
MaxDiff Clustering
What's on this page
About MaxDiff Clustering
Within populations of survey respondents are groups of like-minded people. These groups, or “clusters,” can be determined by how similar each respondent’s most preferred features are. By clustering each respondent based on their individual utility for each attribute, we can determine subpopulations and what demographics make up these subpopulations.
Qtip: This feature is incredibly useful when you are looking to define segments.
Preparing a Survey for Clustering
Before you can use MaxDiff clustering, you have to make sure that the survey of your MaxDiff Project is asking the right questions. This means you need to set up certain features before you collect data.
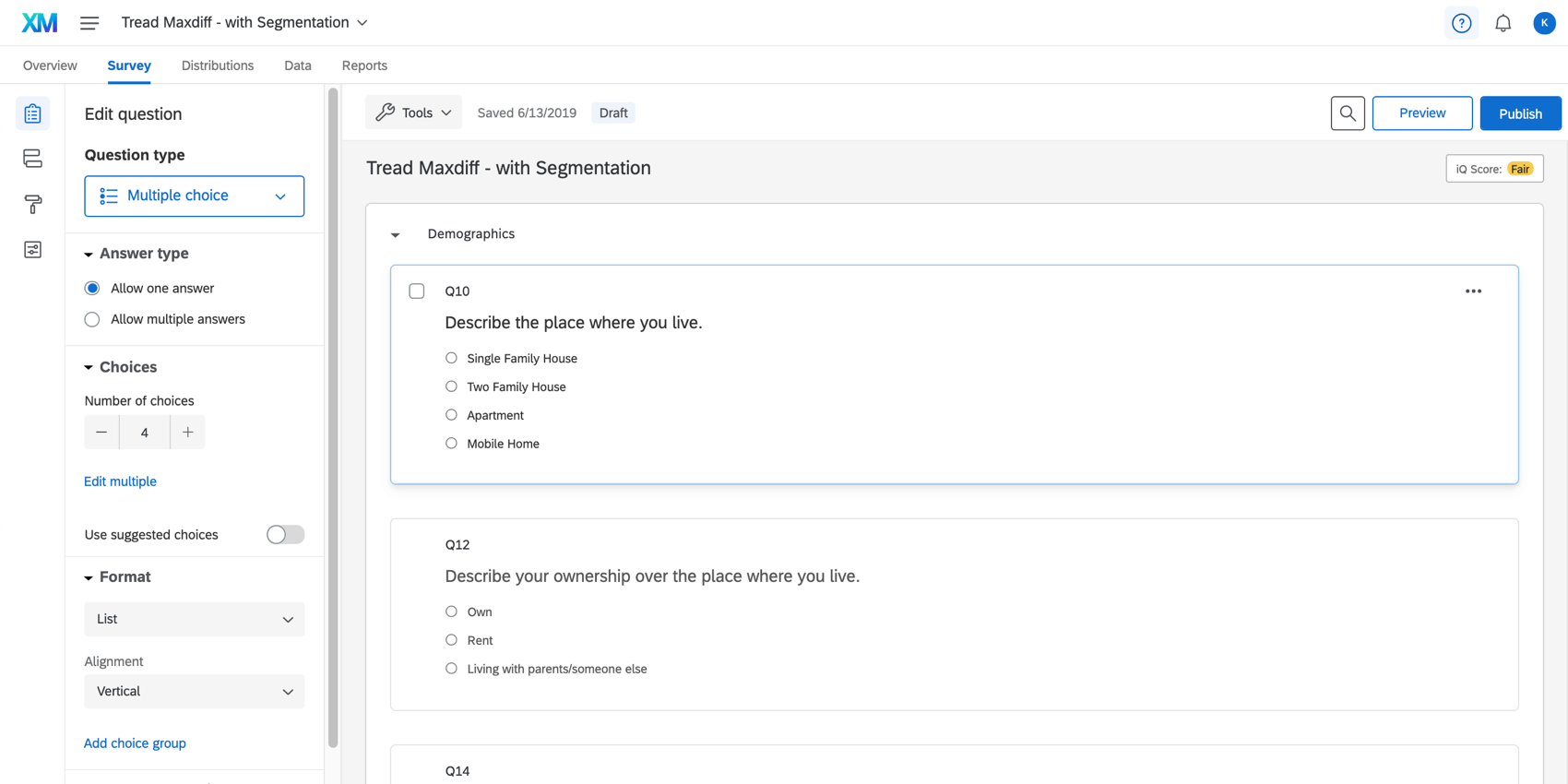
In the Survey tab, make sure you’ve added questions to a non-MaxDiff block. In the example below, the Demographics block has a question on age, the number of people in the respondent’s household, and more.
