-

Qualtrics Platform -

Customer Journey Optimizer -

XM Discover -

Qualtrics Social Connect
Verwendung und Bearbeitung der Datenquelle Ihrer INSTANZ Tracker
Informationen zur Verwendung und Bearbeitung Ihrer Instanz
BX-Programme Sammeln Sie Daten über Ihre Instanz zusätzlich zu wettbewerbsfähigen Marken und dem größeren Markt, was dazu führt, dass der Datensatz komplexer ist als Projekte. BX-Programme verwenden ein gestapeltes Datenset (Instanz oder BTDS), um Erkenntnisse in Ihren Daten einfacher zu identifizieren.
Die BX-Datenquelle verstehen
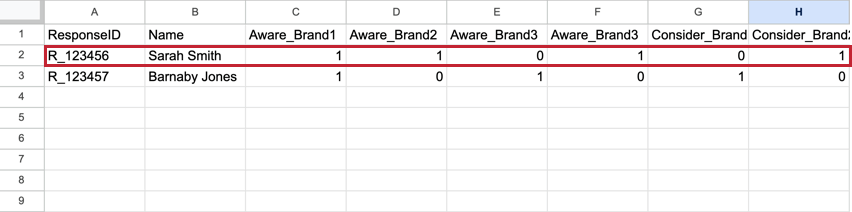
Der BTDS unterscheidet sich von dem, was Sie in einem Standarddatenset sehen würden. In einem Standarddatensatz hat jeder Befragte:r eine Zeile, die alle Antworten auf seine Antworten enthält, wobei die Metrik jeder Instanz eine eigene Spalte ist. Diese Datensets sind tendenziell sehr breit mit Hunderten von Spalten.
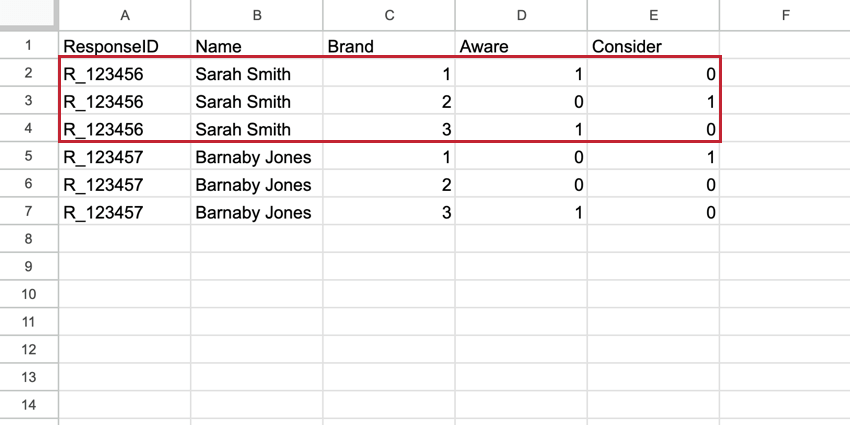
Im BTDS Instanz wird zu einer erstklassigen Spalte im Datensatz, und jeder Befragte:r hat eine Zeile für jede Instanz. Die Zeile der Instanz enthält alle Daten für diese einzelne Instanz. Diese Datensets haben mehr Zeilen als das Standarddatenset, aber sie haben viel weniger Spalten, was sie leichter lesbar macht.
RESPONSEID
Die ResponseID Das Feld hilft uns dabei, zu ermitteln, welche Zeilen zum selben Befragte:r gehören. Dieser Wert stammt aus der ursprünglichen Umfrage und wird für jede Zeile gehören Befragte:r wiederholt.
