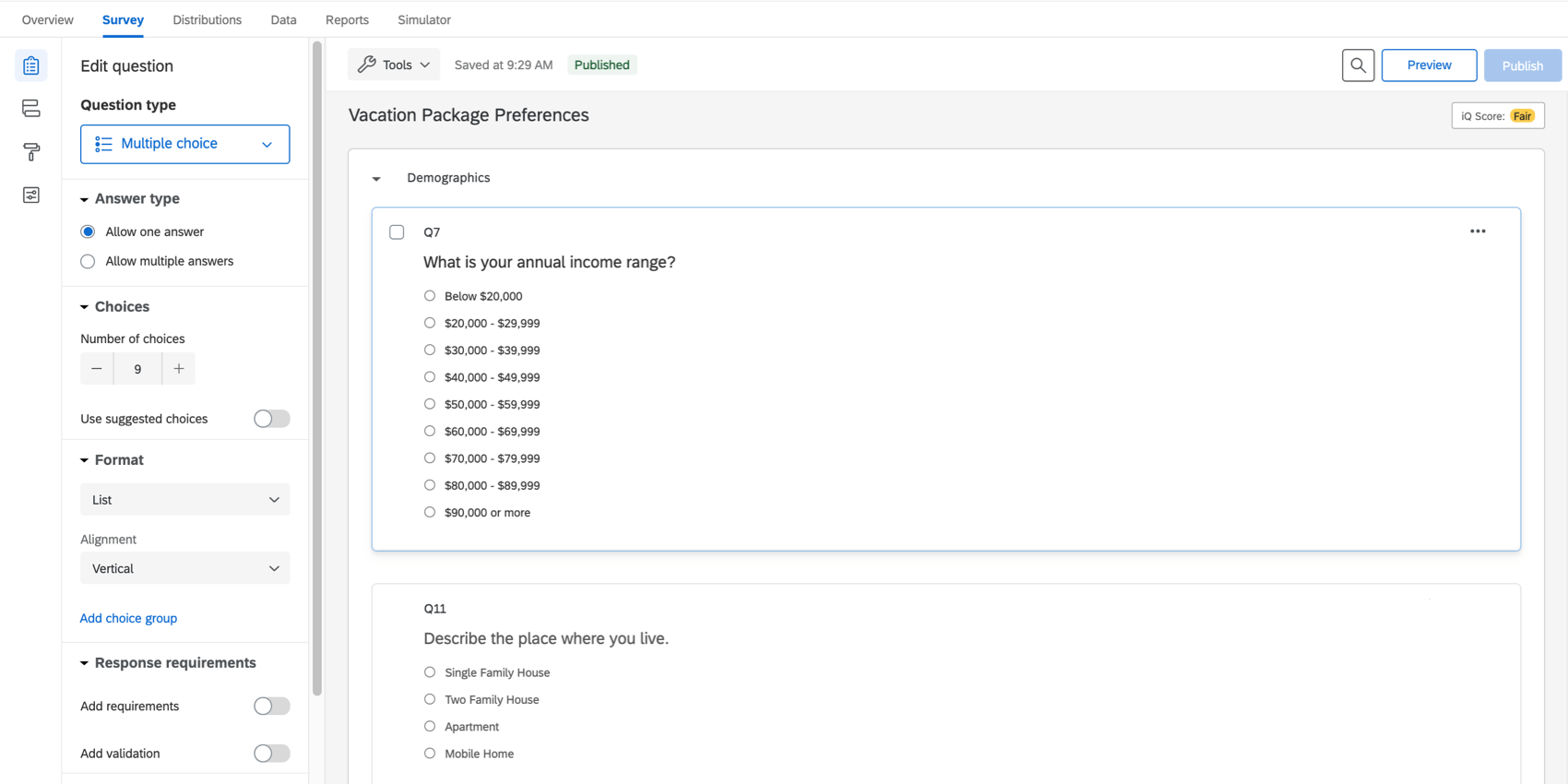
Der Block Demografie befindet sich direkt über dem Conjoint-Block, Sie können ihn jedoch nach Bedarf verschieben.
Fragenformatierung
Sie können das Conjoint-Clustering nur mit Einzelantwort durchführen. Multiple Choice Fragen. Dies liegt daran, dass sie eine begrenzte Auswahl an Auswahlmöglichkeiten bieten, die leicht analysiert werden können. Sie können auch einige Umfrage wie Startdatum, IP, Empfänger:in usw. verwenden.