{kind=link}

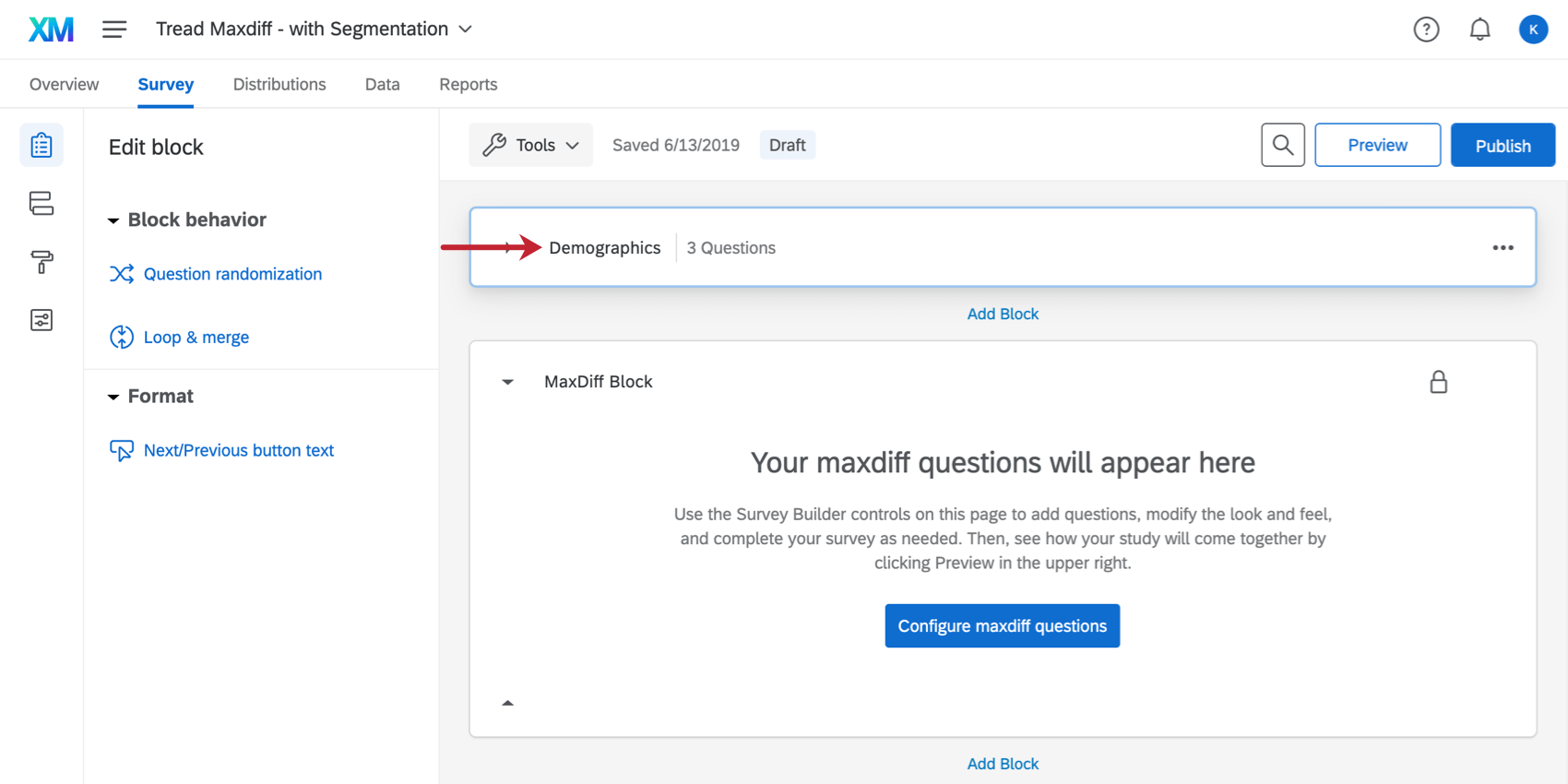
The Demographics block is located right above the MaxDiff block, although you can move it as desired.
{kind=link}
Question Formatting
You can only conduct MaxDiff clustering using single-select multiple choice questions. This is because they offer a finite selection of choices that can be easily analyzed.
- Demographics: Ask about basic descriptive information, such as age, income bracket, race, or gender.
- Behavior: Ask how customers interact with your brand and your products, or about behaviors that may relate to their purchasing behavior. For example, you can ask how often the customer goes shopping.
- Operational Data: This is information such as time spent on your website, or an employee’s tenure in your company.
- Question Formats: Format questions about behaviors and beliefs as scales. The range on a scale can help us understand what scale points are correlated and therefore roughly in the same cluster; Yes/No and single-select questions are not as useful for cluster analysis. Example: If you ask “What kind of shopper are you?” and give the options “Prefer shopping at malls”, “Prefer shopping online”, and “Prefer shopping at boutiques”, the clustering algorithm will want to divide respondents into three groups, one for each answer. If you instead asked those as a series of questions (e.g., “Do you like shopping at malls?”) with responses 1 through 7, the clustering algorithm will do a better job at really discerning what separates different shoppers from each other.

Qtip: Once you’re finished adding questions, don’t forget to publish.
Enabling Clusters
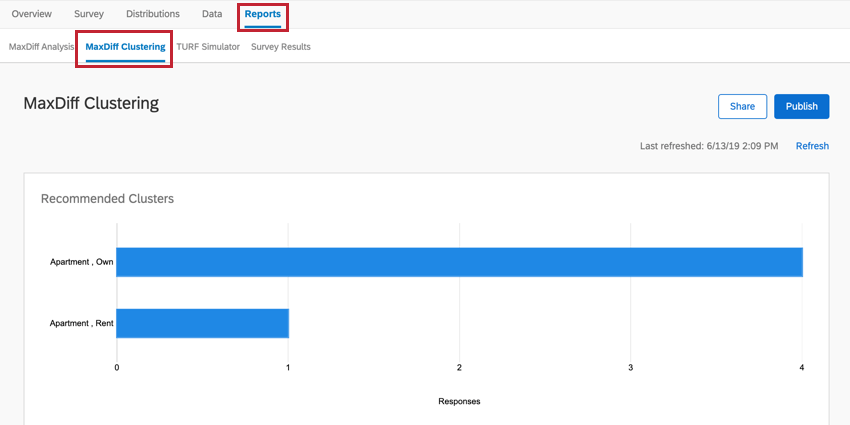
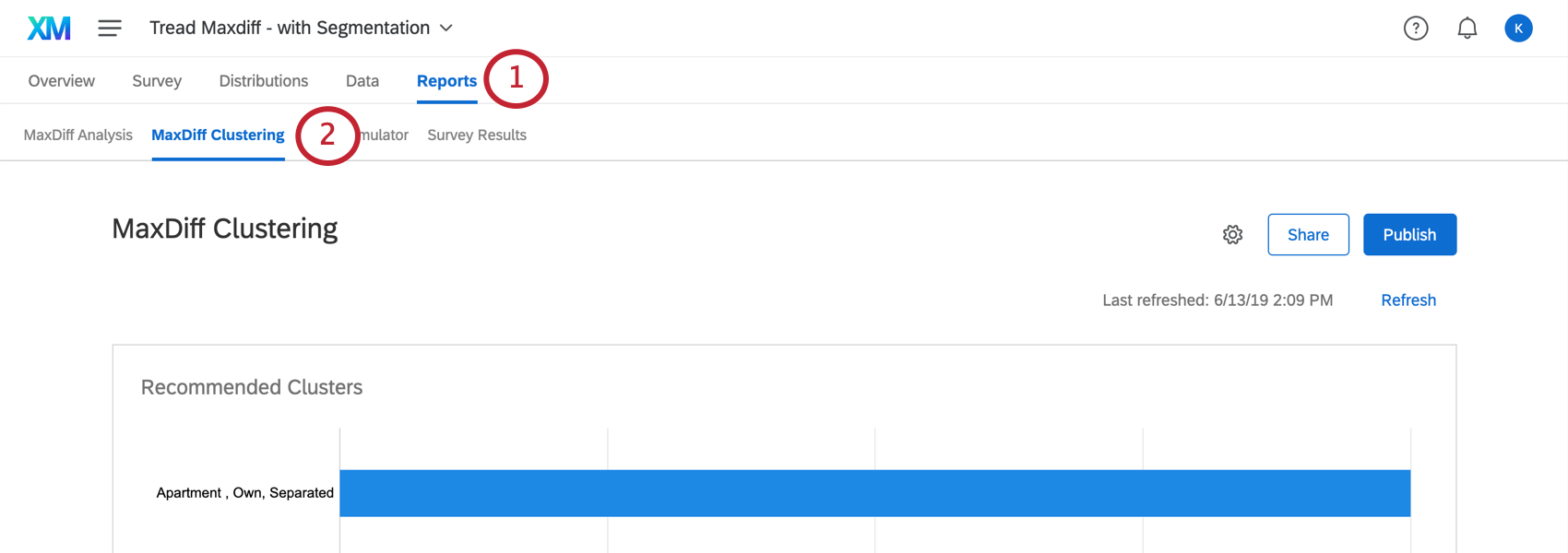
Clustering can be found in the MaxDiff Clustering section of the Reports tab.