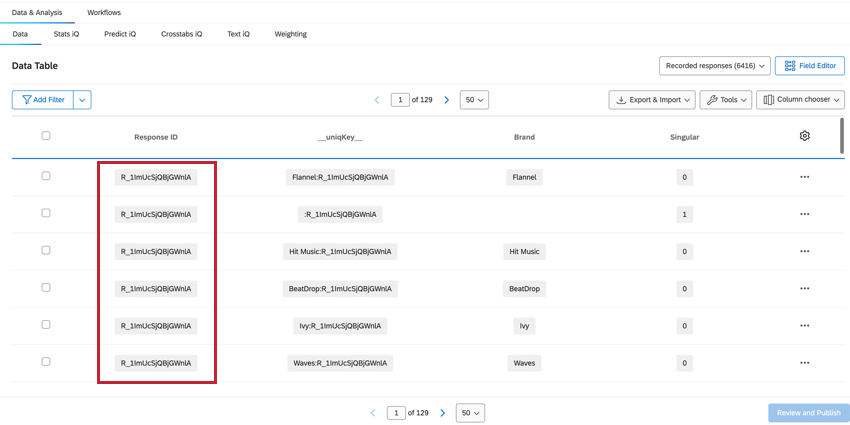
SINGULAR
Die Anzahl der aufgezeichneten Antworten in der Daten& Analyse zeigt die Gesamtanzahl aller Zeilen an, die höher ist als die Gesamtzahl der eindeutigen Teilnehmer. Um die eindeutigen Teilnehmer zu ermitteln, können wir Filter für das Feld Singular.
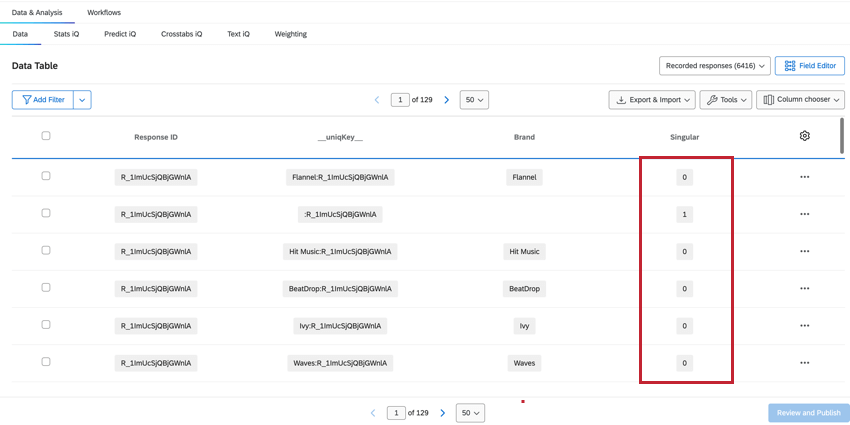
- Wenn Singular = 1, werden eindeutige Befragte:r ohne Instanz angezeigt. Pro Antwort gibt es eine eindeutige Zeile für Befragte:r.
Tipp: Anlegen einer Filter Für Singular = 1 wird die Anzahl der einzelnen Teilnehmer angezeigt.
- Wenn Singular = 0, enthält die Zeile Instanz. Für jeden Befragte:r gibt es mehrere Zeilen Instanz.
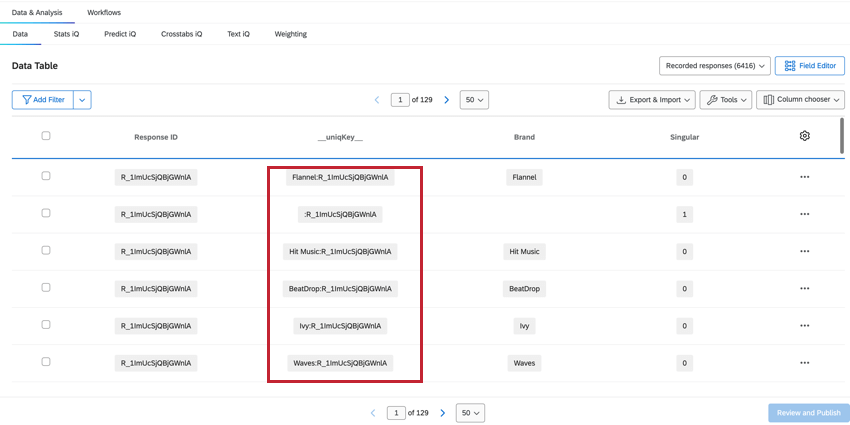
UNIQKEY
Die __uniqKey__ kombiniert ResponseID und Instanz, angezeigt als BrandName:ResponseID. Für die Zeile mit eindeutigen Befragte:r ohne Instanz wird für dieselbe Zeile, in der Singular = 1 ist, __uniqKey__ ResponseID. Dies ist nützlich, um die genaue Antwort einzugrenzen, aus der diese Daten stammen, sowie die Instanz, zu der sie speziell Feedback geben.