- Demografie: Fragen Sie nach grundlegenden beschreibenden Informationen wie Alter, Einkommensklasse, Rasse oder Geschlecht.
- Verhalten: Fragen Sie, wie Kunden mit Ihrer Instanz und Ihren Produkten interagieren oder nach Verhaltensweisen, die sich auf ihr Kaufverhalten beziehen können. Sie können beispielsweise fragen, wie oft der Kunde einkaufen geht.
- Operativ Daten: Dies sind Informationen wie die auf Ihrer Website aufgewendete Zeit oder die Beschäftigungsdauer eines Mitarbeitende in Ihrem Unternehmen.
- Fragenformate: Formatieren Sie Fragen zu Verhaltensweisen und Überzeugungen wie folgt: Staffeln. Der Bereich auf einer Skala kann uns dabei helfen zu verstehen, welche Skalenwerte korreliert sind und daher ungefähr im selben Cluster liegen. Ja/Nein und Fragen mit Einfachauswahl sind für die Cluster-Analyse nicht so nützlich.
Beispiel: Wenn du fragst: „Was für ein Käufer bist du?“ und die Optionen „Einkauf in Einkaufszentren bevorzugen“, „Online-Shopping bevorzugen“ und „Einkaufen in Boutiquen bevorzugen“ anbieten, möchte der Clustering-Algorithmus die Teilnehmer in drei Gruppen einteilen, eine für jede Antwort. Wenn Sie diese stattdessen als eine Reihe von Fragen gestellt haben (z. B. „Mögen Sie in Einkaufszentren einkaufen?“) Mit Antworten 1 bis 7 wird der Clustering-Algorithmus eine bessere Arbeit leisten, um herauszufinden, was verschiedene Käufer voneinander trennt.
Cluster aktivieren
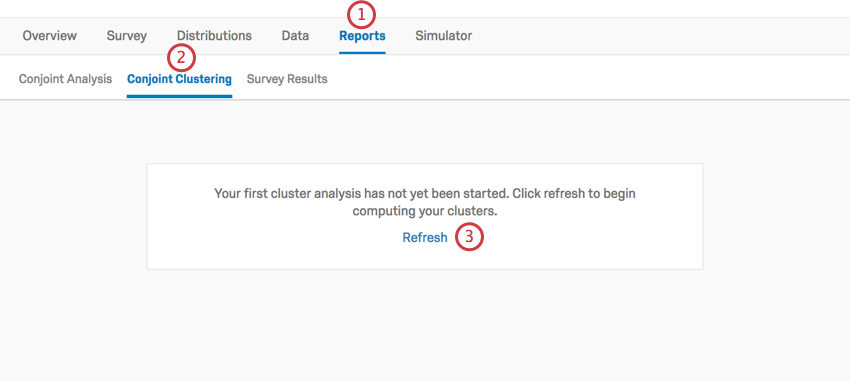
- Wechseln Sie zum Berichte Registerkarte Ihres Conjoint-Kontos.
- Auswählen Conjoint-Clustering.
- Wenn Sie diese Registerkarte zum ersten Mal aufrufen, müssen Sie möglicherweise auf Aktualisieren um die Cluster-Berechnungen zu starten.
Anpassung der im Clustering verwendeten Demografie
Standardmäßig verwendet das Conjoint-Clustering alle Multiple Choice, die Sie gestellt haben. Sie müssen jedoch nicht jede Frage verwenden, wenn Sie dies nicht möchten, und Sie können Inhalte hinzufügen und entfernen, um zu sehen, welche verschiedenen Cluster diese Funktion Ihnen empfiehlt.
& hinzufügen; Demografie entfernen
In der Box rechts neben dem Cluster-Details Kopf eine Frage aus, um sie zur Clusteranalyse hinzuzufügen oder daraus zu entfernen. Wenn Sie eine Frage entfernen, werden die Cluster nicht neu berechnet.