{kind=link}
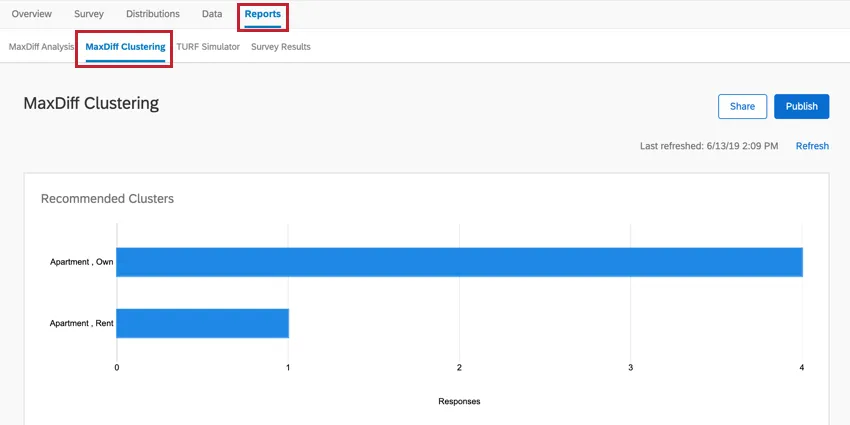
To make data appear the first time, you may need to click Refresh in the MaxDiff Analysis section, instead.
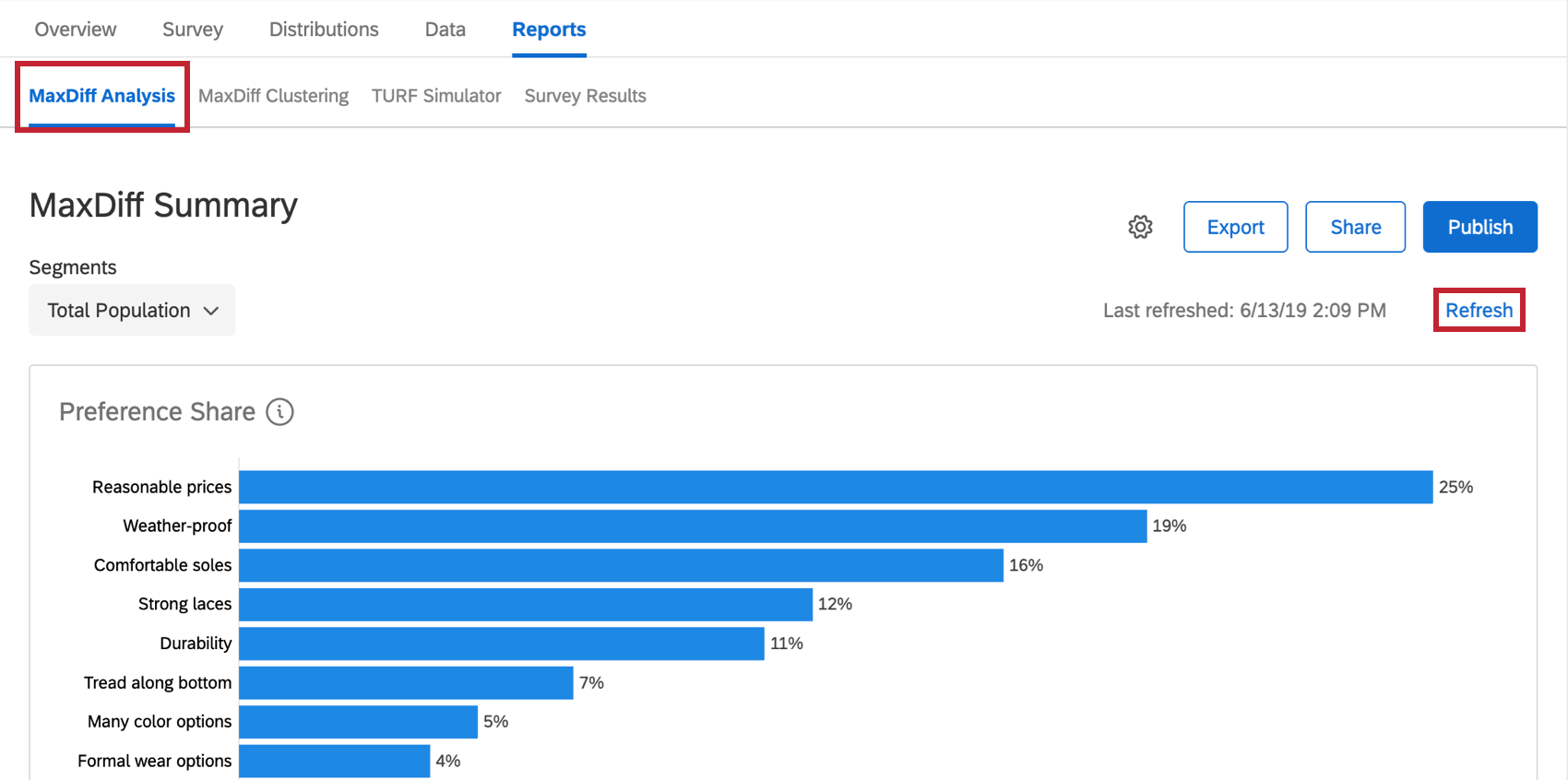{kind=link}
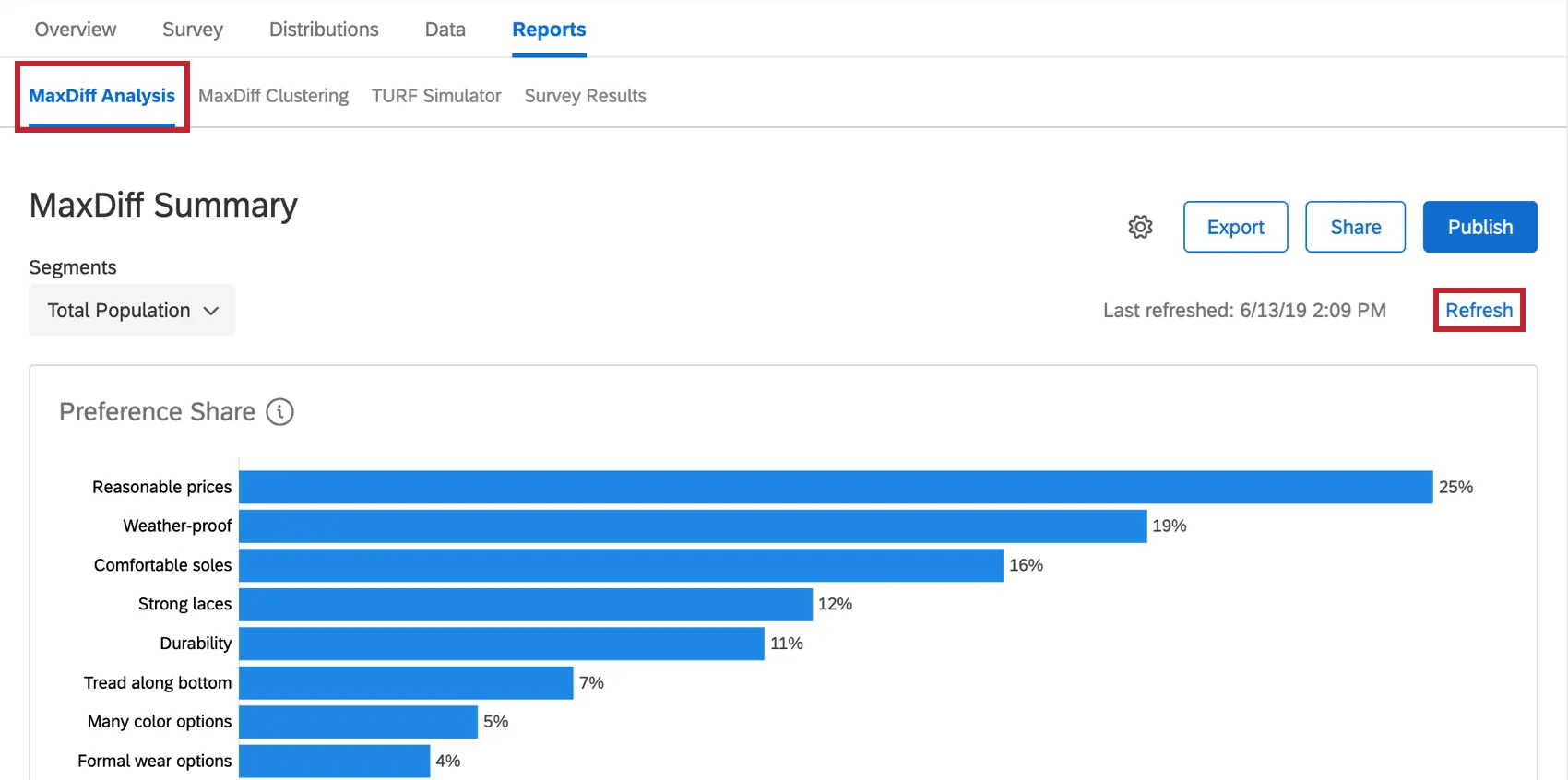
Qtip: Like MaxDiff analysis reports, the MaxDiff clustering report refreshes hourly.
Adjusting Demographics Used in Clustering
By default, MaxDiff clustering will use every multiple choice survey question you have made. However, you don’t have to use every question if you don’t want to, and you