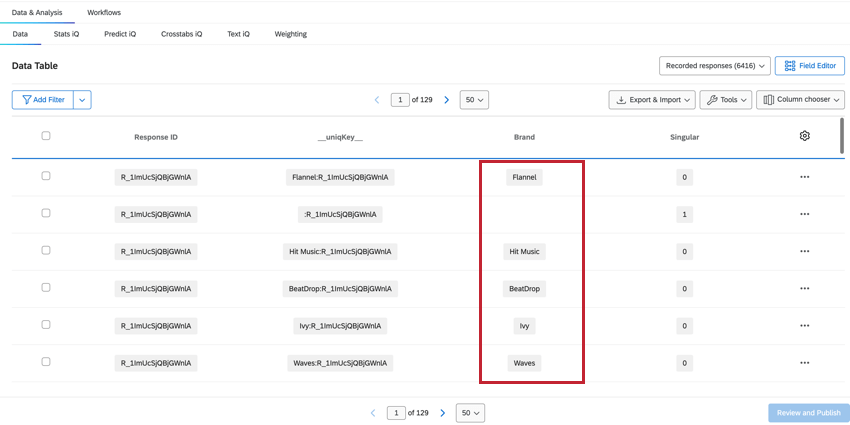
INSTANZ
Die Instanz zeigt an, auf welche Instanz sich die Daten in dieser Spalte beziehen, sodass Sie und Filter für Instanz.
ATTRIBUTE-LED MULTI-SELECT DATEN
Attributgeführte Fragen enthalten die Marken als Antwortmöglichkeiten. Dies sind in der Regel Mehrfachauswahl Fragetypenund es gibt mehrere Spalten mit Daten, die dieser Frage entsprechen.
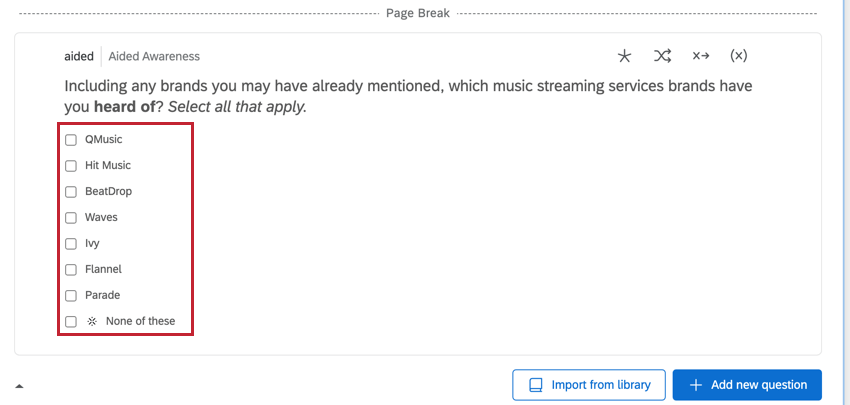
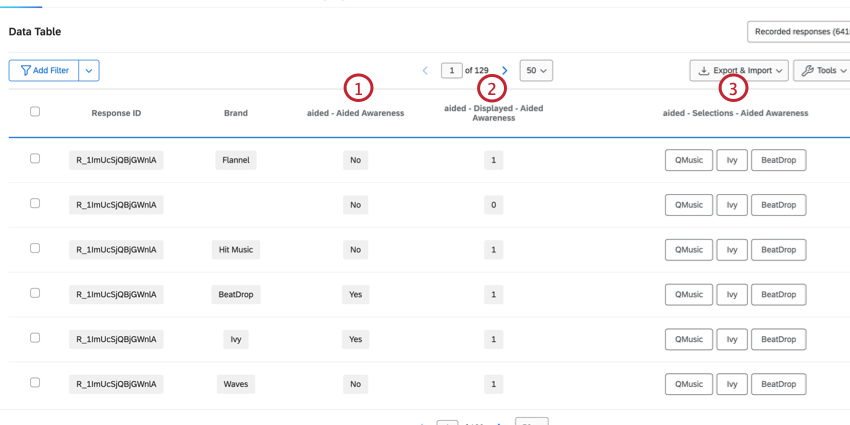
- Frage: Legt fest, ob die Instanz für diese Frage ausgewählt wurde. Die Daten sind 1 („Ja“) oder 0 („Nein“).