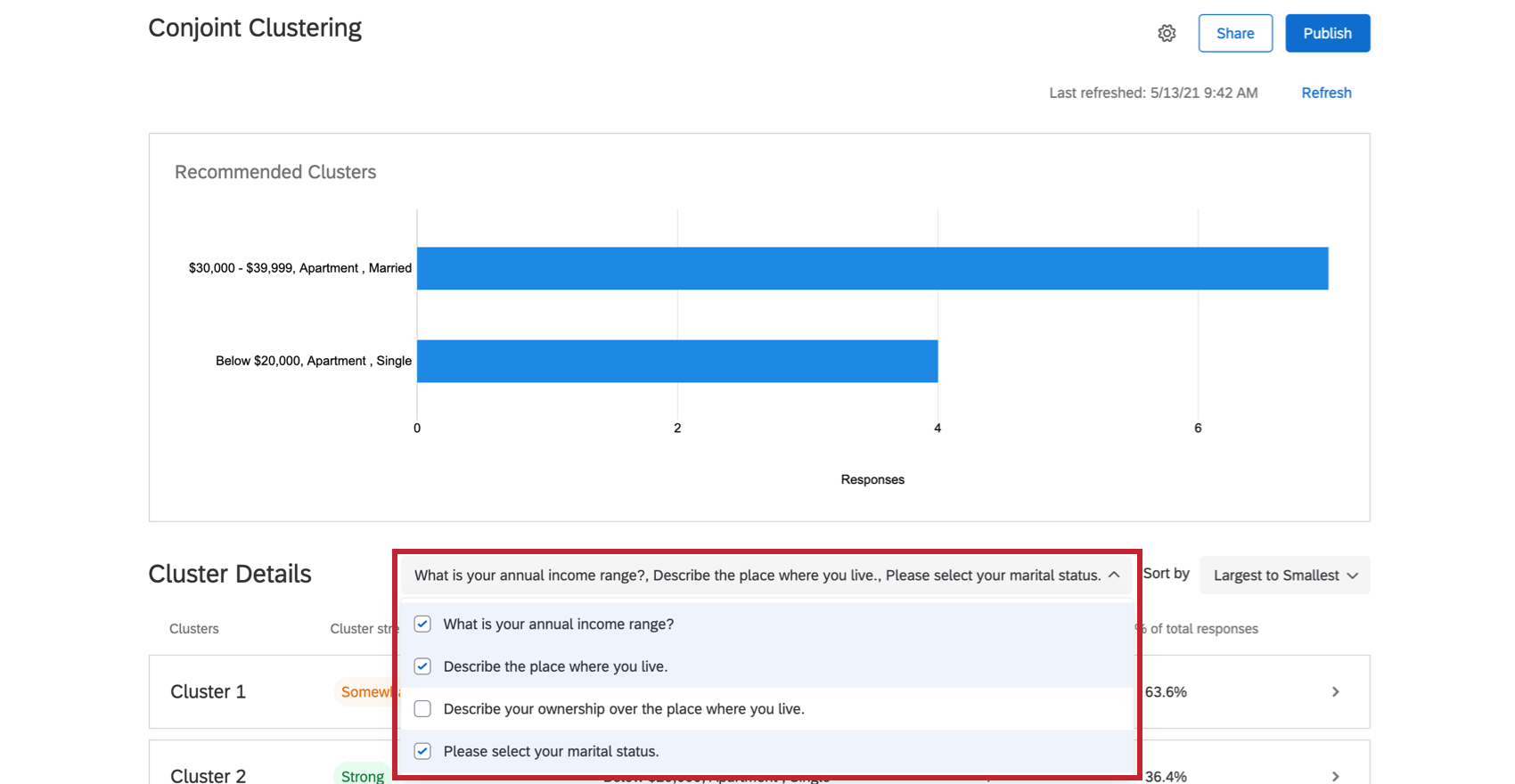
Empfohlene Cluster
Sobald Sie genügend Daten gesammelt und Ihre Ergebnis-Clustering-Seite aktualisiert haben, empfiehlt Ihnen diese Funktion Cluster. Diese Cluster werden basierend darauf ermittelt, wie ähnlich das optimale Paket der Teilnehmer ist. Der individuelle Nutzen für jedes Attribut wird berechnet. Anschließend werden die in diesen Clustern gemeinsamen Demografien hervorgehoben, sodass Sie besser verstehen können, wie verschiedene Populationen Ihre Produkte bevorzugen.
Hervorhebung einen Cluster im oberen Diagramm, um mehr erfahren. Klicken Sie darauf, um die Cluster-Details unten zu öffnen.