can add and remove content to see what different clusters this feature recommends to you.
Removing Demographics
In the box to the right of the Cluster Details header, click the X on a question to remove it from cluster analysis. Removing a question does not cause the clusters to recalculate.
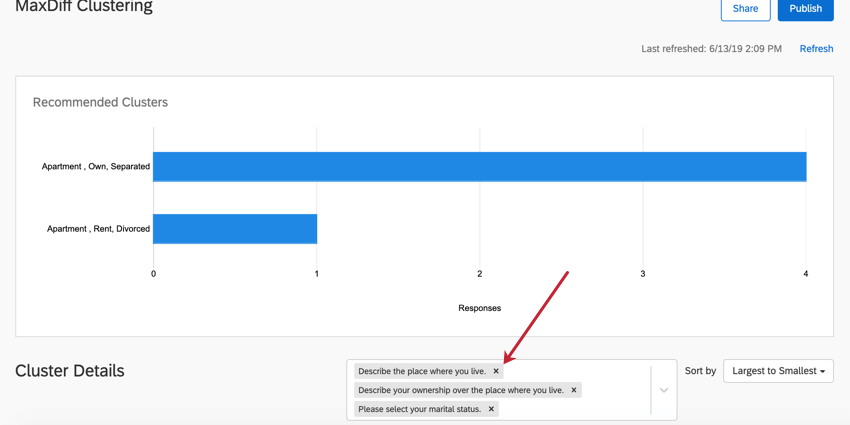{kind=link}
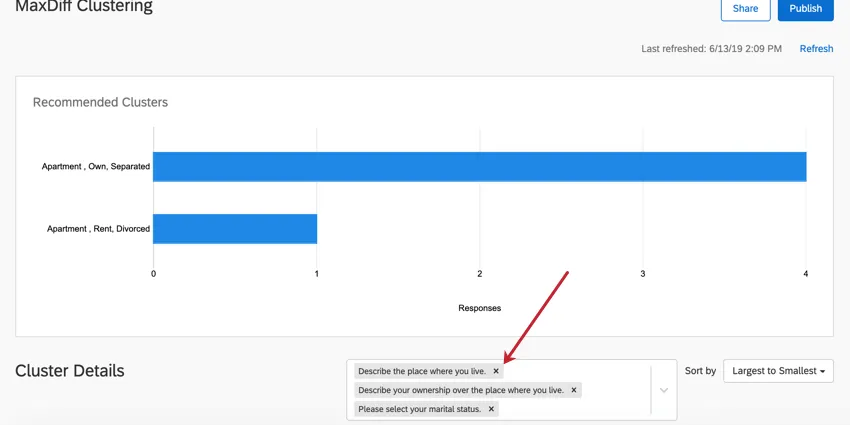
Adding Demographics
In the box to the right of the Cluster Details header, click the dropdown arrow. Then select the questions you’d like to add back to the clusters.