- Frage – angezeigt: Legt fest, ob die Instanz für diese Frage angezeigt wurde. Die Daten sind 1 (angezeigt) oder 0 (nicht angezeigt).
- Frage – Auswahl: Enthält alle Marken, die für diese Frage ausgewählt wurden. Diese Spalte enthält mehrere Werte, und die Werteliste ist für alle Zeilen dieses Befragte:r identisch.
FRAGEDATEN LOOP UND ZUSAMMENFÜHREN
Es gibt auch mehrere Spalten für Fragen, die Pipe im Instanz mit Schleife & zusammenführen.
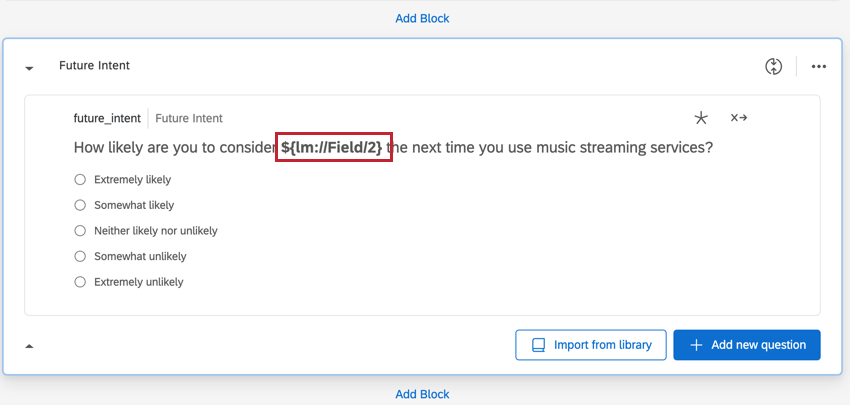
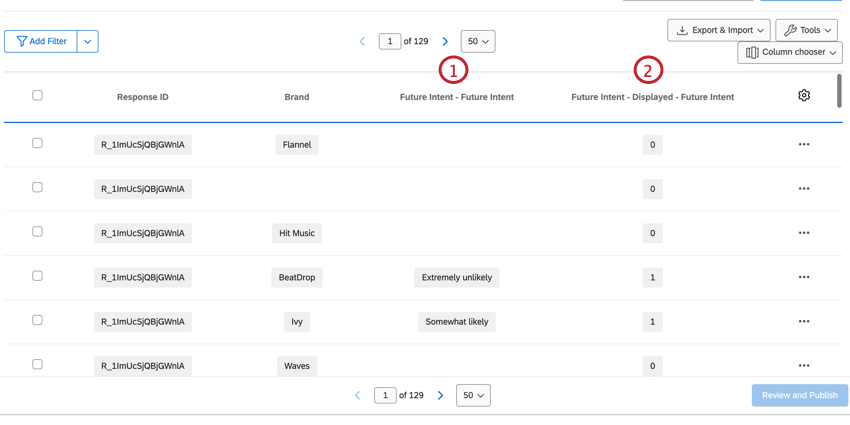
- Frage: Zeigt an, welche Antwortmöglichkeit für die Frage ausgewählt wurde.
- Frage – angezeigt: Legt fest, ob die Instanz für diese Frage angezeigt wurde. Die Daten sind 1 (angezeigt) oder 0 (nicht angezeigt).
NON-STACKED DATA
Nicht gestapelte Daten beziehen sich nicht auf Instanz, z. B. Standardfragen (z. B. demografische Daten) und nicht gestapelte Daten. eingebettete Daten. Diese Felder sind wiederholte für jede Instanz, wodurch die Daten verfügbar bleiben, unabhängig davon, ob Sie sich eine bestimmte Instanz ansehen oder über alle Marken hinweg.