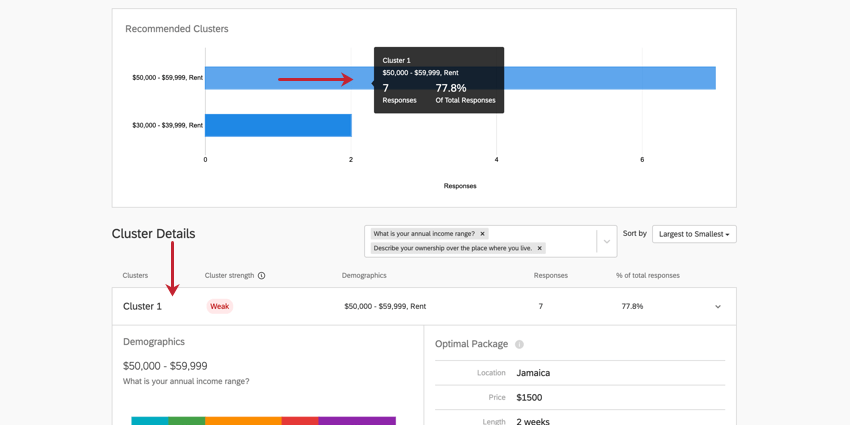
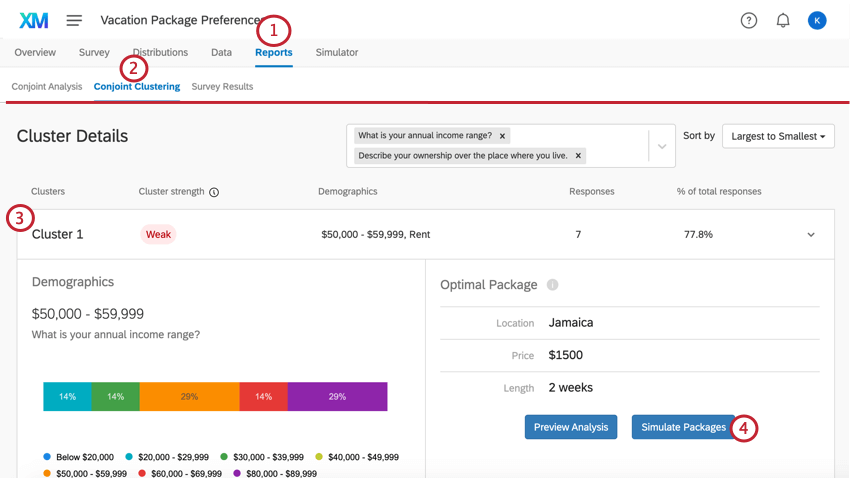
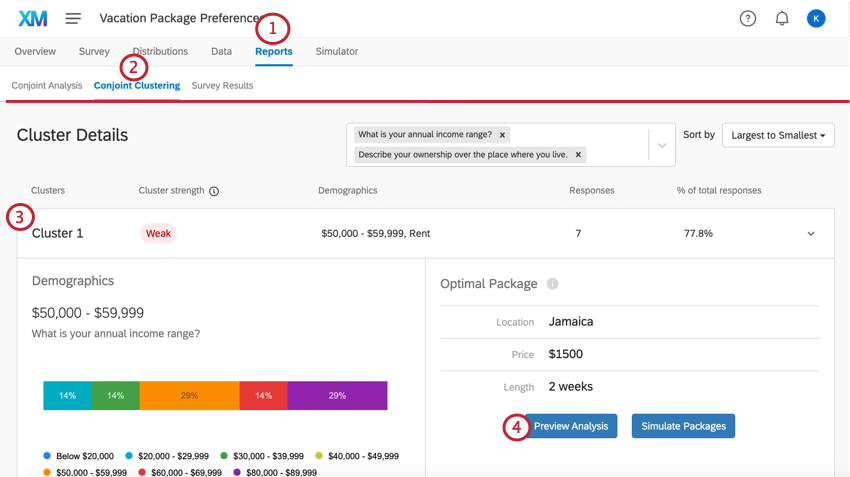
Cluster-Details
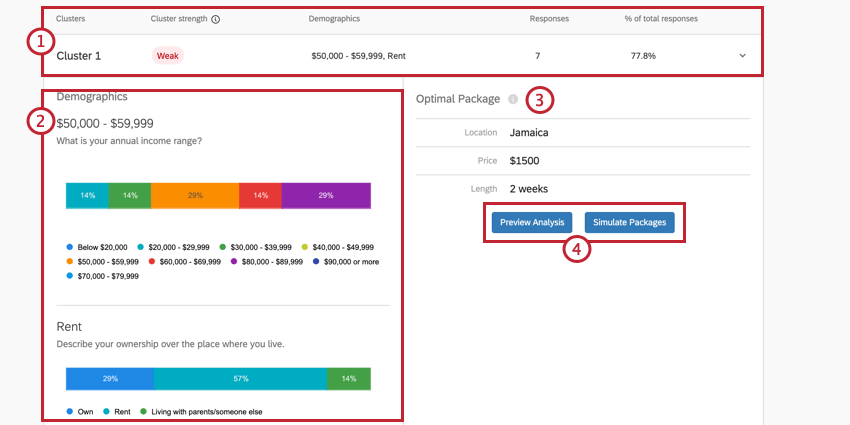
- Zusammenfassung: Die obere Leiste der Cluster-Details bietet eine kurze Zusammenfassung der wichtigsten Details, in erster Linie der Cluster, die statistische Bedeutung des Clusters, die allgemeine Beantwortung der demografischen Fragen durch die Umfrageteilnehmer, die Anzahl der Antworten in diesem Cluster und den Prozentsatz der Antworten, für die dieser Cluster gilt. Sie können auch auf diesen Teil klicken, um die rest Informationen zu expandieren und zu komprimieren.
Beispiel: In Cluster 1, das hier dargestellt wird, stammen die Antworten in der Regel von Leuten, die 50.000 bis 59.999 $ pro Jahr machen, die Wohnungen mieten und ledig sind. Die Cluster-Stärke ist schwach, was bedeutet, dass der Cluster nicht statistisch signifikant ist. 7 Teilnehmer passen in der Regel zu diesem Muster, was 77,8 % des gesamten Datensatzes entspricht. Dies ist ein sehr kleiner Datensatz, daher sollten Entscheidungen wahrscheinlich nicht auf der Grundlage dieser Ergebnisse getroffen werden.
- Demografie: Eine Reihe von Aufschlüsselungsbalken, die anzeigen, wie die Mitglieder dieses Clusters auf die demografischen Fragen reagiert haben. Jede Strukturdiagramm wird durch die Antwort gekennzeichnet, die am ehesten mit den Utility-Scores für die Attribute des optimalen Pakets korreliert. Sie sehen jedoch, dass Personen in einem Cluster je nach Antwort variieren.