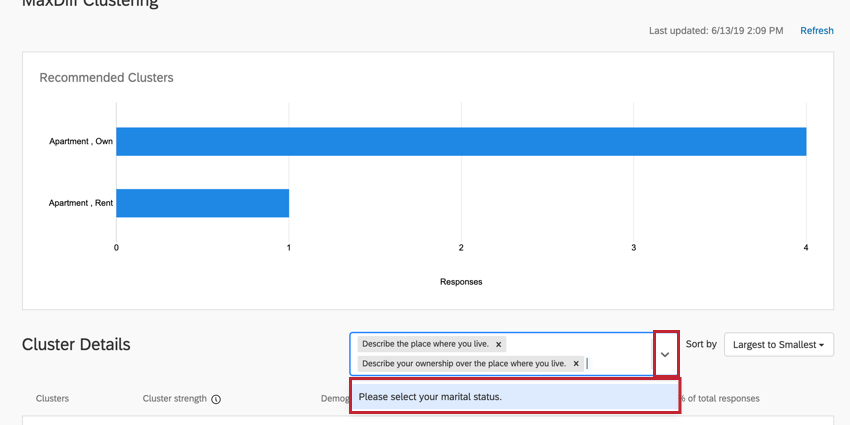{kind=link}
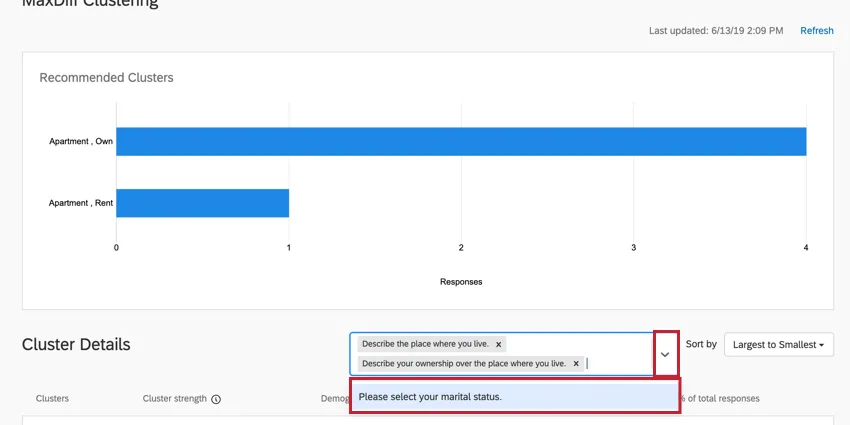
Recommended Clusters
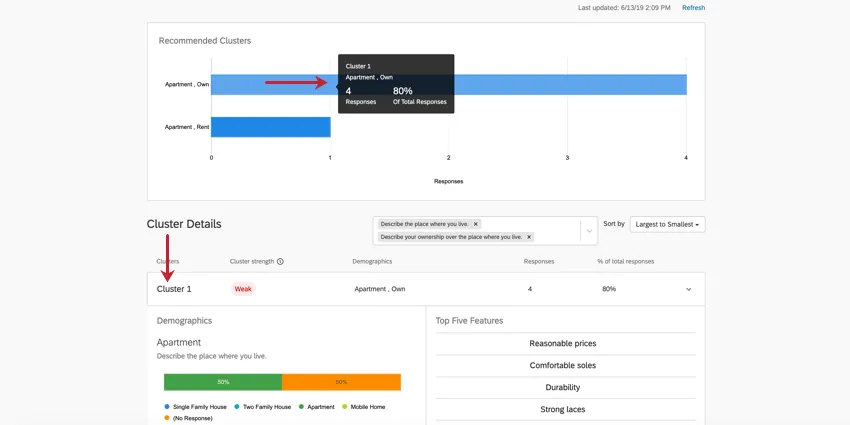
Once you’ve collected enough data and refreshed your MaxDiff clustering page, this feature will recommend clusters to you. These clusters are determined based on how similar the respondents’ most preferred features are. Their individual utility for each attribute is calculated, and then the demographics common amongst these clusters are highlighted so you can gain a better understanding of how different populations prefer your products.
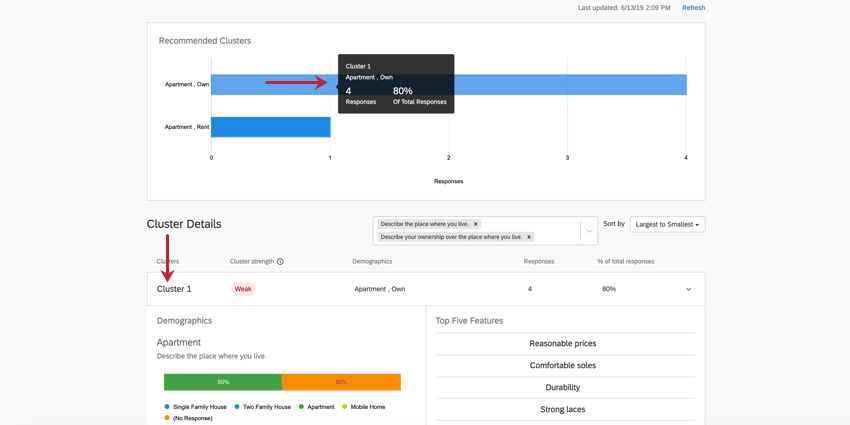
Highlight a cluster in the top graph to learn more about this cluster. Click it to open the cluster details below.