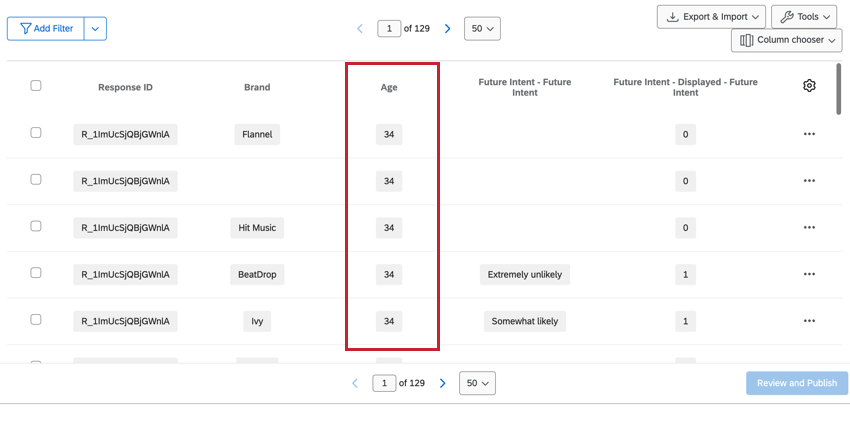
Generierung des BTDS
Wenn Sie ein BX-Programm von Grund auf neu erstellen, wird die Instanz nicht automatisch generiert und muss vor der Datensammlung generiert werden. Alle Daten, die vor der Generierung des BTDS gesammelt wurden, werden nicht gestapelt.
- Anlegen einer BX-Programm.
- Navigieren Sie zu Ihrer Umfrage.
- Geben Sie Folgendes ein: Umfragenverlauf.
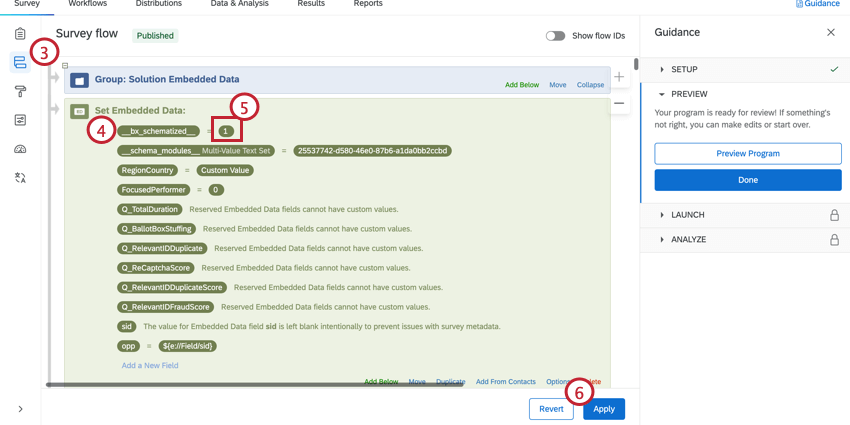
- Suchen Sie die __bx_schematized__. Es sollte das erste eingebettete Daten im Umfragenverlauf sein.
- Ändern Sie den Wert in 1.
- Klicken Sie auf Anwenden.
- Navigieren Sie zurück zum Umfrage-Editor und klicken Sie auf Veröffentlichen , um Ihre Umfrage zu veröffentlichen.
Kompatibilität mit gestapeltem Datenset
Gestapelte Datensets weisen Einschränkungen auf, Feldtypen und Fragetypen für die Datenverarbeitung am besten geeignet sind. Beim Anlegen Ihres BX-Programms ist es wichtig, sicherzustellen, dass die Umfrage mit den generierten BTDS kompatibel ist.
Das BTDS ist kompatibel mit den folgenden Fragetypen:
- Multiple Antwortmöglichkeit (Einfach- und Mehrfachauswahl)
- Texteingabe, Matrix
- Beschreibungstext
- Konstante Summe
- Schieberegler
- Rangfolge
- Browser-Metadaten
Filtern und Exportieren der BTDS
Das Filtern und Exportieren der BTDS funktioniert genauso wie das Filtern und Exportieren über die Registerkarte Data & Analysis. Diese Vorgänge können hilfreich sein, um Erkenntnisse aus dem Dashboard besser zu verstehen, die Größe des Datensatzes einzuschränken oder bestimmte Unterabschnitte des gestapelten Datensatzes anzuzeigen.
Optimierung
BX-Programme mit großen Instanz können Datenmengen erzeugen, die größer als nötig sind. Mit Instanz können Sie Ihre Daten auf die Marken beschränken, die signifikant sind.