Beispiel: Die bevorzugte Wohnanordnung von Cluster 1 ist eine Wohnung. Wohnungen werden jedoch nicht als häufigste Antwortmöglichkeit für dieses Cluster aufgeführt. Das liegt daran, dass diejenigen, die in Wohnungen leben, einfach eher einen Urlaub nach Jamaika für 2 Wochen zu $ 1500 gewählt haben, um das bestmögliche Paket zu sein als diejenigen im Cluster, die andere Wohnverhältnisse haben.
- Optimales Paket: Dies ist das beste Paket für die Mitglieder des Clusters. Die hervorgehobenen Demografien haben hohe Nützlichkeitswerte für die hier ausgewählten Attribute.
- Vorschau der Analyse und Pakete simulieren: Klicken Sie auf diese Schaltflächen, um die Ergebnisse und Simulator nur für die Daten dieses Clusters.
Clusterstärke ermitteln
Qualtrics verwendet eine Kennzahl namens Punktewertung, um die Stärke jedes Clusters zu ermitteln. Diese Bewertung ergibt einen Wert zwischen 0 und 1, der bestimmt, wie eng die Teilnehmer geclustert sind. Wir verwenden die folgende Tabelle, um von Silhouetten-Score zu Cluster-Stärke zu konvertieren:
| Korrelationswert | Beziehung | Cluster-Strength-Label |
| 0,71 bis 1,0 | Sehr starke Beziehung | Stark |
| 0,51 bis 0,70 | Eher starke Beziehung | Eher stark |
| 0,26 bis 0,50 | Etwas schwache Beziehung | Eher schwach |
| 0 bis 0,25 | Keine signifikante Beziehung | Schwach |
Cluster auf Berichte und den Simulator anwenden
Cluster können auf die Ergebnisse und die Simulator So können Sie spezifischere Details darüber anzeigen, wie Teilnehmer in diesem Cluster die ihnen präsentierten Attribute bewertet haben.