{kind=link}
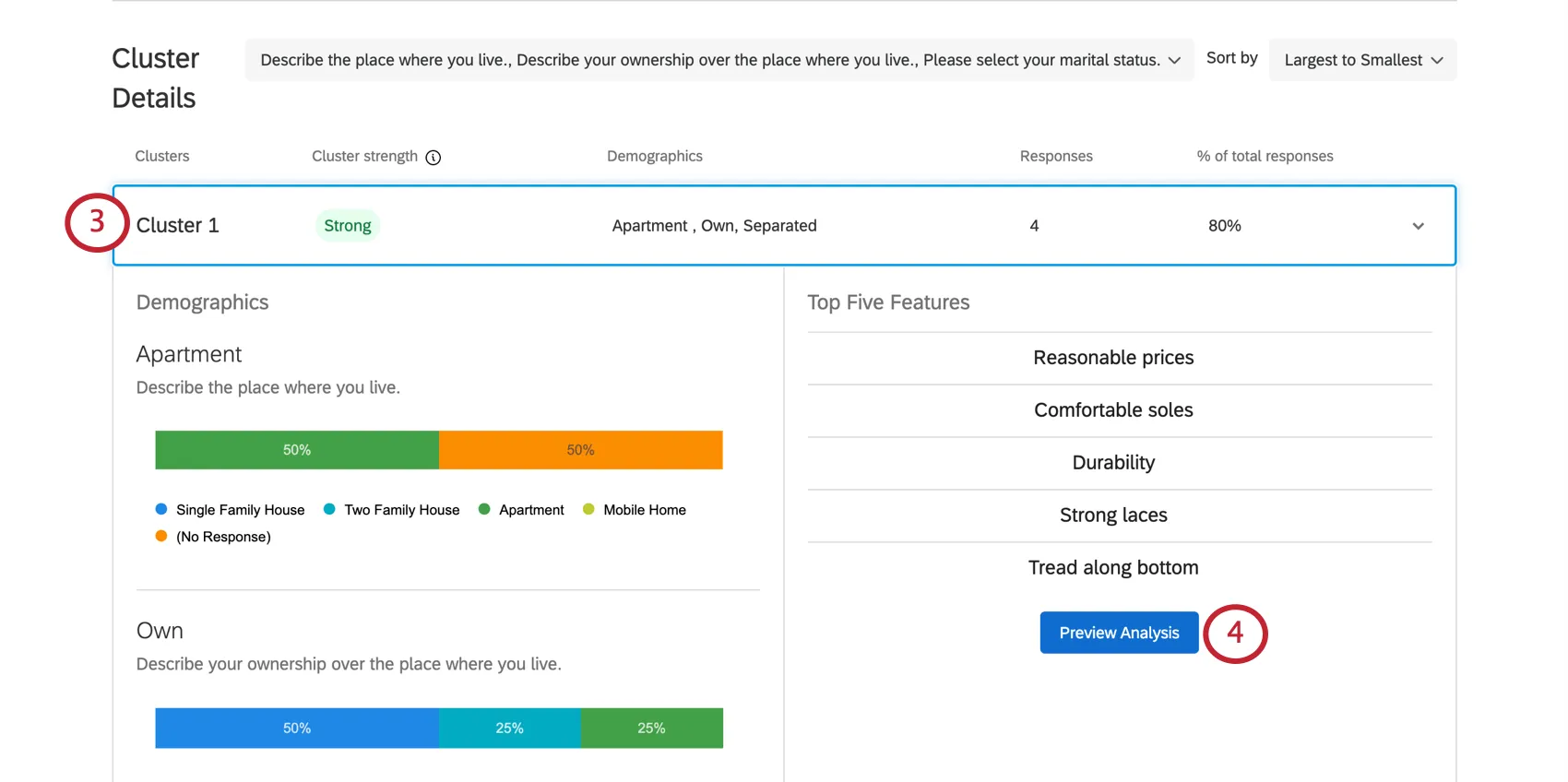
Cluster Details
{kind=link}
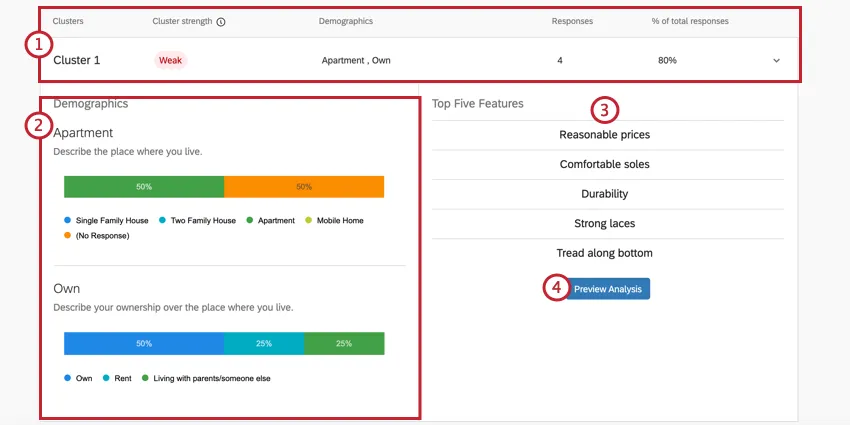
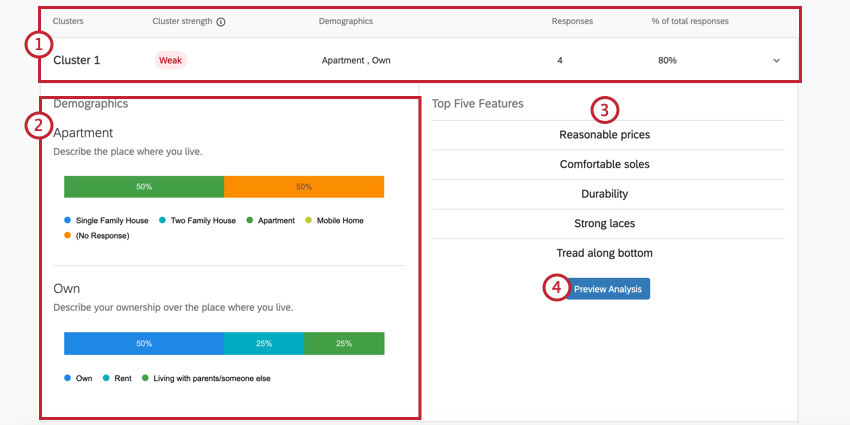
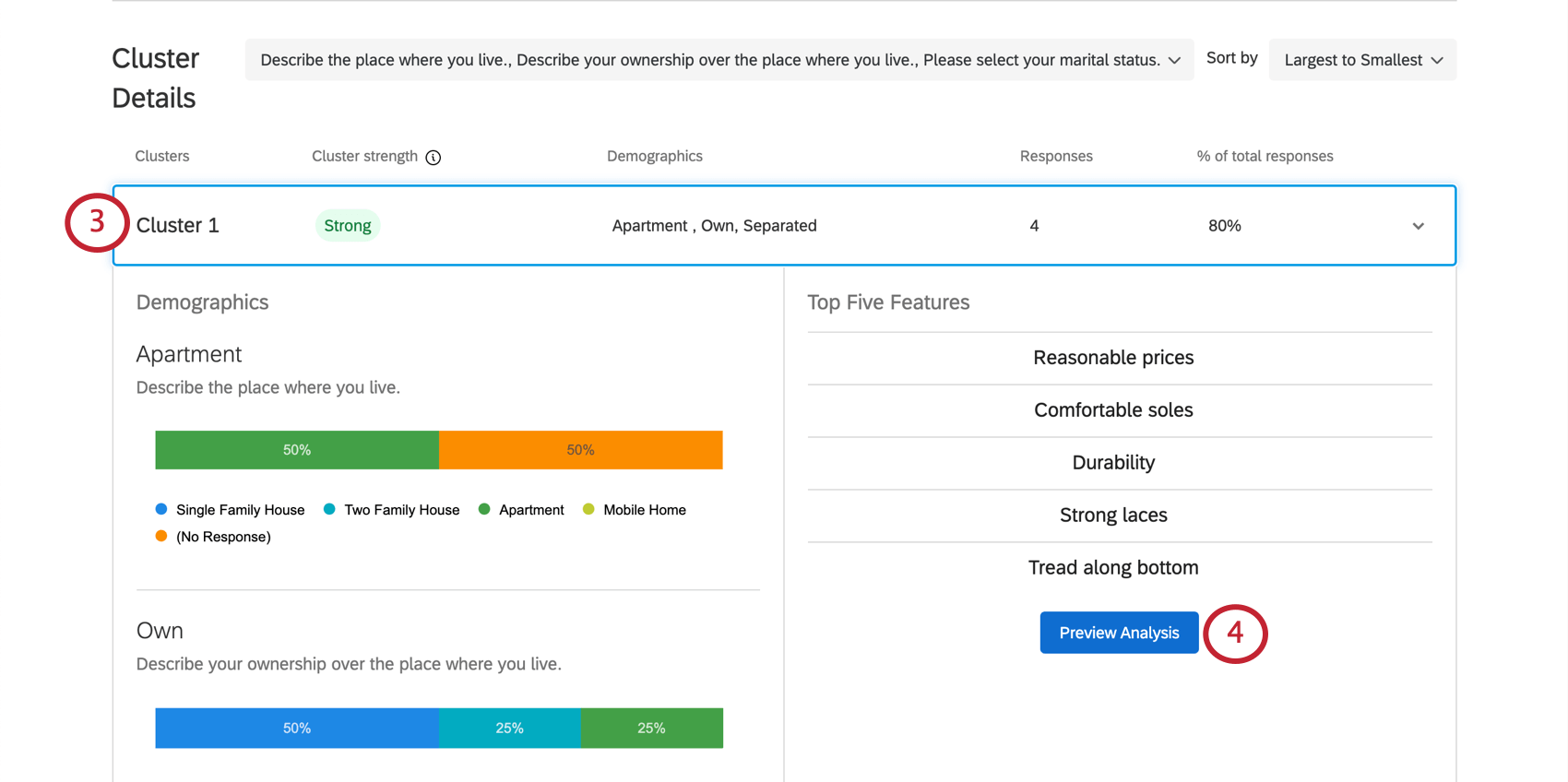
Example: In Cluster 1 pictured here, the responses tend to be from people who own their own apartment. 4 respondents generally fit this pattern, which is 80% of the entire dataset. This is a very small dataset, so decisions likely should not be made based on these results. This is also indicated by the cluster’s weak strength.
Example: Cluster 1’s annual income is listed as “$20,000 – $29,000.” However, this isn’t the most common annual income for this cluster, as we can see the bar for “$70,000 – $79,000” at the end is much longer. That’s because those who