- Zu Ihren BX-Projekten navigieren Umfrage.
- Klicken Sie im eingebettete Daten auf Neues Feld hinzufügen.
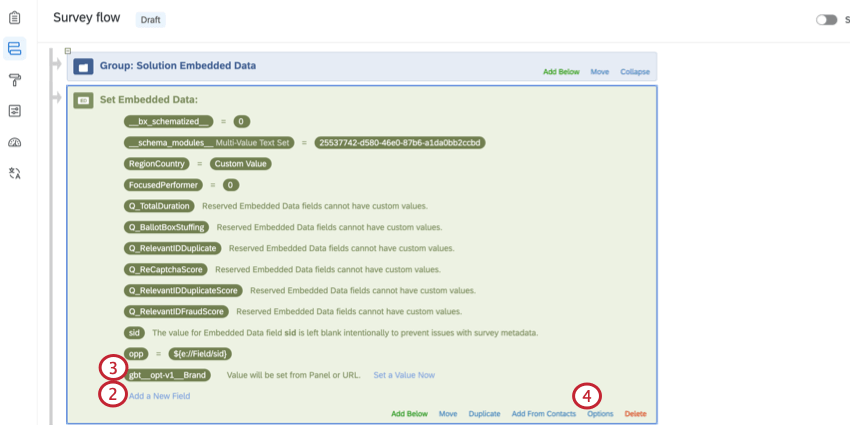
- Feld benennen
gbt__opt-v1__Marke. - Klicken Sie auf Optionen.
- Wählen Sie für die in Schritt 3 angelegte Variable Mehrwertiges Textset als Variablentyp.
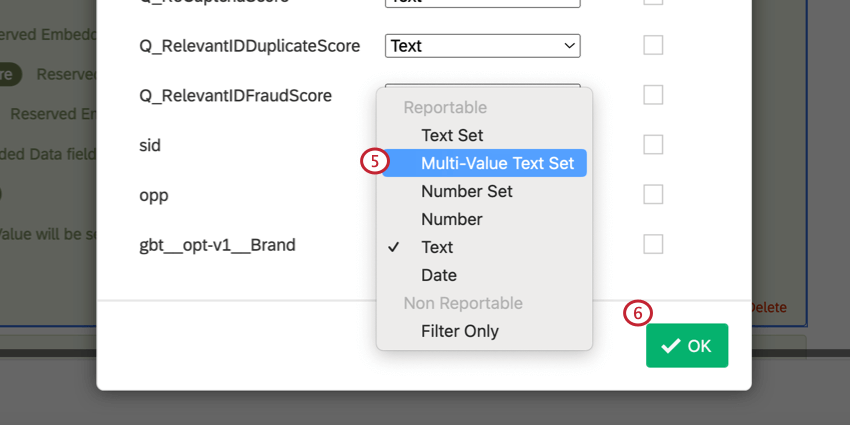
- Klicken Sie auf OK.
- Nach der Frage, die die Instanz definiert, Verzweigung hinzufügen . Im obigen Beispiel wäre diese Verzweigung nach der Frage nach Ländern.
- Klicken Sie auf Bedingung hinzufügen .
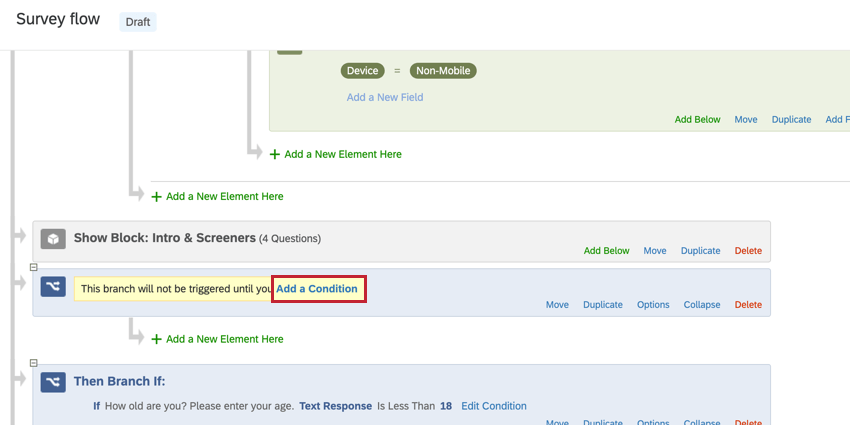
- Legen Sie die Bedingung an, die Ihre Instanz definiert. Für das obige Beispiel wäre dies „Kanada“.