Conjoint-Analyse
Während Sie im Conjoint-Analyse Abschnitt des Berichte einen Cluster aus der Dropdown-Liste oben links aus.
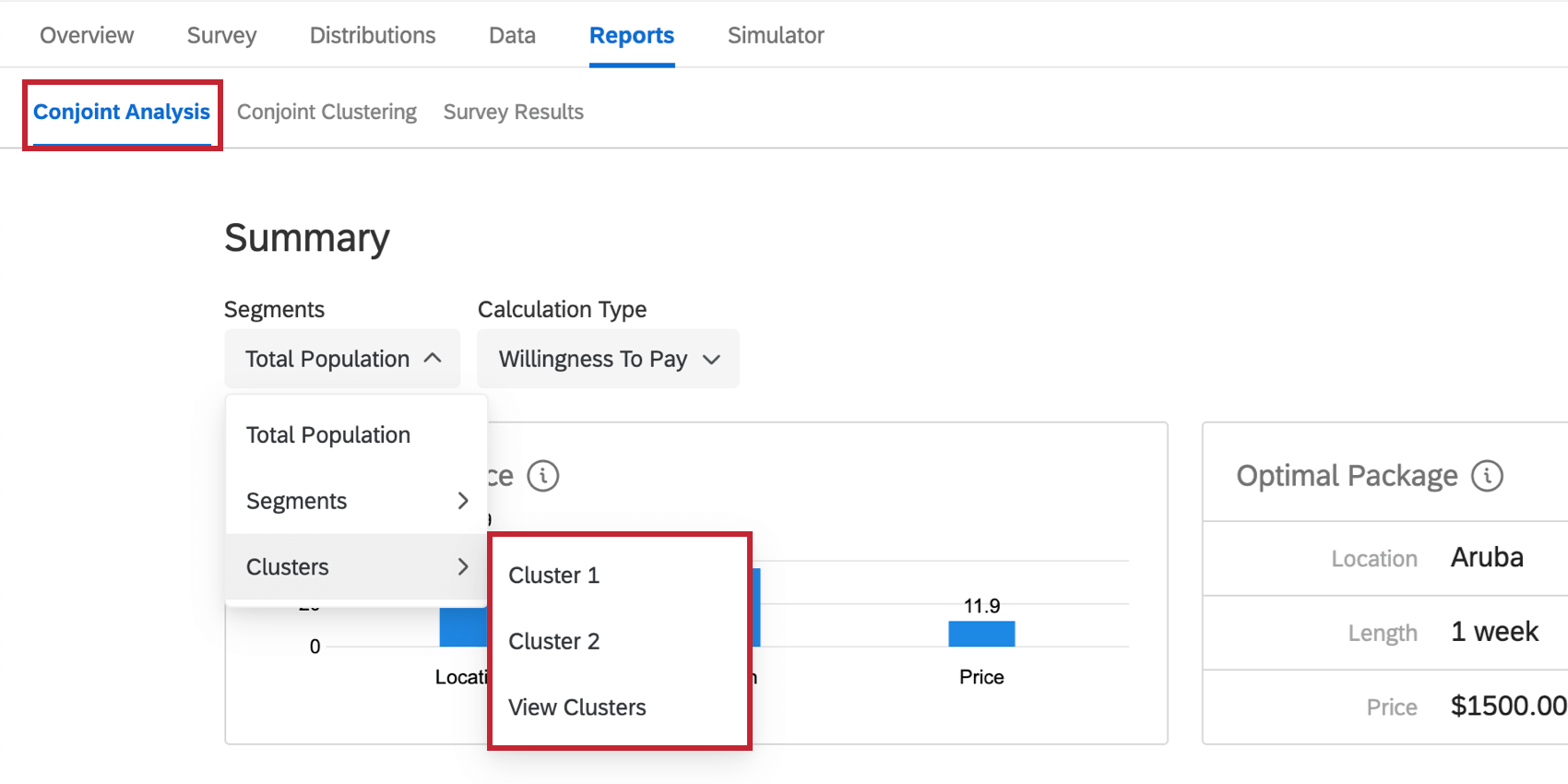
Sie können auch Folgendes auswählen: Analysevorschau wenn Sie einen Cluster in der Conjoint-Clustering Abschnitt des Berichte Registerkarte.