have a lower income are simply more likely to have valued Reasonable prices, Durability, and so on, than those in the cluster who have a higher annual income.
Qtip: Remember, the “Demographics” in these graphs are the non-MaxDiff questions you created in the Survey tab.
Determining Cluster Strength
Qualtrics uses a metric called silhouette scoring to determine the strength of each cluster. This score produces a value between 0 and 1 which determines how closely clustered the respondents are. We use the following table to convert from silhouette score to cluster strength:
| Correlation Score | Relationship Strength | Cluster Strength Label |
|---|---|---|
| 0.71 to 1.0 | Very strong relationship | Strong |
| 0.51 to 0.70 | Somewhat strong relationship | Somewhat strong |
| 0.26 to 0.50 | Somewhat weak relationship | Somewhat weak |
| 0 to 0.25 | No significant relationship | Weak |
Applying Clusters to Reports
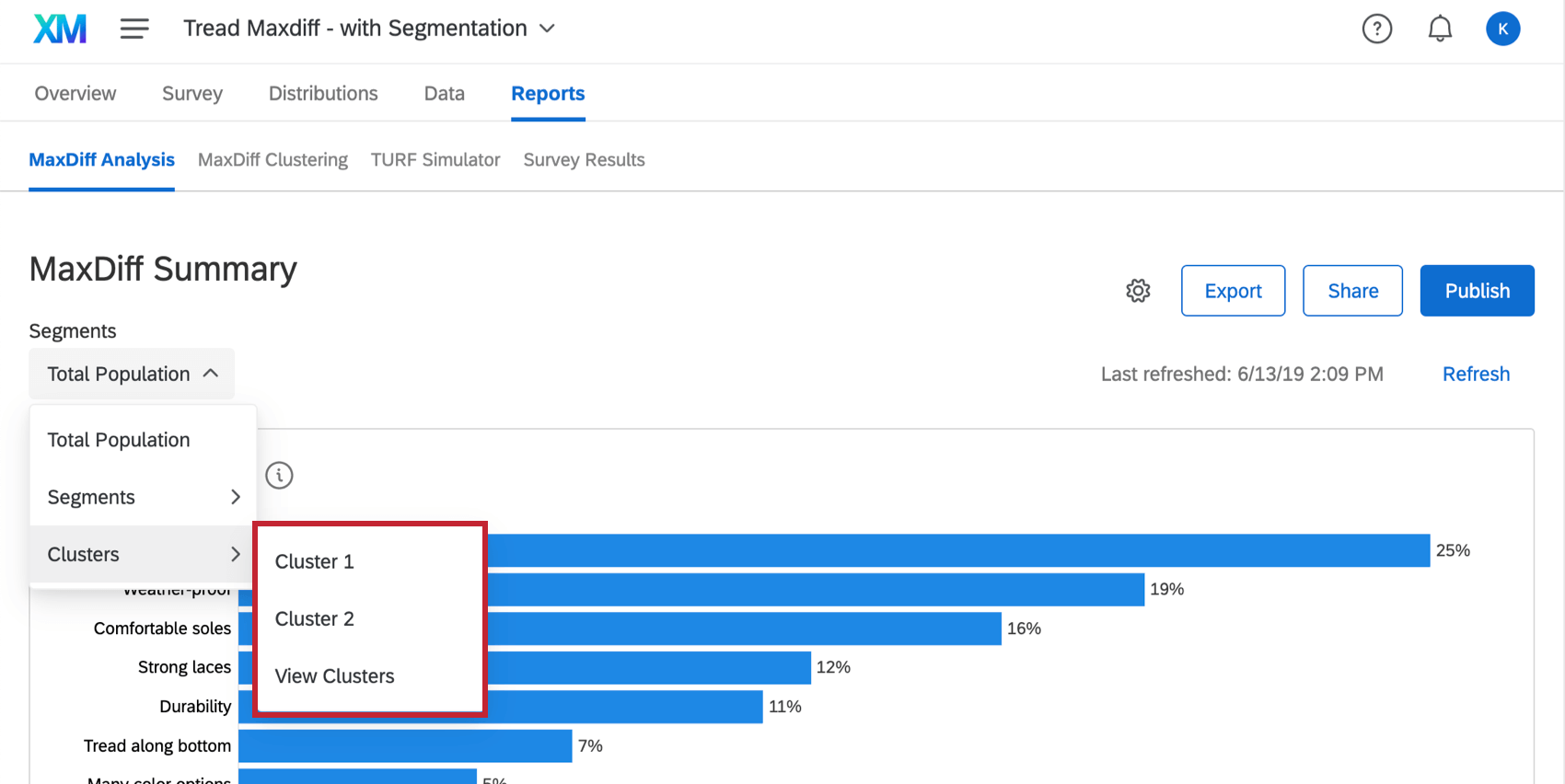
Clusters can be applied to the MaxDiff Analysis report so that you can see more specific details about how respondents in this cluster evaluated the attributes presented to them.
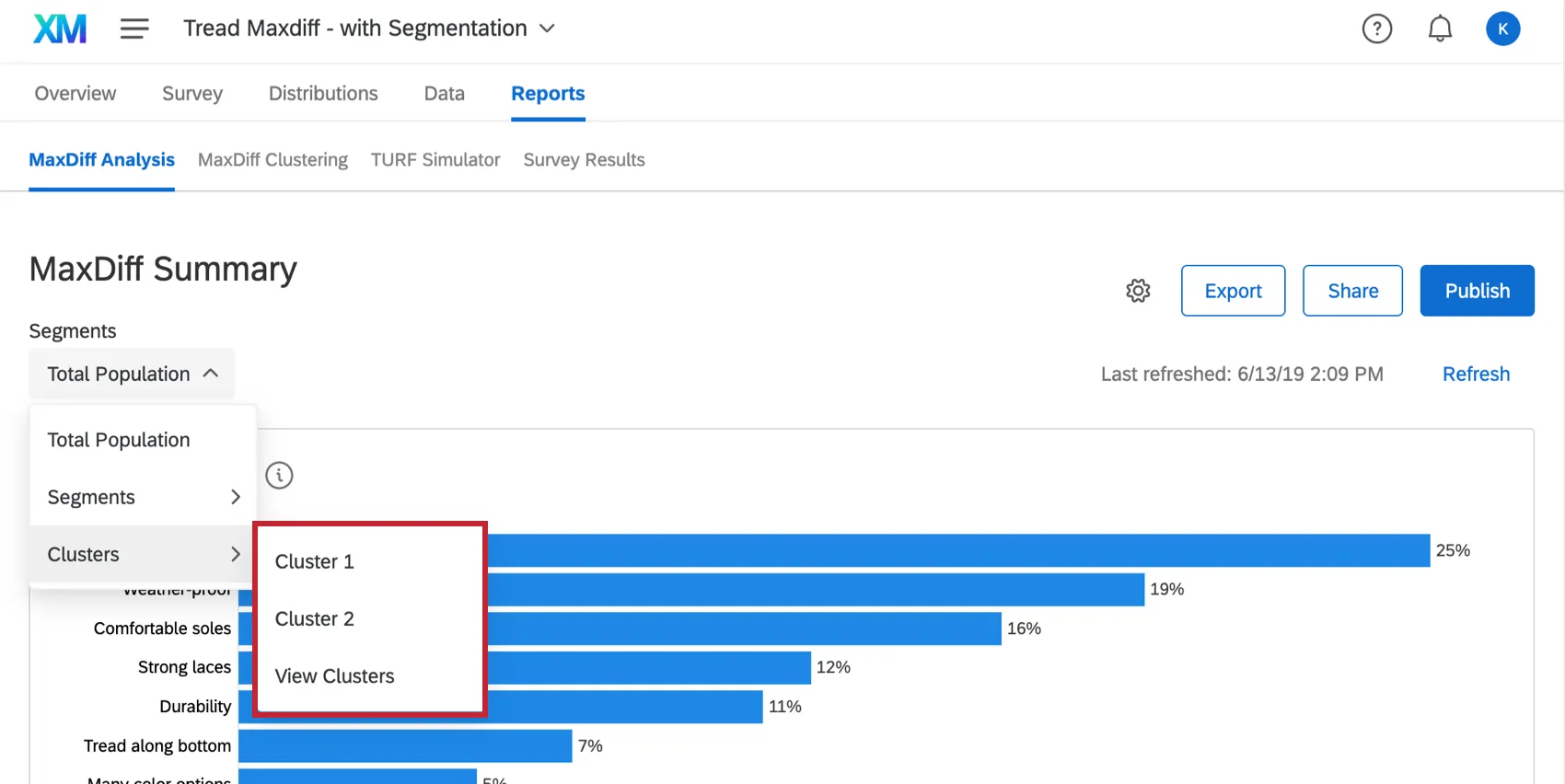
While in the MaxDiff Analysis section of the Reports tab, select a cluster from the Segments dropdown in the upper-left.
{kind=link}
You can also select Preview Analysis when you have a cluster selected in the MaxDiff Clustering section of the Reports tab.
{kind=link}
{kind=link}
That's great! Thank you for your feedback!
Thank you for your feedback!