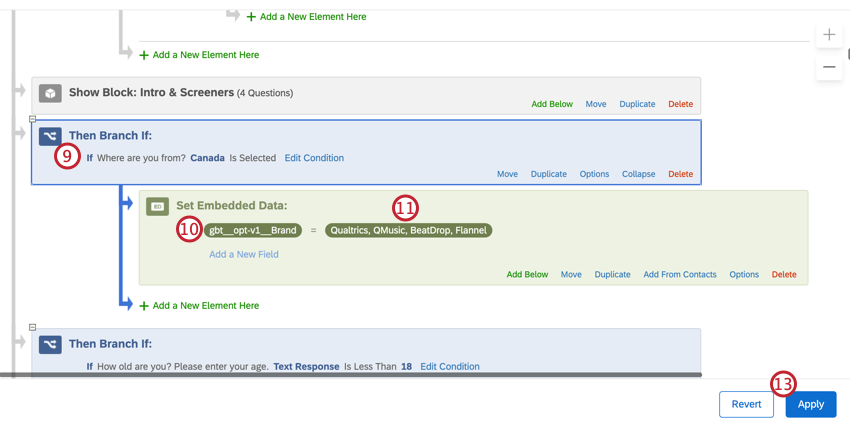
- Fügen Sie die Variable hinzu, die Sie in Schritt 3 angelegt haben.
- Geben Sie die Marken ein, für die Sie einen Bericht erstellen möchten. Für das obige Beispiel wären dies die vier Marken, an denen Kanada interessiert ist.
- Wiederholen Sie die Schritte 7 bis 9 für die anderen Instanz, die Sie optimieren möchten.
- Klicken Sie auf Anwenden.
- Umfrage Veröffentlichen .
Wenn die Optimierungsvariable definiert ist, entfernt der verarbeitete BTDS Zeilen, die nicht in der Liste für diese Variable enthalten sind.
Fehlerbehebung mit BTDS
Häufige Probleme mit dem BTDS sind:
- Die Anzahl der Antworten unterscheidet sich zwischen dem BTDS und der Data & Analyse der Umfrage.
- Die Instanz oder -felder sind nicht oder nicht ordnungsgemäß stapeln nachdem das BTDS generiert wurde.
ANZAHL DER ANTWORT
Um die Antwortanzahl zwischen dem Umfrage und dem BTDS zu vergleichen, filtern Sie die BTDS nach Singular = 1. Vergleichen Sie diese Anzahl mit der Gesamtanzahl im Umfrage. Wenn die Daten korrekt fließen, sollten diese beiden Zahlen übereinstimmen.
Wenn diese Zahlen nicht übereinstimmen, kann es zu inkompatiblen Komponenten in der Umfrage kommen. Überprüfen Best Practices für BX-Programme. Wenn alle Komponenten korrekt erscheinen, wenden Sie sich bitte an den Qualtrics Support mit einer Liste der betroffenen Antwort-IDs.
STACKING ODER STACKING IMPROPERLY
- Prüfen Sie die Liste Wiederverwendbare Antwortmöglichkeit und alle markengeführten Fragen. Die Instanz müssen übereinstimmen genau auf die Liste Wiederverwendbare Antwortmöglichkeit.
- Stellen Sie sicher, dass die Instanz keine Teilzeichenfolgen enthält (z. B. eine Instanz “Qualtrics” und eine andere Instanz „Qualtrics Employee Experience“).
- Stellen Sie sicher, dass der Fragetext eine exakte Übereinstimmung für jede Frage ist, die zusammen gestapelt werden soll. Verschiedene dynamischer Text in jeder Frage (z. B. dynamischer Text für verschiedene Logos pro Instanz) verhindern, dass Fragen zusammen gestapelt werden, was insbesondere in Matrix üblich ist.
- Prüfen Sie die Ergebnisse von Expert Review > Daten-Stacking, um festzustellen, ob es markierte Probleme gibt.