Simulator
Während Sie im Simulator einen Cluster aus der Dropdown-Liste oben rechts aus.
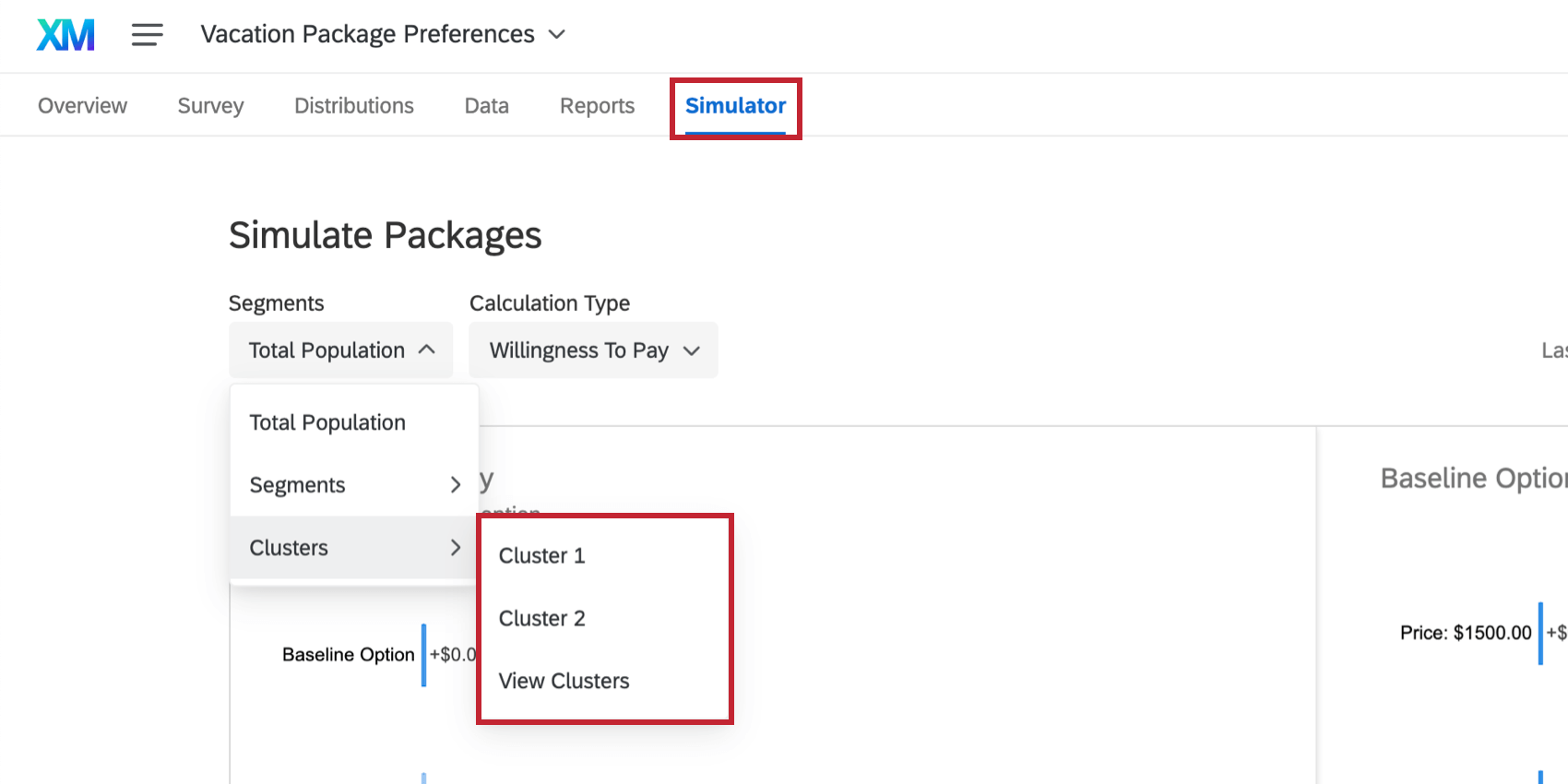
Sie können auch Folgendes auswählen: Pakete simulieren wenn Sie einen Cluster in der Conjoint-Clustering Abschnitt des Berichte Registerkarte.